人工智能行为识别之slowfast源码解读
一.slowfast项目环境配置与配置文件
如下配置都是在linux环境下进行的。
(1)环境基本配置解读
先从github中下载slowfast源代码下来。这个项目是指输入视频后最后做类别预测的功能。通过人体框与人体坐标来做人体检测功能。环境安装如下:
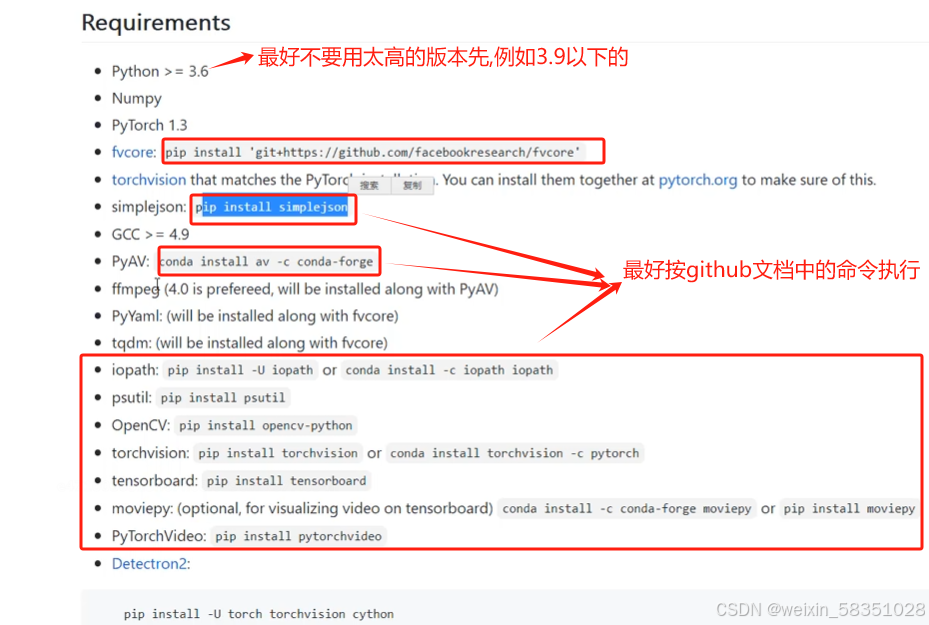
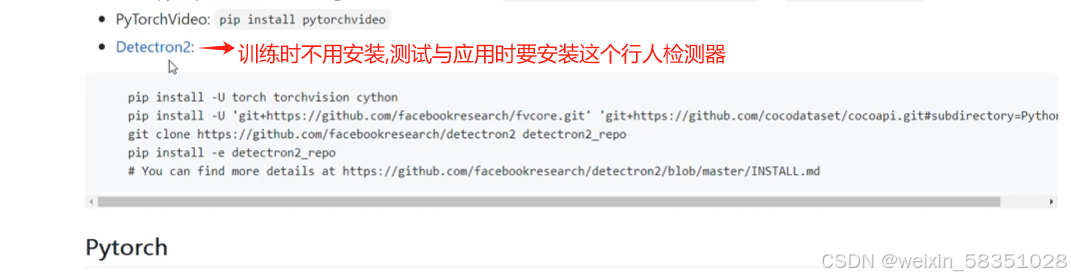
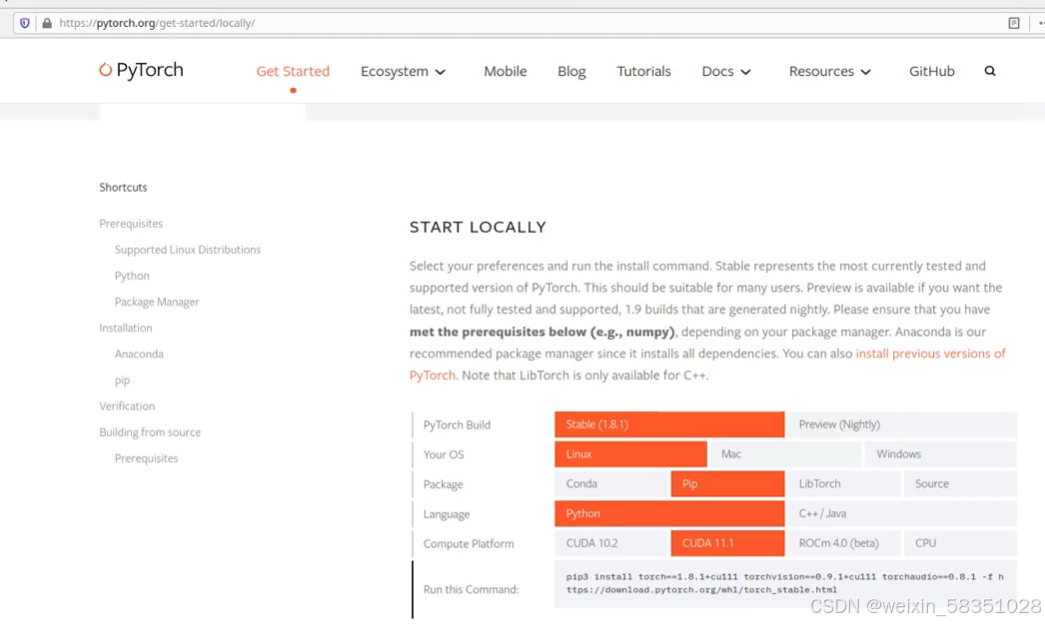
上图中的detectron2也是一个开源项目,它主要做检测与分割的。这些环境命令在linux环境中执行比较方便。然后安装pytorch,不同版本pytorch对应的cuda(可以根据cuda版本选择pytorch)与python版本是不一样的,要结合官方来安装,例如下图:
用命令下载slowFast代码下来:
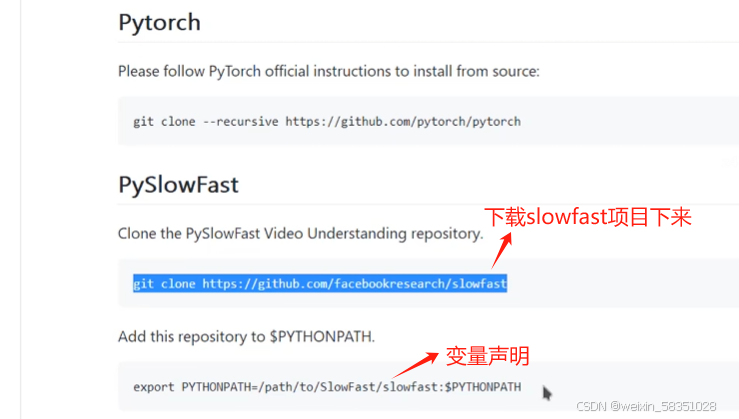
然后进入SlowFast目录下进行编译:
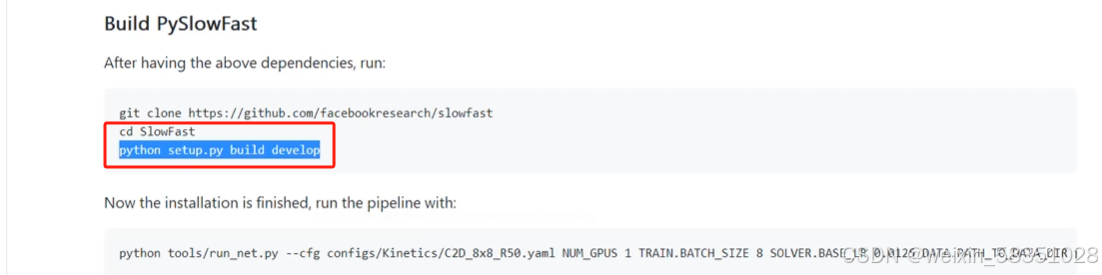
上面命令都是按官网来操作
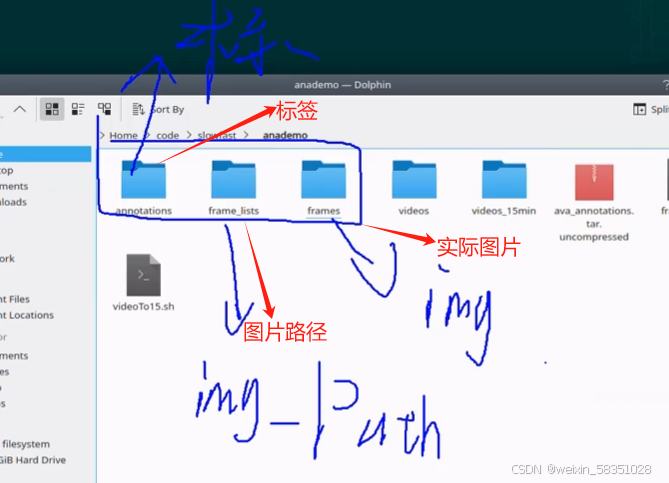
(2)目录各文件分析
本例就用AVA格式的,其它二个不用,
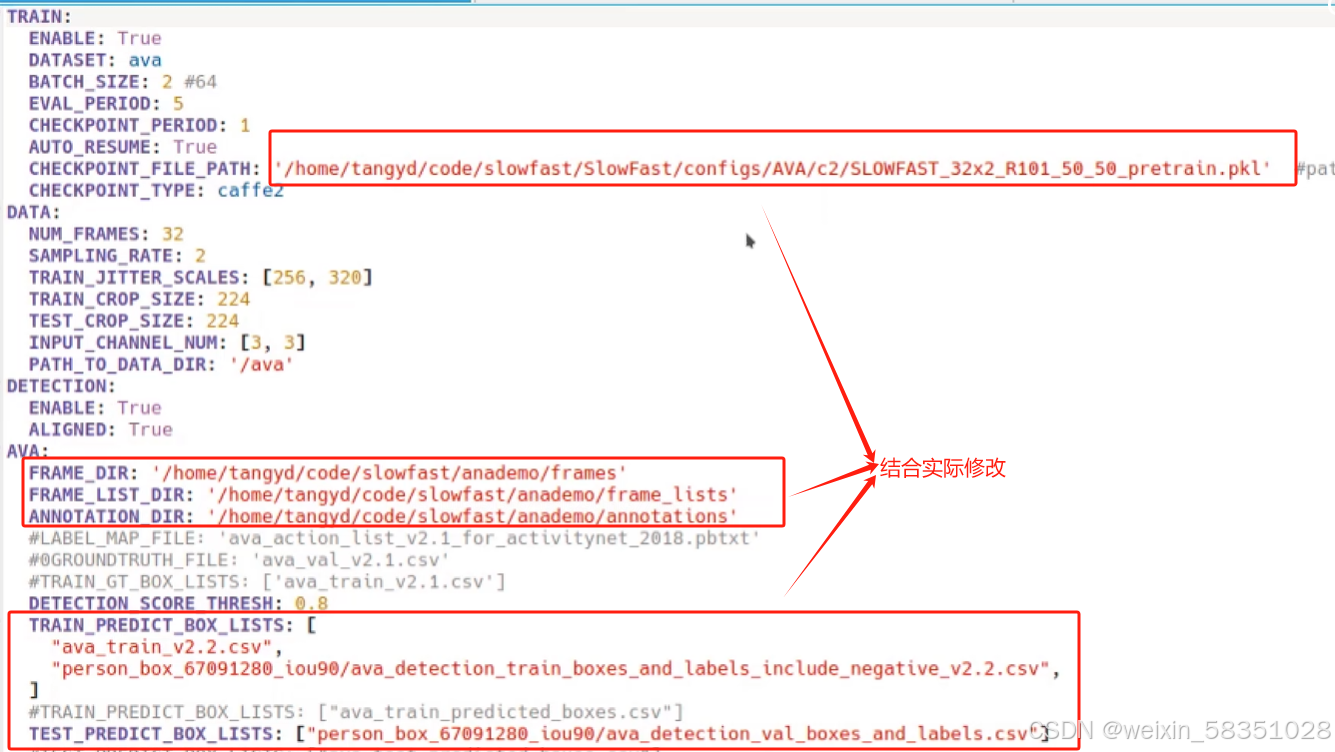
打开上图中的二个文件,做一些配置信息修改:

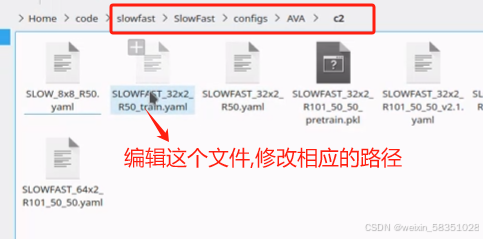
(3)配置文件作用解读
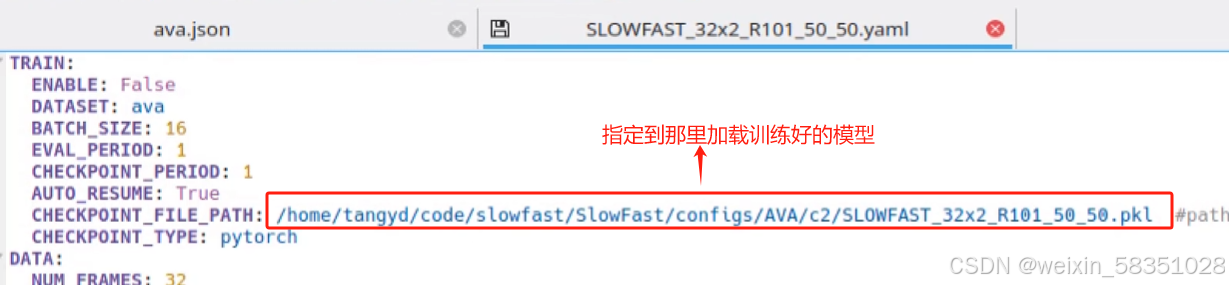
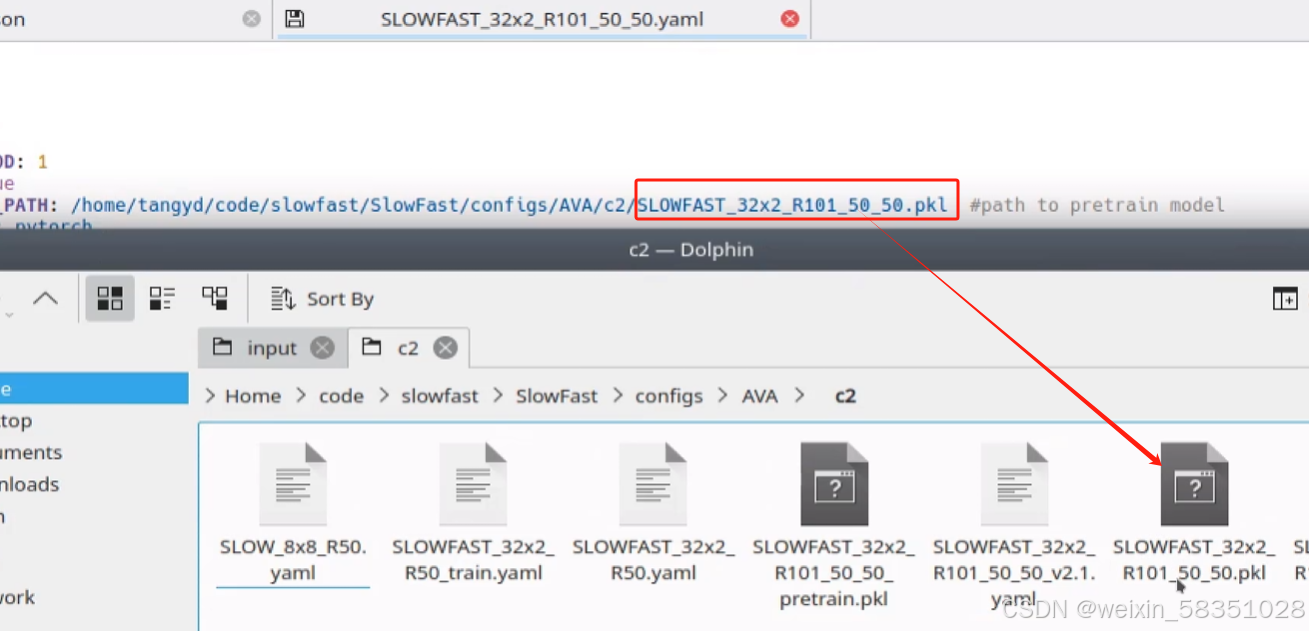
上图中.pkl模型有80个类别的训练好的动作的了,基本上能满足需求的了。
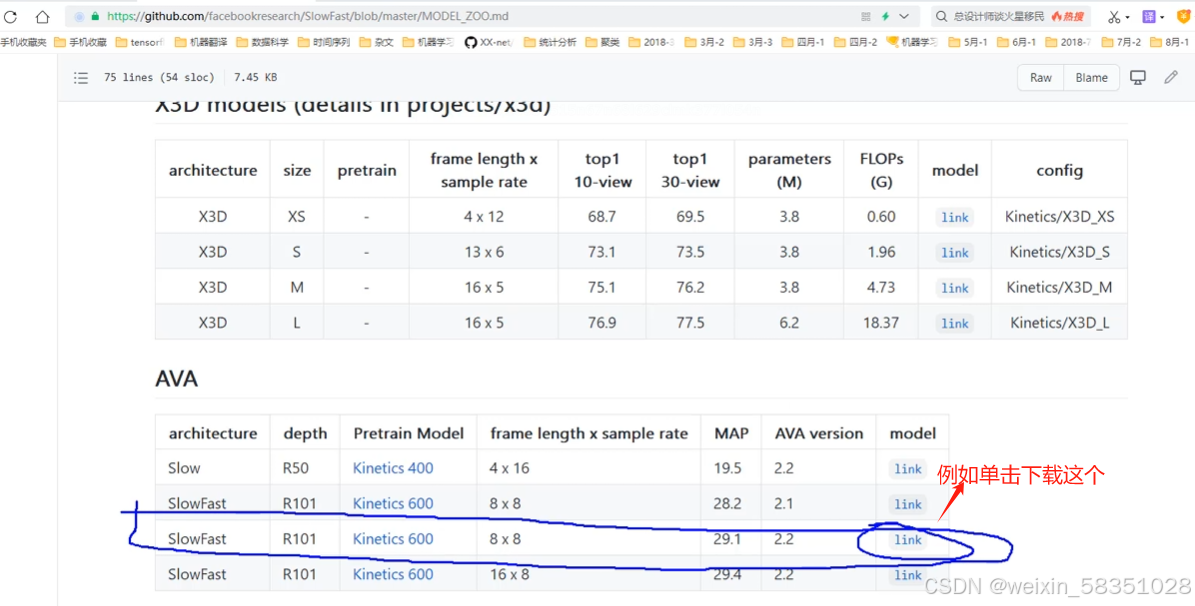
预训练模型也可以自己下载,例如:
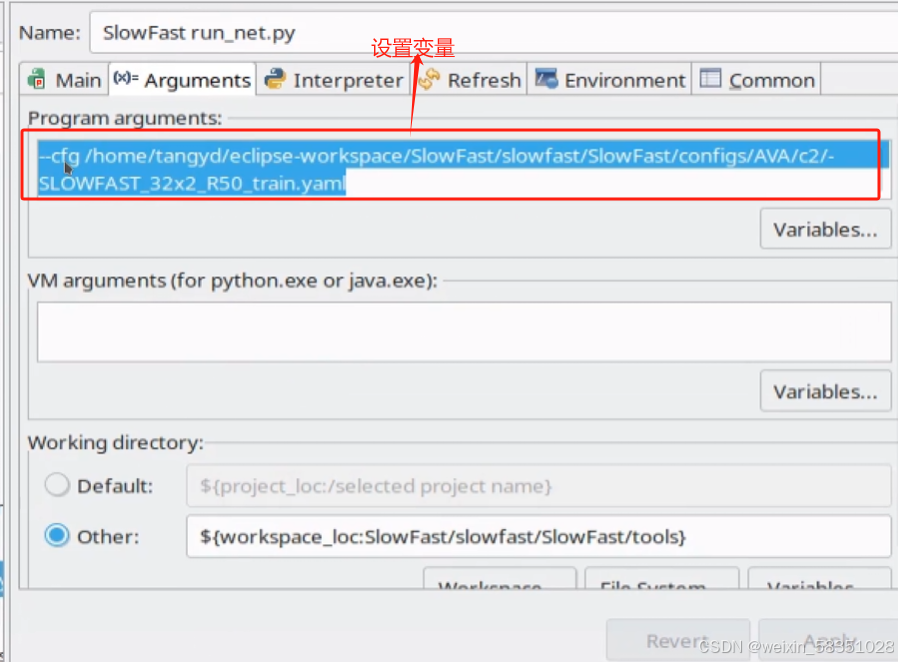
