TimeDistill:通过跨架构蒸馏的MLP高效长期时间序列预测
原文地址:https://arxiv.org/abs/2502.15016
发表会议:暂定(但是Star很高)
代码地址:无
作者:Juntong Ni (倪浚桐), Zewen Liu (刘泽文), Shiyu Wang(王世宇), Ming Jin(金明), Wei Jin(金卫)
团队:埃默里大学(Emory),格里菲斯大学(Griffith)
同时本文在实验部分我也结合了这篇文章的借鉴:TimeDistill:跨架构知识蒸馏,使用 MLP 实现高效长程时间序列预测-腾讯云开发者社区-腾讯云 https://cloud.tencent.com/developer/article/2503439
https://cloud.tencent.com/developer/article/2503439
摘要
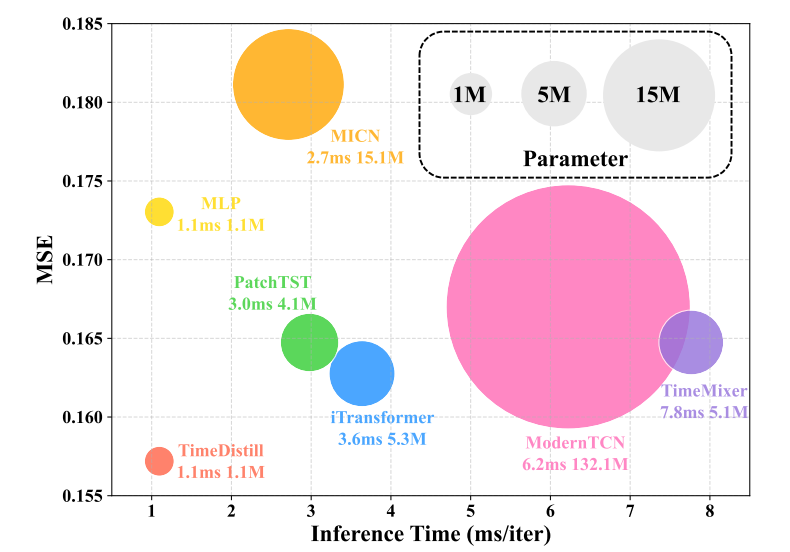
本文提出了一种跨架构知识蒸馏(KD)框架TimeDistill,用于提高轻量级多层感知机(MLP)模型在长期时间序列预测任务上的性能。作者观察到,尽管先进的架构如Transformer和CNN在性能上表现出色,但由于计算和存储需求高,在大规模部署中面临挑战。相比之下,简单的MLP模型具有更高的效率,但性能较低。TimeDistill的关键思想是从教师模型(如Transformer、CNN)中提取补充模式,特别是时间和频域中的多尺度和多周期模式,并将其蒸馏到学生MLP模型中。作者从理论上分析了TimeDistill的优势,表明所提出的蒸馏过程可以视为一种特殊的mixup数据增强策略。实验结果表明,TimeDistill在所有数据集上都能显著优于独立的MLP模型,最高可提升18.6%,并且在大多数情况下也优于教师模型,同时实现了高达7倍的推理加速和高达130倍的参数减少。
此外,作者还探讨了TimeDistill的versatility,包括使用不同的教师模型、学生模型以及不同的历史窗口长度。结果表明,TimeDistill能够从各种教师模型中有效地学习知识,并且能够显著提升其他轻量级模型(如TSMixer和LightTS)的性能。同时,TimeDistill在不同历史窗口长度下都能保持优于教师模型的性能。
总之,本文提出的TimeDistill框架为长期时间序列预测任务提供了一种高效且通用的解决方案,在保持轻量级模型架构的同时,能够显著提升预测性能,并且具有良好的适应性。
科普
- KD(知识蒸馏)的概念:一种将知识从更大更复杂的模型(教师)转移到更小更简单的模型(学生)的技术,同时保持可比的性能。
- transformer的做法:利用了捕捉成对依赖关系和提取顺序数据中的多级表示的强大能力
教师模型里的什么“知识”应该提炼到MLP?
