【昇腾】Benchmark
1. MindIE 服务化
1.1 环境准备
镜像传送门
参数说明:
device用于挂载卡,下面的例子是挂载了8张卡
倒数第二行的镜像名称记得修改
docker run -itd --privileged --name=mindie --net=host \--shm-size 500g \--device=/dev/davinci0 \--device=/dev/davinci1 \--device=/dev/davinci2 \--device=/dev/davinci3 \--device=/dev/davinci4 \--device=/dev/davinci5 \--device=/dev/davinci6 \--device=/dev/davinci7 \--device=/dev/davinci_manager \--device=/dev/hisi_hdc \--device /dev/devmm_svm \-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \-v /usr/local/sbin:/usr/local/sbin \-v /etc/hccn.conf:/etc/hccn.conf \swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:1.0.0-800I-A2-py311-openeuler24.03-lts \bash# 进入容器docker exec -it mindie bash
1.2 MindIE基础配置
cd /usr/local/Ascend/mindie/latest/mindie-service/
vim conf/config.json# 几个参数需要修改:
httpsEnabled: false
modelName: 类似vllm的modelName,用于标识模型,可以随意配置
modelWeightPath: 本地模型路径
npuDeviceIds: 使用的NPU卡,默认[[0,1,2,3]],暂时可不修改
worldSize: 使用的卡数,和npuDeviceIds对应,默认4
# 启动MindIE
cd /usr/local/Ascend/mindie/latest/mindie-service
./bin/mindieservice_daemon
测试服务化
curl -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{"prompt": "你是谁","max_tokens": 200,"repetition_penalty": 1.03,"presence_penalty": 1.2,"frequency_penalty": 1.2,"temperature": 0.5,"top_k": 10,"top_p": 0.95,"stream": false,"ignore_eos": false
}' http://127.0.0.1:1025/generate
2. Benchmark
2.1 配置
# 配置文件权限问题
chmod 640 /usr/local/lib/python3.11/site-packages/mindieclient/python/config/config.json
# 日志打屏
export MINDIE_LOG_TO_STDOUT="benchmark:1; client:1"
2.2 数据集
2.1 合成数据(性能测试)
-
可以指定输入输出的token数量
-
生成的数据为A[空格],如输入token数为5: “A A A A A”
-
输出token数不会因为结束符而停止。可以根据真实场景的输出更好的测试性能。
在任意位置创建:vim synthetic_config.json
样例
{"Input":{"Method": "uniform","Params": {"MinValue": 1, "MaxValue": 200}},"Output": {"Method": "gaussian","Params": {"Mean": 100, "Var": 200, "MinValue": 1, "MaxValue": 100}},"RequestCount": 100
}
| 参数 | 含义 | 取值范围 |
|---|---|---|
| Input | 输入配置 | - |
| Output | 输出配置 | - |