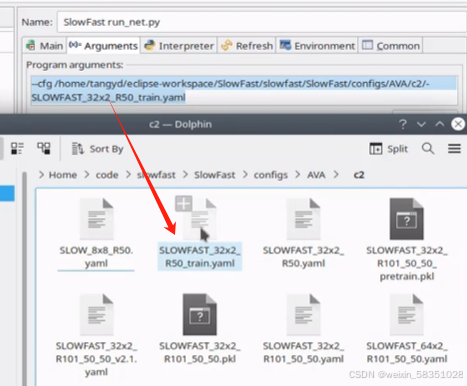
然后测试一下,执行执行入囗文件/tools/run_net.py,例如下图中的最后一行前半部分的命令:
即先进入SlowFast目录下,例如执行
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32*2_R101_50_50.yaml
如果执行正常,将会在配置文件中对应的output_file文件夹下生成新的视频,这个生成的视频就是会对源视频做各个行为动作的类别预测结果。
(5)训练所需标签文件说明
1)上面是直接用人家预训练好的模型,那如果自己想训练模型,怎么做呢?通常的做法是要把数据与标签做好后(配置好)进行训练。
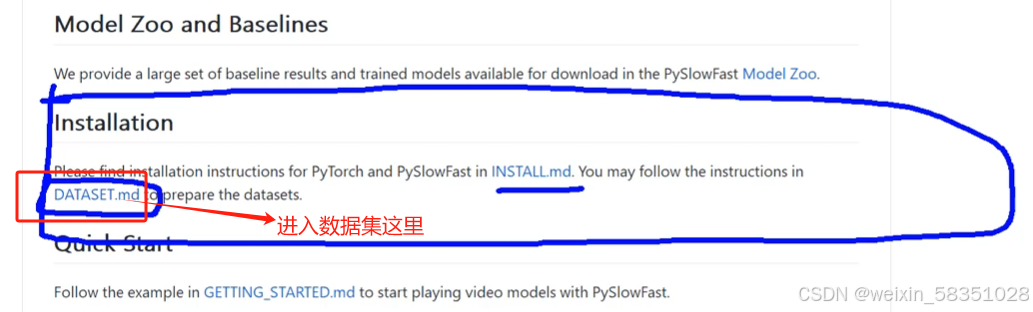
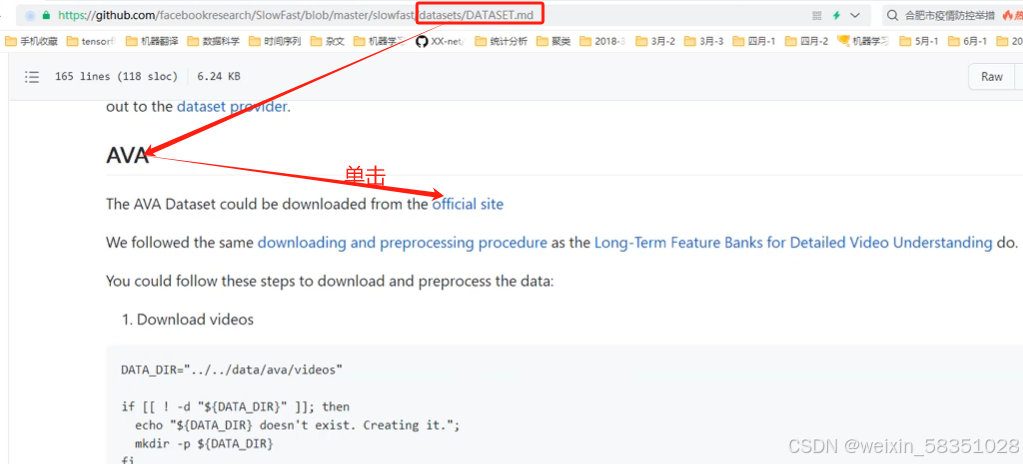
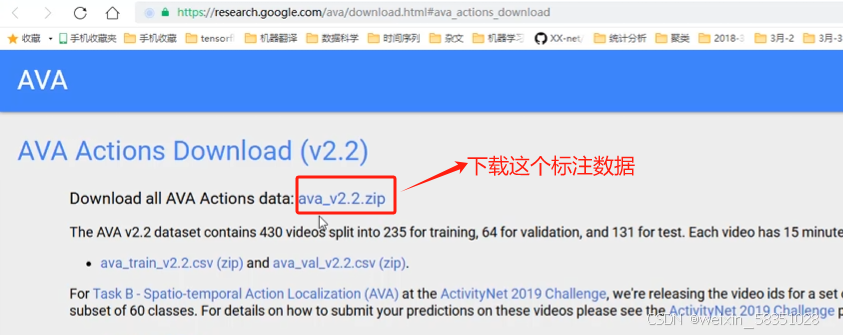
解压出这个zip文件后,会见到很多个.csv格式的标注数据,但不一定都全部需要:
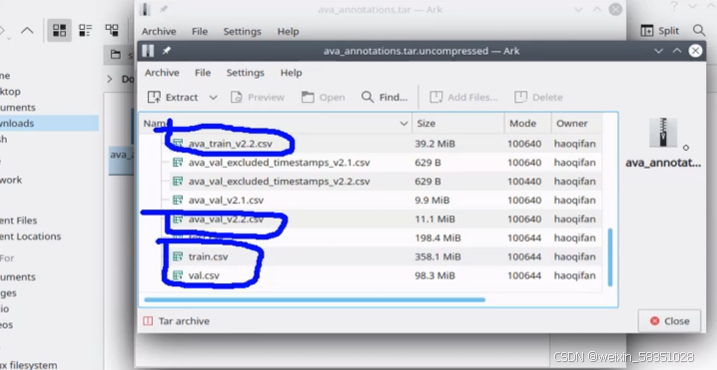
点击这个标注文件夹后进入如下图:
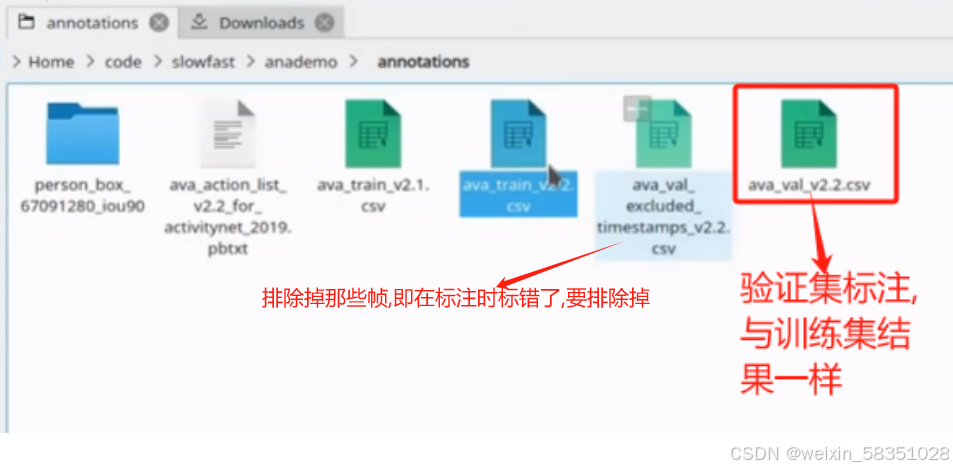
2)先打开annotations文件夹。
上图中annotations是用来上面所说的csv标注文件的,例如下图所示:
然后先说ava_train_v2.2.csv这个标注文件:
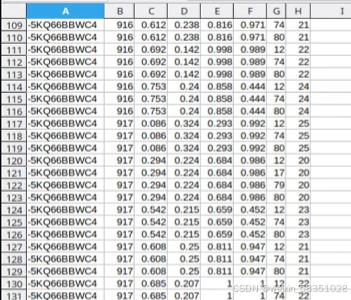
现在对这个标注文件每列进行解释:
A:video名字(视频名称),B:从那一秒开始,C:x1,D:y1,E:x2,F:y2,(x1,y1,x2,y2表示一个人的框),G:表示行为标签(例站,走,说话,看,跑等对应的标签值),H:表示人的ID,指具体那个人。上图标注数据中可分析出某个人在某个时间点在那个位置做什么东西(时,地,人,事)。
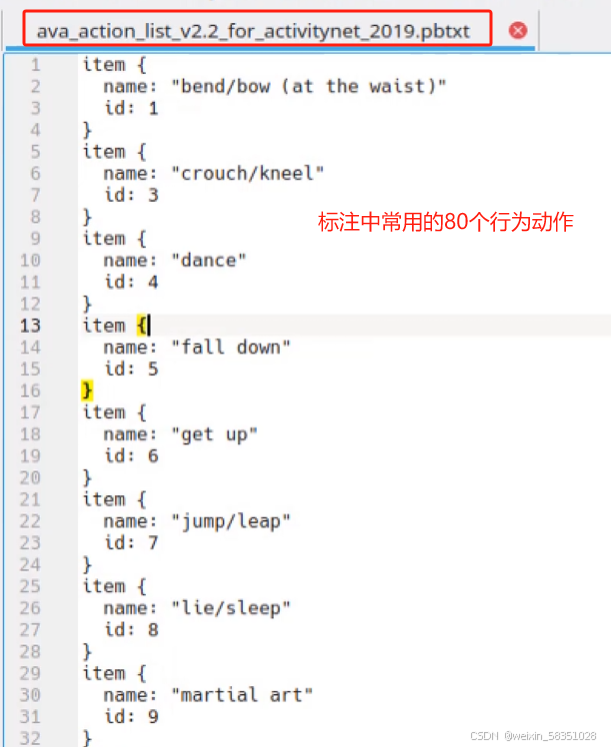
打开.pbtxt文件,如下图:
3)打开frame_lists
