【业务领域】PCIE协议理解
PCIE协议理解
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
PCIE学习理解。
文章目录
- PCIE协议理解
- @[TOC](文章目录)
- 前言
- 零、PCIE掌握点?
- 一、PCIE是什么?
- 二、PCIE协议总结
- 物理层
- 切速
- 链路层
- 事务层
- 6.2 TLP的路由
- 电源管理
- 虚拟化
- 三、疑难杂症
- PCIE4到PCIE5变化点
- PCIE5到PCIE6变化点
- Pcie bar 空间寄存器
- ATS机制
- 参考资料
- 总结
文章目录
- PCIE协议理解
- @[TOC](文章目录)
- 前言
- 零、PCIE掌握点?
- 一、PCIE是什么?
- 二、PCIE协议总结
- 物理层
- 切速
- 链路层
- 事务层
- 6.2 TLP的路由
- 电源管理
- 虚拟化
- 三、疑难杂症
- PCIE4到PCIE5变化点
- PCIE5到PCIE6变化点
- Pcie bar 空间寄存器
- ATS机制
- 参考资料
- 总结
前言
本文内容:PCIE协议理解和总结。
PCIE理解和总结。
提示:以下是本篇文章正文内容
零、PCIE掌握点?
PCIE是什么?
PCIE的优缺点是什么?
PCIE协议与其他协议的不同点是什么?
PCIE有什么应用场景?
PCIE控制器上游对接什么模块,下游对接什么模块?
PCIE驱动是什么?
PCIE芯片如何测试?
一、PCIE是什么?
PCIE是一种外围组件接口协议。
二、PCIE协议总结
物理层
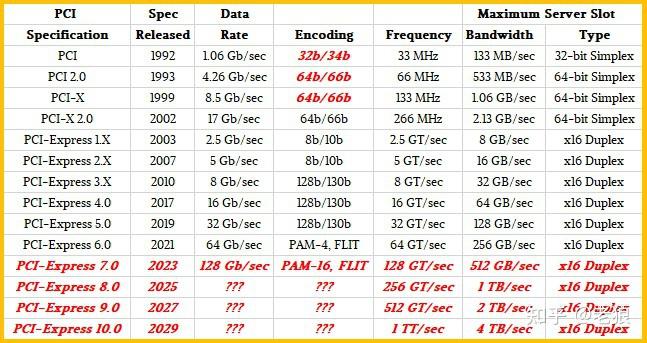
切速
PCIE6下支持怎样的切速?
链路层
事务层
6.2 TLP的路由
基于地址的路由:
存储器读写和I/O读写使用此方式。
基于ID的路由:
主要用于配置读写请求TLP、Cpl、CplD报文和Vender_Defined消息报文。
隐式路由:
消息请求使用隐式路由方式。
电源管理
虚拟化
SR-IOV
