大数据平台与数据仓库的核心差异是什么?
随着数据量呈指数级增长,企业面临着如何有效管理、存储和分析这些数据的挑战。 大数据平台和 数据仓库作为两种主流的数据管理工具,常常让企业在选型时感到困惑,它们之间的界限似乎越来越模糊,功能也有所重叠。本文旨在厘清这两种技术的核心差异,并为企业提供一个实用的选型参考框架。
基础概念解析
什么是大数据平台?
大数据平台是为了处理海量、多样化数据而设计的分布式计算和存储系统。它不仅仅是一种技术,而是一整套解决方案,包括数据采集、存储、处理、分析和可视化等多个环节。
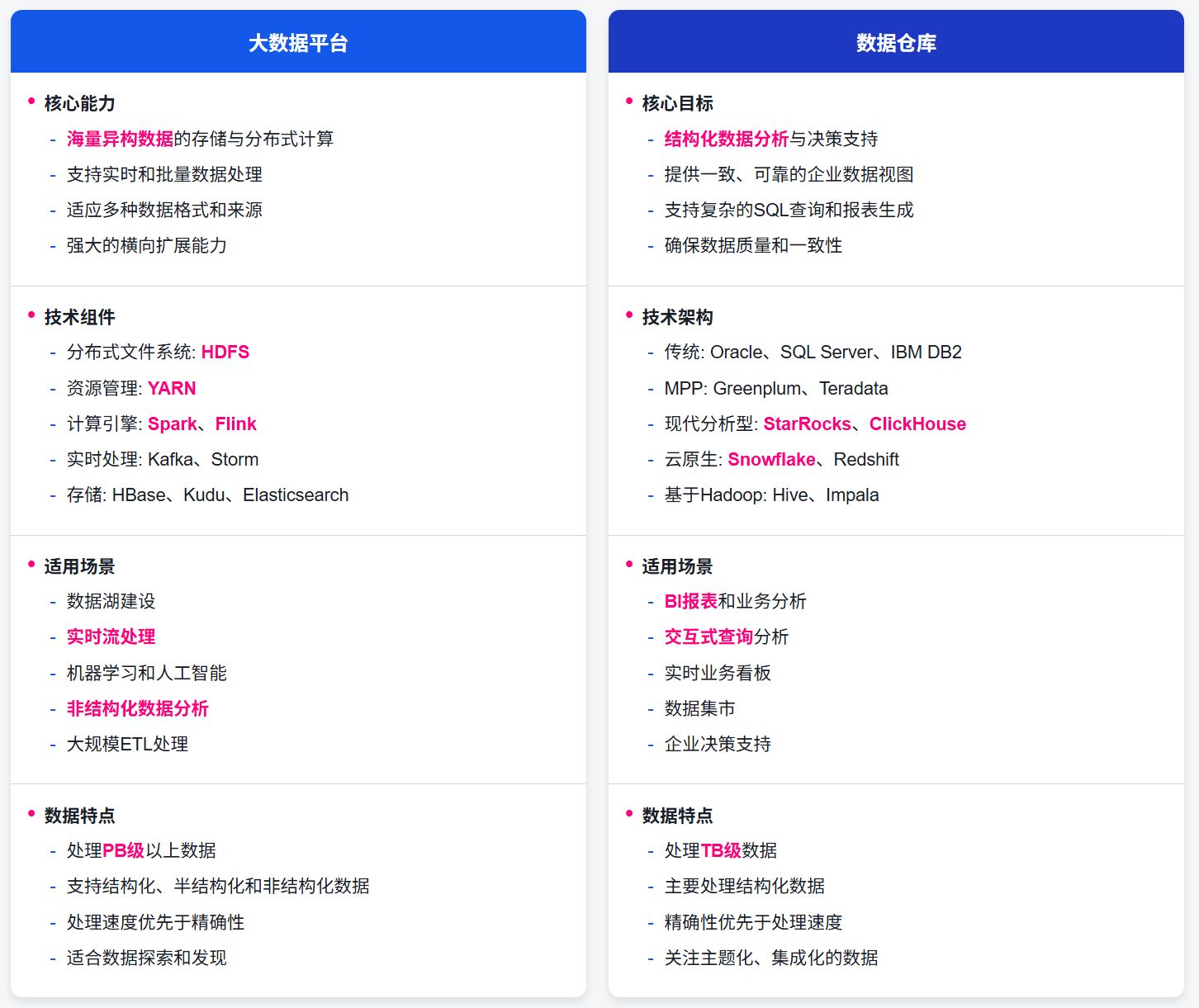
核心能力:
- 海量异构数据的存储与分布式计算
- 实时和批量数据处理
- 支持多种数据格式和来源
- 横向扩展能力强