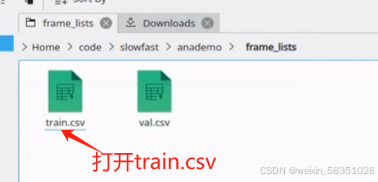

上图中frame_id是指这个视频下的第几帧,而path是指第几帧对应的图片,图片是借用工具切割出来的。这样若要取那一帧下的图片就很容易找出来或者按图片找到对应那一帧。像它提供的视频有训练集,验证集,测试集三种视频,容易还是蛮大的。
(7)视频数据集切分操作
刚才说到github上提供了430个视频(训练集,验证集,测试集),我们可以指定视频名各下载一个下来即可。步骤如下:
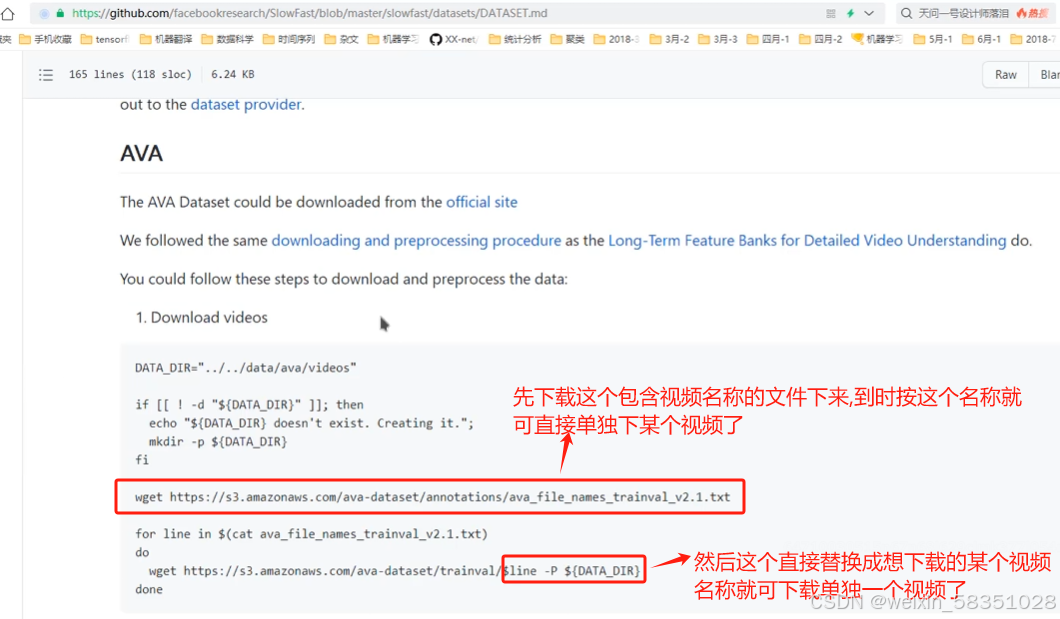
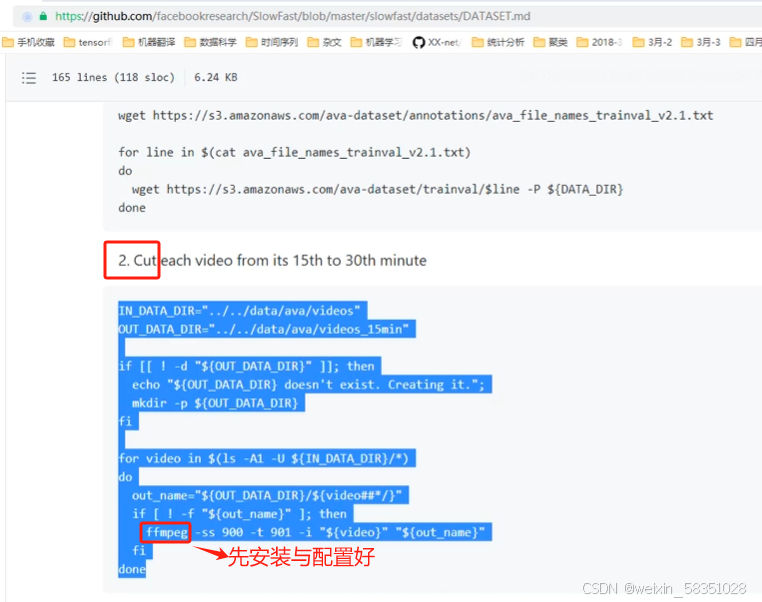
上图中的切割视频的ffmpeg工具要先安装并配置好,用ffmpeg就不用opencv了,opencv还要写代码。
把上面这这些语句复制到videoTo15.sh,和刚下载下来的视频同一级文件夹。
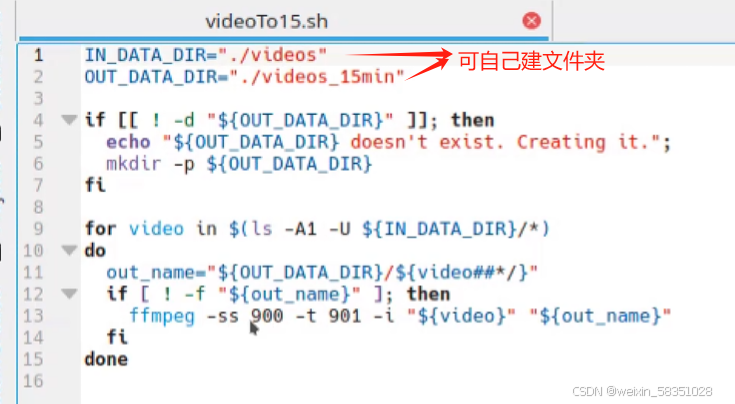
然后在linux上执行 sh videoTo15.sh 后就会把videos中的源视频切到输出到videos_15min文件夹下
(8)完成视频分帧操作
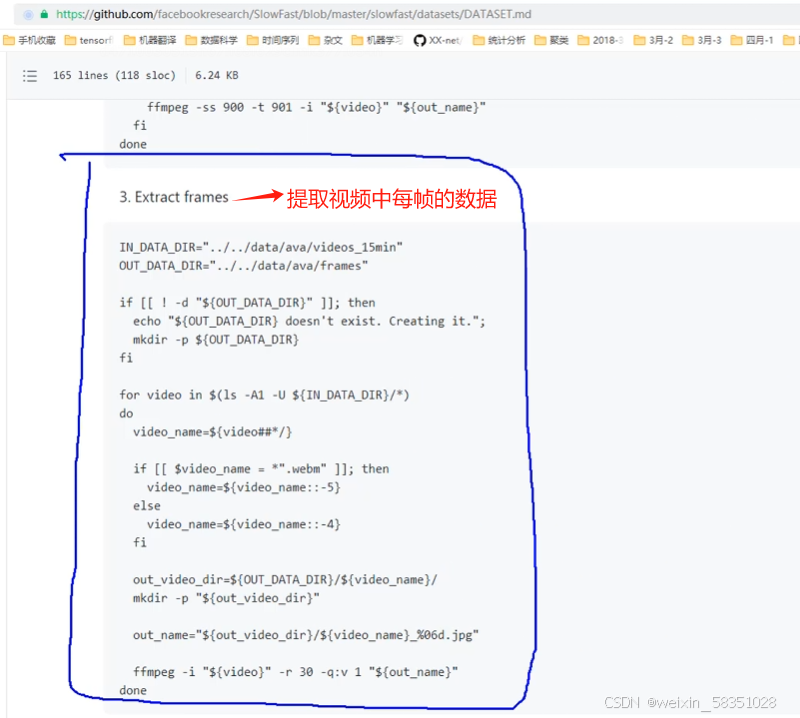
把这部分代码复制到frames.sh中去,其中IN_DATA_DIR是指输入路径,OUT_DATA_DIR是输出路径,结合实际情况修改。
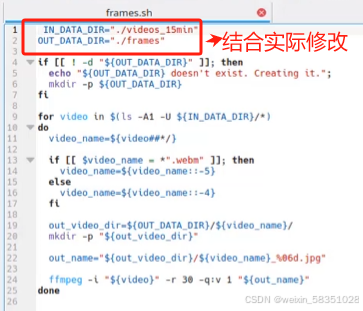
执行 sh frames.sh后就会在相应的输出目录生产出大量的每帧的图片,如下图:

有前面标注内容后,download annotations就不用执行。
这时就可以进行训练了。
二.slowfast源码详细解读
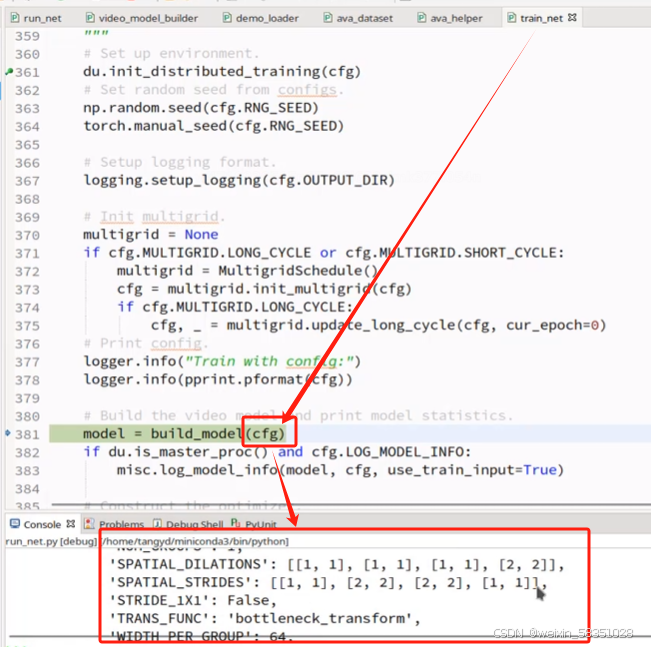
(1)模型所需配置文件参数读取

(2)数据处理概述

源代码中是先说构建模型,再把数据集搞进这个模型中来的顺序。现在我们反过来分析,按先看数据集的处理(loader),再看模型文件的构建,所以现在不看build_model方法先。现在进入到的train_net.py文件中loader.construct_loader方法来构建训练,验证数据集,如下图:
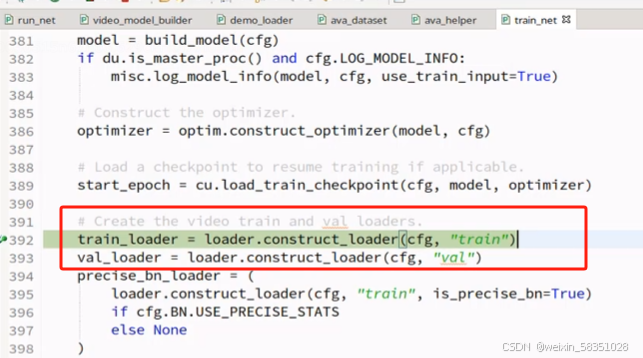
然后进入这个py里面,如下图:
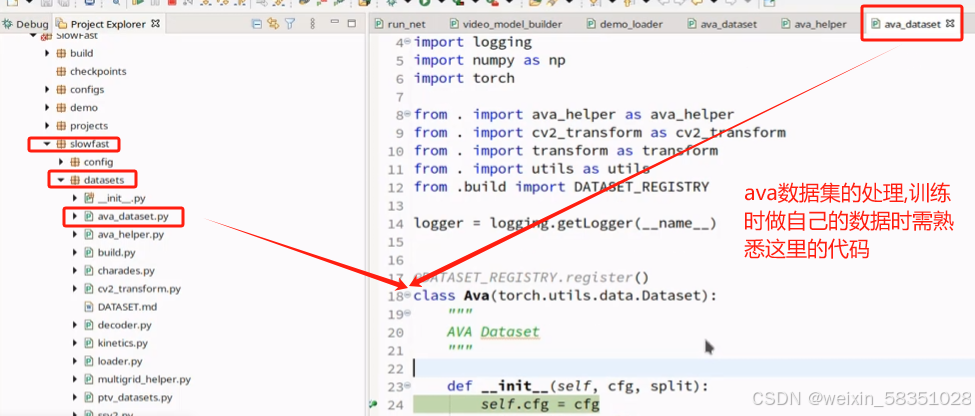
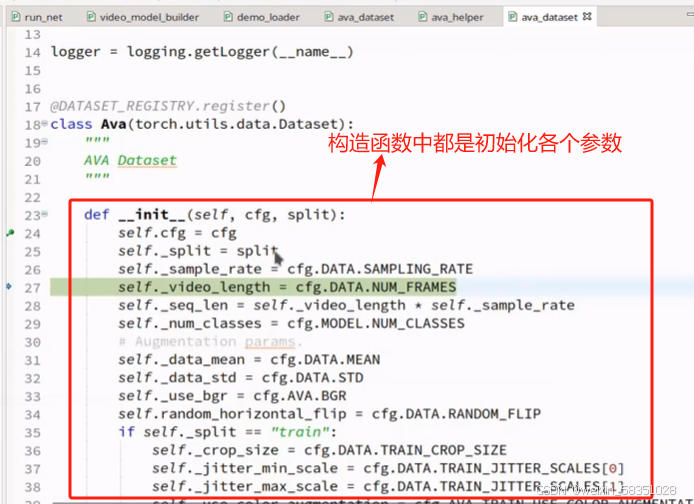
初始化参数后,现在进入__getitem__方法是重点了,__getitem__主要是对输入的数据构建好,取出来准备好,到时给模型前向传播时用。一般情况模型前向传播过程时才进入到dataLoader中取数据。
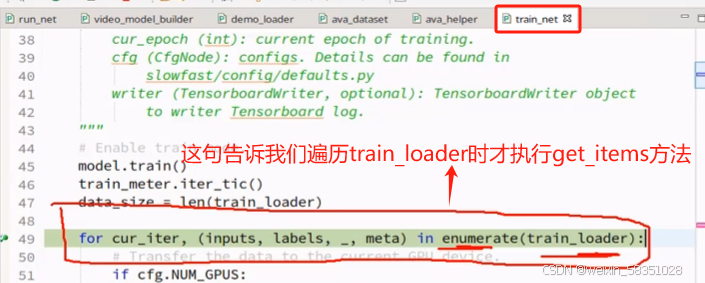
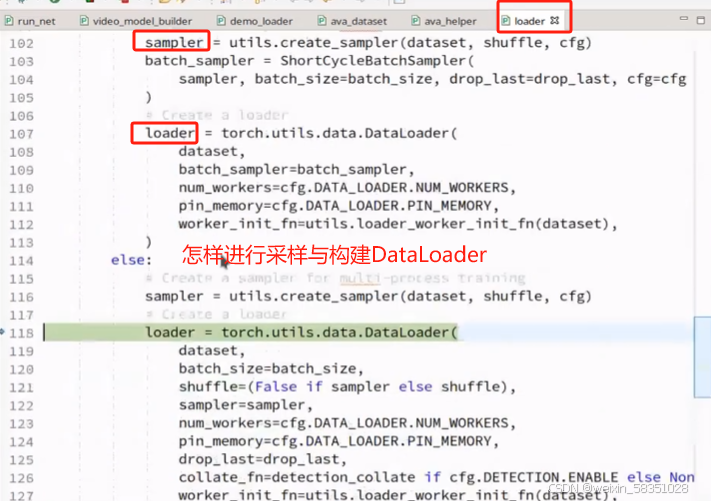
(3)dataloader数据遍历方法
调用__getitem__方法读数据前,先调用ava_dataset.py中的_load_data方法加载数据进来,如下图:
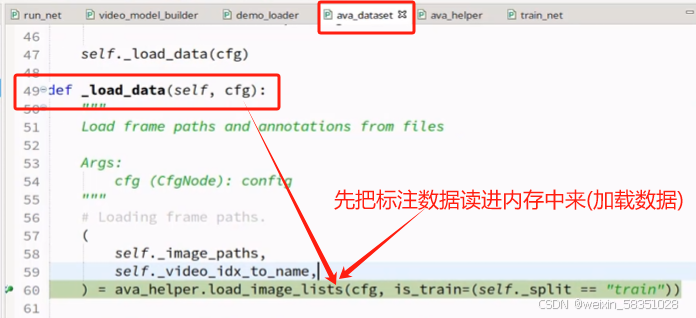
load_image_lists方法返回的主要是对应帧,图片与其路径,到时候就可传入视频中的某些帧可找到相应的图片与路径。
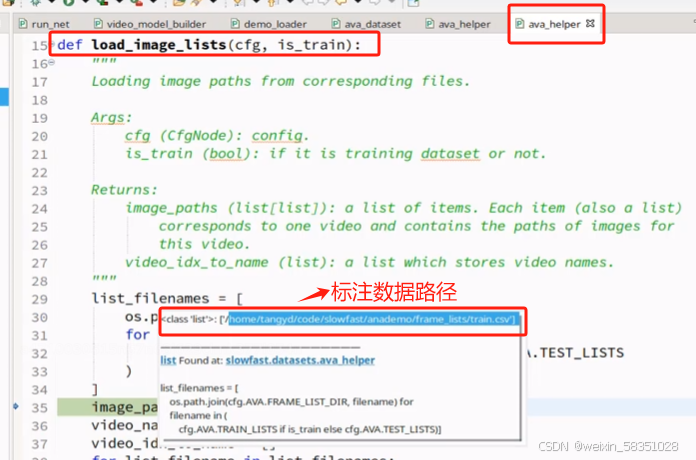
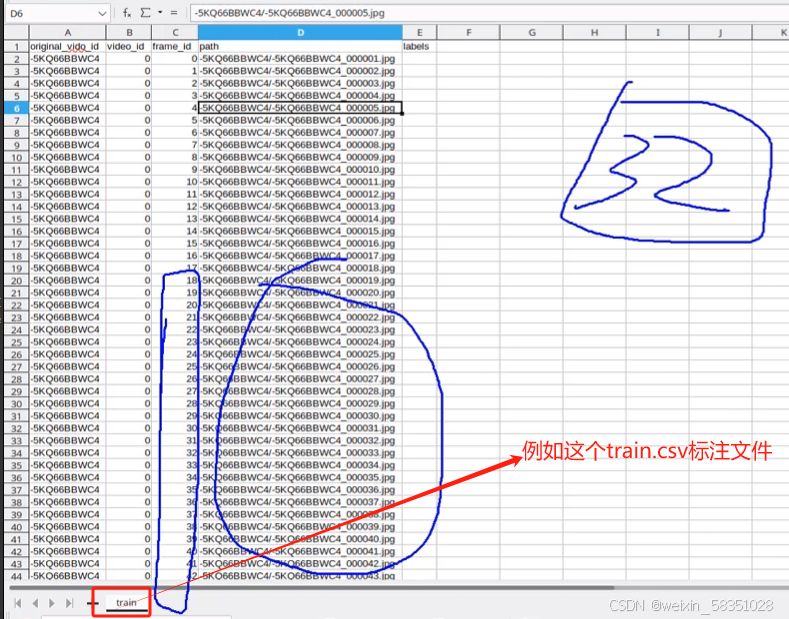
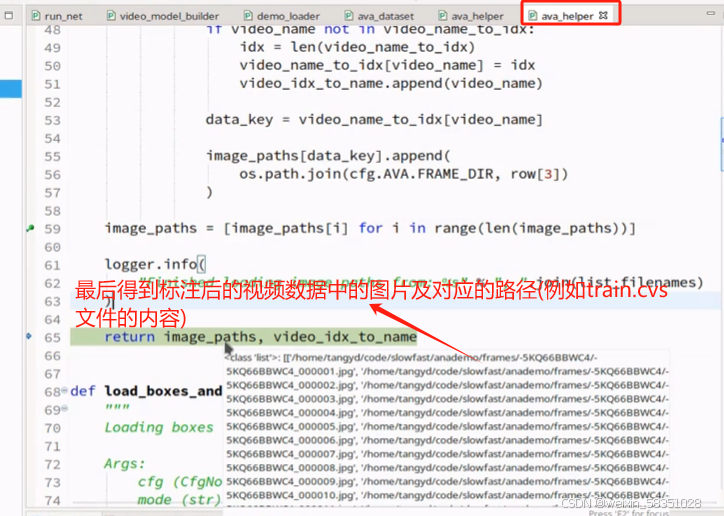
load_image_lists方法读取csv数据到内存就到此结束。标注数据也是一样的,即把csv中的数据读取到内存中。
(4)数据与标签读取实例
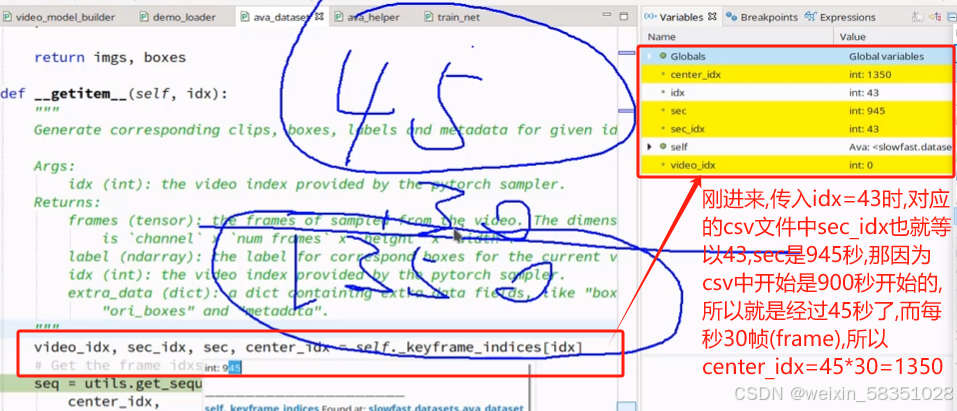
上图中945的数据与标签都可以找到了.
(5)图像数据所需预处理方法
而得到center_idx就可以找到前,后加上多少帧后一共组成32帧的序列数据了,如下图:
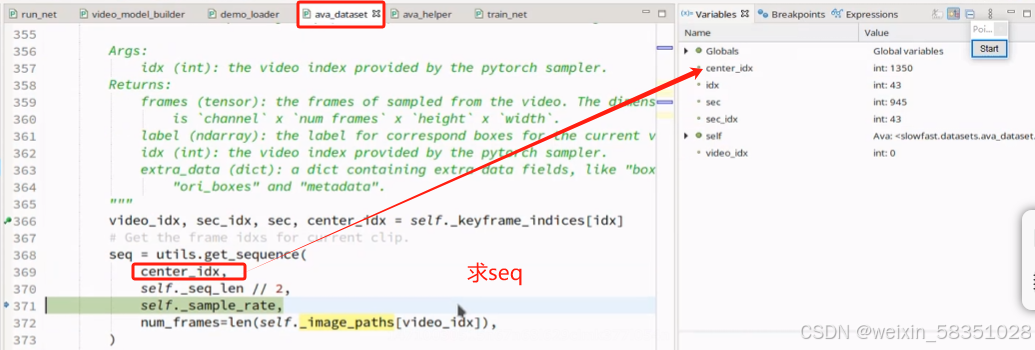
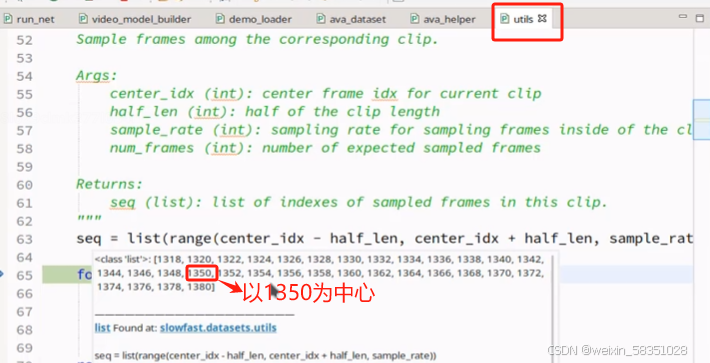
上图seq就是得到以1350为中心得到32帧的序列
