告别碎片化!两大先进分块技术如何提升RAG的语义连贯性?
研究动机
论文核心问题及研究背景分析
1. 研究领域及其重要性
- 研究领域:检索增强生成(Retrieval-Augmented Generation, RAG)系统,结合自然语言处理(NLP)与信息检索技术。
- 重要性:
- RAG通过动态整合外部知识,解决了传统大语言模型(LLMs)依赖静态预训练数据的局限性。
- 在开放域问答、实时信息生成等场景中,RAG能显著提升生成内容的准确性和信息完整性。
- 对知识密集型任务(如医疗问答、法律分析)至关重要,需高效管理大规模外部文档。
2. 当前领域面临的挑战或痛点
| 挑战 | 具体表现 | 影响 |
|---|---|---|
| 输入长度限制 | LLMs的上下文窗口有限(通常数千token),难以处理长文档 | 需分块处理,但分块可能破坏语义连贯性 |
| 上下文碎片化 | 固定分块策略忽略语义边界,导致信息割裂 | 检索不完整,生成结果缺乏连贯性 |
| 位置偏差 | LLMs对文档开头信息更敏感,中间/尾部信息易被忽略 | 关键信息可能未被有效检索或利用 |
| 效率与效果权衡 | 传统分块效率高但牺牲语义;高级方法(如上下文增强)计算成本高 | 实际应用中需平衡资源消耗与性能 |
3. 论文关注的具体问题及研究意义
具体问题
-
两种分块策略的对比:
- Late Chunking(延迟分块):先对整个文档嵌入,再分块聚合,保留全局上下文。
- Contextual Retrieval(上下文增强检索):分块后附加LLM生成的上下文,提升语义连贯性。
-
关键研究问题(RQs):
- RQ#1:早期分块 vs. 延迟分块对检索和生成性能的影响。
- RQ#2:传统分块 vs. 上下文增强分块的效果差异。
研究意义
-
理论意义:
- 揭示两种分块策略在上下文保留与效率上的权衡关系。
- 提出动态分块模型(如Topic-Qwen)和混合排名策略(BM25 + 稠密嵌入),为优化RAG系统提供新思路。
-
应用价值:
- 资源受限场景:优先选择延迟分块(效率高,但需适配长上下文嵌入模型)。
- 高精度需求场景:采用上下文增强检索(牺牲计算资源换取语义连贯性)。
- 开源代码与数据集(NFCorpus、MSMarco)支持实际部署与复现。
相关研究工作
以下是针对检索增强生成(RAG)中分块策略研究的归纳总结:
主要已有方法或技术路线
| 方法名称 | 核心思想 | 技术特点 |
|---|---|---|
| 固定尺寸分块 | 将文档均等分割为固定长度的文本块 | 简单高效,但忽略语义边界 |
| 语义分块 | 根据语义边界(如段落、主题)动态分割文本 | 基于语义模型检测断点,保留局部上下文 |
| 延迟分块 | 先对整个文档进行词元级嵌入,再分割为块并聚合 | 利用长上下文嵌入模型保留全局信息 |
| 上下文检索 | 分块后通过LLM生成全局上下文并预置到每个块中,再结合混合检索(BM25+嵌入) | 增强局部块的语义连贯性,但需额外生成上下文 |
方法对比与优缺点分析
| 方法 | 优点 | 缺点 |
|---|---|---|
| 固定尺寸分块 | 实现简单、计算高效;兼容性强 | 破坏上下文连贯性;可能导致关键信息分割 |
| 语义分块 | 保留局部语义结构;减少信息碎片化 | 依赖语义模型;计算成本较高;动态分割不稳定 |
| 延迟分块 | 保留全局上下文;适配长文本嵌入模型 | 嵌入模型性能影响显著;长文档处理效率低;部分模型(如BGE-M3)表现下降 |
| 上下文检索 | 语义连贯性最佳(NDCG@5提升5%);支持混合检索提升召回率 | 计算资源需求高(需LLM生成上下文);长文档内存占用大 |
现有研究的不足与未解决问题
-
效率与效果的权衡
- 延迟分块和上下文检索虽提升效果,但计算成本显著增加(如上下文检索需要20GB VRAM处理长文档)。
- 动态分块模型(如Topic-Qwen)耗时是固定分块的4倍,且生成结果不稳定。
-
长文档处理瓶颈
