Qwen3 模型架构和能力概览
模型架构与能力
本文为 Qwen3 模型架构和能力提供了全面的技术概览。它详细介绍了模型变体、核心架构组件以及使 Qwen3 与系列中前代模型脱颖而出的关键能力。
关于安装和基本使用的相关信息,请参阅 快速入门。关于部署选项,请参阅 部署。
模型变体与架构
Qwen3 在语言模型架构方面取得了显著进步,涵盖了密集模型和混合专家(MoE)变体。
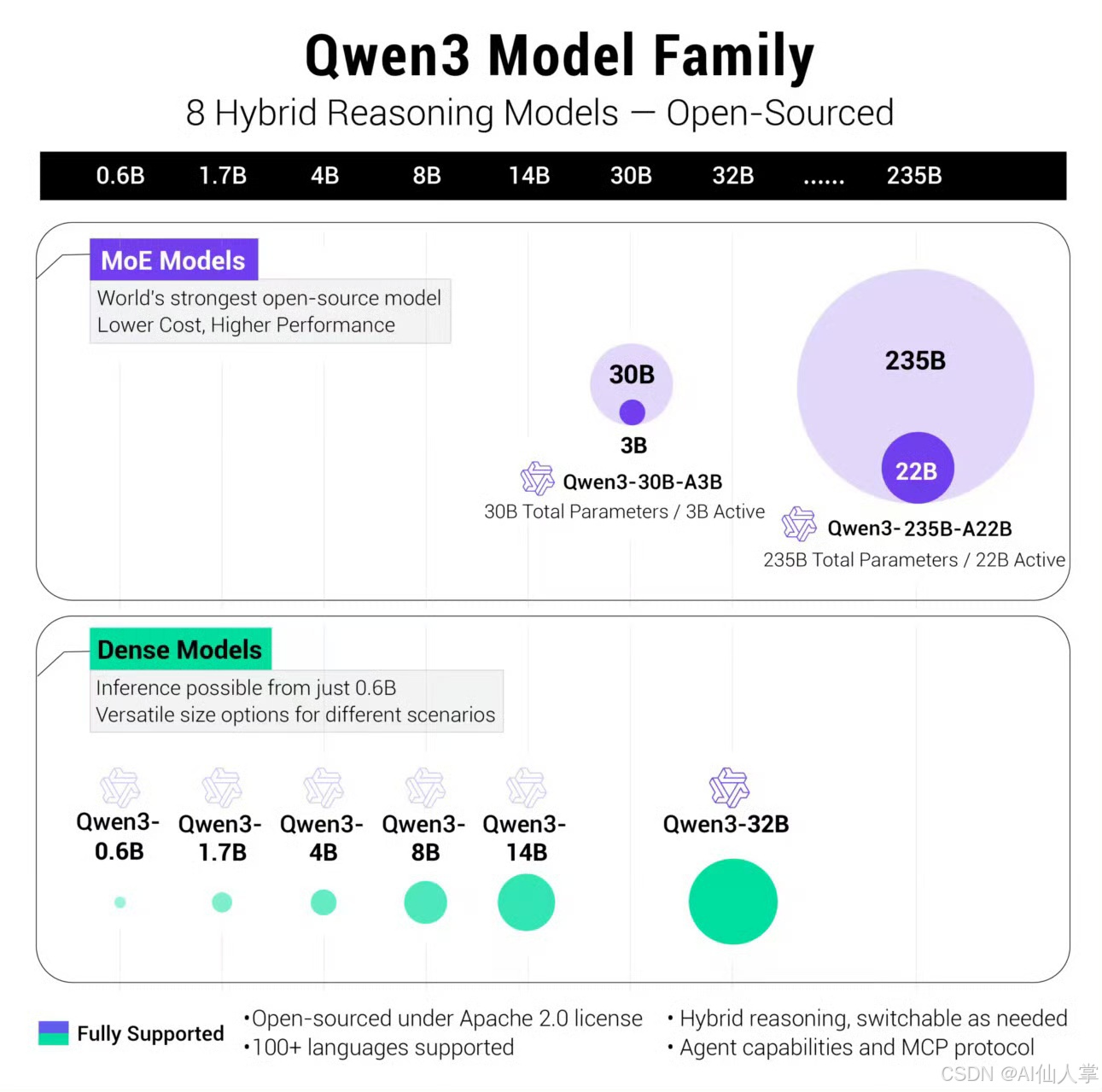
模型家族概览
Qwen3 模型家族包括以下成员:
| 模型类型 | 变体 | 参数数量 |
|---|---|---|
| 密集模型 | Qwen3-0.6B, Qwen3-1.7B, Qwen3-4B, Qwen3-8B, Qwen3-14B, Qwen3-32B | 0.6B 至 32B |
| MoE 模型 | Qwen3-30B-A3B, Qwen3-235B-A22B | 30B 至 235B 有效参数 |
每个模型都提供两种训练变体:
- 基础模型:仅预训练,名称以 “-Base” 结尾(例如,Qwen3-8B-Base)
- 指令模型:在指令数据上进一步微调(例如,Qwen3-8B)
来源:README.md31-46
密集模型架构
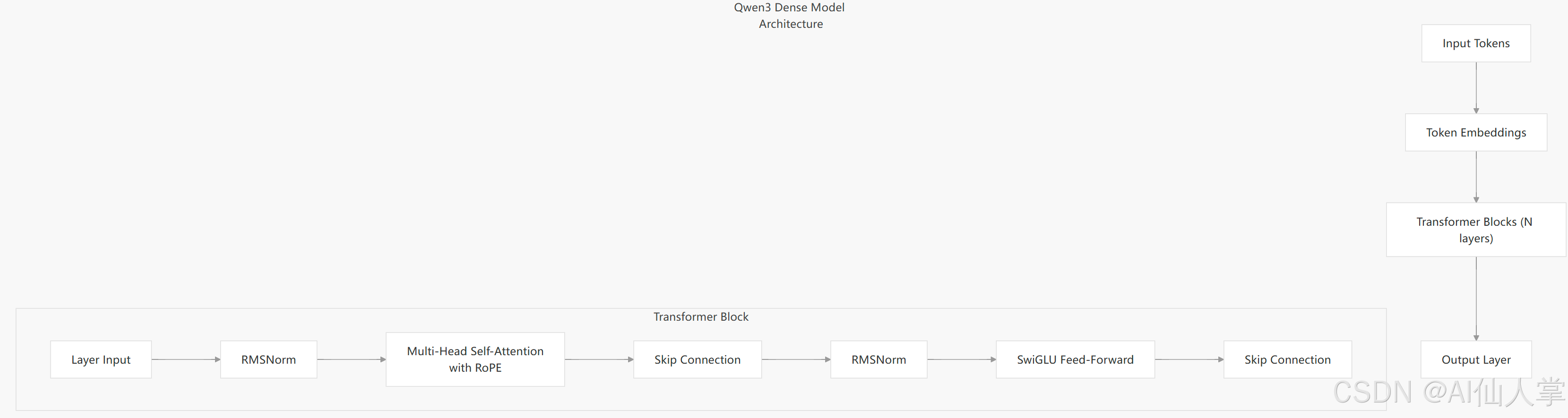
密集模型采用了基于 Transformer 的架构,并进行了多项增强:
- Token 嵌入:将输入 Token 映射为嵌入向量。