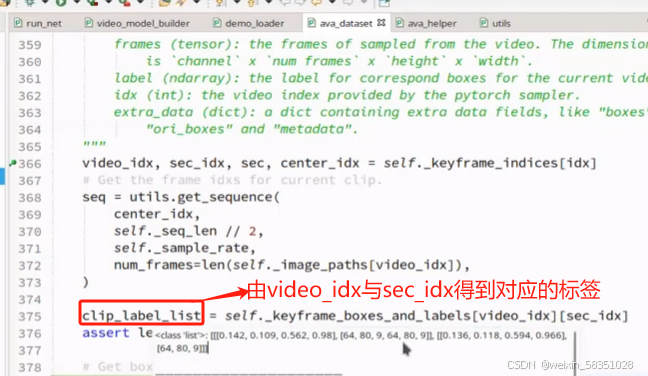
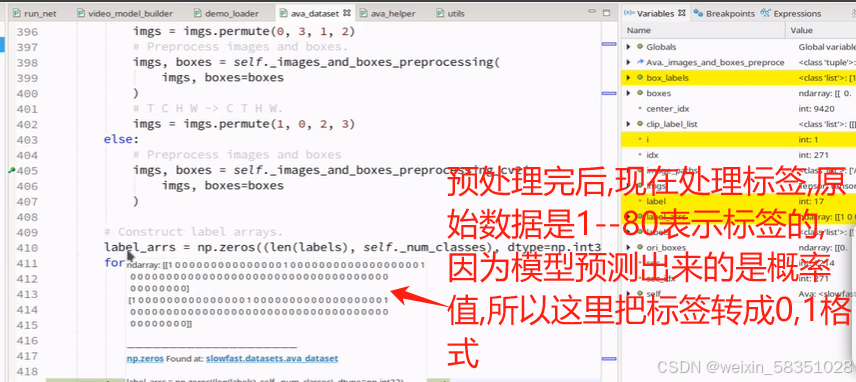
clip_label_list中主要得到的是中间帧(例本例的1350)那一组对应的坐标框与动作等标签,到时候就用中间那一帧(不用每帧都去取)的坐标框去原始图像中取特征,人在变动也许取的特征与原始图像有一点点出入(例如也许会取到更大的区域,会有背景),特征图放大后会比对应的原始范围更大,例如下图所示:
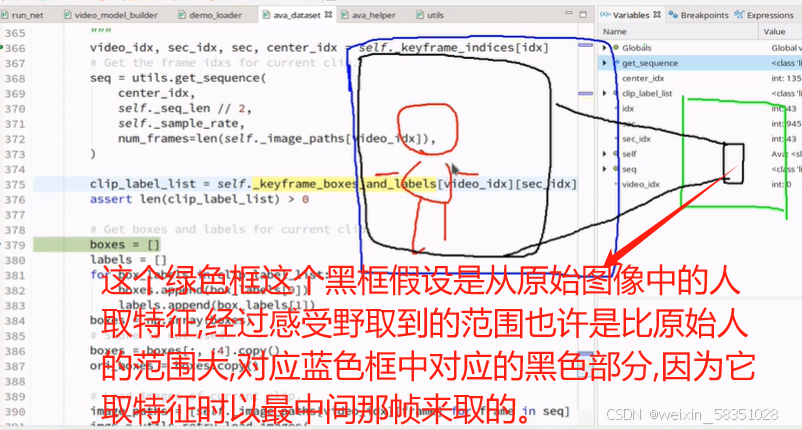
所以说为什么32帧的只取中间那一帧的坐标框与动作等标签(上图clip_label_list中的值)的原因。
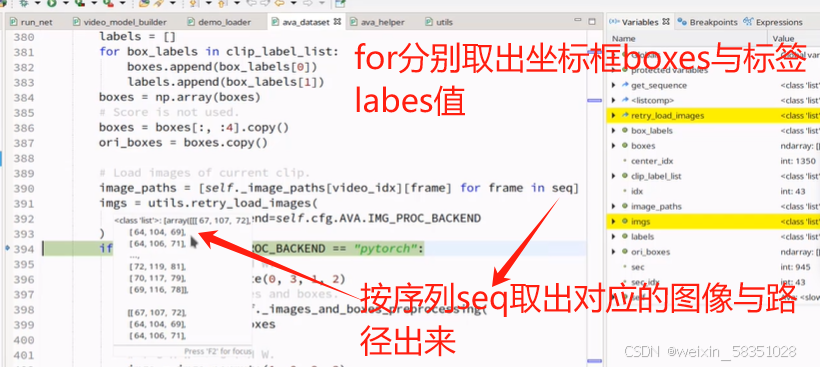
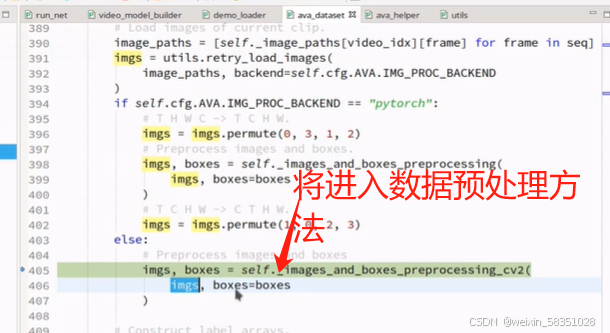
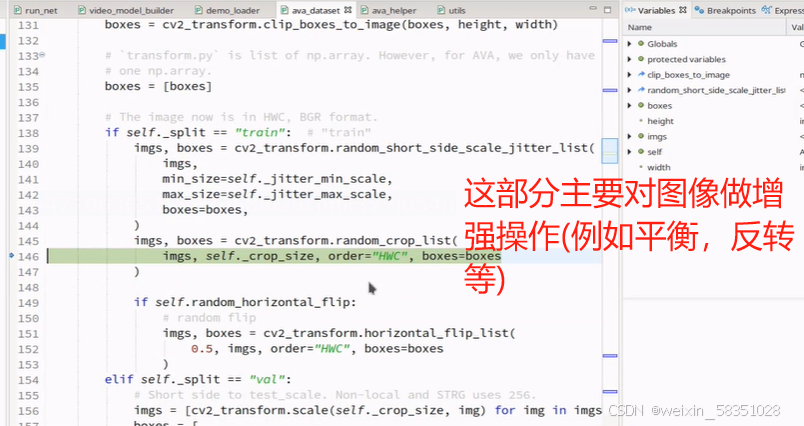
上图中不但是对图像进行增强操作,同时boxes框也要同步增强。
最后还要对图像做归一化,如下图:
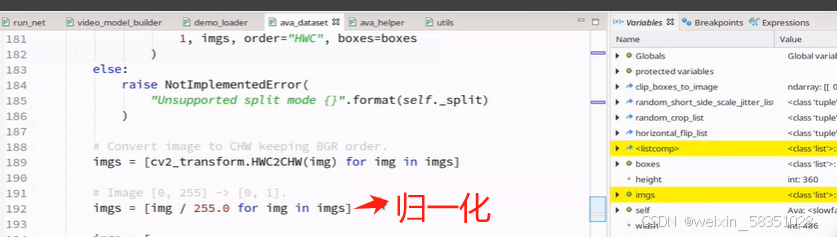
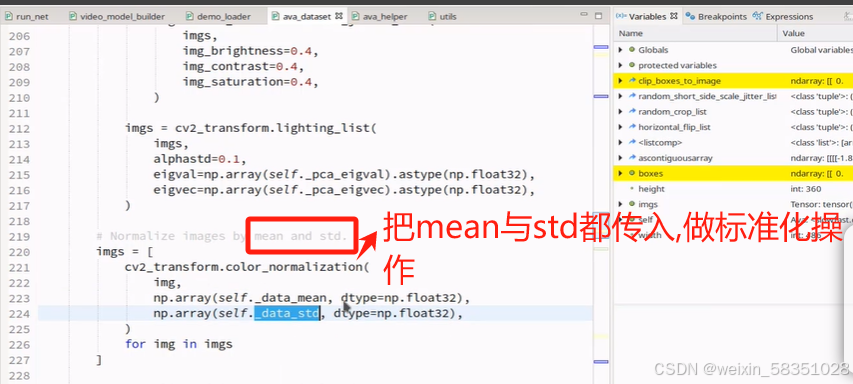
得到图像imgs与框boxes内容后,图像数据的预处理就完成了。
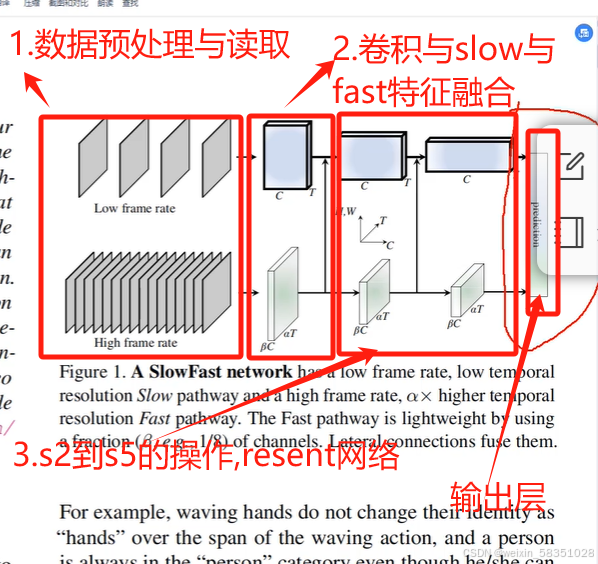
(6)slow和fast分别执行采样操作(网络模型定义模块)
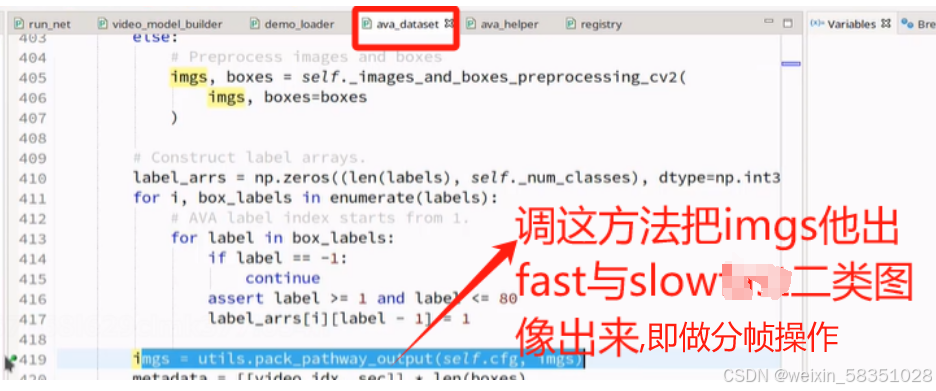
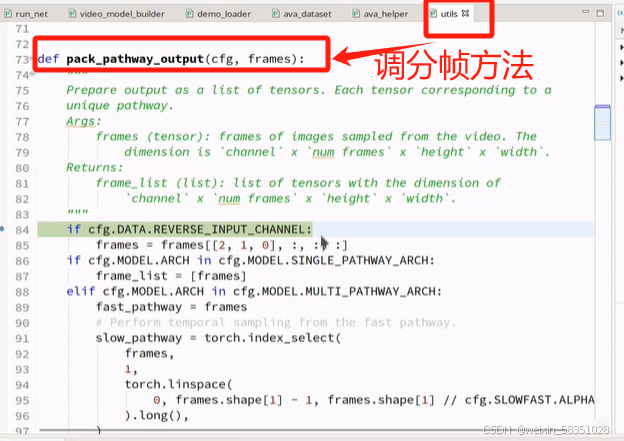
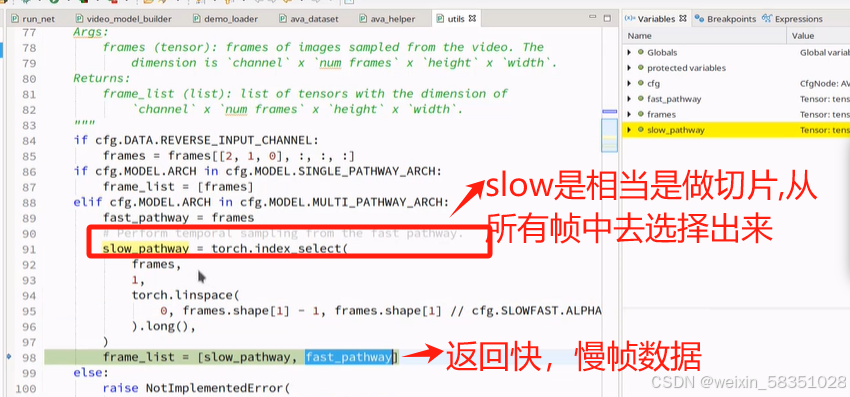
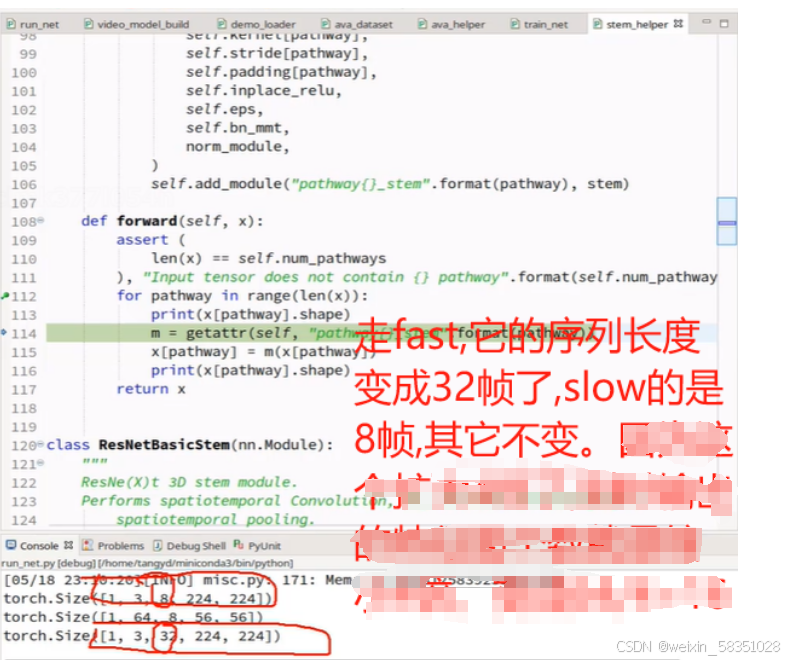
上图的分帧出来fast与slow图像其实也相当于是做了采样操作。
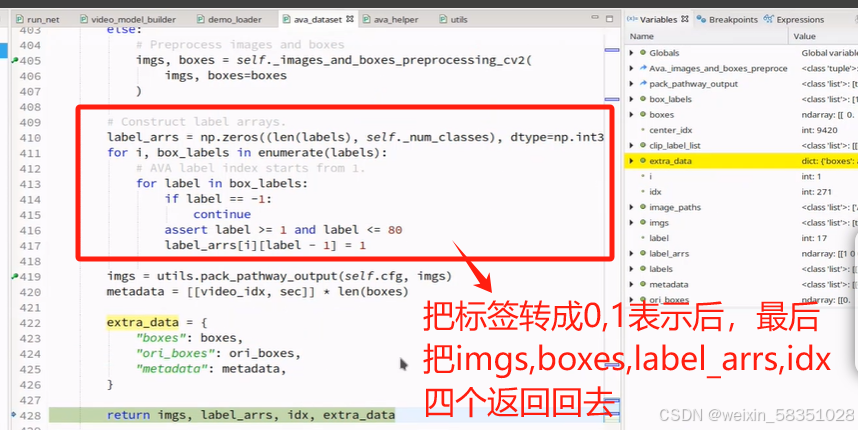