- 现有方法(尤其是上下文检索)对长文档的支持有限,GPU内存限制导致实验仅使用20%数据集。
-
模型依赖性
- 延迟分块效果高度依赖嵌入模型(例如Jina-V3表现优于BGE-M3),缺乏普适性结论。
-
生成性能未显著提升
- 实验显示分块策略对最终生成质量(问答任务)影响有限,需更深入的端到端优化。
-
统一评估框架缺失
- 不同方法在数据集、评测指标上差异大(如NFCorpus与MSMarco),横向对比困难。
可以看出, 当前RAG分块策略的研究聚焦于平衡上下文保留与计算效率。传统方法(固定分块、语义分块)在简单场景中仍具优势,而延迟分块和上下文检索在复杂语义任务中表现更优但代价高昂。未来需探索轻量化上下文增强、长文档优化技术,并建立统一评估标准以推动实际应用。
研究思路来源
作者的研究思路主要受到以下前人工作的启发:
- 经典RAG框架:基于Lewis等人(2020)提出的RAG基础架构,结合检索机制与生成模型,但在处理长文档时面临输入限制和上下文碎片化问题。
- 固定分块与语义分块:传统方法如固定窗口分块(如[7])和语义分块(如Jina-Segmenter API),但无法解决全局上下文丢失问题。
- 动态分块技术:如监督分割模型(Koshorek et al., 2018)和端到端优化分块(Moro & Ragazzi, 2023),但计算成本高且依赖标注数据。
- 长上下文嵌入模型:如Ding等人(2024)提出的LongRoPE,但实际应用中仍存在位置偏差(Hsieh et al., 2024)。
作者提出新方法的动机源于以下核心观察与假设:
- 传统分块的局限性:
- 上下文割裂:固定分块破坏文档的语义连贯性,导致检索不完整(例如,一个分块可能缺少公司名称或时间信息)。
- 位置偏差:LLM对文档开头信息更敏感,而中间或尾部信息易被忽略(Lu et al., 2024)。
- 效率与效果的权衡:动态分块模型(如Topic-Qwen)虽提升效果,但生成不一致且计算成本高。
- 假设:
- 延迟分块保留全局上下文:在文档级嵌入后再分块(Late Chunking)可减少局部语义损失。
- 上下文增强提升检索质量:通过LLM生成附加上下文(Contextual Retrieval)可弥补分块的语义不完整。
3. 主要创新点与差异化对比
论文的核心创新点及与现有工作的对比:
| 创新点 | 技术细节 | 与现有工作的差异化 | 效果对比 |
|---|---|---|---|
| Late Chunking(延迟分块) | 先对整个文档进行嵌入,再分块并聚合向量。 | 区别于传统“先分块后嵌入”,避免分块前的上下文丢失。 | 优势: - 保留全局语义(如文档主题一致性); - 计算效率高(无需LLM生成额外内容)。 劣势: - 对长文档嵌入模型依赖性强(如BGE-M3效果差); - 部分场景下相关性下降(表3中MsMarco数据集表现弱于早期分块)。 |
| Contextual Retrieval(上下文检索) | 分块后通过LLM生成上下文摘要(如Phi-3模型),并与BM25稀疏向量融合排序。 | 结合语义(密集向量)与精确匹配(稀疏向量),优于单一检索策略。 | 优势: - 提升检索完整性(NDCG@5提高5.3%,表5); - 缓解位置偏差(通过上下文补充关键信息)。 劣势: - 计算成本高(GPU内存占用达20GB); - 依赖LLM生成质量(小模型如Phi-3可能表现不稳定)。 |
| 动态分块模型优化 | 测试Simple-Qwen和Topic-Qwen分块模型,结合主题边界检测。 | 超越传统固定或语义分块,但需权衡生成稳定性与计算效率。 | 优势: - 自适应内容分块(如按主题划分); - 提升下游任务性能(Jina-V3模型NDCG@5达0.384)。 劣势: - 生成不一致性(分块边界波动); - 处理时间增加(Topic-Qwen耗时4倍于固定分块)。 |
解决方案细节
论文针对传统RAG(检索增强生成)系统中固定分块(fixed-size chunking)导致的上下文碎片化问题,提出了两种改进策略:
-
延迟分块(Late Chunking)
- 核心思想:推迟分块过程,先对整个文档进行嵌入(embedding),保留全局上下文,再分割为块。
- 原理:通过长上下文嵌入模型直接处理完整文档,避免早期分块造成的语义割裂。
-
上下文检索(Contextual Retrieval)
- 核心思想:在分块后,通过大语言模型(LLM)为每个块动态生成补充上下文。
- 原理:利用LLM提取文档的全局语义信息,附加到分块中,增强单一块的语义连贯性。
方法的主要组成模块及功能
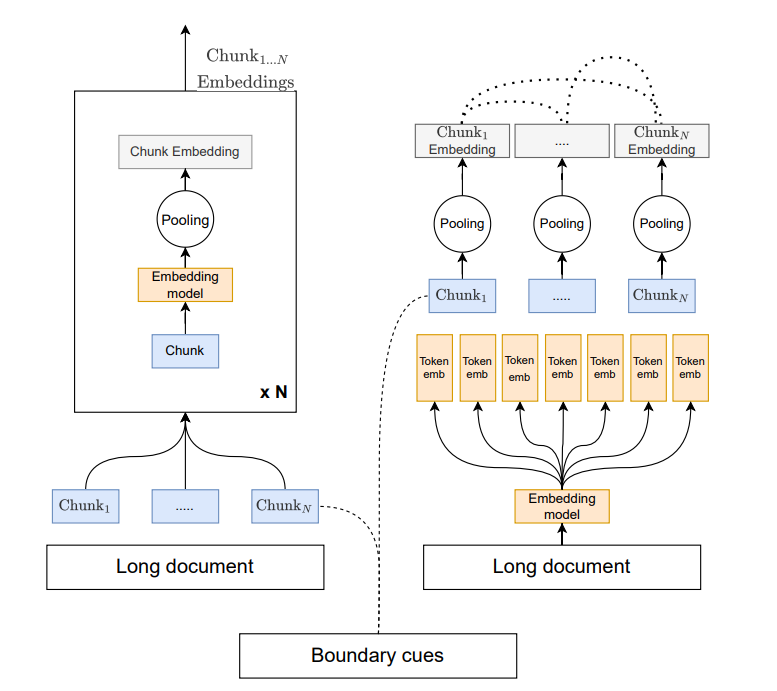
1. 延迟分块(Late Chunking)流程
完整文档 → Token级嵌入 → 分块 → 池化 → 块嵌入
-
模块功能:
- Token级嵌入:使用长上下文嵌入模型(如Stella-V5)对完整文档生成细粒度嵌入。
- 动态分块:根据语义边界或固定窗口分割嵌入结果。
- 池化(Pooling):对每个块的Token嵌入取均值,生成块级嵌入。
Jina有篇文章,更详细的解释了Late Chunking,文章链接如下;
长文本表征模型中的后期分块
https://jina.ai/news/late-chunking-in-long-context-embedding-models/
"Late Chunking"方法首先将嵌入模型的 transformer 层应用于整个文本或尽可能多的文本。这会为每个 token 生成一个包含整个文本信息的向量表示序列。随后,对这个 token 向量序列的每个块应用平均池化,生成考虑了整个文本上下文的每个块的嵌入。与生成独立同分布(i.i.d.)块嵌入的朴素编码方法不同,Late Chunking 创建了一组块嵌入,其中每个嵌入都"以"前面的嵌入为条件,从而为每个块编码更多的上下文信息。
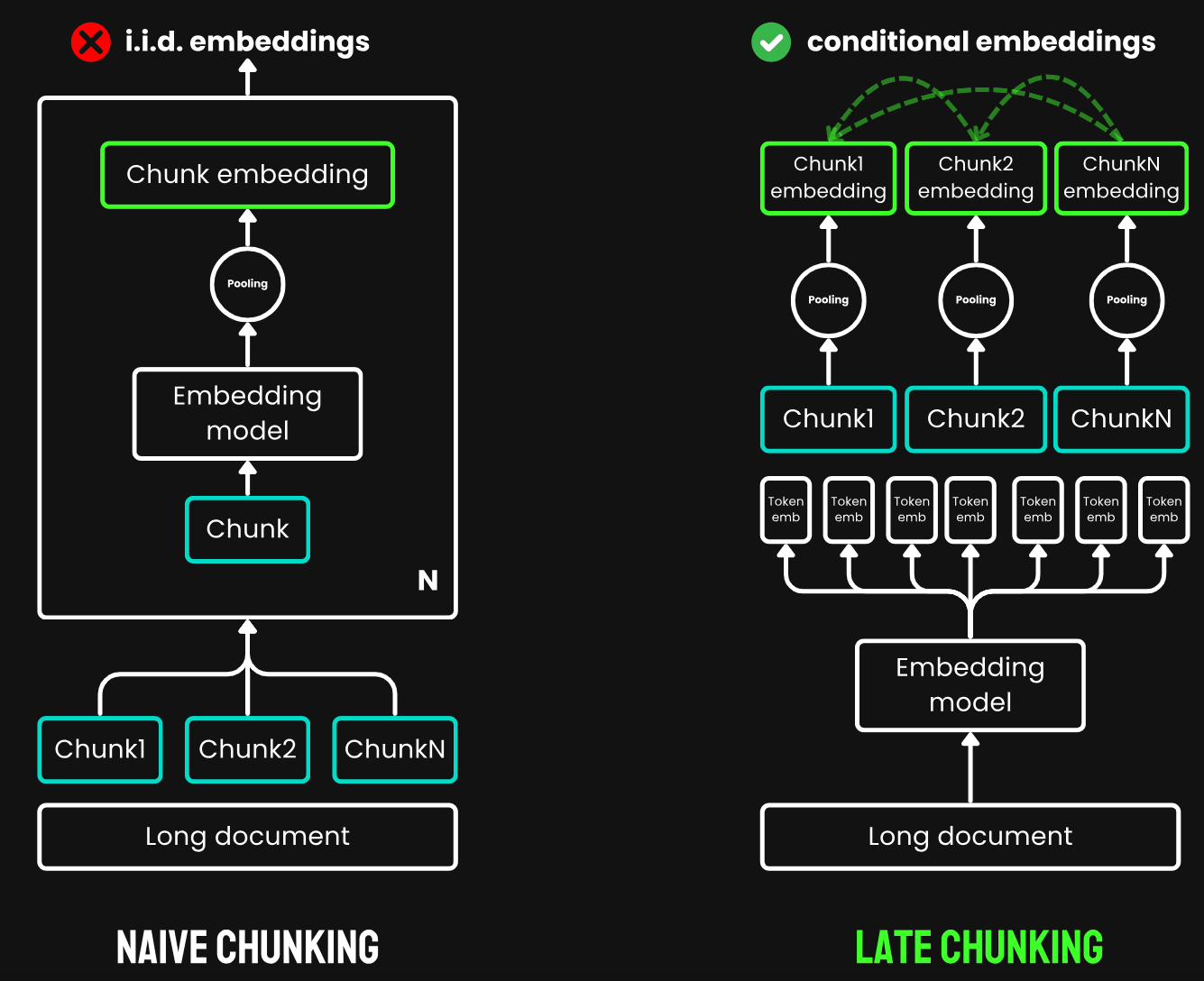
传统分块策略(左)和 Late Chunking 策略(右)的示意图。
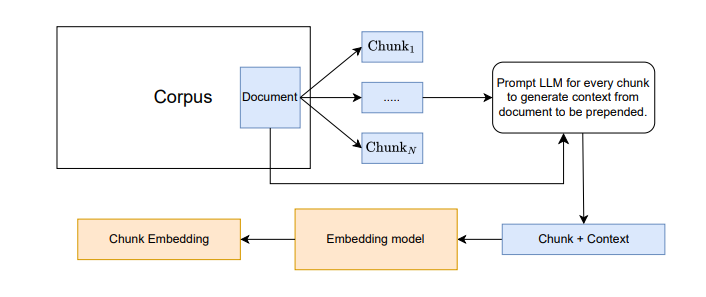
2. 上下文增强切块(Contextual Retrieval)流程
分块 → LLM生成上下文 → 块+上下文嵌入 → 混合检索(BM25+密集检索) → 重排序
-
模块功能:
- 上下文生成:用LLM为每个块生成补充信息(如所属章节、主题)。
- 混合检索:结合BM25的精确匹配和密集嵌入的语义匹配(权重4:1)。
- 重排序:使用交叉编码器(cross-encoder)对检索结果重新评分。
关键技术细节
1. 延迟分块的关键改进
-
长上下文嵌入模型:支持处理超长文档(如Stella-V5支持131k Token)。
-
动态分块策略:
- Simple-Qwen:基于文档结构(如标题、段落)分块。
- Topic-Qwen:基于主题边界分块(通过LLM识别主题切换点)。
2. 上下文检索的关键技术
-
上下文生成提示模板:
"基于以下文档,为当前块生成上下文摘要:[文档内容] [当前块]" -
混合检索的权重分配:
嵌入类型 权重 密集嵌入 1.0 BM25稀疏嵌入 0.25 -
重排序模型:Jina Reranker V2(交叉编码器架构,计算查询与块的相关性得分)。
3. 动态分块模型的权衡
| 分块策略 | 优点 | 缺点 |
|---|---|---|
| 固定窗口分块 | 计算效率高 | 忽略语义边界 |
| 语义分块(Jina) | 保留语义连贯性 | 依赖外部API,速度较慢 |
| 动态分块(Qwen) | 自适应文档结构/主题 | 生成不稳定,计算成本高 |
实验与性能对比
1. 检索性能(NFCorpus数据集)
| 方法 | NDCG@5 | MAP@5 | F1@5 |
|---|---|---|---|
| 传统分块(Early) | 0.303 | 0.137 | 0.193 |
| 延迟分块(Late) | 0.380 | 0.103 | 0.185 |