SR-IOV介绍
SR-IOV 技术是一种基于硬件的虚拟化解决方案,可提高性能和可伸缩性。
SR-IOV 标准允许在虚拟机之间高效共享 PCIe(Peripheral Component Interconnect Express,快速外设组件互连)设备,并且它是在硬件中实现的,可以获得能够与本机性能媲美的 I/O 性能。SR-IOV 规范定义了新的标准,根据该标准,创建的新设备可允许将虚拟机直接连接到 I/O 设备。SR-IOV 规范由 PCI-SIG 在 http://www.pcisig.com 上进行定义和维护。单个 I/O 资源可由许多虚拟机共享。共享的设备将提供专用的资源,并且还使用共享的通用资源。这样,每个虚拟机都可访问唯一的资源。因此,启用了 SR-IOV 并且具有适当的硬件和 OS 支持的 PCIe 设备(例如以太网端口)可以显示为多个单独的物理设备,每个都具有自己的 PCIe 配置空间。
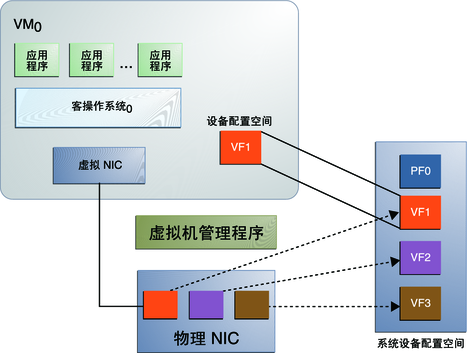
PF 包含 SR-IOV 功能结构,用于管理 SR-IOV 功能。PF 是全功能的 PCIe 功能,可以像其他任何 PCIe 设备一样进行发现、管理和处理。PF 拥有完全配置资源,可以用于配置或控制 PCIe 设备。虚拟功能 (Virtual Function, VF)是与物理功能关联的一种功能。VF 是一种轻量级 PCIe 功能,可以与物理功能以及与同一物理功能关联的其他 VF 共享一个或多个物理资源。==VF 仅允许拥有用于其自身行为的配置资源。==一个 具备SR-IOV能力的设备可以被配置成被枚举出多个Virtual Functions(数量可控制),而且每个Function 都有自己的完整有BAR的配置空间。VMM可以把一个或者多个VF 分配给VM。
三、疑难杂症
PCIE4到PCIE5变化点
除了 PCI Express Gen 5 版本附带的更严格的抖动要求、信道损耗预算约束以及通道电压和时间裕度要求外,速度提高还需要额外的物理层更改,同时还包括其他改进,以保持与以前的 PCIe 版本所需的向后兼容性。