- 旋转位置嵌入(RoPE):在注意力机制中编码位置信息。
- 多头自注意力:允许模型同时关注输入序列的不同部分。
- SwiGLU 前馈网络:使用门控激活处理注意力输出。
- RMSNorm:对层输入进行归一化,以确保训练稳定。
- 跳跃连接:在训练过程中促进梯度流动。
来源:README.md31-38
MoE 模型架构
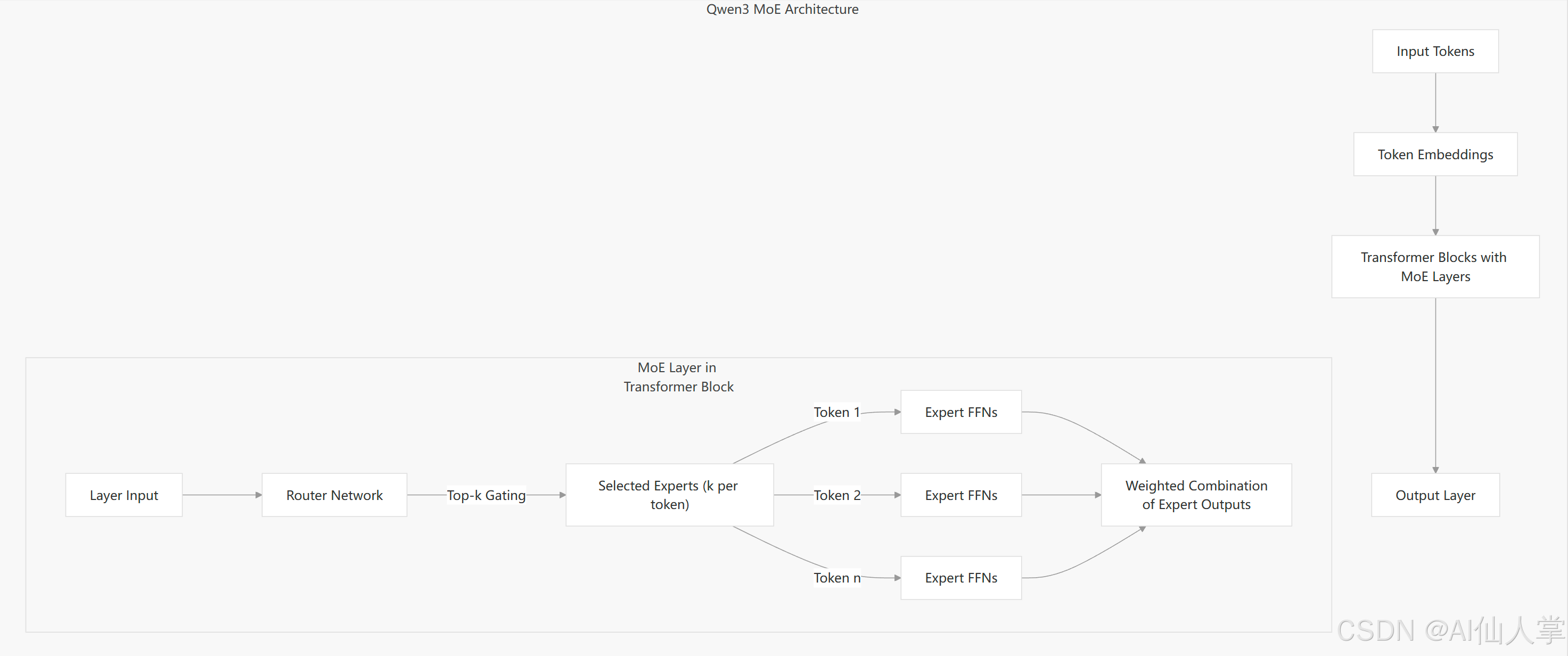
MoE 模型通过用混合专家层替换标准前馈网络,扩展了密集架构。这些模型为每个 Token 激活一部分专家:
- Qwen3-30B-A3B:每个 Token 激活 3 个专家。
- Qwen3-235B-A22B:每个 Token 激活 22 个专家。
模型名称中的 “A” 数字表示推理时每个 Token 激活的专家数量。这使得模型在保持推理效率的同时,能够拥有更大的总参数量。
来源:README.md32-33
关键能力
双重思考模式
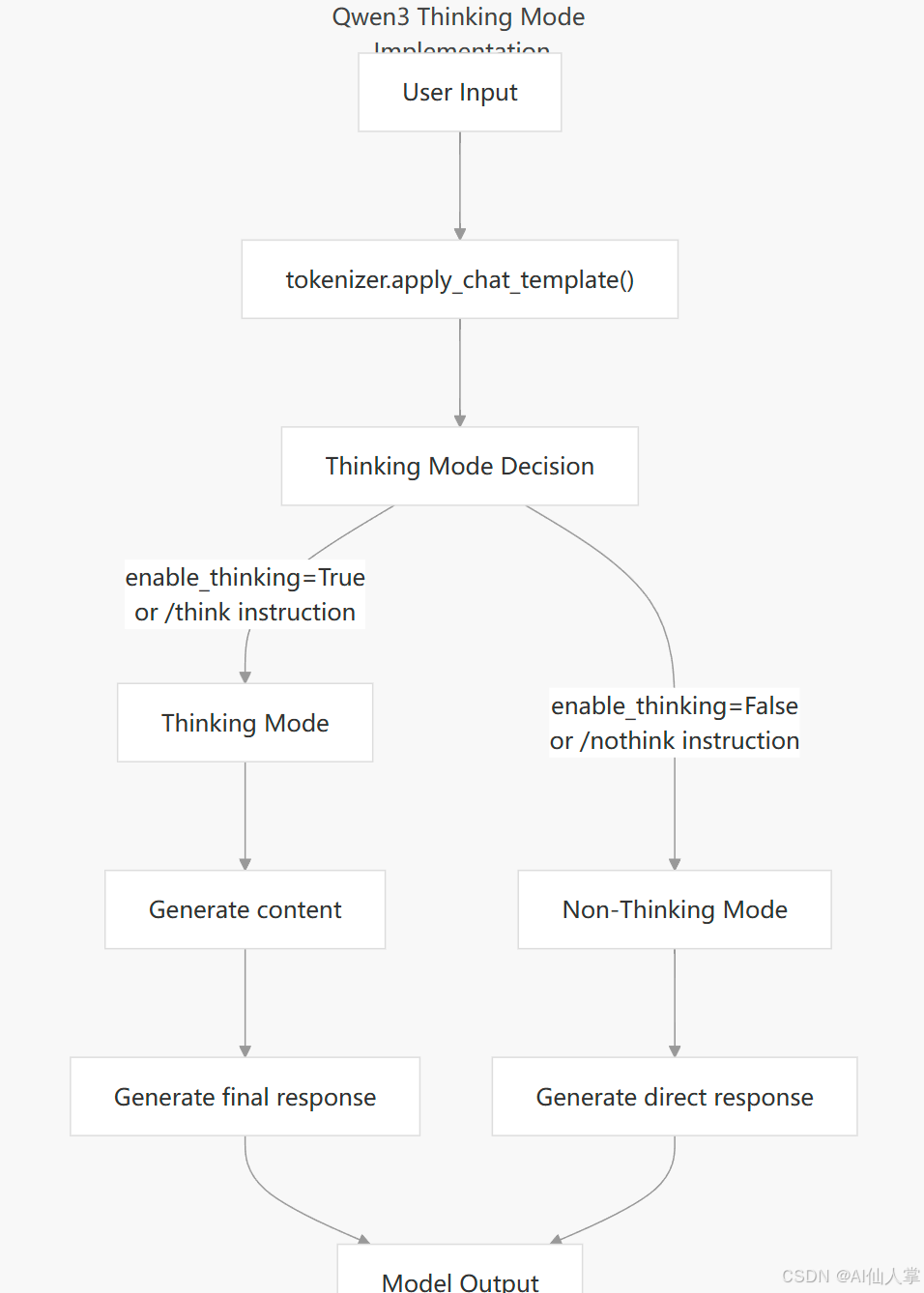
Qwen3 最具特色的功能之一就是它的双重思考模式:
思考模式:
- 专为复杂推理任务设计。
- 在 `` 标签中生成明确的思考步骤。
- 适用于数学、逻辑和代码生成。
非思考模式:
- 优化为直接、高效的响应。
- 不显示明确的推理步骤。
- 适用于简单问题和对话交流。
控制机制:
- 硬切换:在调用
tokenizer.apply_chat_template()时设置enable_thinking=True/False。 - 软切换:在系统或用户消息中包含
