航空客户价值分析阶段性测验
航空公司客户价值分析
学习目标
- 学会怎么进行数据分析。
- 掌握hive的使用方法。
- 学会数据清洗和K-Means聚类算法。
- 了解航空公司现状与客户价值分析
任务描述
面对激烈的市场竞争,各个航空公司都推出了更多的优惠来吸引客户。国内某航空公司面临着常旅客流失,竞争力下降和资源未充分利用等经营危机。通过建立合理的客户价值评估模型,对客户进行分群,分析及比较不同客户群的客户价值,并制定相应的营销策略,对不同的客户群提供个性化服务。
任务分析
- 了解航空公司现状。
(2)认识客户价值分析。
(3)熟悉航空公司客户价值分析的步骤与流程。
-
- 分析航空公司现状
民航的竞争除了三大航空公司之间的竞争之外,还将加入新崛起的各类小型航空公司、民营航空公司,甚至国外航空巨头。航空产品生产过剩,产品同质化特征愈加明显,于是航空公司从价格、服务间的竞争逐渐转向对客户的竞争。
-
- 认识客户价值分析
(1)航空公司的数据分析:
目前航空公司已积累了大量的会员档案信息和其乘坐航班记录。以2014-03-31为结束时间,选取宽度为两年的时间段作为分析观测窗口,抽取观测窗口内有乘机记录的所有客户的详细数据形成历史数据,44个特征,总共62988条记录。数据如air_data.csv所示!
(2)航空公司的营销实施经验分析:
1、公司收入的80%来自顶端的20%的客户。
2、20%的客户其利润率100%。
3、90%以上的收入来自现有客户。
4、大部分的营销预算经常被用在非现有客户上。
5、5%至30%的客户在客户金字塔中具有升级潜力。
6、客户金字塔中客户升级2%,意味着销售收入增加10%,利润增加50%。
-
- 熟悉航空客户价值分析的步骤与流程
(1)抽取航空公司2012年4月1日至2014年3月31日的数据。
(2)对抽取的数据进行数据探索分析与预处理,包括数据缺失值与 异常值的探索分析、数据清洗、特征构建、标准化等操作。
(3)基于RFM模型,使用K-Means算法进行客户分群。
(4)针对模型结果得到不同价值的客户,采用不同的营销手段,提供定制化的服务。
- 预处理航空客户数据
任务描述
航空公司客户原始数据存在少量的缺失值和异常值,需要清洗后才能用于分析。同时由于原始数据的特征过多,不便直接用于客户价值分析,因此需要对特征进行刷选,挑选出衡量客户价值的关键特征。
任务分析
- 处理数据缺失值与异常值。
- 结合RFM模型刷选特征。
- 标准化刷选后的数据。
- 处理数据缺失值与异常值
#建立数据库与数据表
create database air_data;
Show database;
use air_data;
create table air_table(
member_no string,
ffp_date string,
first_flight_date string,
gender string,
ffp_tier int,
work_city string,
work_province string,
work_country string,
age int,
load_time string,
flight_count int,
bp_sum bigint,
ep_sum_yr_1 int,
ep_sum_yr_2 bigint,
sum_yr_1 bigint,
sum_yr_2 bigint,
seg_km_sum bigint,
weighted_seg_km double,
last_flight_date string,
avg_flight_count double,
avg_bp_sum double,
begin_to_first int,
last_to_end int,
avg_interval float,
max_interval int,
add_points_sum_yr_1 bigint,
add_points_sum_yr_2 bigint,
exchange_count int,
avg_discount float,
p1y_flight_count int,
l1y_flight_count int,
p1y_bp_sum bigint,
1y_bp_sum bigint,
ep_sum bigint,
add_point_sum bigint,