有序集更改是 PCI Express 5.0 规范版本附带的一项重要修改。EIEOS 有序集用于帮助退出电气空闲状态。在 PCIe Gen 5 惯例中,用于每个 PCIe 4.0 有序对的熟悉的 16 个 0 和 1 的模式变成了对每个通道重复的 32 个 0 和 1。背靠背(重复)EIEOS 信号是 PCIe 5.0 协议的额外更改。数据流起始有序集 (SDS) 也已更新,因此接收方可以清楚地区分 PCI Express Gen 5 数据流起始点。
训练序列 (TS1/TS2) 受益于旨在促进 PCIe Gen 5 速度倍增的创新新选项。训练序列是链路建立和均衡 (EQ) 的必要先导,但随着有序集通过每个速度支持增量(从 2.5 GT/秒开始并逐步移动到 32.0 GT/秒 PCIe Gen 5 速度),训练序列也可能导致延迟。为了解决这个难题,提供了EQ 旁路选项,以基本上“跳过”中间速度均衡级别,或者通过使用“无 EQ”选项立即转换到 L0 活动数据传输状态来完全省略均衡。
PCIe Gen 5 的改进型 TS1 和 TS2 也增加了新的字段,用于替代协议标识和增强的预编码支持。一旦系统和设备之间的协商成功,链路就可以立即以支持的最高速度进入 L0 状态,并开始使用协商的备用协议传输数据。如果替代协议协商失败,系统可以快速恢复到主干 PCIe 5.0 协议。
PCIE5到PCIE6变化点
开发者需要考虑的PCIe 6.0的三个主要变化如下:
● 数据速率从32GT/s翻倍至64GT/s
● 从NRZ编码转换到PAM-4编码,以及由此带来的纠错影响
● 从传输的可变大小TLP到固定大小FLIT
● 除了速度,PCIe 6.0还引入了L0p链路状态,关于它的内容,我们将在介绍链路ASPM(L0,L1,L0s和L0p)中介绍。
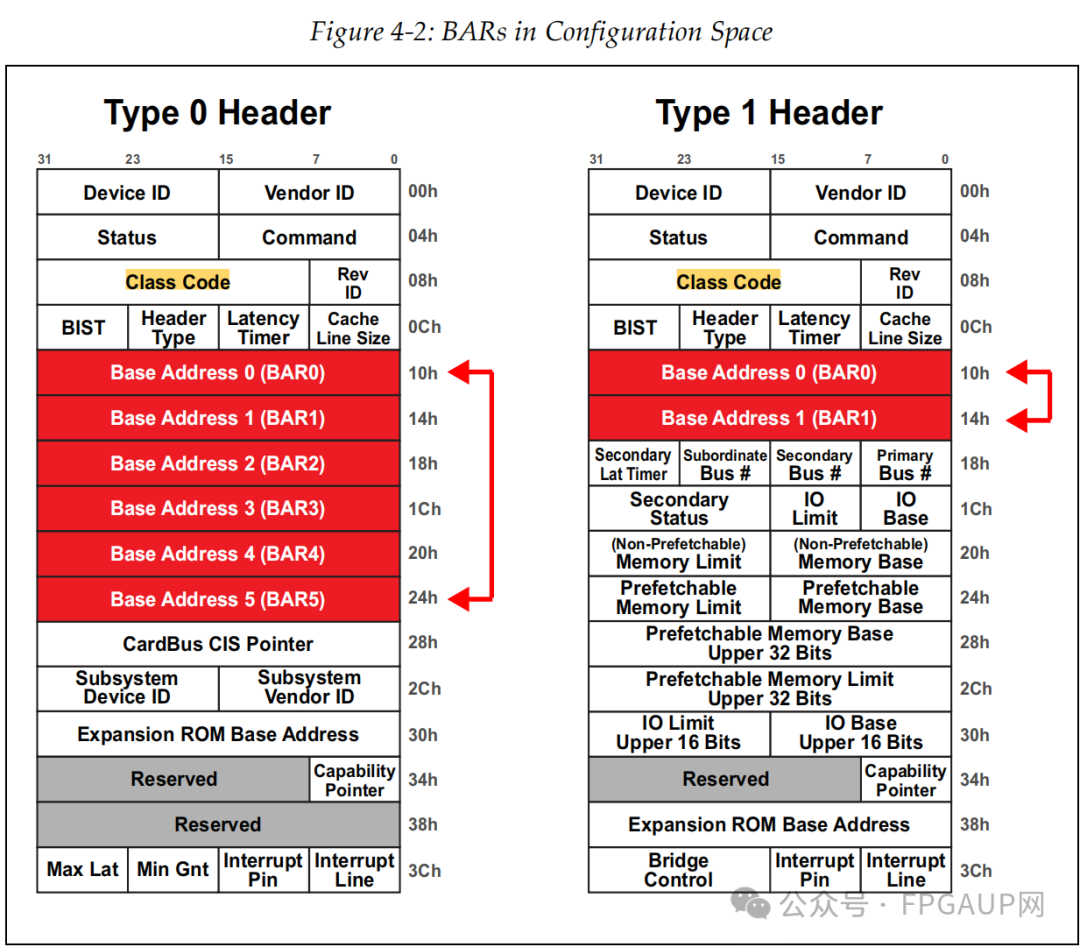
Pcie bar 空间寄存器
如下图标红的两部分是bar寄存器。
为什么需要bar寄存器:
一方面这还是和CPU、操作系统的机制有关,它们不允许PCI设备自己在内存中划拉片地方供自己使用,而是必须由系统统一分配。
另一方面PCI设备需要一定内存空间来存储自身需要的些数据,例如功能相关的配置数据,而且不同设备不同功能的情况下需要的空间大小还不一致,所以就有了bar寄存器了,用于对不同设备进行量身定制内存空间。
PCI设备有6个bar寄存器,可以启用全部或其中几个,一旦启用,这个bar寄存器就与内存建立了关系,主机就可以根据BARs中所写入的地址范围进行访问。任何时候,当设备发现一个请求事务的地址是映射到自己的一个BAR时,它就会接收这个请求事务,因为它自己就是这个请求的目标设备。
02bar寄存器如何使用:
根据上图可知,type0和type1拥有的bar数量是不一样的,为什么不一样放在后面说,bar在使用上可分为三种,分别是
1、32bit内存地址空间请求
2、64bit内存地址空间请求
3、IO地址空间请求
但在配置机制上是一致的,均是分为三个步骤,
Step 1
主机发起配置请求向目标PCIE设备的目标bar寄存器,对这个bar寄存器进行写 1操作。
Step 2
主机发起读配置请求读取目标PCIE设备的目标bar寄存器的值,由于有些bit 位主机是无法改写的,在上电就强制为固定值了,所以主机回读的值部分不是1。
Step 3
主机根据读取的值判断bar请求内存空间的大小并为其分配,并将起始地址写入目标bar寄存器,这就完成了两个功能,一是确定基地址,二是确定了寻址范围。具体是如何实现的呢?接下来以32bit内存地址空间请求为例详细看下bar寄存器的结构

这里提到了预取和非预取,对于PCI来说,预取功能能提升性能,但在PCIE上不是很明显,只不过将此继承了过来,所以可以先忽略,等后面用到了再说了。
03拿32bit的bar空间申请举例:
bar寄存器的存在的目的是告诉使用者我需要多大的空间,在诉说之前自身肯定得先知道并做一定设置,这种设置呢就是将某些位写0,且不可更改。
如下图是32bit非预取内存请求的申请过程描述,申请4KB大小的空间。