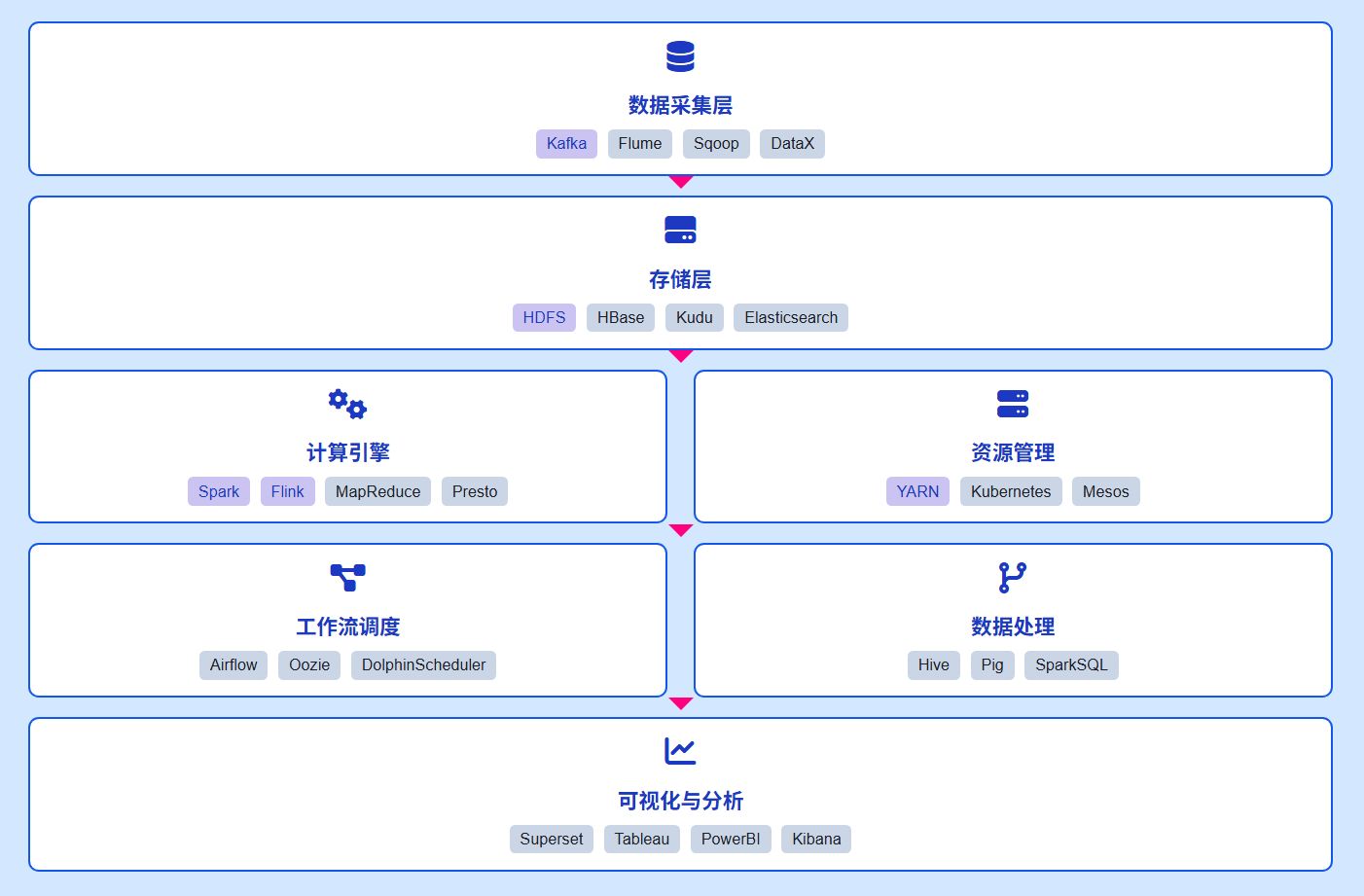
典型组件: 大数据平台通常由 Hadoop / Spark / Flink 等生态系统组成。Hadoop 提供分布式文件系统(HDFS)和资源管理(YARN),Spark 提供内存计算框架,Flink 则专注于流处理。这些组件共同构成了一个完整的大数据处理生态系统。
适用场景:
- 数据湖 建设:存储和管理各种原始数据,为后续的数据探索和分析提供基础。
- 实时流处理:处理持续生成的数据流,如用户点击流、传感器数据、金融交易等。
- 机器学习和人工智能:为训练复杂的机器学习模型提供大规模数据处理能力。
- 非结构化数据分析:处理文本、图像、视频等非结构化数据,提取有价值的信息。
- 大规模 ETL 处理:对原始数据进行清洗、转换和加载,为数据分析做准备。
什么是数据仓库?