利用不同架构的互补能力的价值,主要聚焦于两个关键的时序模式:
- 多尺度模式 : 现实世界的时间序列通常在多个时间尺度上显示变化。表现良好的模型在最细粒度尺度上也能准确地在更粗糙的尺度上表现, 而 MLP 在大多数尺度上都失败。
- 多周期模式 : 时间序列通常表现出多个周期性。表现良好的模型能够捕捉与真实数据相似的周期性, 但 MLP 无法捕捉这些周期性。
TimeDistill和传统KD的区别,以及它的处理办法和优点?
TIMEDISTILL专注于对齐MLP和教师之间的多尺度和多周期模式,而不是仅仅匹配传统KD中的预测:首先对时间序列进行下采样以进行时间多尺度对齐,并应用快速傅立叶变换(FFT)来对齐频域中的周期分布。KD过程可以离线进行,将繁重的计算从延迟关键的推理阶段(毫秒级问题)转移到对时间不太敏感的训练阶段,在那里可以接受更长的处理时间。
与之前只关注预测输出的LightTS(另一篇KD论文)不同
1️⃣ LightTS(旧方法):就像专门给「学霸小组」(集成分类器)设计的教学大纲,只能让组内学霸互相学习。
但问题是:
- 只适用于特定班级(集成模型)
- 无法推广到其他类型的学生(比如普通学生MLP)
2️⃣ 本文方法(新方法):更像针对「时间科目」的定制教学,专门攻克两类难题:
- 多尺度题(比如同时分析每小时+每天的交通数据变化)
- 多周期题(比如识别天气中的日循环+年循环规律)
并且允许:
✅ 跨班级教学(如让Transformer学霸教MLP学渣)
✅ 提炼学科专用技巧(而非通用解题套路)
为什么选择蒸馏?
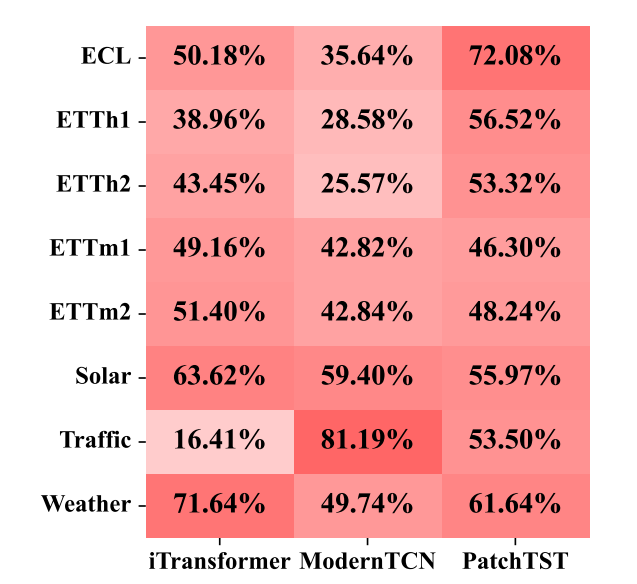
MLP(多层感知机)在效率上的优势以及其在性能上的局限性,并提出知识蒸馏(KD)作为一种可能的解决方案。尽管MLP在整体性能上可能不如Transformer或CNN等复杂模型,但它在特定样本上可能表现更好。通过分析MLP与教师模型的预测误差,可以发现MLP在某些子集上具有优势,这为知识蒸馏提供了潜在的价值。
关键点 MLP的效率与性能权衡: MLP在效率上表现优异,但在整体性能上通常不如Transformer和CNN模型。 尽管如此,MLP在某些样本上可能优于教师模型,这表明它们在特定任务上具有不同的优势。
胜率的计算: 通过比较MLP和教师模型的预测误差,计算MLP优于教师模型的比例(胜率)。 实验表明,尽管MLP总体上不如教师模型,但它在某些数据集(如Traffic)上表现出较高的胜率(81.19%),说明不同模型在不同子集上的表现存在差异。
知识蒸馏的潜力: 从教师模型中提取互补知识到MLP中,可以弥补MLP的不足,同时利用其在特定样本上的优势。
知识蒸馏的局限性:
- 过拟合噪声:直接对齐预测可能过拟合教师模型中的噪声,导致知识不稳定。
- 复杂模式的复制困难:MLP可能难以直接复制教师模型预测中的复杂模式(如季节性、趋势等)。
- 忽略中间特征:仅对齐预测忽略了教师模型中间特征的有价值知识。
KD应该提取什么?
