机器学习实战,天猫双十一销量与中国人寿保费预测,使用多项式回归,梯度下降,EDA数据探索,弹性网络等技术
前言
很多同学学机器学习时总感觉:“公式推导我会,代码也能看懂,但自己从头做项目就懵”。
这次我们选了两个小数据集,降低复杂度,带大家从头开始进行分析,建模,预测,可视化等,体验完整流程。把多项式回归、梯度下降、正则化等技术真正用起来,而不是只做数学题。
所有代码用Python实现(sklearn+pandas+matplotlib),可直接在Jupyter笔记本上跑通,适合练手。
数据集较旧,学习完后可寻找最新数据集等自行训练模型。
关注我,学习技术,一起进步!
天猫双十一销量预测
天猫双十一,从2009年开始举办,第一届成交额仅仅0.5亿,后面呈现了爆发式的增长,那么这些增长是否有规律呢?是怎么样的规律,该如何分析呢?我们使用多项式回归一探究竟!
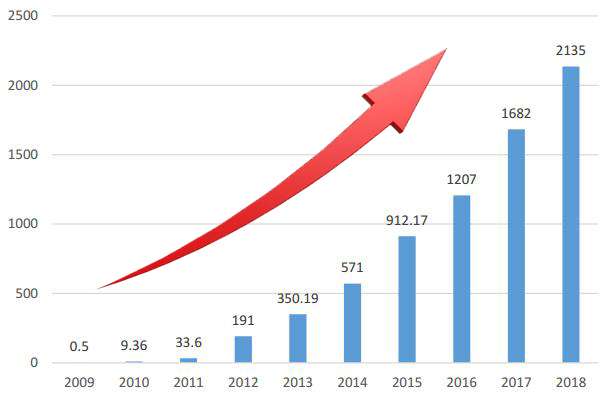
数据可视化,历年天猫双十一销量数据:
import numpy as np
from sklearn.linear_model import SGDRegressor
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 18
plt.figure(figsize=(9,6))# 创建数据,年份数据2009 ~ 2019
X = np.arange(2009,2020)
y = np.array([0.5,9.36,52,191,350,571,912,1207,1682,2135,2684])
plt.bar(X,y,width = 0.5,color = 'green')
plt.plot(X,y,color = 'red')
_ = plt.xticks(ticks = X)
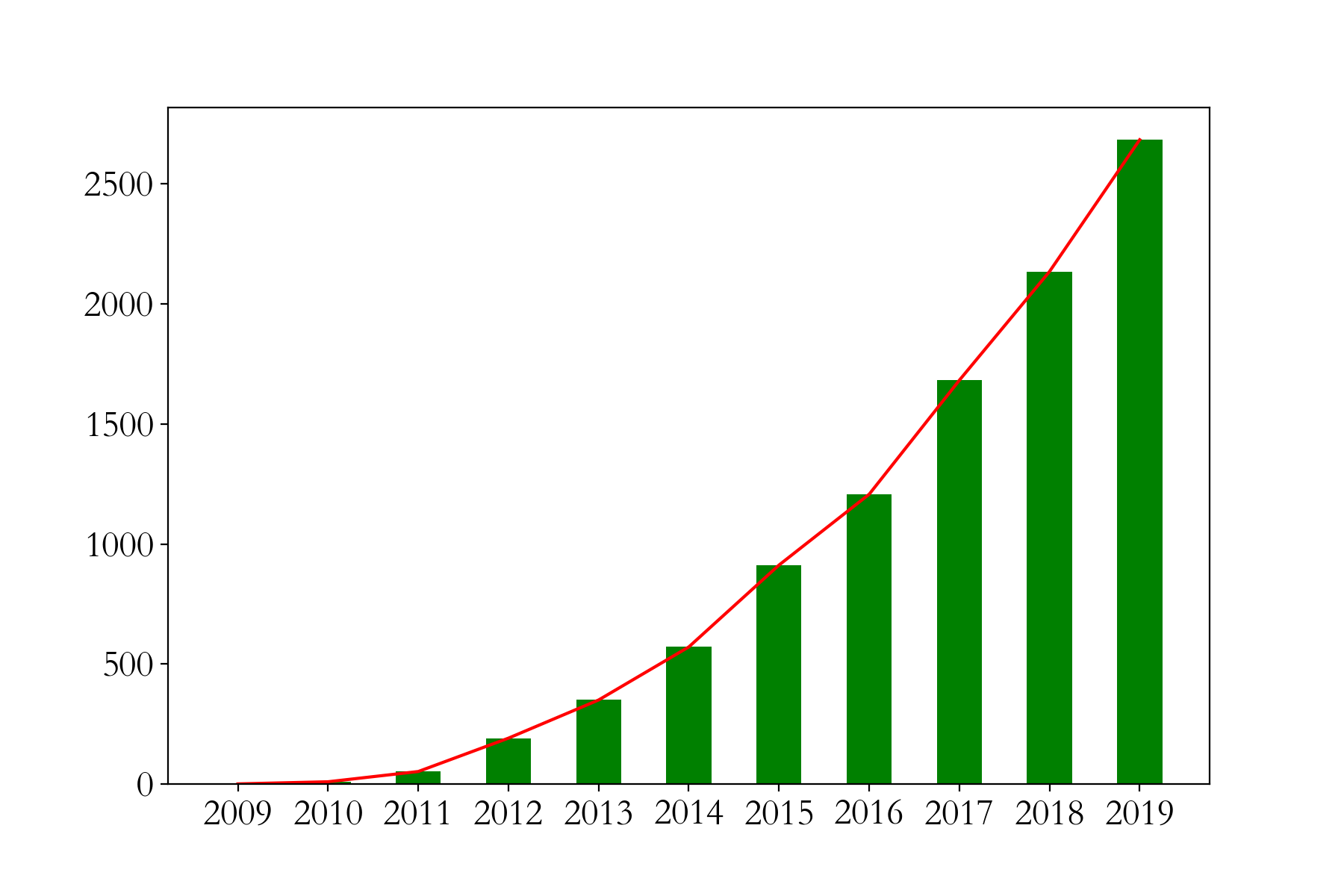
有图可知,在一定时间内,随着经济的发展,天猫双十一销量与年份的关系是多项式关系!假定,销量和年份之间关系是三次幂关系:
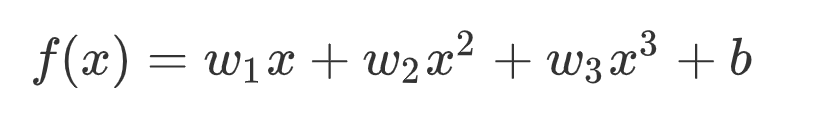
import numpy as np
from sklearn.linear_model import SGDRegressor