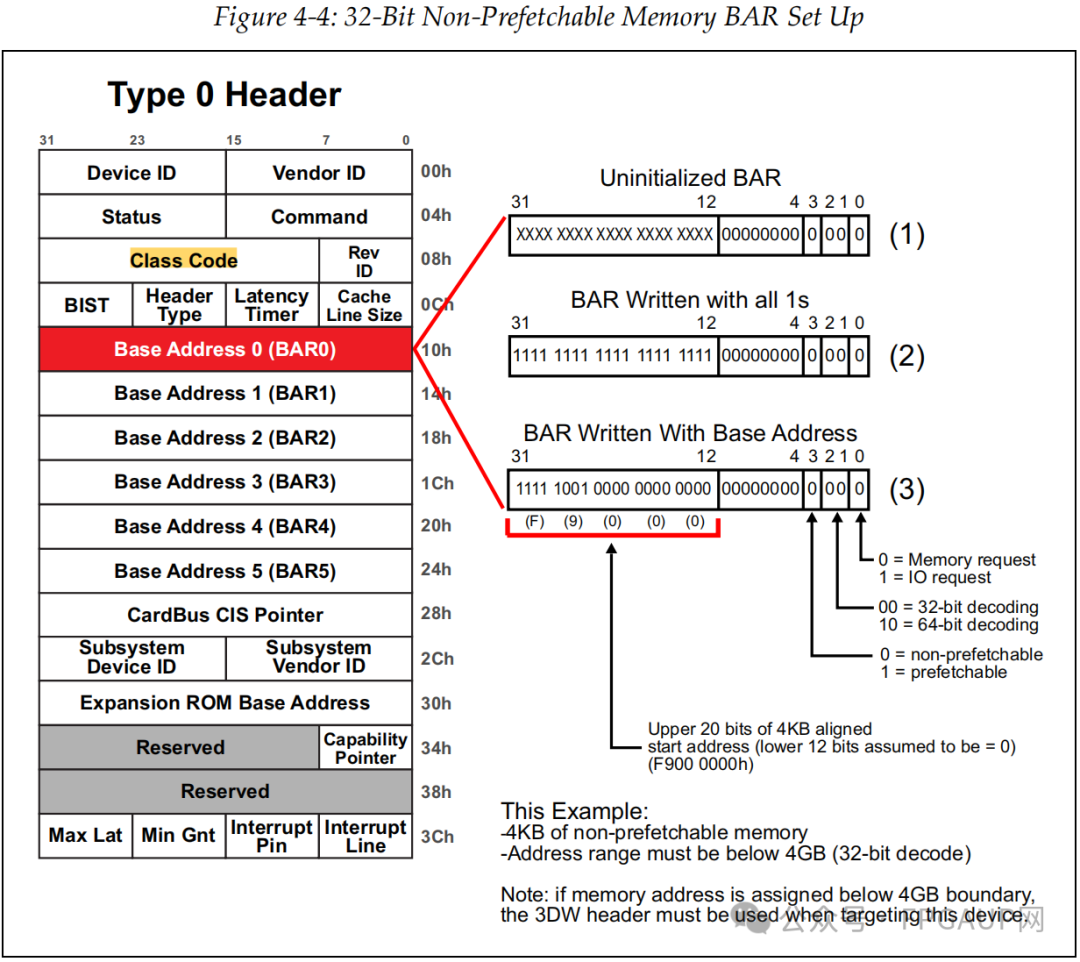
如上图(1)所描述的“Uninitialized bar”,bit0bit3是固定内容,bit11bit4的预设0就是表示申请内存大小的,12bit写0表示申请内存空间为4KB,因为2^12=4096嘛,如果bit13也是0,那就表示想要申请8KB的内存空间。
那么为啥要这样搞呢?主机又是怎么知道的呢?首先说主机是怎么知道的,主机会对bar寄存器各个bit位都写1(0XFFFFFFFF)然后再回读。对于我们这个例子回读内容就是0XFFFFF000,通过bit3~0知道了申请内存空间的属性,又因为bit12是1,所以知道了申请内存大小位4KB。
随后主机再把内存基地址写入bar寄存器,例如下图的0xF9000000,如此主机就知道了这个设备的对应功能的bar0申请4KB内存。
最后说,为什么要这样做,在我看来,这样做即实现了我们的目的,也节省了需要的配置字。我们需要告知主机需要多大的空间和属性,可以单独占一个字段,让主机读就行了。但再发TLP包时,主机寻址也需要知道目的地址,这样还需要一个字段。现在将两字段合一的,而且目的还实现了。
04另外两种bar寄存器的使用
如下图是对64bit的设置,申请一个64MB内存大小的过程,与32bit相比就是基地址更大些。
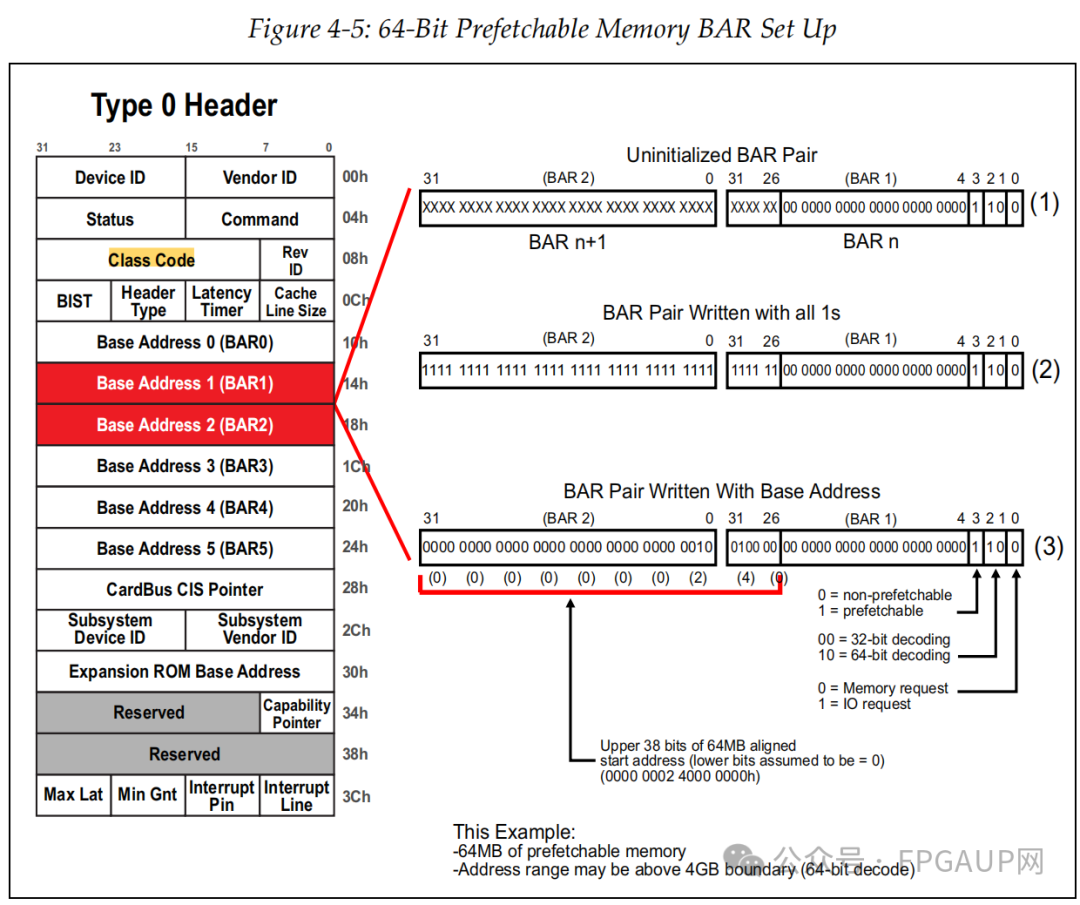
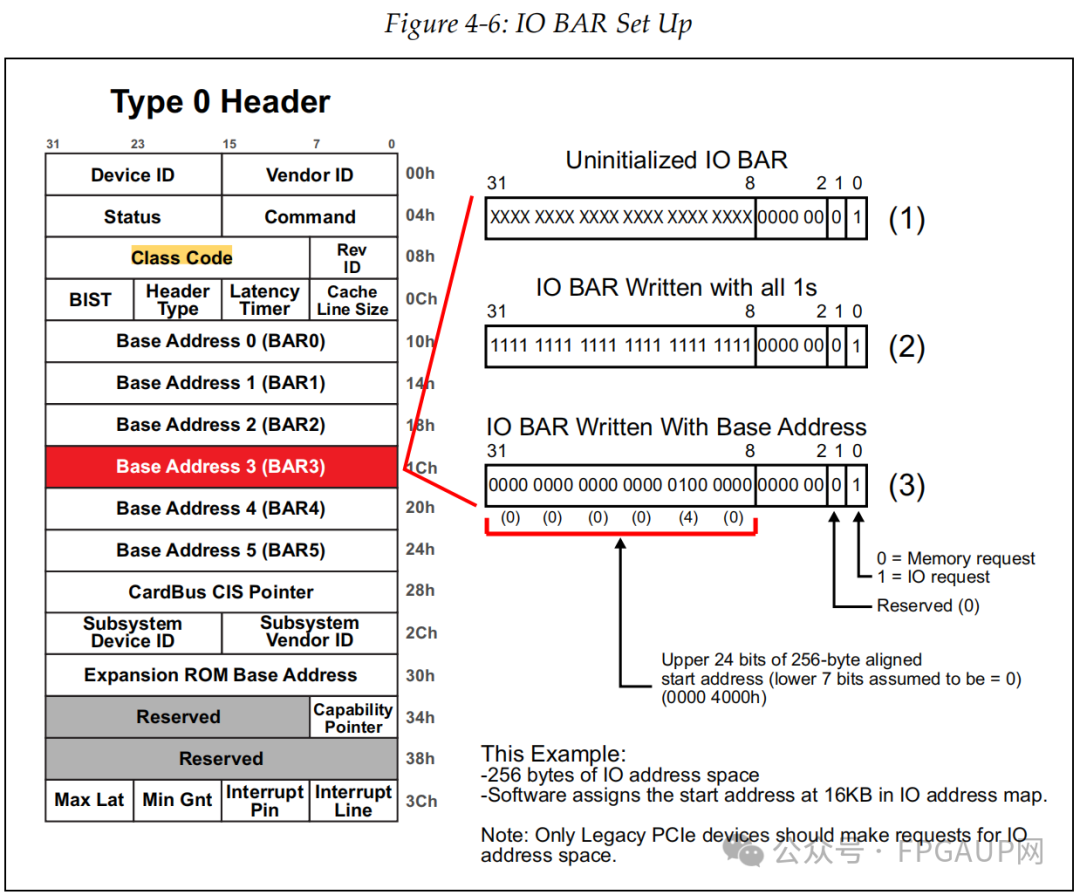
入下图是申请一个256Byte大小的过程,也就是bit8~2是固定为0,其中bit0为1表示是IO请求。
参考资料:bar空间介绍
ATS机制
ATS全称是Address Translation Service,顾名思义,就是一个地址翻译服务机制。PCIe下的ATS是以CPU为中心,PCIe总线上的各个设备可以通过ATS机制向主机申请未翻译地址对应的物理地址映射以及响应的属性、权限等信息。
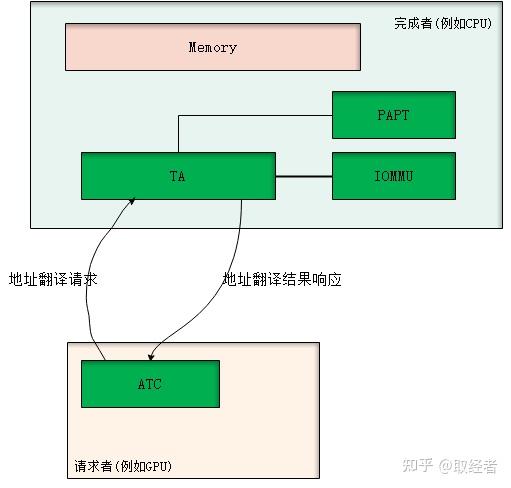