| 上下文检索(RFR) | 0.317 | 0.146 | 0.206 |
2. 计算资源消耗
| 方法 | VRAM占用 | 处理时间(NFCorpus) |
|---|---|---|
| 传统分块 | 5-10GB | 30分钟 |
| 延迟分块 | 10-15GB | 60分钟 |
| 上下文检索 | 20GB+ | 120分钟+ |
- 延迟分块:适合资源受限场景,但可能牺牲相关性。
- 上下文检索:适合对语义连贯性要求高的任务,但需高算力支持。
- 实际应用:短文档优先选择上下文检索,长文档可尝试延迟分块与动态分块结合。
论文通过系统实验验证了两种方法的互补性,为RAG系统的分块策略选择提供了明确指导。
实验设计与结果分析
1. 实验目的与验证假设
-
目的:比较两种高级分块策略(Late Chunking 和 Contextual Retrieval)在 RAG 系统中的效果,验证它们在 检索准确性、生成连贯性 和 计算效率 上的优劣。
-
核心假设:
- Late Chunking 通过延迟分块保留全局上下文,可能提升检索效果。
- Contextual Retrieval 通过 LLM 生成上下文增强分块语义,可能改善生成质量,但需更高计算资源。
2. 数据集与任务设置
| 数据集 | 任务 | 特点 |
|---|---|---|
| NFCorpus | 检索性能评估 | 长文档(平均长度长),需处理上下文碎片化问题;子集实验(20%数据)用于降低计算开销。 |
| MSMarco | 问答生成评估 | 短文本段落,缺乏完整文档上下文,用于测试生成任务中信息整合能力。 |
任务设置:
- 检索任务:从文档库中检索与查询相关的文档/段落。
- 生成任务:基于检索结果生成答案,评估语义连贯性和准确性。
3. 评估指标
| 指标 | 含义 |
|---|---|
| NDCG@k | 归一化折损累积增益,衡量前 k 个结果的排序质量,重视高相关性结果的排名。 |
| MAP@k | 平均精度均值,衡量所有查询的检索精度均值,关注相关结果的位置分布。 |
| F1@k | 精确率与召回率的调和平均,平衡检索结果中相关性与完整性的权衡。 |
4. 基线方法与对比实验设置
| 方法类型 | 方法细节 | 特点 |
|---|---|---|
| 传统 RAG | 早期分块(固定窗口或语义分块) + 嵌入模型(如 Jina-V3、BGE-M3)。 | 分块后嵌入,可能丢失全局上下文。 |
| Late Chunking | 先嵌入完整文档,再分块并池化(mean pooling)生成分块嵌入。 | 保留全局上下文,计算效率较高。 |
| Contextual Retrieval | 分块后通过 LLM 生成上下文(如 Phi-3.5-mini),结合 Rank Fusion(BM25 + 密集嵌入) | 增强语义连贯性,但需额外生成步骤和 GPU 资源。 |
对比实验设置:
| 实验组 | 分块策略 | 嵌入模型 | 数据集 | 关键参数 |
|---|---|---|---|---|
| RQ#1 | Early vs Late | Stella-V5, Jina-V3 | NFCorpus, MSMarco | 分块大小 512 字符,动态分块模型 |
| RQ#2 | Contextual vs 传统 | Jina-V3, BGE-M3 | NFCorpus 子集 | Rank Fusion 权重(4:1) |
5. 实验环境
| 组件 | 配置/参数 |
|---|---|
| 硬件 | NVIDIA RTX 4090(24GB VRAM),受限于显存,部分实验使用数据子集。 |
| 生成模型 | Phi-3.5-mini-instruct(4-bit 量化),用于生成上下文和问答任务。 |
| 嵌入模型 | Jina-V3(MTEB 排名 53)、Stella-V5(排名 5)、BGE-M3(排名 211)等。 |