eli_add_point_sum bigint,
l1y_eli_add_points bigint,
points_sum bigint,
l1y_points_sum float,
ration_l1y_flight_count float,
ration_p1y_flight_count float,
ration_p1y_bps float,
ration_l1y_bps float,
point_notflight int )
row format delimited fields terminated by ',';
#导入数据
load data local inpath 'data/air_data.csv' overwrite into table air_table;
#统计SUM_YR_1,SEG_KM_SUM,AVG_DISCOUNT空值记录
create table count_null as select * from
(select count(*) as sum_yr_1_null_count from air_table where sum_yr_1 is null)
sum_yr_1,
(select count(*) as seg_km_sum_null from air_table where seg_km_sum is null)
seg_km_sum,
(select count(*) as avg_discount_null from air_table where avg_discount is null)
avg_discount;
select * from count_null;
#统计SUM_YR_1等于0,SEG_KM_SUM大于0,AVG_DISCOUNT不为0的异常数据。
create table count_sj as select * from
(select count(*) as sum_yr_1_0_count from air_table where sum_yr_1 =0)
sum_yr_1,
(select count(*) as seg_km_sum_0 from air_table where seg_km_sum >0)
seg_km_sum,
(select count(*) as avg_discount_0 from air_table where avg_discount <>0)
avg_discount;
select * from count_sj ;
##清洗数据
#清除空值
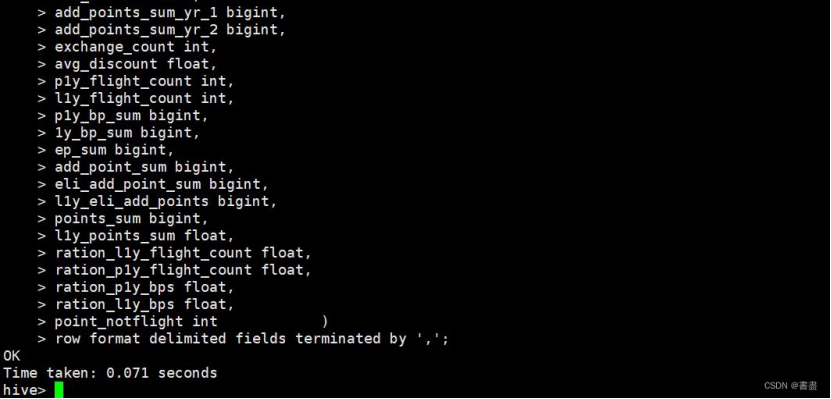
create table sas_not_0 as
select * from air_table
Where (sum_yr_1 !=”null” and seg_km_sum !=”null” and avg_discount!=”null”);
#清除异常数据
create table sas_not_1 as
select * from sas_not_0
where !(sum_yr_1=0 and avg_discount <> 0
and seg_km_sum > 0);
-
- 构建航空客户价值分析关键特征
#从清洗的数据中取出6个属性
create table flfasl as
select
ffp_date,
load_time,
flight_count,
avg_discount,
seg_km_sum,
last_to_end
from sas_not_0;
select * from flfasl limit 10;
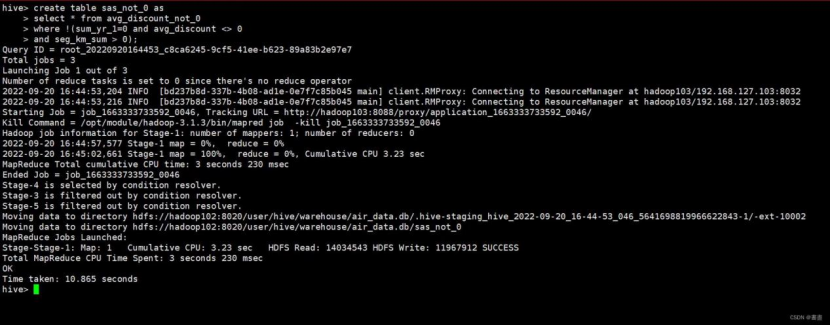
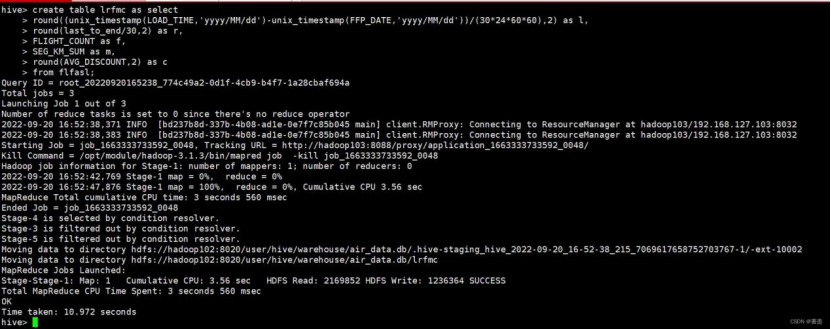
#对数据进行变换
create table lrfmc as select
round((unix_timestamp(LOAD_TIME,'yyyy/MM/dd')-unix_timestamp(FFP_DATE,'yyyy/MM/dd'))/(30*24*60*60),2) as l,
round(last_to_end/30,2) as r,