| RequestCount | 请求次数,即样本数量 | [1,1048576] |
| Method | 采样方法 | 取 “uniform”、“gaussian"或"zipf”。 |
| Params | 采样方法中对应的采样参数 | 取值详情请参见表2。 |
| “Input” 中的 “MinValue” | token 数量最小值 | [1,1048576] |
| “Input” 中的 “MaxValue” | token 数量最大值 | [1,1048576] |
| “Output” 中的 “MinValue” | token 数量最小值 | [1,1048576] |
| “Output” 中的 “MaxValue” | token 数量最大值 | [1,1048576] |
| “gaussian” 中的 “Mean” | 高斯分布均值 | [-3.0 x 10^38, 3.0 x 10^38] |
| “gaussian” 中的 “Var” | 高斯分布方差 | [0, 3.0 x 10^38] |
| “zipf” 中的 “Alpha” | zipf分布Alpha系数 | (1.0,10.0] |
| 注:1048576 = 2^20 = 1 M。 |
Benchmark命令: 合成数据配置路径使用**SyntheticConfigPath**指定
benchmark \
--DatasetType "synthetic" \
--ModelName llama_7b \
--ModelPath "/{模型权重路径}/llama_7b" \
--TestType vllm_client \
--Http https://{ipAddress}:{port} \
--ManagementHttp https://{managementIpAddress}:{managementPort} \
--Concurrency 128 \
--MaxOutputLen 20 \
--TaskKind stream \
--Tokenizer True \
--SyntheticConfigPath /{配置文件路径}/synthetic_config.json
测试环境:910B、四卡、DeepSeek-R1-Qwen-32B
# 配置:
{"Input":{"Method": "uniform","Params": {"MinValue": 500, "MaxValue": 1000}},"Output": {"Method": "gaussian","Params": {"Mean": 100, "Var": 200, "MinValue": 1, "MaxValue": 100}},"RequestCount": 2000
}# 输出
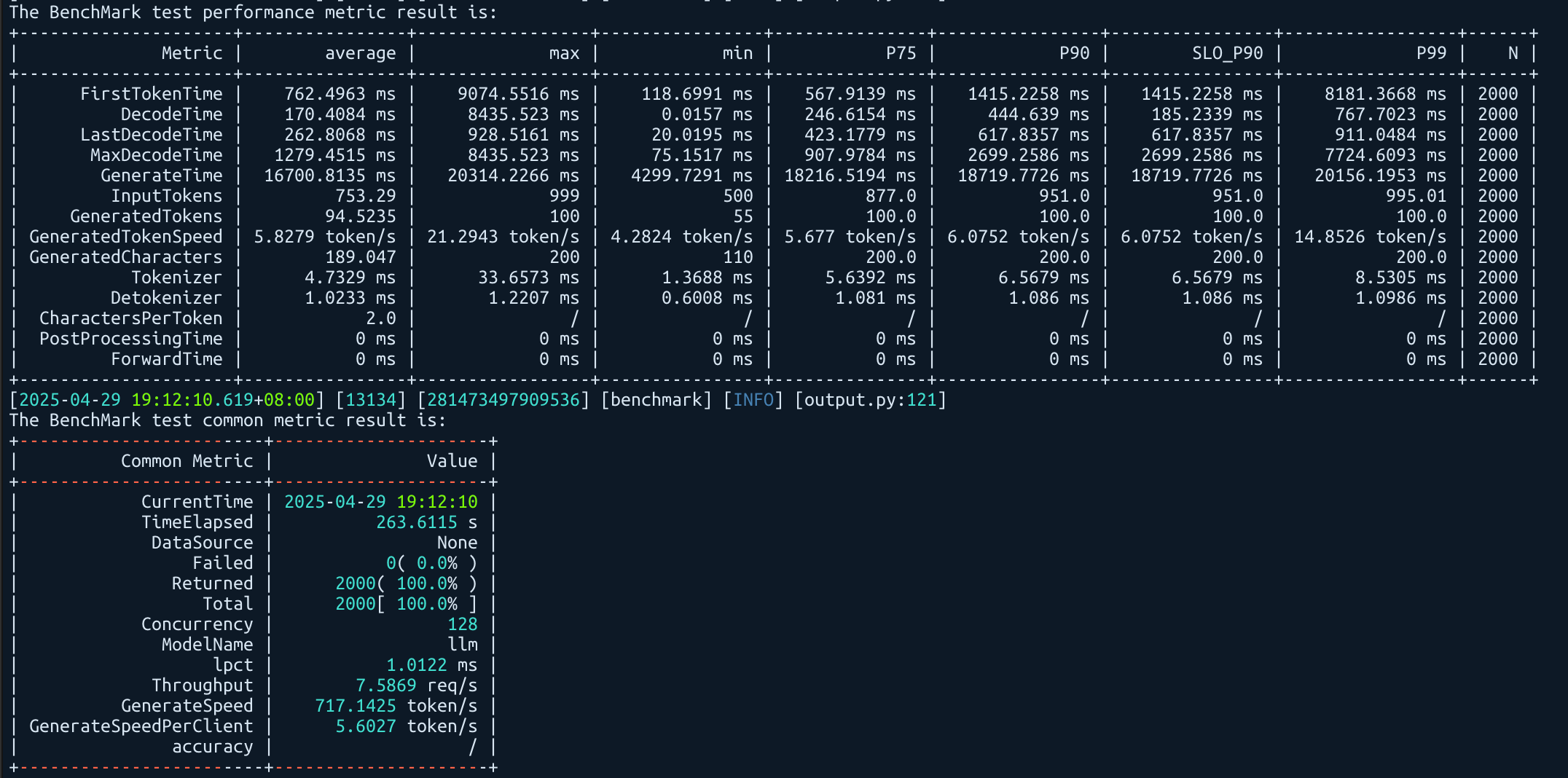
+---------------------+----------------+-----------------+----------------+---------------+----------------+----------------+-----------------+------+
| Metric | average | max | min | P75 | P90 | SLO_P90 | P99 | N |
+---------------------+----------------+-----------------+----------------+---------------+----------------+----------------+-----------------+------+
| FirstTokenTime | 762.4963 ms | 9074.5516 ms | 118.6991 ms | 567.9139 ms | 1415.2258 ms | 1415.2258 ms | 8181.3668 ms | 2000 |
| DecodeTime | 170.4084 ms | 8435.523 ms | 0.0157 ms | 246.6154 ms | 444.639 ms | 185.2339 ms | 767.7023 ms | 2000 |
| LastDecodeTime | 262.8068 ms | 928.5161 ms | 20.0195 ms | 423.1779 ms | 617.8357 ms | 617.8357 ms | 911.0484 ms | 2000 |