| 分块工具 | Jina-Segmenter(语义分块)、Simple-Qwen(动态分块)、Topic-Qwen(主题分块)。 |
| 检索库与工具 | Milvus 向量数据库(支持 BM25 与密集嵌入混合检索),Jina Reranker V2(重排序)。 |
验证严谨性体现
- 控制变量:统一使用相同嵌入模型(如 Jina-V3)对比不同分块策略。
- 数据集适配:针对文档长度调整实验规模(如 NFCorpus 子集解决显存限制)。
- 多指标评估:结合检索(NDCG、MAP)和生成(F1)指标,全面衡量性能。
- 计算效率分析:记录处理时间与显存占用(如 Contextual Retrieval 显存达 20GB)。
- 统计显著性:多次实验取均值,结果表格中标注最优值(Bold 显示)。
论文通过系统化的实验设计,验证了两种分块策略在不同场景下的权衡:Late Chunking 效率更优,Contextual Retrieval 语义更佳,为实际 RAG 系统优化提供了重要参考。
6. 关键实验结果
| 评估指标 | 上下文检索 (ContextualRankFusion) | 延迟分块 (Late Chunking) | 早期分块 (Early Chunking) |
|---|---|---|---|
| NDCG@5 | 0.317 | 0.309 | 0.312 (最佳嵌入模型) |
| MAP@5 | 0.146 | 0.143 | 0.144 (最佳嵌入模型) |
| F1@5 | 0.206 | 0.202 | 0.204 (最佳嵌入模型) |
| 计算资源消耗 | 高(需LLM生成上下文 + 重排序) | 中 | 低 |
| 适用场景 | 长文档、高语义连贯性需求 | 资源受限、效率优先 | 固定长度、简单任务 |
- 嵌入模型对比:
- Jina-V3 在上下文检索中表现最佳(NDCG@5=0.317)。
- BGE-M3 在早期分块中优于延迟分块(NDCG@5=0.246 vs. 0.070)。
- 动态分块模型(如Topic-Qwen)在语义分割中提升效果,但计算耗时增加4倍。
论文结论
核心结论
-
无单一最优策略:
- 上下文检索在语义连贯性上占优(NDCG@5提升2.5%),但资源消耗高;延迟分块效率优先,牺牲局部相关性。
-
关键权衡维度:
- 任务需求:长文档、高准确性场景倾向上下文检索;实时性任务倾向延迟分块。
- 嵌入模型适配:模型特性(如长上下文支持)显著影响分块策略效果。
科学意义
- 实践指导:为RAG系统设计提供量化权衡框架(如资源-效果平衡表),助力开发者按场景优化。
- 理论创新:验证了全局上下文保留(延迟分块)与局部语义增强(上下文检索)的互补性,为后续混合策略(如动态切换)提供基础。
- 开源价值:释放代码与数据集(MIT协议),推动社区在真实场景中复现与扩展(如优化LLM上下文生成效率)。
对应研究目标
- RQ#1(分块时机):延迟分块验证了全局嵌入的高效性,但需结合模型特性(如BGE-M3不适用)。
- RQ#2(上下文增强):上下文检索通过LLM生成与重排序提升语义质量,但需硬件支持。
- 核心目标达成:系统性对比两种策略,揭示了其在RAG系统中的互补性与场景适配边界。
代码实现
延迟切块
class BgeEmbedder():def __init__(self):self.model_id = 'BAAI/bge-m3'self.model = AutoModel.from_pretrained(self.model_id, trust_remote_code=True).cuda();self.tokenizer = AutoTokenizer.from_pretrained(self.model_id);self.model.eval()def get_model(self):return self.modeldef encode(self, chunks, task, max_length=512):if type( chunks) == str:chunks = [chunks]chunks_embeddings = []for chunk in chunks:tokens = self.tokenizer(chunk, return_tensors='pt')['input_ids'].to("cuda")with torch.no_grad():token_embeddings = self.model(input_ids=tokens)[0]pooled_embeddings = token_embeddings.sum(dim=1) / len(token_embeddings)pooled_embeddings = F.normalize(pooled_embeddings, p=2, dim=1).squeeze(0)chunks_embeddings.append(pooled_embeddings.to(dtype=torch.float32).detach().cpu().numpy())if task == 'retrieval.query':return chunks_embeddingselse:return [chunks_embeddings]# def encode(self, chunks, task, max_length=512):# if type( chunks) == str:# chunks = [chunks]# chunks_embeddings = []# for chunk in chunks:# tokens = self.tokenizer(chunk, return_tensors='pt')['input_ids'].to("cuda")# with torch.no_grad():# token_embeddings = self.model(input_ids=tokens)[0]# div = token_embeddings.size(1)# pooled_embeddings = token_embeddings.sum(dim=1) / div# pooled_embeddings = F.normalize(pooled_embeddings, p=2, dim=1).squeeze(0)# chunks_embeddings.append(pooled_embeddings.to(dtype=torch.float32).detach().cpu().numpy())# if task == 'retrieval.query':# return chunks_embeddings# else:# return [chunks_embeddings]def encodeLateChunking(self, text_token, span_annotation, task, max_length = None ):with torch.no_grad():token_embeddings = self.model(input_ids=text_token)[0]outputs = []for embeddings, annotations in zip(token_embeddings, span_annotation):if (max_length is not None): # remove annotations which go bejond the max-length of the modelannotations = [(start, min(end, max_length - 1))for (start, end) in annotationsif start < (max_length - 1)]pooled_embeddings = [embeddings[start:end].sum(dim=0) / (end - start)for (start, end) in annotationsif (end - start) >= 1]pooled_embeddings = [F.normalize(pooled_embedding.unsqueeze(-1), p=2, dim=0).squeeze(-1)for pooled_embedding in pooled_embeddings]pooled_embeddings = [embedding.to(dtype=torch.float32).detach().cpu().numpy()for embedding in pooled_embeddings]outputs.append(pooled_embeddings)return outputs
上下文增强切块
class ChunkContextualizer():"""This class is used to contextualize the chunks of text.It gives to the model the document and the chunk of text to generate the context to be added to the chunk.The model is a language model that generates the context."""def __init__(self, corpus, prompt, examples, llm_id, segmenter,load_in_4bit = True): #model_templateself.corpus = corpusself.prompt = promptself.examples = examplesself.segmenter = segmenter#self.model_template = model_template#self.chat_template = (model_template,"<|end|>")self.llm_id = llm_idself.load_in_4bit = load_in_4bitdtype = Noneself.llm_model, self.llm_tokenizer = FastLanguageModel.from_pretrained(model_name = model_id,dtype = dtype,load_in_4bit = load_in_4bit,)self.llm_tokenizer = get_chat_template(self.llm_tokenizer,chat_template = 'phi-3.5',#self.chat_template, # apply phi-3.5 chat templatemapping = {"role" : "from", "content" : "value", "user" : "human", "assistant" : "gpt"},)FastLanguageModel.for_inference(self.llm_model);self.generation_config = GenerationConfig(eos_token_id=self.llm_tokenizer.convert_tokens_to_ids("<|end|>"))def get_llm(self):return self.llm_modeldef get_formatted_prompt(self,doc,chunk):ex = '\n'.join([f'CHUNK: {chunk}\nCONTEXT: {context}' for (chunk, context) in self.examples]) # format examples with chunk and contextreturn self.prompt.format(doc_content=doc, chunk_content=chunk, examples=ex) # format prompt with chunk, document and examplesdef extract_llm_responses(self, conversation: str): # extract assistant responses from the conversation# Regex to match assistant output between <|assistant|> and <|end|>assistant_responses = re.findall(r"<\|assistant\|>(.