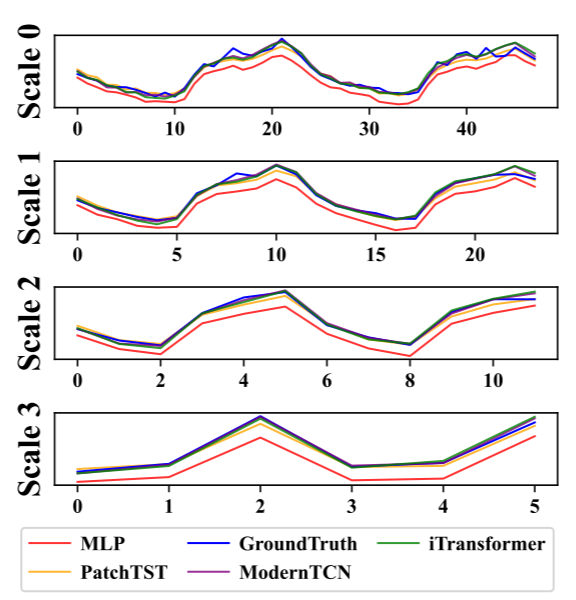
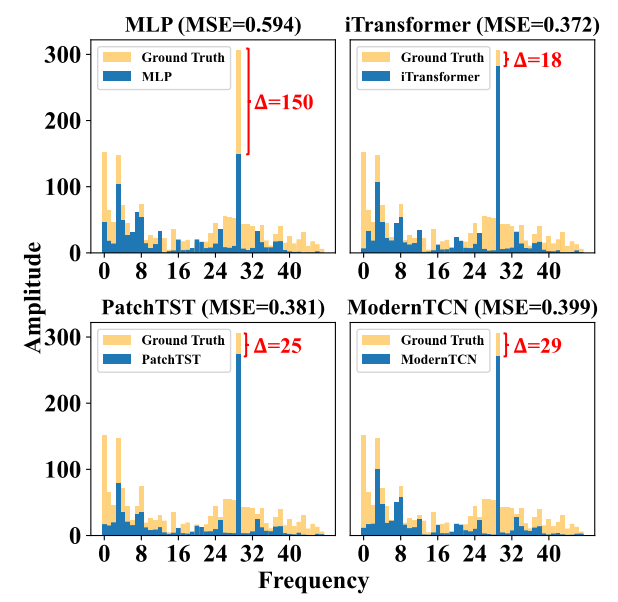
MLP因难以捕获时间序列的多尺度趋势和周期性模式导致预测偏差。实验显示,教师模型在粗粒度趋势(如尺度3)和主频周期性上表现优异,而MLP显著落后。因此,需通过知识蒸馏将教师模型的这些互补模式引入MLP,以提升其时间序列预测能力。
时间序列中的周期性在频域中通过将时间序列转换为频谱图来显现,其中x轴表示频率,周期性计算为时间序列长度 S 除以频率。
下采样(Downsampling) 是指通过降低时间序列的分辨率(如减少数据点的数量),提取更粗粒度的数据表示。其核心目的是捕捉数据的宏观趋势或长期依赖,同时过滤掉高频噪声或细节波动。常用方法包括:
- 平均池化:将相邻多个数据点取平均,合并为一个点。
- 最大/最小池化:取相邻点的最大值或最小值。
- 卷积操作:使用低通滤波器(如移动平均)平滑数据后,按步长跳过部分点。
知识蒸馏(KD)在时间序列中的演进
1️⃣ 传统KD(Hinton, 2015): 核心:将复杂教师模型的知识迁移至轻量学生模型 局限:依赖输出分布对齐,未针对时序特性设计