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
plt.figure(figsize=(12,9))# 1、创建数据,年份数据2009 ~ 2019
X = np.arange(2009,2020)
y = np.array([0.5,9.36,52,191,350,571,912,1207,1682,2135,2684])# 2、年份数据,均值移除,防止某一个特征列数据天然的数值太大而影响结果
X = X - X.mean()
X = X.reshape(-1,1)# 3、构建多项式特征,3次幂
poly = PolynomialFeatures(degree=3)
X = poly.fit_transform(X)
s = StandardScaler()
X_norm = s.fit_transform(X)# 4、创建模型
model = SGDRegressor(penalty='l2',eta0 = 0.5,max_iter = 5000)
model.fit(X_norm,y)# 5、数据预测
X_test = np.linspace(-5,6,100).reshape(-1,1)
X_test = poly.transform(X_test)
X_test_norm = s.transform(X_test)
y_test = model.predict(X_test_norm)# 6、数据可视化
plt.plot(X_test[:,1],y_test,color = 'green')
plt.bar(X[:,1],y)
plt.bar(6,y_test[-1],color = 'red')
plt.ylim(0,4096)
plt.text(6,y_test[-1] + 100,round(y_test[-1],1),ha = 'center')
_ = plt.xticks(np.arange(-5,7),np.arange(2009,2021))
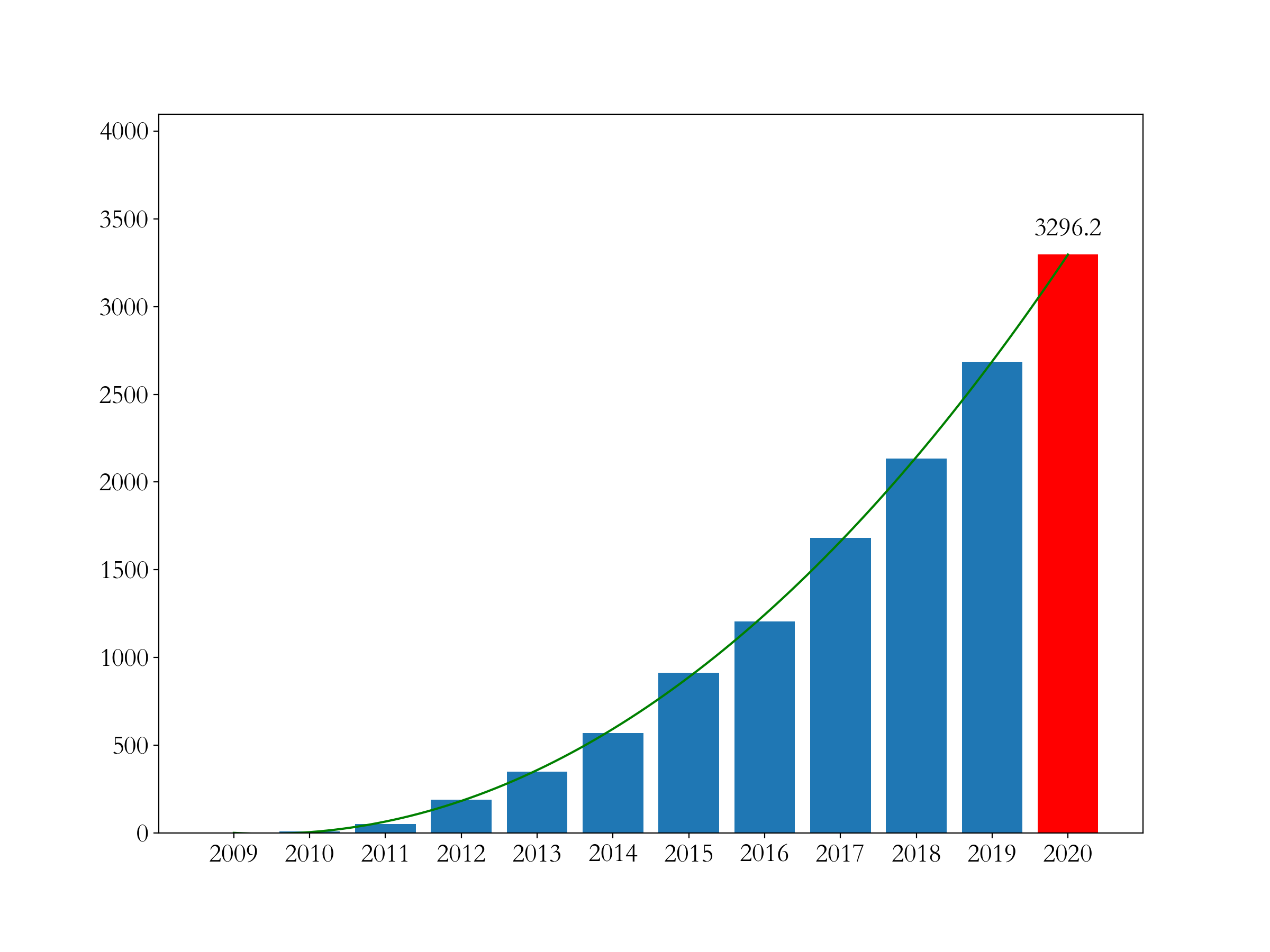
结论:
- 数据预处理,均值移除。如果特征基准值和分散度不同在某些算法(例如回归算法,KNN等)上可能会大大影响了模型的预测能力。通过均值移除,大大增强数据的离散化程度。