FLIGHT_COUNT as f,
SEG_KM_SUM as m,
round(AVG_DISCOUNT,2) as c
from flfasl;
-
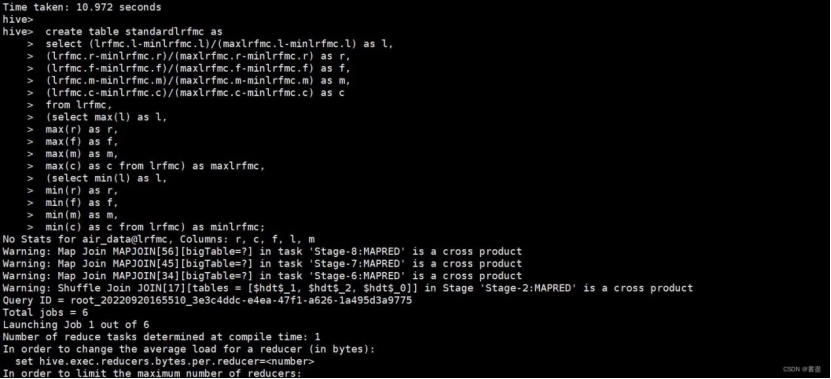
- 标准化LRFMC五个特征
create table standardlrfmc as
select (lrfmc.l-minlrfmc.l)/(maxlrfmc.l-minlrfmc.l) as l,
(lrfmc.r-minlrfmc.r)/(maxlrfmc.r-minlrfmc.r) as r,
(lrfmc.f-minlrfmc.f)/(maxlrfmc.f-minlrfmc.f) as f,
(lrfmc.m-minlrfmc.m)/(maxlrfmc.m-minlrfmc.m) as m,
(lrfmc.c-minlrfmc.c)/(maxlrfmc.c-minlrfmc.c) as c
from lrfmc,
(select max(l) as l,
max(r) as r,
max(f) as f,
max(m) as m,
max(c) as c from lrfmc) as maxlrfmc,
(select min(l) as l,
min(r) as r,
min(f) as f,
min(m) as m,
min(c) as c from lrfmc) as minlrfmc;
- 使用K-Means算法进行客户分群
任务描述
聚类模型的用途非常广泛,从用户画像到客户价值分析,均有其身影。K-Means算法是一种最常用的聚类算法,简单易行且使用于中大型数据量的数据聚类。本任务将使用K-Means算法进行航空公司用户分群,最终得到不同特征的客户群,并分析不同客户群的特征,指定相对应的策略。
任务分析
- 了解K-Means算法的基本原理。
- 使用K-Means算法对航空客户进行分群。
- 根据分群结果制定营销策略。
- 了解K-Means聚类算法
K-Means聚类算法是一种基于质心的划分方法,输入聚类个数k,以及包含n个数据对象的数据库,输出满足误差平方和最小标准的k个聚类。算法步骤如下。
(1)从n个样本数据中随机选取k个对象作为初始的聚类中心。
(2)分别计算每个样本到各个聚类质心的距离,将样本分配到距离最近的那个聚类中心类别中。
(3)所有样本分配完成后,重新计算k个聚类的中心。
(4)与前一次计算得到的k个聚类中心比较,如果聚类中心发生变化,转(2),否则转(5)。
(5)当质心不发生变化时停止并输出聚类结果。
-
- 分析聚类结果
# 读入数据
import numpy as np
import pandas as pd
# 导入kmeans算法
from sklearn.cluster import KMeans
#导入航空数据
airline_data = pd.read_csv("air_data_base.csv",encoding="gb18030")
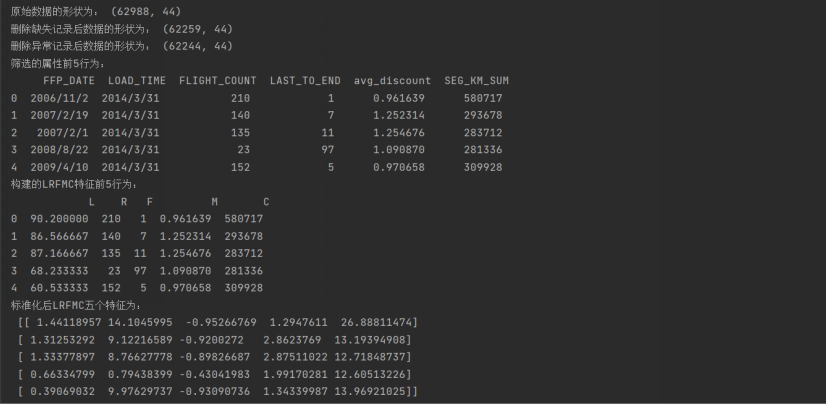
print('原始数据的形状为:',airline_data.shape)
## 去除票价为空的记录
exp1 = airline_data["SUM_YR_1"].notnull()
exp2 = airline_data["SUM_YR_2"].notnull()
exp = exp1 & exp2
airline_notnull = airline_data.loc[exp,:]
print('删除缺失记录后数据的形状为:',airline_notnull.shape)
#只保留票价非零的,或者平均折扣率不为0且总飞行公里数大于0的记录。
index1 = airline_notnull['SUM_YR_1'] != 0
index2 = airline_notnull['SUM_YR_2'] != 0
index3 = (airline_notnull['SEG_KM_SUM']> 0) & \
(airline_notnull['avg_discount'] != 0)
airline = airline_notnull[(index1 | index2) & index3]