一般地,在PCIe体系下,发起地址翻译请求的设备叫请求者,也叫client,而处理地址翻译请求的(即CPU)叫完成者,也叫home。因此,对于地址翻译请求的流程如下:
1、client有数据访问需求(或者是prefetching引入的需求);
2、client发出翻译请求给home侧,携带需要访问的虚拟地址空间块和响应属性、提示信息;
3、home侧进行翻译,之后返回翻译结果给client;
4、client在本地cache翻译结果;
5、client引擎发出数据访问,查本地cache,直接发出查完后的结果访问home侧;
6、home侧直接bypass TA,访问home本地内存。

ATS机制想要解决的问题(优势):
1、能够分担主机(CPU)侧的查表压力,特别是大带宽、大拓扑下的IO数据流,CPU侧的IOMMU/SMMU/VT-d的查表将会成为性能瓶颈,而ATS机制正好可以提供将这些查表压力卸载到不同的设备中,对整个系统实现“who consume it, who pay for it”。
2、对于IO设备往CPU的数据流,其IOMMU/SMMU/VT-d的查表性能在整个IO性能中显得极为关键,查表性能的好坏至今影响IO性能的好坏。而根据现今大量学术界和工业界的研究表明,决定查表性能的好坏的一个最为关键的点是TLB的预测。而像传统PCIe IO数据流,在CPU侧集中式做IOMMU/SMMU/VT-d的查表,对于其TLB的预测(prefetch)是很困难,极为不友好的。因为,很多不同workload的IO流汇聚到一点,对于TLB的预测的冲击很大,流之间的干扰很大,很难做出准确的预测,从而TLB的命中率始终做不到太高,从而影响IO性能。而ATS的机制恰好提供了一个TLB的预测卸载到源头去的机制,让用户(设备)自己根据自己自身的业务流来设计自己的预测策略,而且用户彼此之间的预测模型不会受到彼此的影响,从而大大提高了用户自己的预测的准确性。抽象来看,这时候的设备更像是CPU核,直接根据自身跑的workload来预测本地的TLB,从而提升预测性能,进而提升整系统的预测性能。