- 多项式升维,需要对数据进行Z-score归一化处理,效果更佳出色
- SGD随机梯度下降需要调整参数,以使模型适应多项式数据
- 从2020年开始,天猫双十一统计的成交额改变了规则为11.1日~11.11日的成交数据(之前的数据为双十一当天的数据),2020年成交额为4980亿元
- 可以,经济发展有其客观规律,前11年高速发展(曲线基本可以反应销售规律),到2020年是一个转折点。
中国人寿保费预测
1、数据加载与介绍
import numpy as np
import pandas as pd
data = pd.read_excel('./中国人寿.xlsx')
print(data.shape)
data.head()
注意可能需要安装库:openpyxl
pip install openpyxl
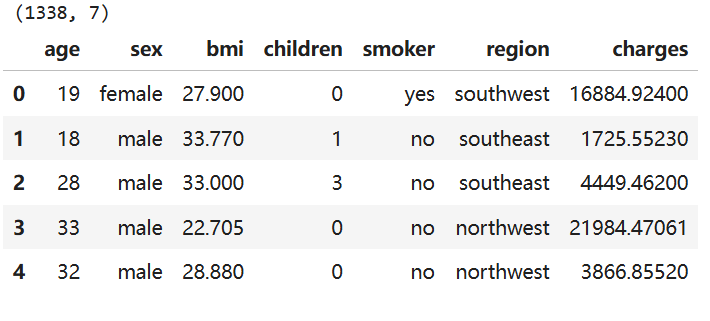
数据介绍:
- 共计1338条保险数据,每条数据7个属性
- 最后一列charges是保费
- 前面6列是特征,分别为:年龄、性别、体重指数、小孩数量、是否抽烟、所在地区
2、EDA数据探索
EDA(Exploratory Data Analysis),即探索性数据分析,是数据分析中的一个重要环节,旨在对数据进行初步的探索和分析,以发现数据的内在结构、特征、关系以及潜在的问题,为后续的数据分析和建模提供基础。
通过 EDA,可以帮助数据分析师和机器学习工程师更好地理解数据,发现数据中的问题和规律,为制定合适的数据分析策略、选择合适的模型以及进行有效的特征工程提供依据,从而提高数据分析和建模的准确性和可靠性。
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 定义一个函数来绘制不同特征对保费的影响
def plot_kde_by_feature(data, feature, ax):# 将数据转换为长格式melted_data = pd.melt(data, id_vars=['charges'], value_vars=[feature])# 绘制核密度估计图sns.kdeplot(data=melted_data, x='charges', fill=True, hue='value', ax=ax)ax.set_title(f'{feature}对保费的影响')# 创建一个 2x2 的子图布局