| MaxDecodeTime | 1279.4515 ms | 8435.523 ms | 75.1517 ms | 907.9784 ms | 2699.2586 ms | 2699.2586 ms | 7724.6093 ms | 2000 |
| GenerateTime | 16700.8135 ms | 20314.2266 ms | 4299.7291 ms | 18216.5194 ms | 18719.7726 ms | 18719.7726 ms | 20156.1953 ms | 2000 |
| InputTokens | 753.29 | 999 | 500 | 877.0 | 951.0 | 951.0 | 995.01 | 2000 |
| GeneratedTokens | 94.5235 | 100 | 55 | 100.0 | 100.0 | 100.0 | 100.0 | 2000 |
| GeneratedTokenSpeed | 5.8279 token/s | 21.2943 token/s | 4.2824 token/s | 5.677 token/s | 6.0752 token/s | 6.0752 token/s | 14.8526 token/s | 2000 |
| GeneratedCharacters | 189.047 | 200 | 110 | 200.0 | 200.0 | 200.0 | 200.0 | 2000 |
| Tokenizer | 4.7329 ms | 33.6573 ms | 1.3688 ms | 5.6392 ms | 6.5679 ms | 6.5679 ms | 8.5305 ms | 2000 |
| Detokenizer | 1.0233 ms | 1.2207 ms | 0.6008 ms | 1.081 ms | 1.086 ms | 1.086 ms | 1.0986 ms | 2000 |
| CharactersPerToken | 2.0 | / | / | / | / | / | / | 2000 |
| PostProcessingTime | 0 ms | 0 ms | 0 ms | 0 ms | 0 ms | 0 ms | 0 ms | 2000 |
| ForwardTime | 0 ms | 0 ms | 0 ms | 0 ms | 0 ms | 0 ms | 0 ms | 2000 |
+---------------------+----------------+-----------------+----------------+---------------+----------------+----------------+-----------------+------+
[2025-04-29 19:12:10.619+08:00] [13134] [281473497909536] [benchmark] [INFO] [output.py:121]
The BenchMark test common metric result is:
+------------------------+---------------------+
| Common Metric | Value |
+------------------------+---------------------+
| CurrentTime | 2025-04-29 19:12:10 |
| TimeElapsed | 263.6115 s |
| DataSource | None |
| Failed | 0( 0.0% ) |
| Returned | 2000( 100.0% ) |
| Total | 2000[ 100.0% ] |
| Concurrency | 128 |
| ModelName | llm |
| lpct | 1.0122 ms |
| Throughput | 7.5869 req/s |
| GenerateSpeed | 717.1425 token/s |
| GenerateSpeedPerClient | 5.6027 token/s |
| accuracy | / |
+------------------------+---------------------+