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持企业的决策分析。它将来自不同业务系统的数据整合在一起,构建一个统一的数据视图,为业务分析和决策提供支持。
核心目标:
- 结构化数据分析与决策支持
- 提供一致、可靠的企业数据视图
- 支持复杂的 SQL 查询和报表生成
- 确保数据质量和一致性
架构演进: 数据仓库的架构已从传统的集中式系统演变为现代分析型数据库。传统数据仓库如 Oracle、SQL Server 主要依赖于垂直扩展,而现代数据仓库如 StarRocks 、ClickHouse、Snowflake 则采用了分布式架构,支持更灵活的扩展和更快的查询性能。
适用场景:
- BI 报表:为业务分析提供数据支持
- 交互式分析:支持用户进行即席查询
- 实时看板:展示关键业务指标的实时状态
- 数据集市:为特定业务部门提供定制化的数据视图
核心差异对比
数据类型差异
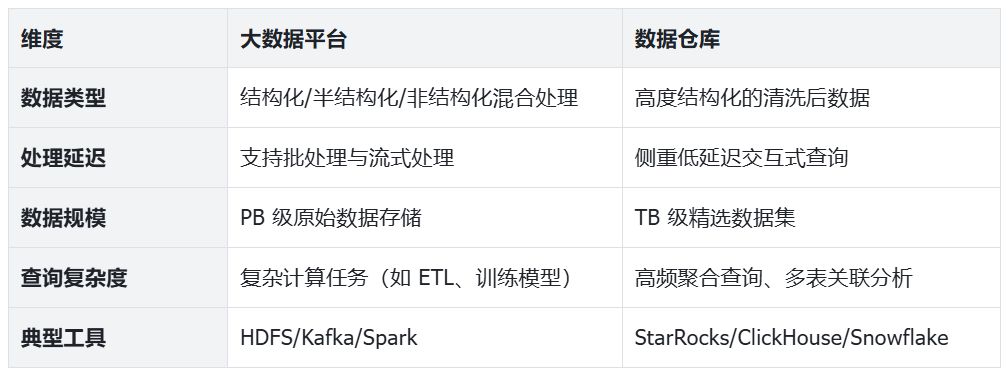
大数据平台: 大数据平台的一个显著特点是能够处理多种类型的数据。它不仅可以处理结构化数据(如关系型数据库中的表格数据),还能处理半结构化数据(如 JSON、XML)和非结构化数据(如文本、图像、视频)。这种灵活性使得大数据平台能够从各种来源收集和分析数据,包括社交媒体、传感器、日志文件等。例如,一家电子商务公司可以使用大数据平台来分析用户在网站上的行为(结构化数据)、社交媒体上的评论(非结构化数据)以及移动应用的使用模式(半结构化数据),从而全面了解客户需求和行为。
数据仓库: 相比之下,数据仓库主要处理高度结构化的数据。这些数据通常经过了严格的 ETL(提取、转换、加载)过程,确保了数据的质量、一致性和可靠性。数据仓库中的数据通常按照预定义的模式组织,便于进行复杂的查询和分析。数据仓库的这种特性使其特别适合于需要高度可靠和一致数据的业务智能和报告应用。例如,财务报表、销售分析和客户细分等任务都需要高质量、结构化的数据来确保结果的准确性。
处理延迟差异