fig, axes = plt.subplots(2, 2, figsize=(12, 10))# 性别对保费影响
plot_kde_by_feature(data, 'sex', axes[0, 0])# 地区对保费影响
plot_kde_by_feature(data, 'region', axes[0, 1])# 吸烟对保费影响
plot_kde_by_feature(data, 'smoker', axes[1, 0])# 孩子数量对保费影响
plot_kde_by_feature(data, 'children', axes[1, 1])# 调整子图之间的间距
plt.tight_layout()
plt.show()
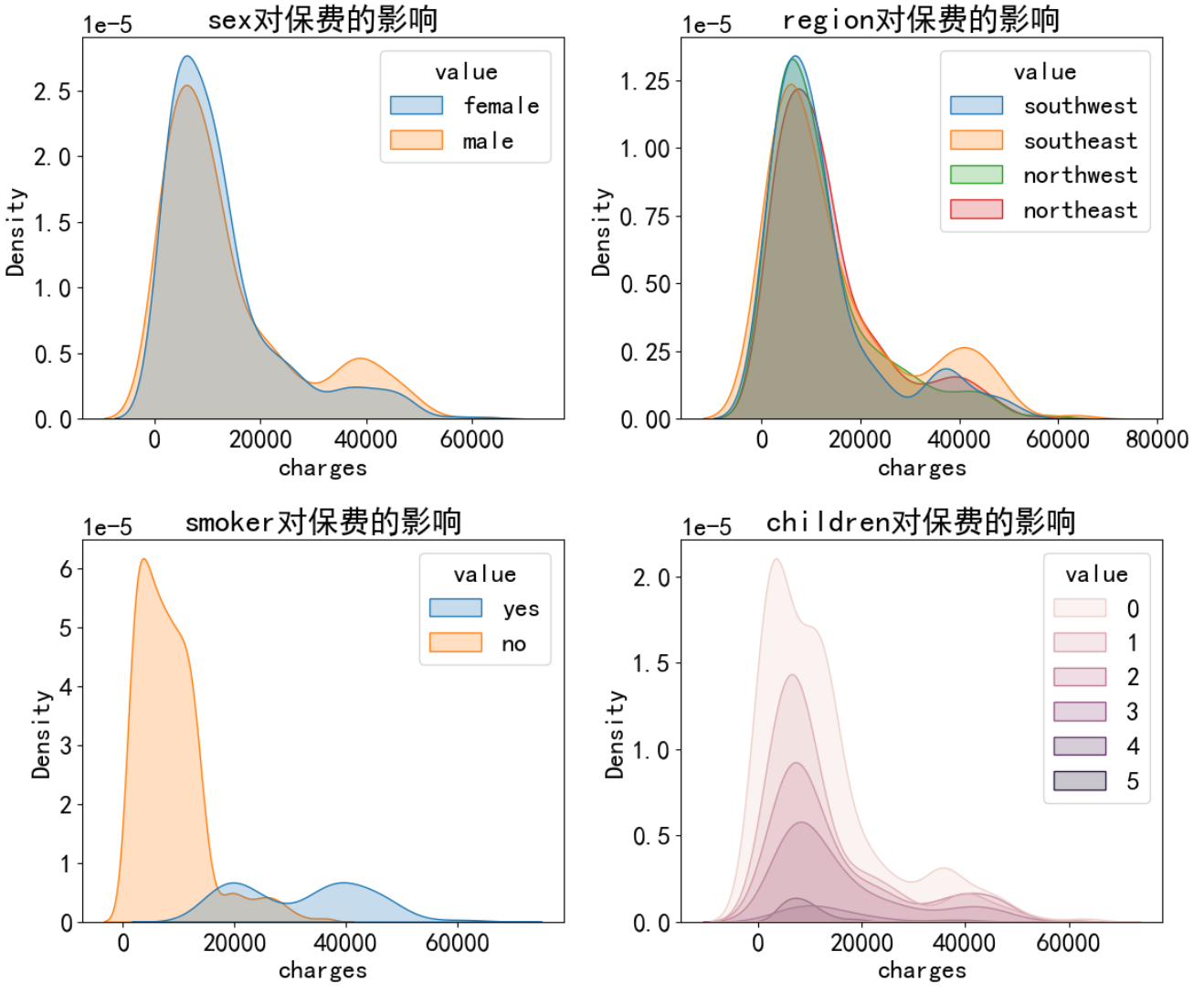
总结:
- 不同性别对保费影响不大,不同性别的保费的概率分布曲线基本重合,因此这个特征无足轻重,可以删除
- 地区同理
- 吸烟与否对保费的概率分布曲线差别很大,整体来说不吸烟更加健康,那么保费就低,这个特征很重要
- 家庭孩子数量对保费有一定影响
3、特征工程
特征工程是指从原始数据中提取、转换和选择特征,以提高机器学习模型性能的过程。
它是数据科学和机器学习领域中至关重要的一个环节,直接影响模型的效果和效率。
特征工程的目的是为了让数据更好地表达问题的本质,使模型能够更准确地学习到数据中的模式和规律,从而提高模型的性能和泛化能力。
一个好的特征工程可以显著提升模型的效果,甚至比选择更复杂的模型更有效。
data = data.drop(['region', 'sex'], axis=1)
data.head() # 删除不重要特征# 体重指数,离散化转换,体重两种情况:标准、肥胖
def convert(df,bmi):df['bmi'] = 'fat' if df['bmi'] >= bmi else 'standard'return df
data = data.apply(convert, axis = 1, args=(30,))
data.head()# 特征提取,离散型数据转换为数值型数据