/think或/nothink。
来源:README.md34 README.md106-110
增强推理能力
Qwen3 在多个领域展现了增强的推理能力:
- 数学推理:在思考模式下,逐步解决问题并明确展示解题过程。
- 代码生成与理解:
- 多语言代码生成。
- 代码解释与调试。
- 算法实现。
- 逻辑推理:
- 三段论推理。
- 常识推理。
- 连贯推理。
思考模式显著提升了复杂推理任务的表现,而非思考模式则为简单查询提供了更高效的响应。
来源:README.md35
函数调用与工具使用
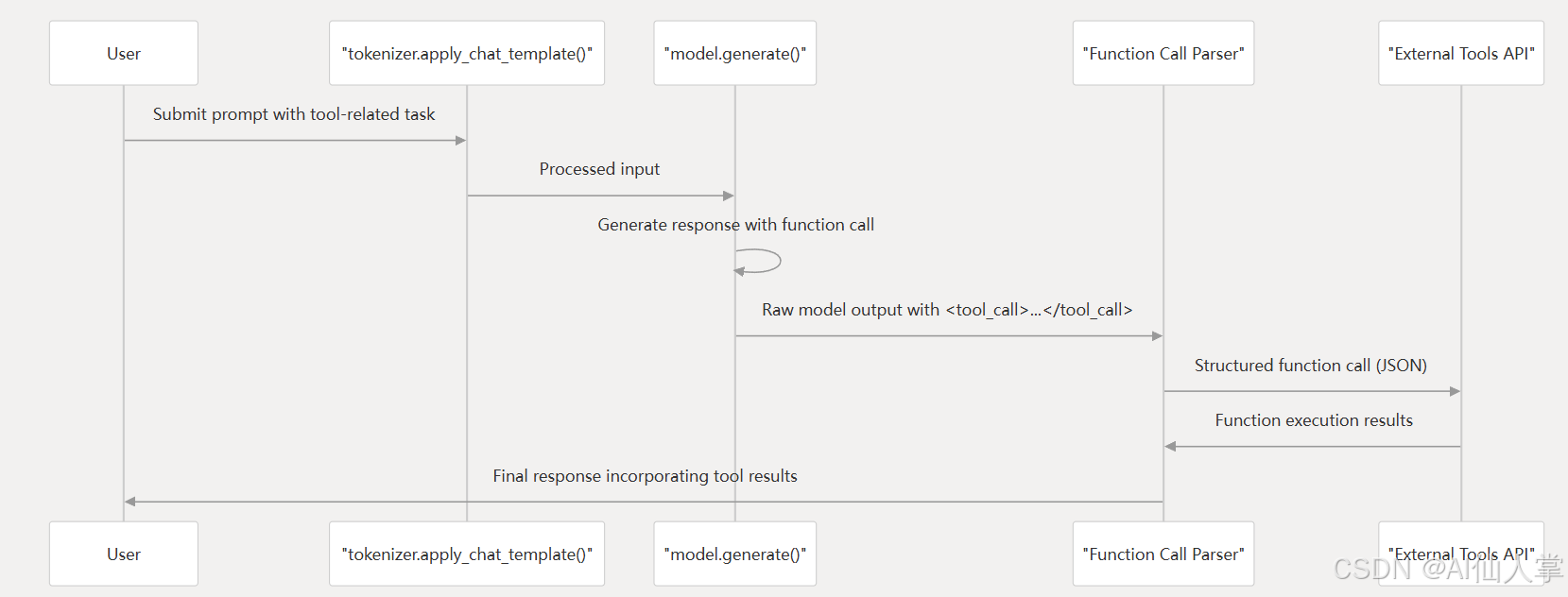

Qwen3 提供了强大的函数调用能力,用于与外部工具集成。关键特性包括:
- 使用结构化的 JSON 格式表示函数参数。
- 支持在单次交互中进行多次函数调用。
- 与 OpenAI 的函数调用格式兼容。
- 支持多种推理框架(Transformers、SGLang、vLLM、llama.cpp)。
关于实现细节,请参阅 Qwen-Agent 框架,它为工具使用和函数调用提供了专门的包装器。
来源:README.md36 README.md229-234
多语言支持
Qwen3 支持超过 100 种语言和方言,具备强大的能力:
- 跨语言指令遵循。
- 语言之间的翻译。
- 多语言内容生成。
这种多语言能力是集成在核心模型架构中的,而不是附加功能,因此在非英语任务中特别有效。
来源:README.md38
技术规格
分词
