【Redis——数据类型和内部编码和Redis使用单线程模型的分析】
文章目录
- Redis的数据类型和内部编码
- 单线程模型的工作过程
- Redis虽然是一个单线程模型,为啥效率那么高,速度快呢?
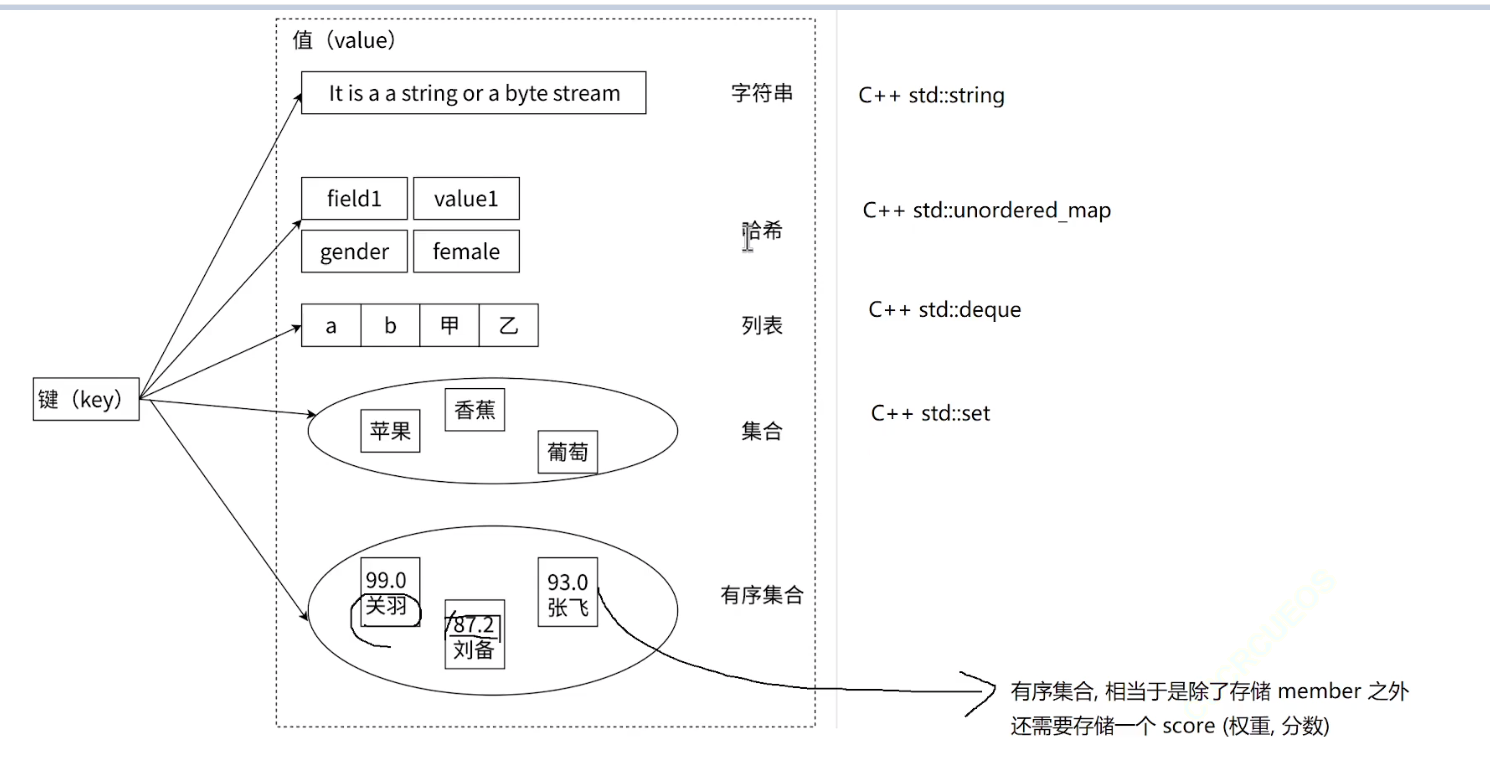

总而言之,Redis提供的哈希表容器并不一定真的是真的哈希表,而是在特点的场景下,用别的容器去实现,为了保证时间复杂度符合承诺(就是为了高效)
Redis的数据类型和内部编码
string
(由于只学过C++,这里只站在C++的角度理解Redis中的数据结构
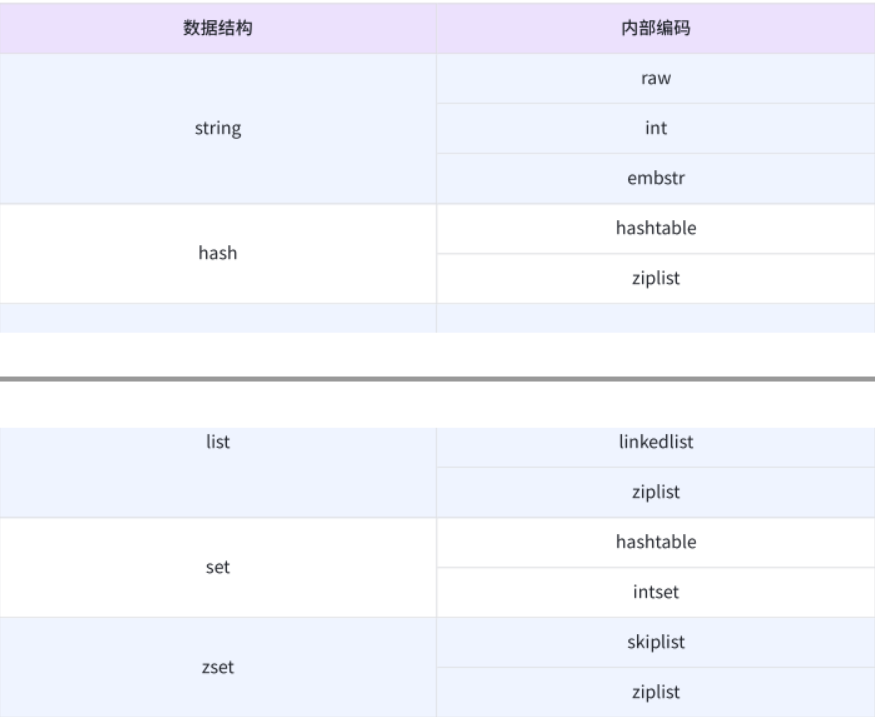
- raw:最基本的字符串,底层就是持有一个char数组(C++)。
- int:当value是一个整数时,此时redis可能用int来保存。
- embstr:针对短字符串进行的特殊优化。
以上内部编码方式Redis会自动适应,在使用时感知不到。
hash:
- hashtable:虽然有可能实现方式不太一样,但是整体的思想跟C++的哈希表是一样的。
- ziplist:压缩列表,在哈希表元素较少的时候,可能优化成ziplist压缩列表,就能够节省空间。因为元素较少,所以遍历的时候仍然能视为O(1)的时间复杂度。
为啥要压缩,为啥要节省时间呢?
因为在key特别多的情况下,如果key对应的value都是哈希表,则对应的hash也特别多,但是每个hash又不大的情况下,就可以将这些hash压缩,让整体占用内存更少。
list:
- linkedlist:链表,就是数据结构中熟悉的那个链表,包括单链表,双链表。
- ziplist:如果元素个数少,就用压缩列表实现,因为节省空间,如果元素个数多,那就会用链表。
从redis3.2版本开始,引入了新的实现方式:quicklist,这个就同时兼顾了linkedlist和ziplist的优点。
可以认为quicklist就是一个链表,链表的每个元素是ziplist。这样的折中方案把空间和效率都兼顾了。
所以quicklist就比较像C++的deque。
set:
- hashtable:这个跟前面那个讲解一样,看上面那个即可。
- intset:针对特定场景的优化:比如集合中都是一个整数,就优化成intset
zset:
-
skiplist:跳表。在链表的笔试题中,有一道题叫做:“复杂链表的复制”,除了有一个next指向下一个节点外,还有一个Random节点指向其他随机节点。这里的跳表同理,每个节点上有多个指针域的指向,巧妙的搭配这些指针域的指向,就能做到查找时的时间复杂度O(logN)
-
ziplist:看上面的解释
通过object encoding key来查看key对应的value的编码方式。
比如:
set key1 1
object encoding key1,可以得到key1对应的value的编码方式是int
单线程模型的工作过程

Redis虽然是一个单线程模型,为啥效率那么高,速度快呢?
(面试题)(说Redis快的参照物是关系型数据库:MySQL等)
- 1.redis访问内存,MySQL访问硬盘。
- 2.redis的核心功能比数据库的核心功能简单。比如针对插入删除,数据库的各种约束(主键约束,外键约束),在插入时,会先判断在不在,判断完成后,还得找个位置插入。这样同样又会有消耗。
- 3.单线程模型避免了不必要的线程竞争开销。Redis的每个基本操作都是短平快的,就是简单地操作内存,没多大消耗CPU,就算搞个多线程提升不大(具体得看业务场景)。
- 4.处理网络IO时,使用了epoll的I/O多路复用。一个线程可以管理多个socket,对TCP来说,当客户端到来时,都要给该客户端设置一个socket,并且在很多情况下,大部分客户端的通信并没有那么频繁,而是仅仅有少量客户端是活跃的。但是在传统的IO时,是为一个客户端创建一个线程专门服务的。而大部分客户端只发了几次数据就不活跃了。此时线程也会被阻塞住,而线程创建,销毁,调度都是消耗性能的操作。所以使用I/O多路服用,让一个线程同时监听处理多个socket,大大提高了效率。(但是,一个线程监听多个socket是只有当这些socket只有少量是活跃的时候才能这样做。否则这些socket如果同时非常活跃,就可能导致线程忙不过来。打游戏+和女朋友打电话的例子)