data = pd.get_dummies(data)
data.head()# 特征和目标值抽取
X = data.drop('charges', axis=1) # 训练数据
y = data['charges'] # 目标值
X.head()
4、特征升维
特征升维是一种数据预处理技术,其核心目的是通过对原始特征进行组合、变换等操作,创造出更多的特征,从而增加数据的维度。
这有助于机器学习模型捕捉到数据中更复杂的模式和关系,尤其适用于处理线性模型难以拟合的非线性数据。
为什么需要特征升维?
在很多实际问题中,数据的特征和目标变量之间可能存在非线性关系。
然而,像线性回归这类基础的线性模型,只能学习到特征和目标变量之间的线性关联。
通过特征升维,能够让线性模型也具备一定捕捉非线性关系的能力,进而提升模型的拟合效果和预测能力。
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import ElasticNet
from sklearn.metrics import mean_squared_error,mean_squared_log_error# 数据拆分
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 特征升维
poly = PolynomialFeatures(degree= 2, include_bias = False)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.fit_transform(X_test)
5、模型训练与评估
普通线性回归:
model_1 = LinearRegression()
model_1.fit(X_train_poly, y_train)
print('测试数据得分:',model_1.score(X_train_poly,y_train))
print('预测数据得分:',model_1.score(X_test_poly,y_test))
print('训练数据均方误差:',np.sqrt(mean_squared_error(y_train,model_1.predict(X_train_poly))))