大数据平台: 大数据平台支持多种处理模式,包括批处理和流式处理。批处理适用于处理大量历史数据,通常以小时或天为单位运行。而流式处理则允许实时或近实时地处理数据,适用于需要即时响应的场景。例如,Apache Spark 可以用于批量处理大量历史数据以生成趋势报告,而 Apache Flink 则可以用于实时检测欺诈交易或监控系统异常。
数据仓库: 传统数据仓库主要侧重于批处理,但现代数据仓库已经发展出了支持低延迟交互式查询的能力。这使得用户可以快速获取查询结果,而不必等待批处理作业完成。例如,StarRocks 等现代分析型数据库可以在秒级或亚秒级完成复杂的聚合查询,使得业务分析师能够快速探索数据并获取洞察。
数据规模差异
大数据平台: 大数据平台设计用于处理 PB(拍字节)级甚至更大规模的数据。它们采用分布式存储和计算架构,可以通过添加更多节点来水平扩展,从而应对不断增长的数据量。例如,一家大型社交媒体平台每天可能会生成数 PB 的用户行为数据,这些数据需要被存储和分析以优化用户体验和广告投放。
数据仓库: 数据仓库通常处理 TB(太字节)级的精选数据集。这些数据经过了筛选和聚合,只保留了对业务决策有价值的信息。虽然现代数据仓库也支持 PB 级数据,但它们通常不会存储原始数据,而是存储经过处理的、结构化的数据。
查询复杂度差异
大数据平台: 大数据平台擅长执行复杂的计算任务,如 ETL 处理、机器学习模型训练、图分析等。这些任务通常涉及大量的数据转换和计算,需要分布式计算框架的支持。例如,使用 Spark MLlib 训练一个推荐系统模型,或者使用 MapReduce 进行大规模的日志分析,都是大数据平台的典型应用。
数据仓库: 数据仓库专为高频聚合查询和多表关联分析而优化。它们通常使用列式存储、索引和物化视图等技术来加速这类查询。例如,一个销售分析师可能需要快速查询不同地区、不同产品类别的销售趋势,并与历史数据进行比较。数据仓库可以在几秒钟内完成这类复杂的多维分析查询。
实践中的互补关系
尽管大数据平台和数据仓库在设计理念和适用场景上存在差异,但在实际应用中,它们往往是互补的,而非相互排斥的。现代数据架构通常会同时包含这两种技术,以充分发挥各自的优势。