2️⃣ 时序领域现有方法: CAKD(Xu等, 2022):结合对抗学习+对比学习的两阶段蒸馏(特征级+预测级) LightTS(Campos等, 2023):专为集成分类器设计,架构兼容性差 ❗ 共性缺陷:未聚焦时序特有模式(如多尺度、多周期)
3️⃣ 本文创新: 时序模式蒸馏:显式提取多尺度(时间域)与多周期(频域)关键模式 跨架构突破:首次实现异构模型间KD(如Transformer→MLP),解决架构差异挑战 (对比:传统KD通用但粗放 → 本文定向提炼时序核心规律 + 跨架构兼容性)
方法
背景与目标
提出了一个新颖的知识蒸馏(KD)框架 TIMEDILL,用于时间序列。其核心思想是将知识从一个固定的、预训练的教师模型 转移到学生 MLP 模型
。
模型结构
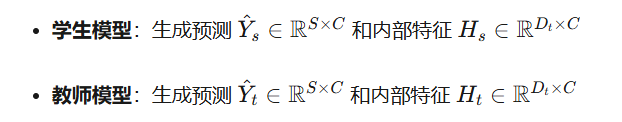
优化目标
整个框架的优化目标是通过监督损失和知识蒸馏损失
和
来最小化学生模型的预测误差和特征误差。

pipeline
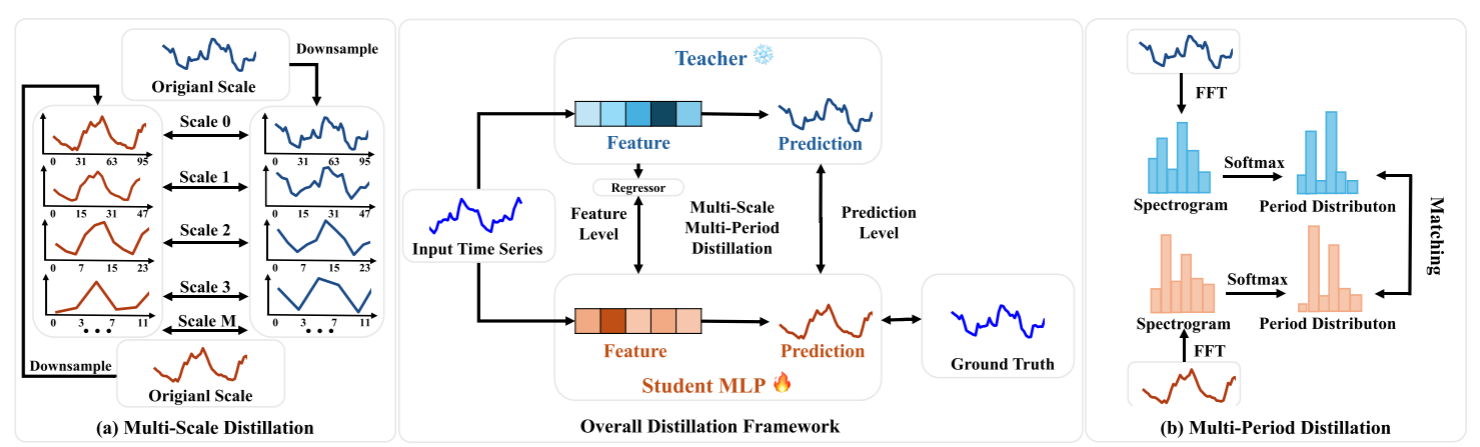
(a)多尺度蒸馏涉及将原始时间序列下采样为多个较粗尺度,并在学生和教师之间调整这些尺度。
(b)多周期蒸馏应用FFT将时间序列转换为谱图,然后在应用softmax之后匹配周期分布。