返回的imgs是指分成fast与slow二类图像后的list,到时传入到网络结构中去。到此时就完成了__getitem__的方法了,它主要是做了数据预处理与取对应的图像,框坐标与标签值。这时data_load就完成了,如果有自己的数据集最好把它转成AVA格式(csv中的数据格式)来,不要去改源代码。
数据读取成功后,下面开始进入网络模型定义模型,如下图:
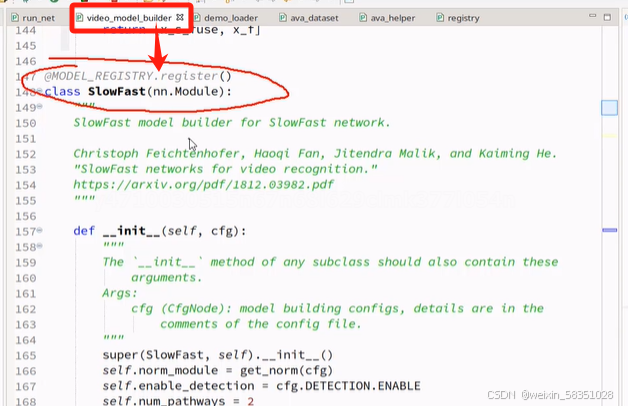
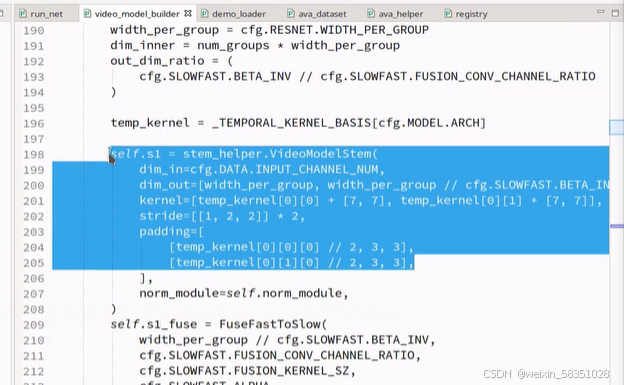
SlowFast的__init__构造方法中主要是对网络模型各层的定义。现在主要看forward前向传播方法,这方法里会实际执行构造方法中所定义的网络模块(即来了数据后,网络中各层是怎么处理的)。
(7)分别计算特征图输出结果
紧接上面内容,进入到SlowFast的前向传播方法forward中,开始走S1:
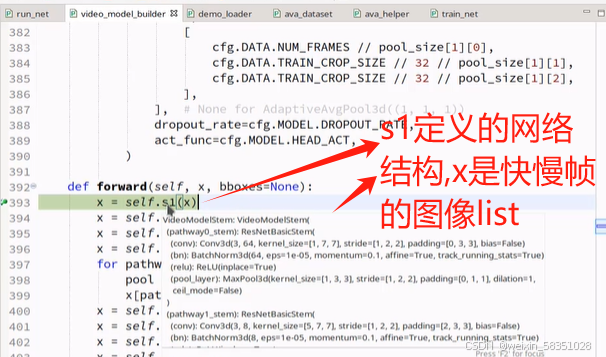
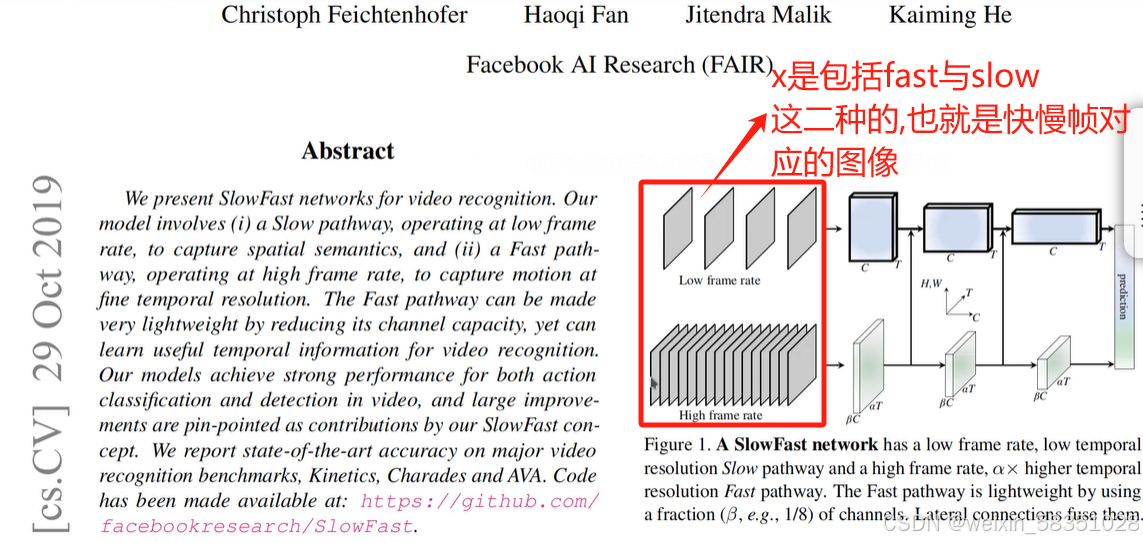
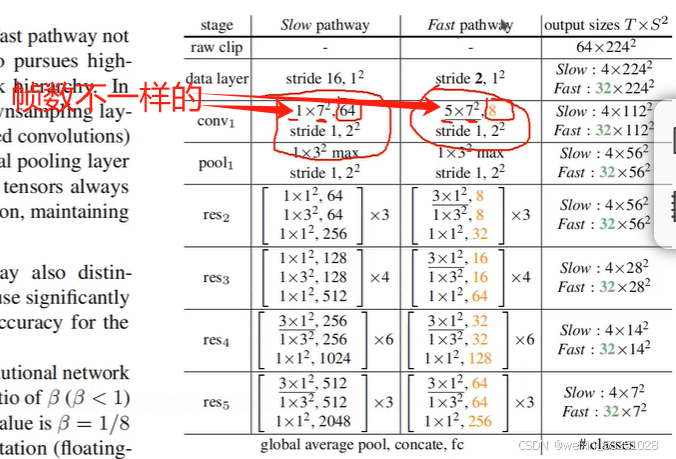
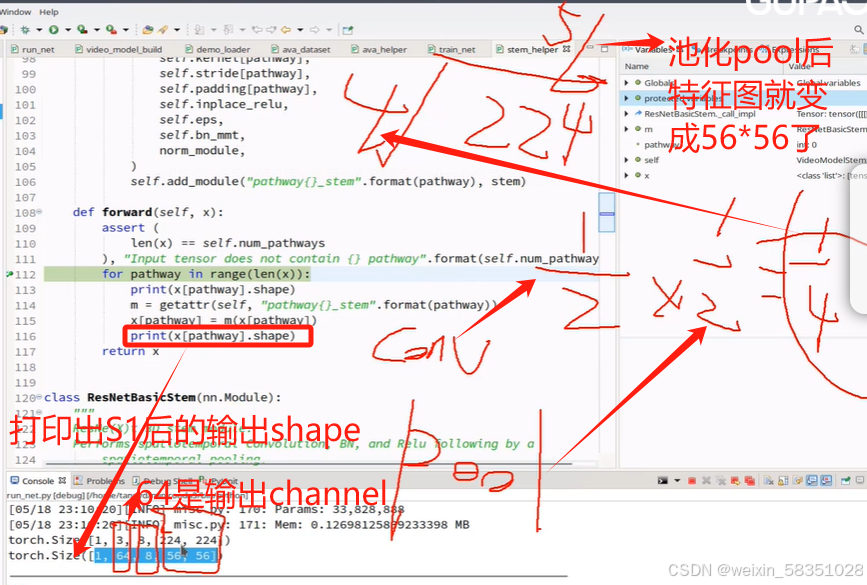
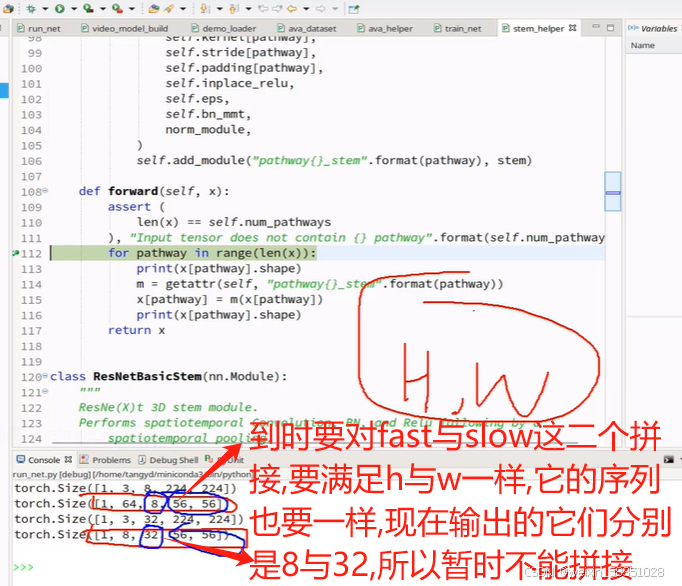
上图中取的帧数不一样,所以输出的特征图个数也肯定不一样的(本图的conv1层中输出的特征图个数分别是64与8).
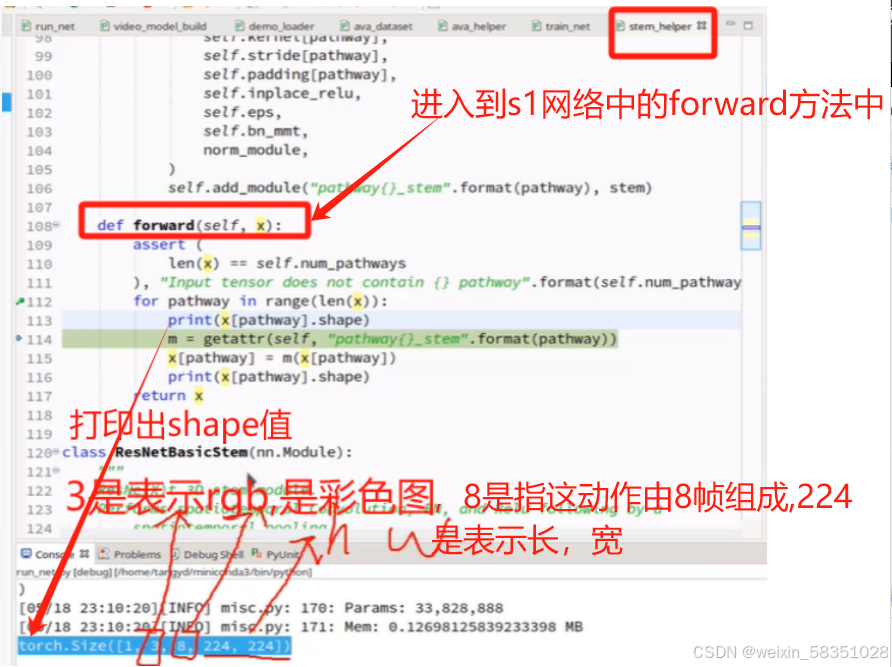
上图中的3解释错了,它不是表示彩色图,不是rgb的意思。3是指input channel。
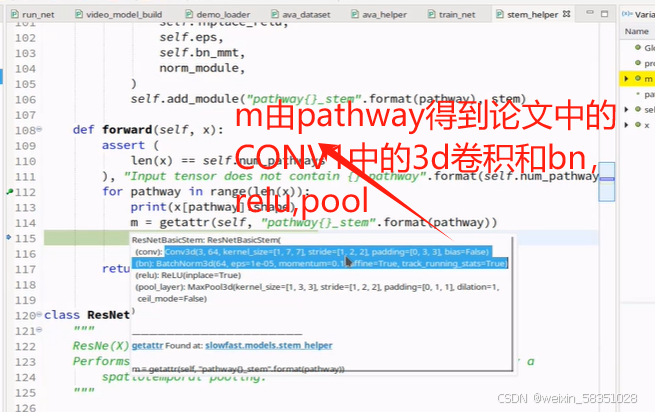
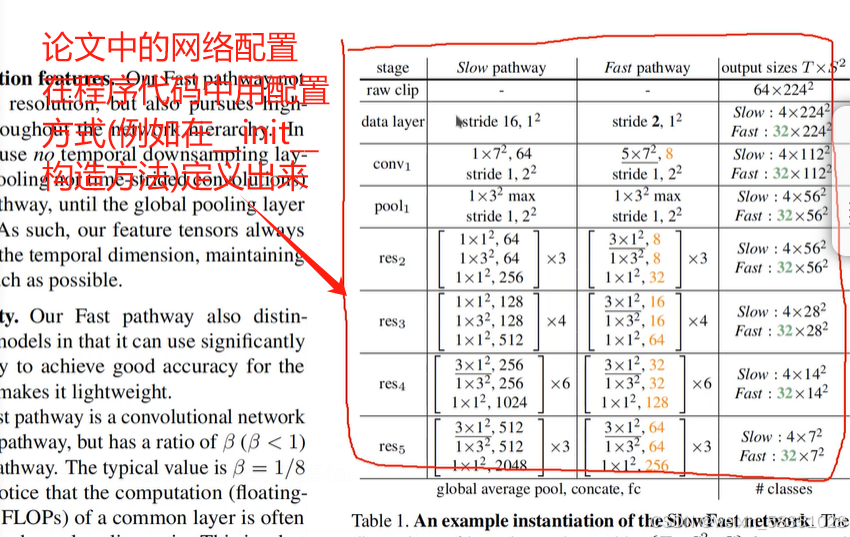
上图中为什么是用3D卷积,因为它是多一个时间维度的(例8帧),由上图可知道S1完成论文中如下的操作,如下图的红色部分:

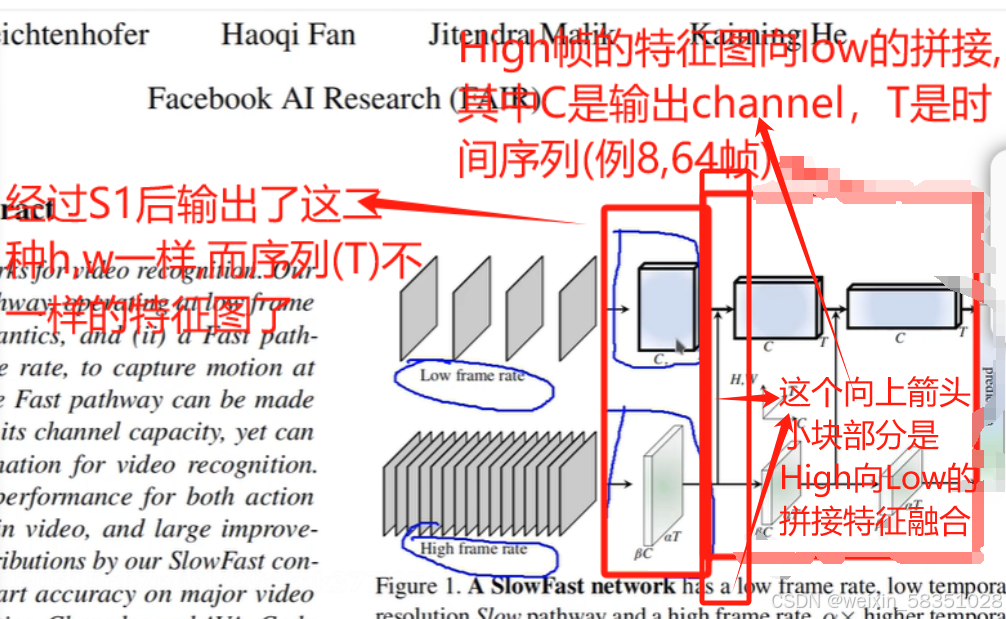
slowfast当中很重要的一点是在时间上联系动作的东西,还要在空间上联系语义上的东西,到时要进行上图中所说的拼接操作(时间上与空间上信息的拼接),如下图:
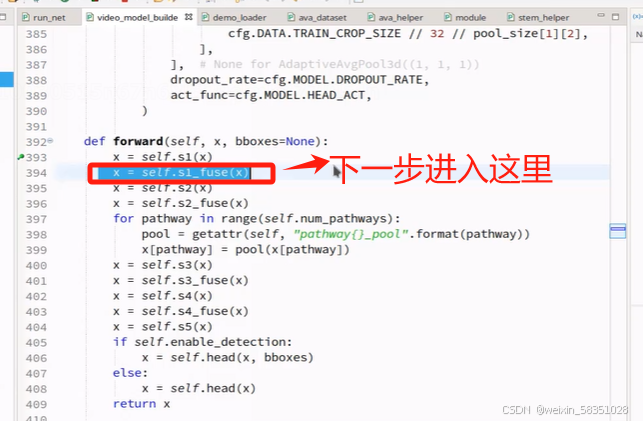
上图中的s1_fuse是fast与slow的融合操作,融合之前必须保证规格一样(图像大小与时间序列一样),也许会说reshape操作来改变规格,但是reshape会丢失信息和不能学习,所以本例中不是用reshape来改变规格的,而是再走一个卷积,让它们两的输出结果匹配即可。现不看定义直接进入它的前向传播forward方法中去。
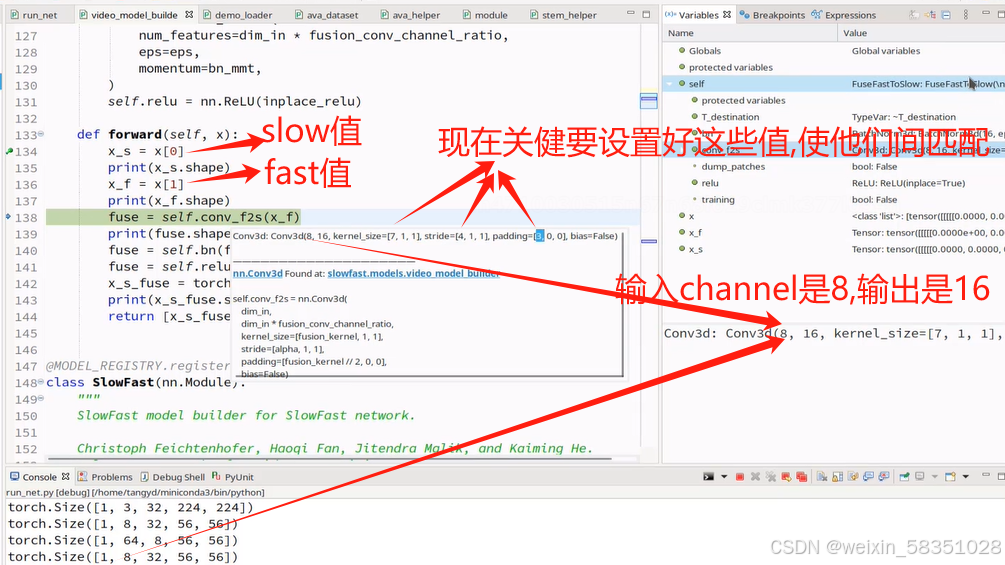
上图中设置好这三个值()后,就按这样计算的,它的序列是32,所以有 ((32-7+2*3)/4)+1,这值约等以8,所以到时输出shape中的序列值就由32变成8了,这样就从时间维度进入改变,使32帧变成8帧;output_channel值就是16,如下图:
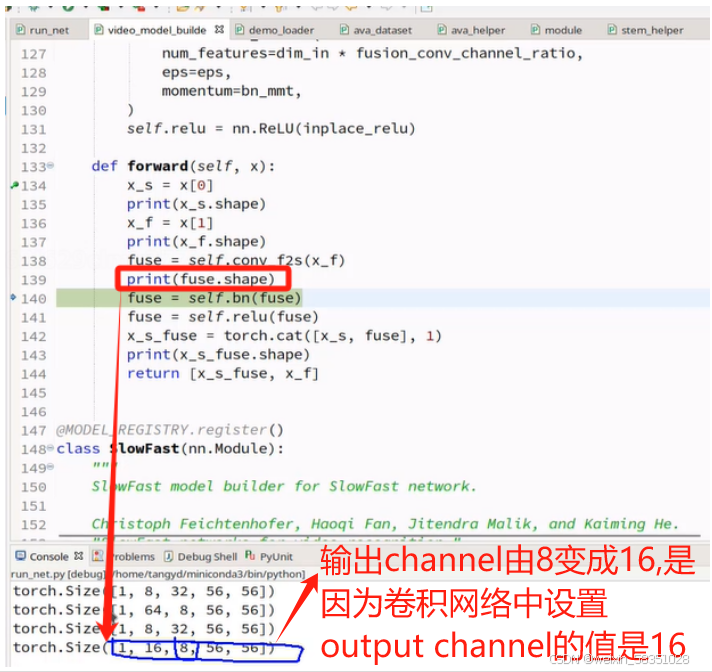
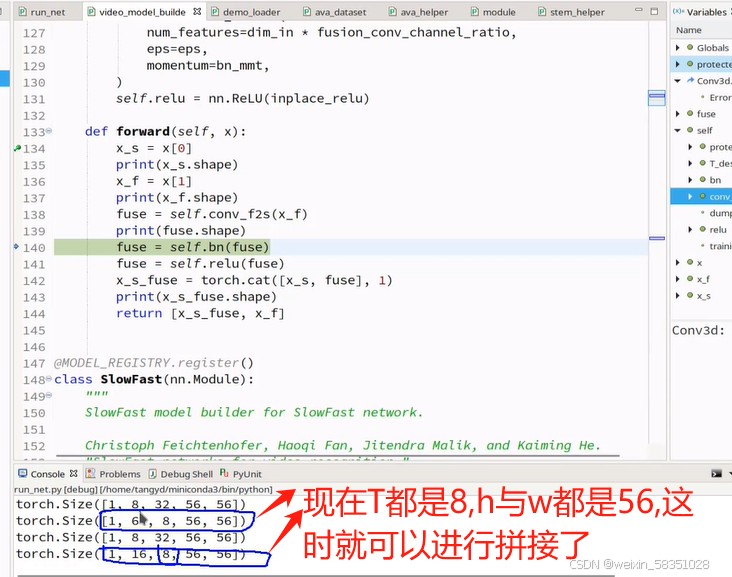
这样二个拼接后,特征图个数就是64+16=80了(上图64中的4被鼠标挡住了),帧数与图像大小一样拼接后,特征图个数增加。如下图: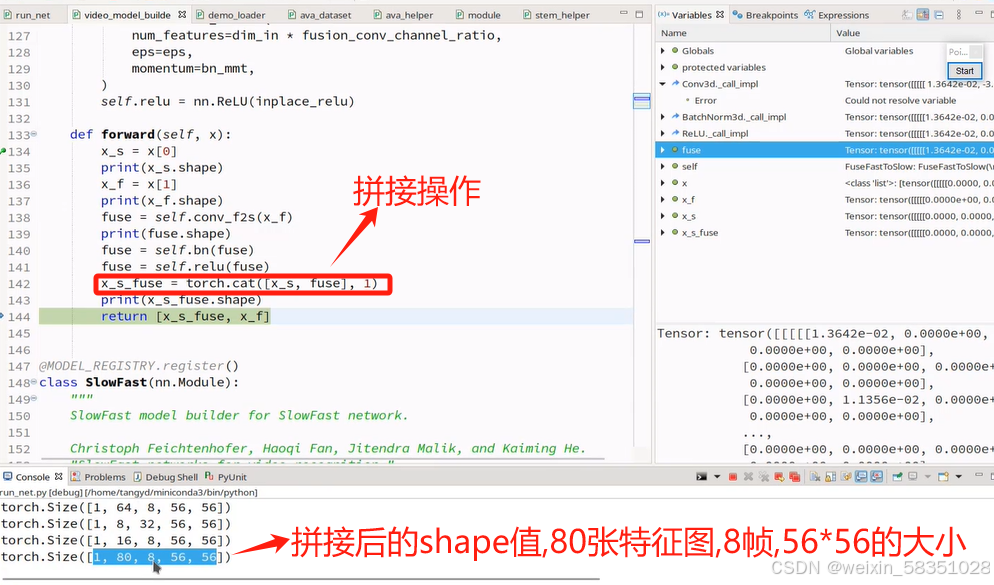
至此s1与s1_fuse融合操作就走完了。
(9)resetBolock操作
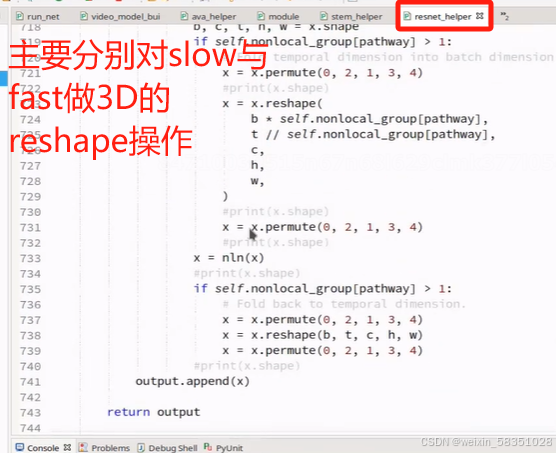
下面开始走s2与s2_fuse,s3与s3_fuse,s4与s4_fuse,s5操作,它们都是一样的操作(3Du卷积与特征融合拼接),只是参数不同。现在就直接看s3吧,单击红色方法进入到ResStage:
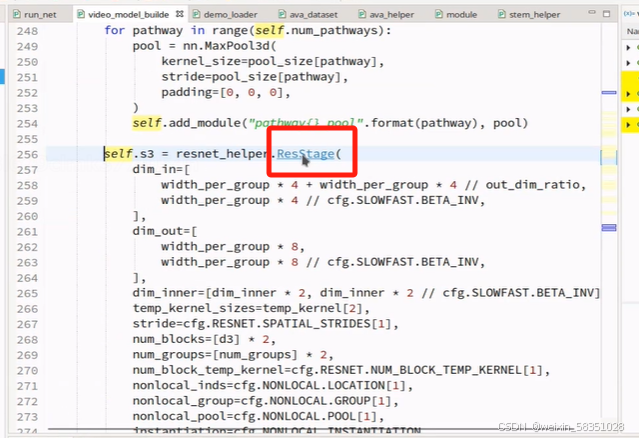
进入对应的forward方法中,
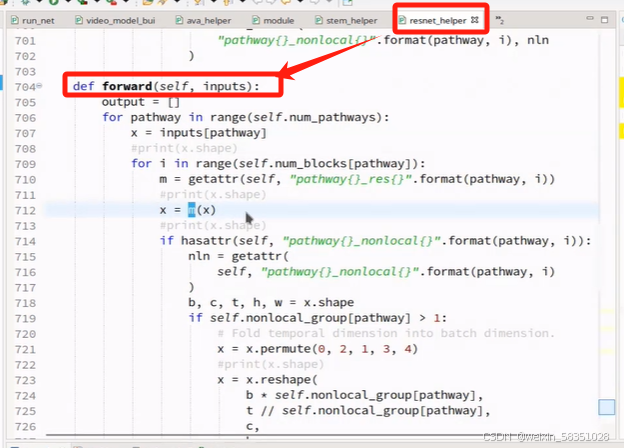
然后就看输出层head,如下图:
前面的s2,s2_fuse至s5部分做的是论文中下面的第3点:
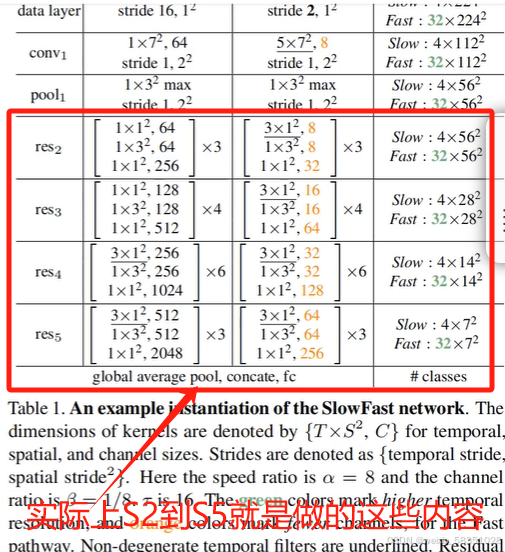
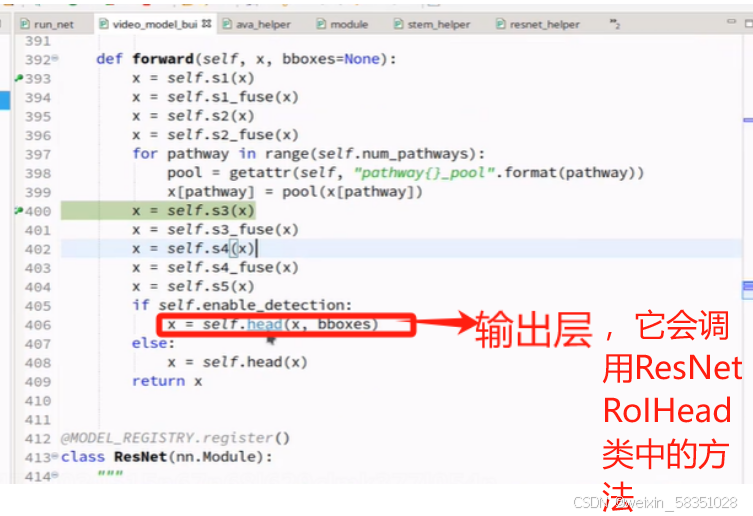
