【Hive入门】Hive性能优化:执行计划分析EXPLAIN命令的使用
目录
1 EXPLAIN命令简介
1.1 什么是EXPLAIN命令?
1.2 EXPLAIN命令的语法
2 解读执行计划中的MapReduce阶段
2.1 执行计划的结构
2.2 Hive查询执行流程
2.3 MapReduce阶段的详细解读
3 识别性能瓶颈
3.1 数据倾斜
3.2 Shuffle开销
3.3 性能瓶颈识别与优化
4 总结
在大数据处理中,Hive作为Hadoop生态中的核心组件,广泛应用于数据仓库和数据分析场景。然而,随着数据量的增长和查询复杂度的提升,Hive查询的性能问题逐渐成为开发者和数据工程师关注的焦点。为了优化Hive查询性能,深入理解查询的执行计划至关重要。Hive提供了EXPLAIN命令,可以帮助我们分析查询的执行计划,识别性能瓶颈,从而进行针对性的优化。
1 EXPLAIN命令简介
1.1 什么是EXPLAIN命令?
EXPLAIN是Hive中用于分析查询执行计划的命令。通过 EXPLAIN,我们可以查看查询的详细执行步骤,包括MapReduce阶段、数据流、操作符等信息。这些信息对于优化查询性能至关重要。
1.2 EXPLAIN命令的语法
EXPLAIN [FORMATTED|EXTENDED|DEPENDENCY|AUTHORIZATION] query;
- FORMATTED:以易读的格式输出执行计划
- EXTENDED:输出更详细的执行计划信息,包括操作符的详细信息
- DEPENDENCY:显示查询依赖的表和分区
- AUTHORIZATION:显示查询的授权信息
2 解读执行计划中的MapReduce阶段
2.1 执行计划的结构
Hive查询的执行计划通常分为以下几个阶段:
- Parse:解析SQL语句,生成抽象语法树(AST)
- Semantic Analysis:语义分析,验证表和列的存在性
- Logical Plan:生成逻辑执行计划
- Optimization:优化逻辑执行计划
- Physical Plan:生成物理执行计划
- MapReduce:将物理计划转换为MapReduce任务
2.2 Hive查询执行流程

- SQL Query:输入SQL查询语句
- Parse:解析SQL语句,生成抽象语法树(AST)
- Semantic Analysis:验证表和列的存在性,确保查询语义正确
- Logical Plan:生成逻辑执行计划,描述查询的逻辑操作
- Optimization:优化逻辑执行计划,提高查询效率
- Physical Plan:生成物理执行计划,描述查询的具体执行步骤