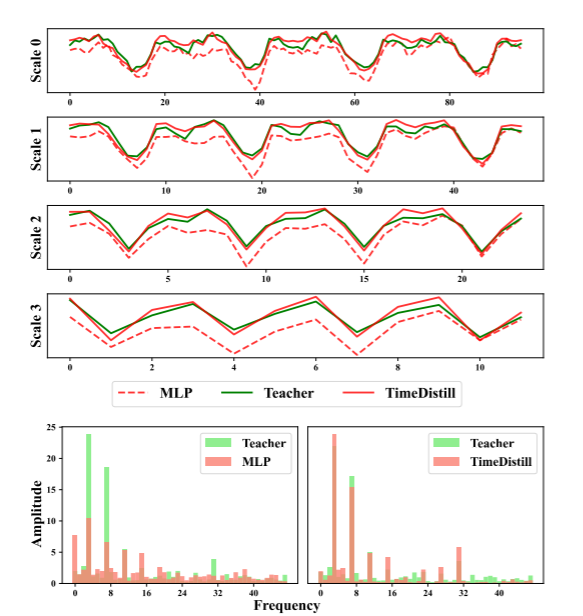
解释图(a)
多尺度蒸馏的过程,用于将教师模型的多尺度模式知识转移到学生模型中 教师模型和学生模型的比较:
- 教师模型(蓝色曲线)在所有尺度上都能较好地捕捉时间序列的趋势和模式。
- 学生模型(棕色曲线)在较细的尺度(如Scale 0)上可能表现较好,但在较粗的尺度(如Scale 3)上表现较差,显示出其在处理多尺度模式上的局限性。
多尺度蒸馏
核心概念
TimeDistill 的核心组件之一是多尺度蒸馏,通过不同采样率表示同一时间序列,使 MLP 能有效捕捉粗粒度和细粒度模式。通过预测级别和特征级别的联合蒸馏,确保 MLP 不仅复现教师模型的多尺度预测,还能对齐其中间层的内部表示。


多周期蒸馏
预测层面

特征层面


总体优化与理论分析
总体训练损失

理论解释
从数据增强的角度理解多尺度和多周期蒸馏损失,其类似于mixup策略。这种蒸馏方法通过混合真实值和教师预测来增强数据,为时间序列预测带来以下好处:增强泛化能力、显式整合模式、稳定训练动态。这些优势有助于减轻过拟合、提供隐藏模式见解,并支持更平滑的优化和更好的收敛。