print('测试数据均方误差:',np.sqrt(mean_squared_error(y_test,model_1.predict(X_test_poly))))print('训练数据对数误差:',np.sqrt(mean_squared_log_error(y_train,model_1.predict(X_train_poly))))
print('测试数据对数误差:',np.sqrt(mean_squared_log_error(y_test,model_1.predict(X_test_poly))))

弹性网络回归:
model_2 = ElasticNet(alpha = 0.3,l1_ratio = 0.5,max_iter = 50000)
model_2.fit(X_train_poly,y_train)
print('测试数据得分:',model_2.score(X_train_poly,y_train))
print('预测数据得分:',model_2.score(X_test_poly,y_test))print('训练数据均方误差为:',np.sqrt(mean_squared_error(y_train,model_2.predict(X_train_poly))))
print('测试数据均方误差为:',np.sqrt(mean_squared_error(y_test,model_2.predict(X_test_poly))))print('训练数据对数误差为:',np.sqrt(mean_squared_log_error(y_train,model_2.predict(X_train_poly))))
print('测试数据对数误差为:',np.sqrt(mean_squared_log_error(y_test,model_2.predict(X_test_poly))))

结论:
- 进行EDA数据探索,可以查看无关紧要特征
- 进行特征工程:删除无用特征、特征离散化、特征提取。这对机器学习都至关重要
- 对于简单的数据(特征比较少)进行线性回归,一般需要进行特征升维
- 选择不同的算法,进行训练和评估,从中筛选优秀算法
做完这两个项目,最大的收获不是模型多准,而是摸清了机器学习项目的套路,现在相信你可以进行简单模型的建立和训练了,快去试试吧!