Qwen3 使用字节级字节对编码(BPE)分词器,词汇量为 151,646 个 Token。关键特性包括:
- 没有未知词汇(所有文本都可以分词)。
- 支持控制 Token,如
<|endoftext|>、<|im_start|>、<|im_end|>。 - 支持思考模式标签:``。
- 支持工具调用标签:
<tool_call>、</tool_call>。 - 对于英文文本,大约 1 个 Token ≈ 3-4 个字符。
- 对于中文文本,大约 1 个 Token ≈ 1.5-1.8 个字符。
来源:docs/source/getting_started/concepts.md125-134
上下文长度
Qwen3 模型支持:
- 标准配置下支持 32,768 个 Token 的上下文长度。
- 通过 YaRN 扩展,部分模型可支持高达 131,072 个 Token。
这些模型既能处理简短的互动,也能处理长篇内容,使其在从聊天机器人到文档分析的各种应用场景中都非常灵活。
来源:docs/source/getting_started/concepts.md195-209
聊天格式
Qwen3 使用基于 ChatML 的格式,结构如下:
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{user_message}<|im_end|>
<|im_start|>assistant
{assistant_response}<|im_end|>
<|im_start|>system
You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>
<|im_start|>user
Hello, can you help me with something?<|im_end|>
<|im_start|>assistant
Hello! I'd be happy to help you. What do you need assistance with today?<|im_end|>
在思考模式下,助手的响应可以包含明确的推理步骤:
<|im_start|>assistant答案在这里:...
<|im_end|>
来源:docs/source/getting_started/concepts.md146-191
与推理框架的集成
Qwen3 可以使用多种推理框架进行部署:
| 框架 | 关键特性 | 设置命令 |
|---|---|---|
| 🤗 Transformers | 标准 Python API,支持完整模型 | model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-8B") |
| vLLM | 高吞吐量服务,兼容 OpenAI API | vllm serve Qwen/Qwen3-8B --port 8000 --enable-reasoning-parser |
| SGLang | 快速服务,支持思考模式 | python -m sglang.launch_server --model-path Qwen/Qwen3-8B --port 30000 --reasoning-parser qwen3 |