湖仓:混合架构成为现代技术选型的平衡
近年来, 湖仓一体化(Lakehouse)架构的兴起标志着大数据平台和数据仓库的融合趋势。数据湖仓结合了数据湖的灵活性和数据仓库的结构化查询能力,为企业提供了一个统一的数据平台。
数据湖仓的特点:
- 支持结构化和非结构化数据
- 提供 ACID 事务支持
- 支持模式演化和数据版本控制
- 结合了批处理和流处理能力
- 提供高性能 SQL 查询和分析
在实际应用中,常见的架构模式是“分层处理”:原始数据首先进入数据湖,然后经过处理和转换后加载到数据仓库中。这种模式充分利用了两种技术的优势。
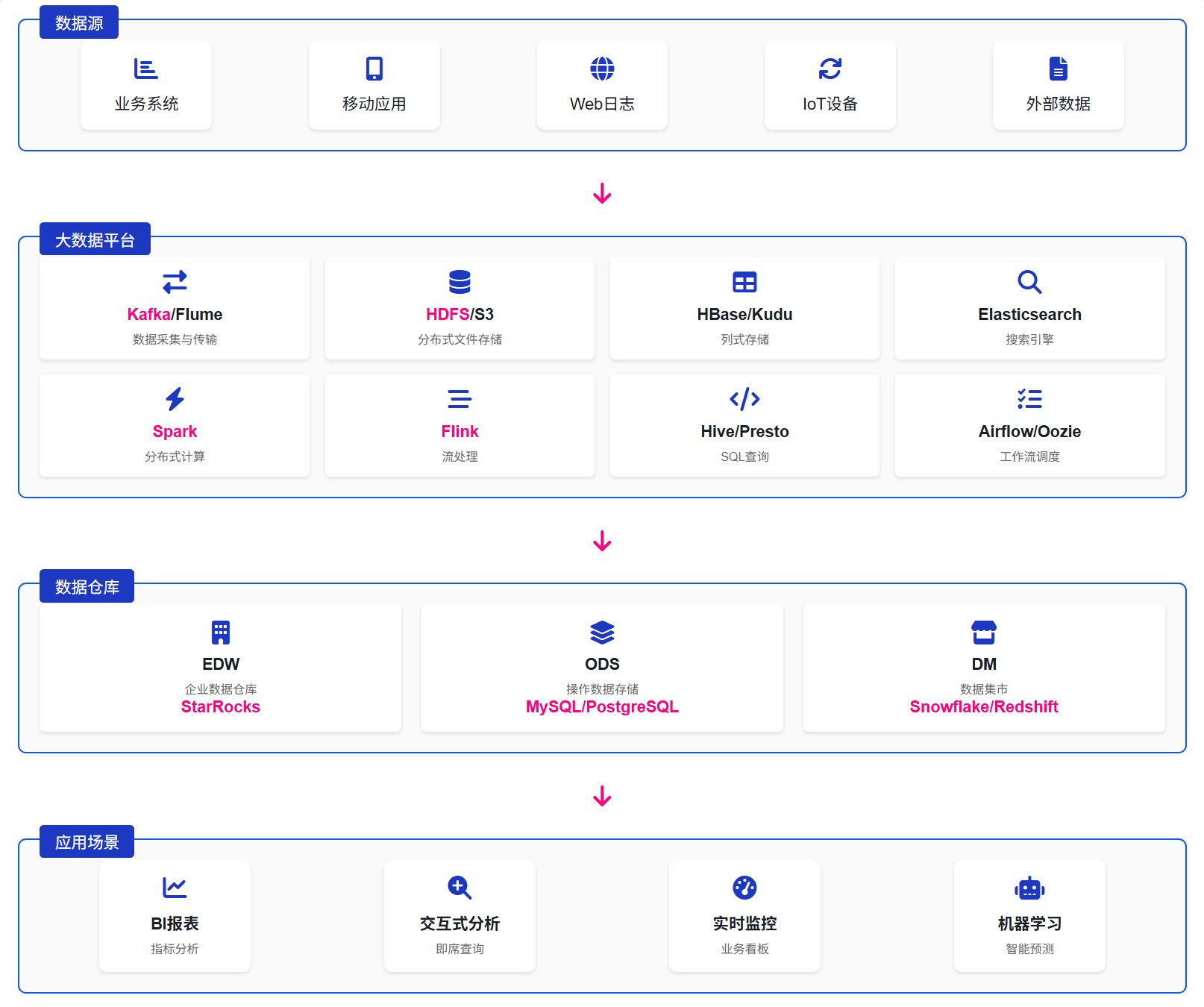
典型的数据流程:
- 数据采集:从各种来源收集原始数据
- 数据存储:将原始数据存储在数据湖中
- 数据处理:使用大数据处理工具对数据进行清洗、转换和聚合
- 数据加载:将处理后的数据加载到数据仓库中
- 数据分析:使用数据仓库进行业务分析和报表生成
这种分层架构使企业能够同时保留原始数据的完整性和提供高性能的分析查询能力。
实践案例:同程旅行——流式湖仓与用户画像优化
StarRocks 通过存算分离、联邦查询、物化视图、主键模型四大核心技术,构建了“极速统一”的湖仓新范式。以同程旅行为例:
痛点
用户画像分析需处理复杂多表关联查询,原有 Spark+Kudu 方案存在查询延迟高、资源消耗大等问题。
解决方案
- 构建流式湖仓:采用 Flink+Paimon+StarRocks 技术栈,ODS 层数据实时写入 Paimon 湖表,StarRocks 作为查询引擎加速 ADS 层分析。
- 物化视图分层建模:通过 StarRocks 物化视图自动匹配查询模式,减少人工建模成本,TPCH 10G 查询性能提升 3 倍。
收益
- 实时订单分析响应速度提升至 TP99<10 秒,资源利用率优化 40%。
- 统一查询引擎替代 ClickHouse/Greenplum,运维复杂度降低 70%
企业可以结合自身业务特点和发展规划,选择最适合的大数据平台或数据仓库解决方案,实现数据价值的最大化。