现在进入到输出层的类ResNetRoIHead中的forward方法中,如下图:
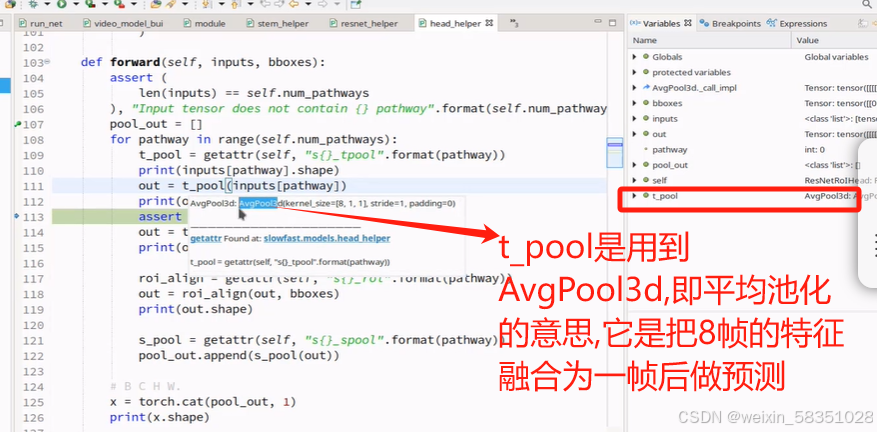
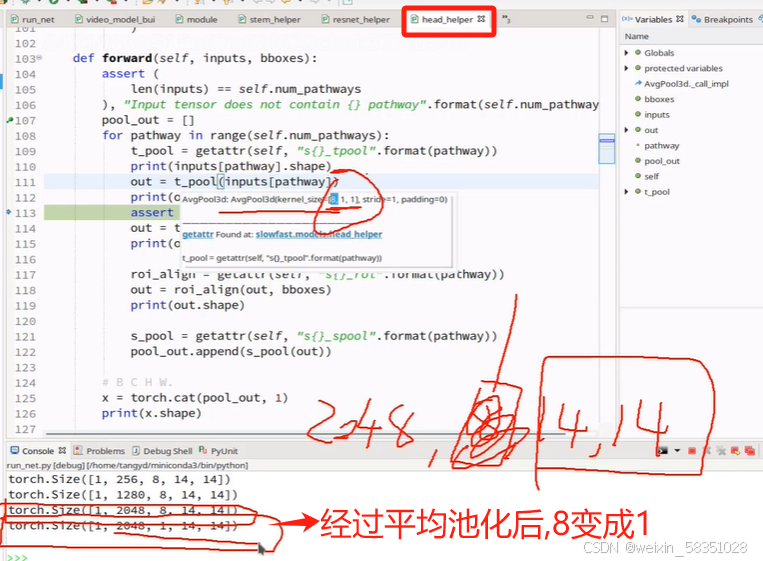
(10)RoiAlign与输出层
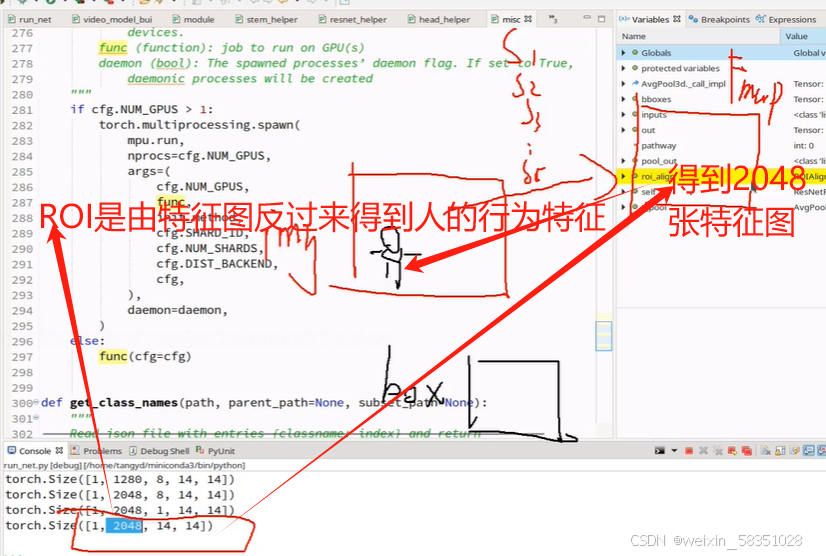
前面经过一系统操作后得到2048张特征图,现在用Roi就是从这些特征图反过来从原始图像中定位到人的动作行为特征出来,只需要人的,不需要其它的,如下图:
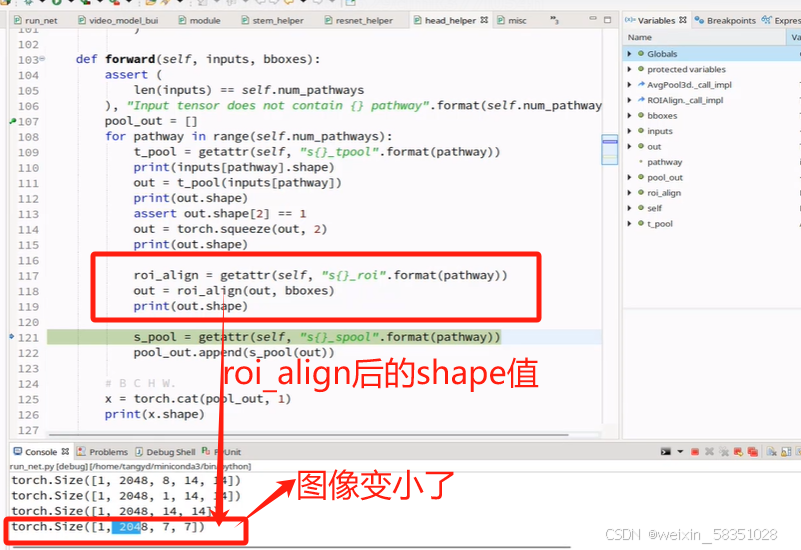
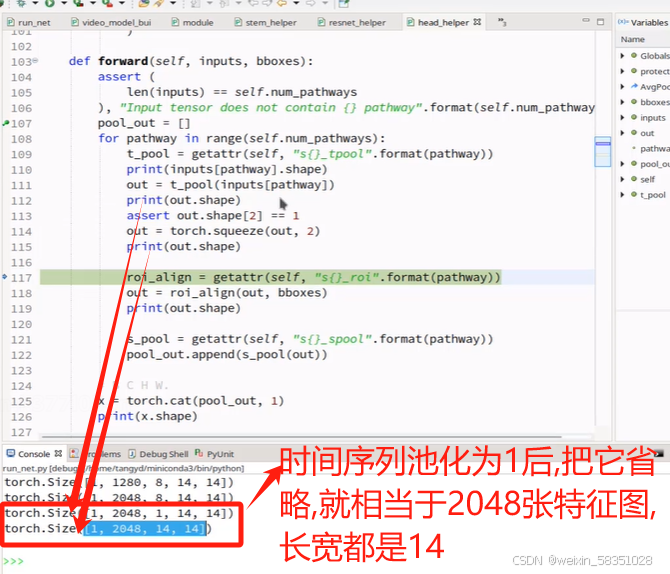
图像变小的特征图还要等下还要做全连接操作,所以可以把它拉长成向量,也可以通过Maxpool把w与h都设置成1.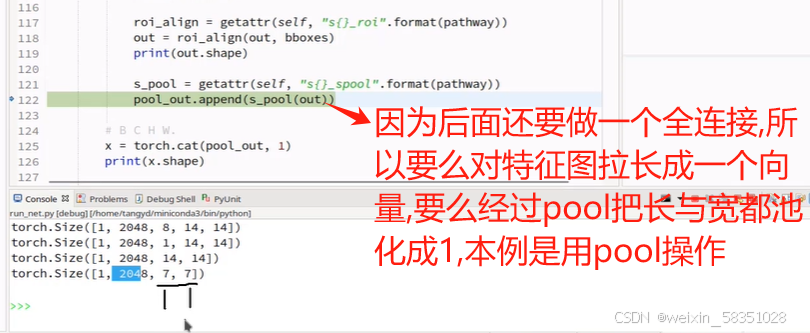
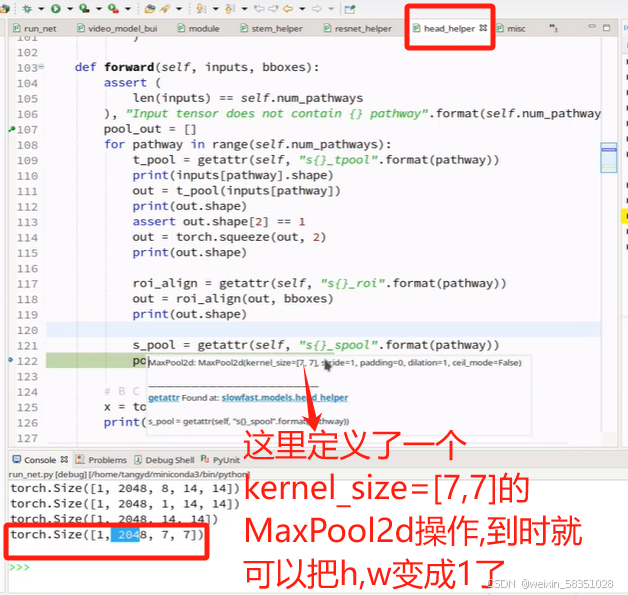
fast与slow特征都经过MaxPool后,就分别变成2048,256维的微量了,这时2048与256维的向量加起来连接一个全连接层(FC),最后预测(Prediction),如下图:
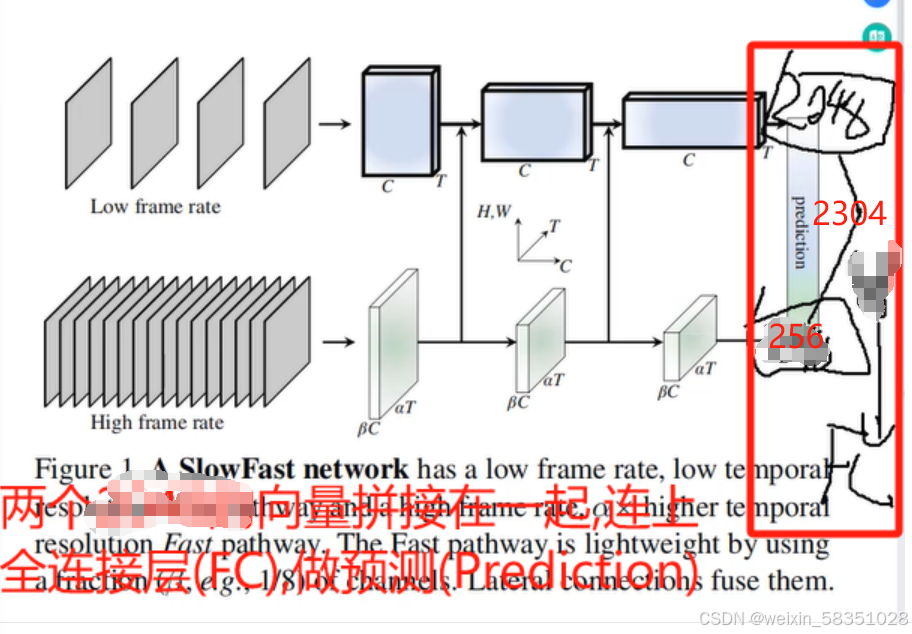
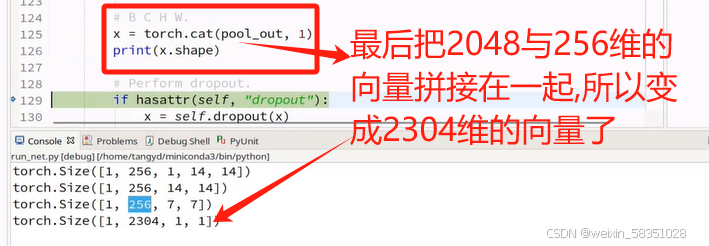
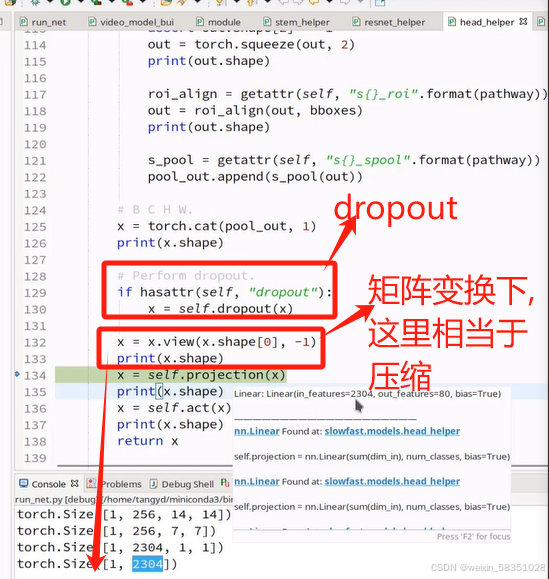
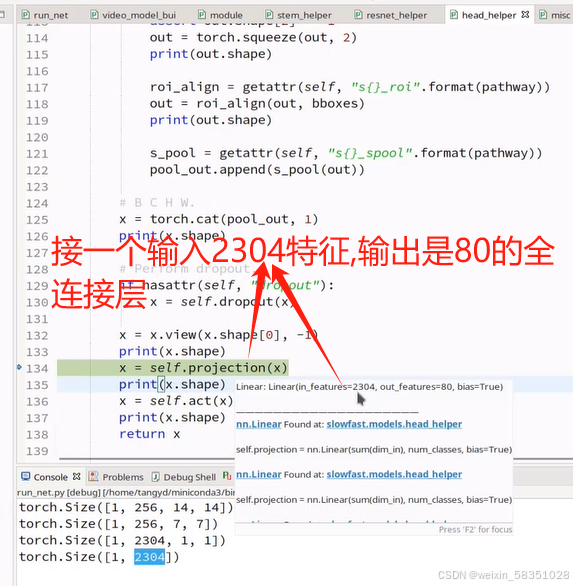
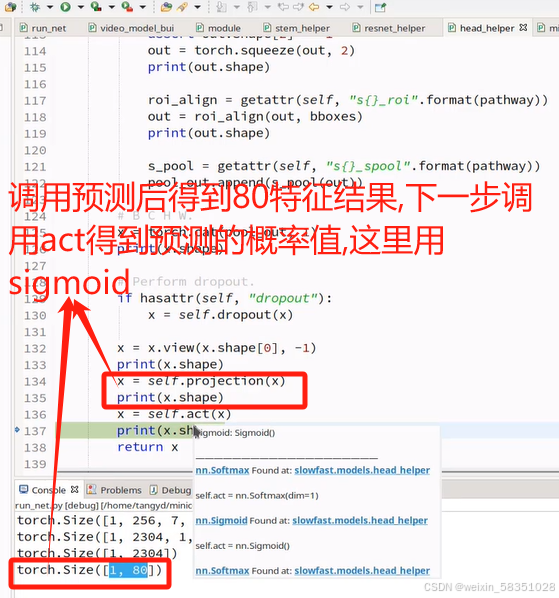
返回x后就说明我们从数据输入到预测输出结果的前向传播过程全部走完了。因为它是做行为识别,所以最后预测的结果就是做分类任务即可。损失函数这一部分就不调试代码了。
总结:这里主要是对AVA格式数据的处理,模型算法方面主要用到conv3d,bn,relu,特征融合与拼接(时间与空间角度融合),平均与最大池化(pool),resnet,全连接,分类预测过程。