- MapReduce Execution:将物理计划转换为MapReduce任务并执行
- Query Result:返回查询结果
2.3 MapReduce阶段的详细解读
在 EXPLAIN的输出中,MapReduce阶段通常包含以下信息:
- Map Operator Tree:描述Map阶段的操作符
- Reduce Operator Tree:描述Reduce阶段的操作符
- Group By Operator:描述分组操作
- Select Operator:描述选择操作
- Join Operator:描述连接操作
- 示例:
EXPLAIN
SELECT department, COUNT(*) as emp_count
FROM employees
GROUP BY department;3 识别性能瓶颈
3.1 数据倾斜
数据倾斜是Hive查询中常见的性能问题,通常发生在 GROUP BY或 JOIN操作中。数据倾斜会导致某些Reducer任务处理的数据量远大于其他任务,从而拖慢整体查询速度。识别方法:
- 检查EXPLAIN输出中的Group By Operator和Join Operator,观察是否有某些键值的数据量异常大
- 使用COUNT和GROUP BY分析数据分布
解决方案:
- 使用随机数对数据进行分桶
- 增加Reducer数量
- 使用skewjoin优化连接操作
3.2 Shuffle开销
Shuffle是MapReduce阶段中数据从Map任务传输到Reduce任务的过程,通常会产生较大的网络和磁盘开销。识别方法:
- 检查EXPLAIN输出中的Reduce Operator Tree,观察Shuffle数据量
- 使用Hadoop的JobTracker或YARN的ResourceManager查看Shuffle阶段的详细指标
解决方案:
- 优化数据分区,减少Shuffle数据量
- 使用压缩技术减少网络传输开销
- 调整Reducer数量,平衡Shuffle负载
3.3 性能瓶颈识别与优化
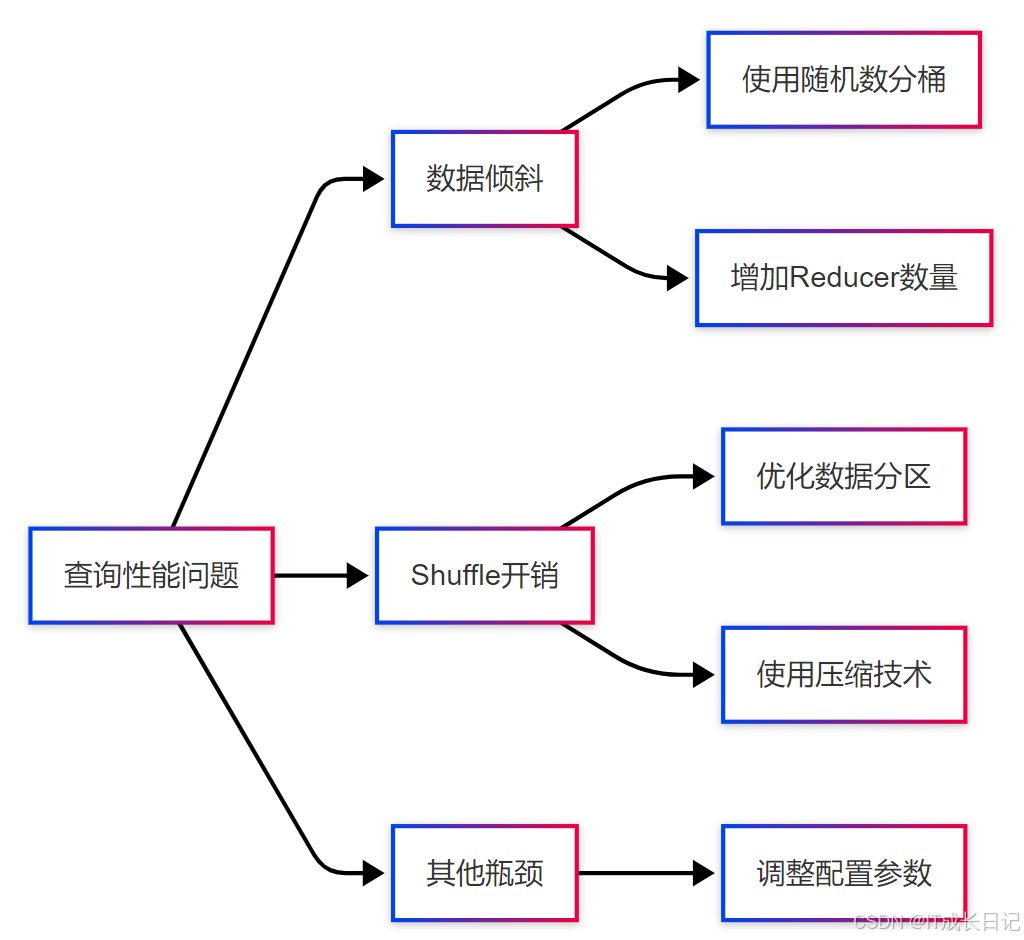
- 查询性能问题:发现查询性能不佳
- 数据倾斜:识别数据倾斜问题,采取分桶或增加Reducer数量等措施
- Shuffle开销:识别Shuffle开销问题,优化数据分区或使用压缩技术
- 其他瓶颈:调整Hive配置参数,优化查询性能
4 总结
EXPLAIN命令是Hive性能优化的重要工具,通过分析执行计划中的MapReduce阶段,我们可以识别查询的性能瓶颈,如数据倾斜和Shuffle开销,并采取针对性的优化措施。