- 通过同时优化监督损失(学生直接学真实值)和多尺度蒸馏损失(学生学教师的多尺度特征),实际上就相当于在优化这些“增强样本”上的损失。
- 通过同时优化监督损失(学生直接学真实值的周期分布)和多周期蒸馏损失(学生学教师的周期分布),实际上就相当于在优化这些“增强样本”上的KL散度损失。 好处:这种混合策略让学生的训练目标更平滑,帮助它更好地捕捉周期性模式,从而提高预测的稳定性。
想象一下,你在教一个学生做数学题,但直接教他可能会有些吃力。于是,你决定用一种特别的方法来辅助教学:把原题(原始数据)和标准答案(教师模型的预测)混合起来,形成一个“增强版”的题目。同时,你希望学生不仅能做对原题(监督损失),还能从标准答案里学到解题思路(周期蒸馏损失)。

实验
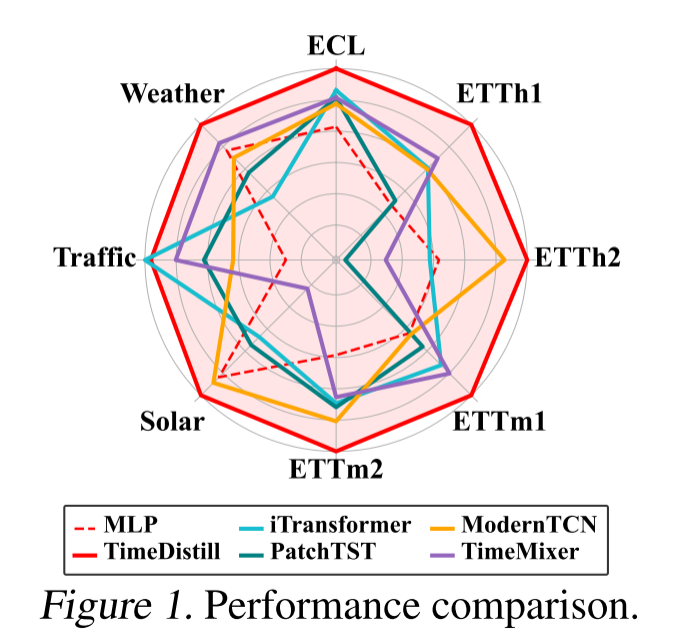
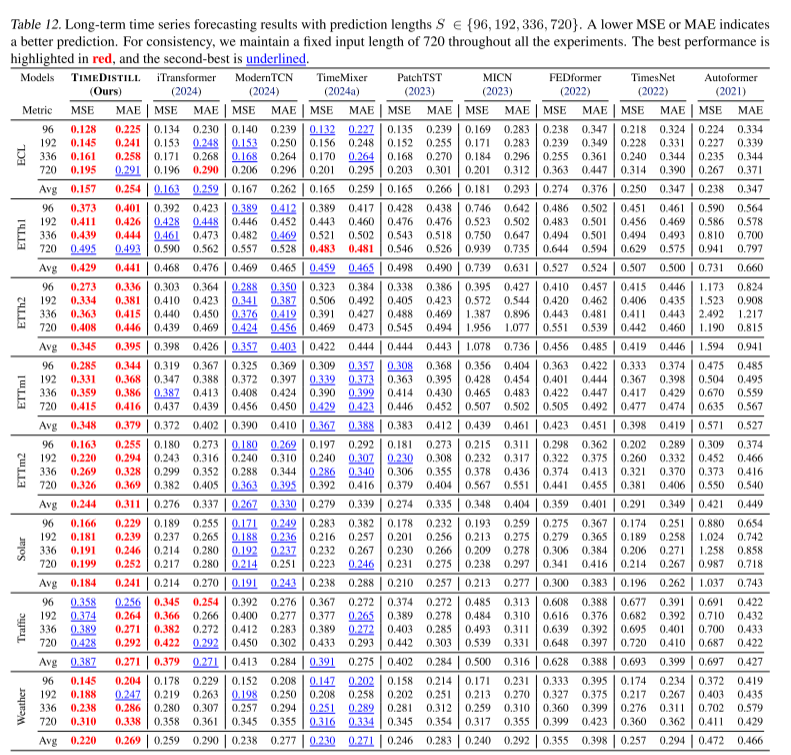
效果全面领先
TimeDistill在8个时序数据集上进行实验,其中7个数据集的MSE指标优于基线教师模型,在所有数据集的MAE指标上均取得最佳表现,展现出卓越的预测能力。
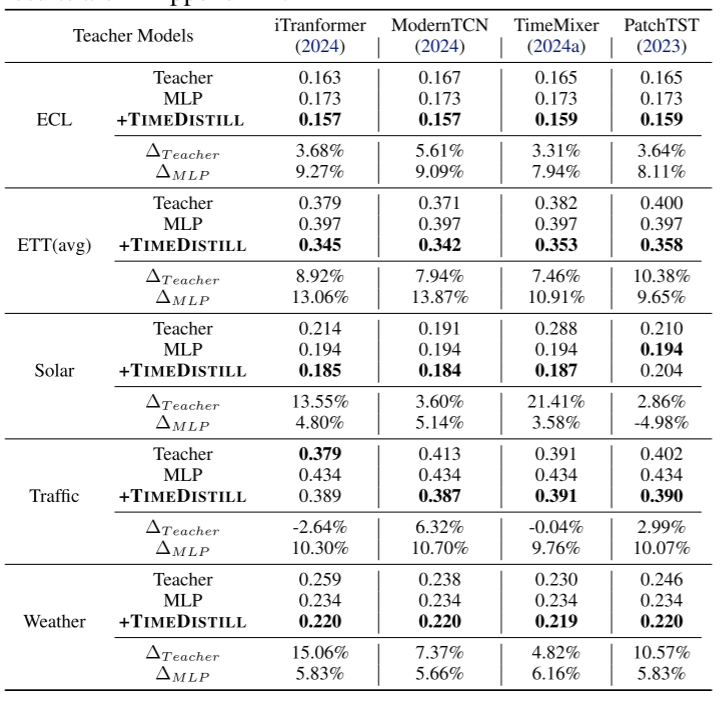
兼容多种教师模型