ATS机制就是一个分布式的地址翻译系统,对于异构架构的地址问题也起到了很好的支持效果。例如,NVIDIA和IBM最近搞的NVLINK互联CPU和GPU,其就是用了ATS来实现SVM,这个后续我想详细介绍一下。
当然,ATS也会带来如下两个比较严重的问题:
1、安全问题。也就是有了ATS后,设备会直接发出PA来访问CPU的内存空间,而CPU这边将不再查页表,从而也不再有地址访问权限的检查。因此,对于malicious设备,或者是被入侵的设备,又或者是设备自身设计的bug,其会发出PA访问那些其没有权限访问或者是不属于其的物理地址空间,从而带来系统的isolation的破坏,系统安全的威胁等安全问题。现有机制下,目前还没有解决办法。但,本人有专利可以解决,而且本人也有更好的机制可以解决,目前保密,暂时不能公布。本人的专利的话,后面有时间可以写一下。
2、无效化问题。也就是,在CPU侧被cache的页表发生变化(例如权限发生了变化,对应的PA需要回收SWAP等)的时候,此时CPU需要发出无效化指令给对应cache过的设备(ATC)来通知这件事,这会影响CPU回收页表/物理空间的性能。这就意味着CPU侧要实时跟踪页表被谁cache走了,维护这些信息也带来了成本的开销增长。
3、对设备的设计要求比较高,可以看到,ATS在某些时刻势必增加了延时。而为了减少甚至消除影响,就需要设备设计出具有良好的ATC机制,包括ATC的预测、地址翻译请求的长度、发送翻译请求的时机等,这里的设计空间都比较大,对设备的要求都比较高。
前面的问题1和2是系统需要解决的功能问题,后者3是一个趋势。我想象中的设备将会越来越智能,设备和CPU之间将会是点对点的平等计算地位,在异构体系下,它们是平等的计算关系。它们之间SVM、具有cache coherence等,从而第3看起来不是问题,而是趋势。
ATS机制
参考资料
PCIE6.0差异点基础介绍:
《PCIe 6.0概述》
NRZ编码和PAM4编码介绍:
《学会“NRZ”、“PAM4”,仅仅需要三分钟!》
总结
提示:这里pcie bar总结:
以上就是今天要讲的内容。