| llama.cpp | CPU 推理,支持量化模型 | ./llama-cli -hf Qwen/Qwen3-8B-GGUF:Q8_0 --jinja --color -ngl 99 |
每个框架都实现了对 Qwen3 的关键能力的支持,包括思考模式和工具调用。对于生产环境中的部署,vLLM 和 SGLang 在 GPU 推理方面表现最佳,而 llama.cpp 则针对 CPU 部署进行了优化。
来源:README.md62-104 README.md186-210
模型优化选项
Qwen3 支持多种优化技术用于部署:
量化
所有模型都可以进行量化,以减少内存占用,同时保持性能:
- FP8:8 位浮点量化,用于高效的推理。
- AWQ:激活感知权重量化,提供更好的质量与大小权衡。
- GGUF:适用于 llama.cpp 的量化格式(Q4_K_M、Q5_K_M、Q8_0)。
低比特量化(4 位及以下)特别适用于在消费级硬件上运行更大模型。
YaRN 上下文扩展
YaRN(Yet another RoPE extension)允许将上下文长度扩展到训练时使用的 32K Token 之外。这对于文档处理和长篇内容生成特别有用。
来源:docs/source/quantization/llama.cpp.md1-148
本文提供了 Qwen3 模型架构和能力的概览。有关具体实现细节,请参阅代码库中的代码和文档。