TimeDistill适用于多种教师模型,能够有效蒸馏知识并提升MLP学生模型的性能,同时相较教师模型本身也有显著提升。
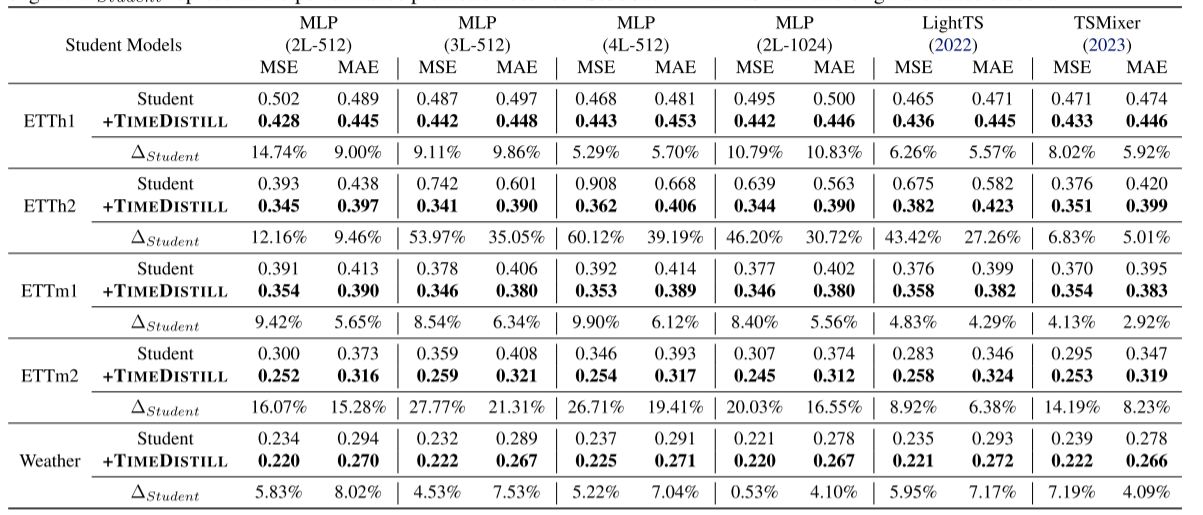
兼容多种学生模型
TimeDistill不仅适用于 MLP 结构,还可以增强轻量级学生模型的性能。例如,在以ModernTCN作为教师模型的实验中,TimeDistill使两个轻量模型TSMixer和LightTS的MSE分别降低6.26%和8.02%,验证了其在不同学生模型上的适应性。
兼容多种回溯窗口长度
时序模型的预测性能往往随回溯窗口(历史观测长度)变化而波动,而 TimeDistill在所有窗口长度下均能提升MLP表现,甚至超越教师模型,体现出对不同时间依赖模式的强大适应能力。
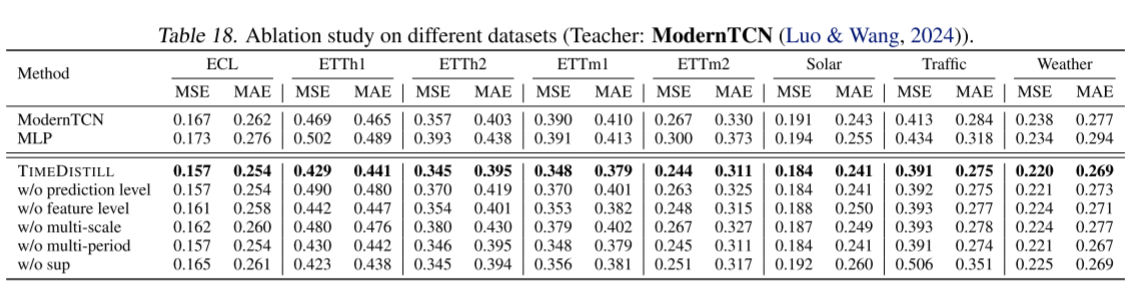
消融实验
TimeDistill通过消融实验进一步验证了模型设计的合理性。值得注意的是,即使去掉Ground Truth监督信号(w/o sup),TimeDistill仍然能够显著提升MLP预测精度,表明其可以从教师模型中有效学习到丰富的知识。
idea
从先进的时间序列模型中提取,例如时间序列基础模型,并结合多变量模式。