print('删除异常记录后数据的形状为:',airline.shape)
airline_data.to_csv("处理后的数据.csv",encoding="gb18030")
## 选取需求特征
airline = pd.read_csv("处理后的数据.csv",encoding="gb18030")
airline_selection = airline[["FFP_DATE","LOAD_TIME","FLIGHT_COUNT","LAST_TO_END","avg_discount","SEG_KM_SUM"]]
print('筛选的属性前5行为:\n',airline_selection.head())
## 构建L特征
L = pd.to_datetime(airline_selection["LOAD_TIME"]) - \
pd.to_datetime(airline_selection["FFP_DATE"])
L = L.astype("str").str.split().str[0]
L = L.astype("int")/30
## 合并特征
airline_features = pd.concat([L,airline_selection.iloc[:,2:]],axis = 1)
airline_features.columns=['L','R','F','M','C']
print('构建的LRFMC特征前5行为:\n',airline_features.head())
## 标准化
from sklearn.preprocessing import StandardScaler
data = StandardScaler().fit_transform(airline_features)
np.savez('airline_scale.npz',data)
print('标准化后LRFMC五个特征为:\n',data[:5,:])
##K-Means算法
# 读取标准化后的数据
airline_scale = np.load(r'airline_scale.npz')['arr_0']
# 确定聚类中心数
k = 5
# 构建模型,随机种子设为123
kmeans_model = KMeans(n_clusters = k, random_state = 123)
# 模型训练
fit_kmeans = kmeans_model.fit(airline_scale)
# 查看聚类结果
# 聚类中心
kmeans_cc = kmeans_model.cluster_centers_
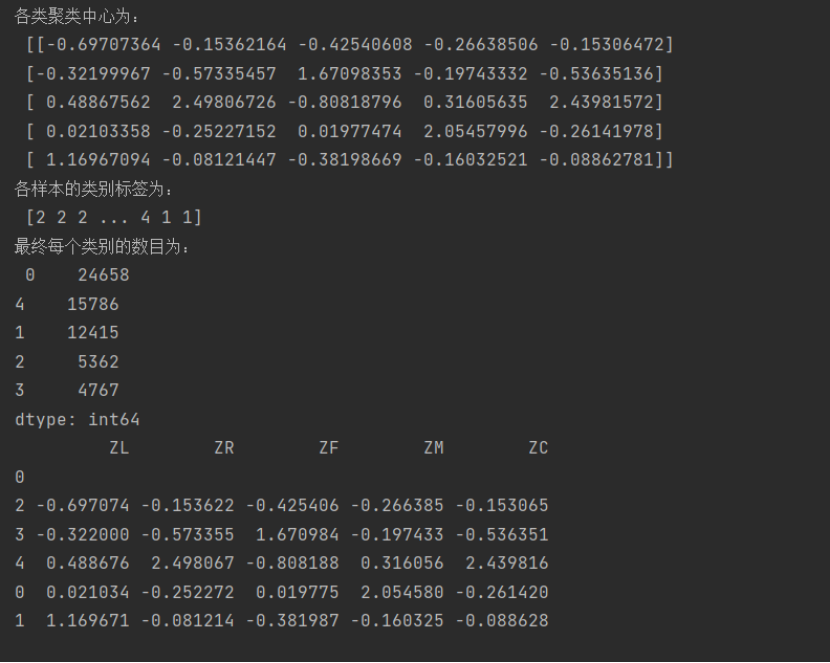
print('各类聚类中心为:\n',kmeans_cc)
# 样本的类别标签
kmeans_labels = kmeans_model.labels_
print('各样本的类别标签为:\n',kmeans_labels)
# 统计不同类别样本的数目
r1 = pd.Series(kmeans_model.labels_).value_counts()
print('最终每个类别的数目为:\n',r1)
# 输出聚类分群的结果
# 将聚类中心放在数据框中
cluster_center = pd.DataFrame(kmeans_model.cluster_centers_,\
columns = ['ZL','ZR','ZF','ZM','ZC'])
# 将样本类别作为数据框索引
cluster_center.index = pd.DataFrame(kmeans_model.labels_ ).\
drop_duplicates().iloc[:,0]
print(cluster_center)
-
- 模型应用
(1)会员的升级和保级
对那些接近但尚未达到的⾼消费客户采取⼀定的促销活动,刺激他们通过消费达到相应的升级标准。
(2)⾸次兑现
对那些接近但尚未达到⾸次兑现机票的会员,对他们进⾏提醒,使他们达到⾸次兑现标准。
- 小结
本项目结合航空公司客户价值分析的案例,重点介绍了数据分析算法中K-Means聚类算法在客户价值分析中的应用。针对RFM客户价值分析模型的不足,使用K-Means算法构建了航空客户价值分析LRFMC模型,详细描述了数据分析的整个过程。