*?)<\|end\|>", conversation, re.DOTALL)return assistant_responsesdef contextualize(self, chunking_size):ids,texts = zip(*[ (key, value['text']) for (key,value) in self.corpus.items() ])ids,texts = list(ids), list(texts)chunks_ids,contextualized_chunks=[],[]pbar = tqdm(total=len(texts), desc="Contextualizing Chunks", mininterval=60.0)for i in range(len(texts)):chunks = self.segmenter.segment(input_text=texts[i],max_chunk_length=chunking_size) # segment text into chunks with passed segmenterfor j in range(len(chunks)):chunk = chunks[j]doc = texts[i] # getting document for all the chunksprompt = self.get_formatted_prompt(doc,chunk) # formatting prompt with current document and current chunkmessages=[{"from": "human", "value": prompt}]inputs = self.llm_tokenizer.apply_chat_template( # apply chat template to the prompt to get the inputmessages,tokenize=True,return_tensors="pt",padding=True,).to("cuda")output_ids = self.llm_model.generate(input_ids=inputs,do_sample=False,max_new_tokens=2000,generation_config=self.generation_config,)output = self.llm_tokenizer.batch_decode(output_ids) # decode the output to textgenerated_context = self.extract_llm_responses(output[0]) # extract context from output stringif generated_context: # only add non-empty entriescontextualized_chunks.append(chunk + '\n' + generated_context[0]) # append generated context to current chunkchunks_ids.append(f'{ids[i]}:{j}')pbar.update(1)return contextualized_chunks, chunks_ids
其中提示语为:
contextual_retrieval_prompt = """
DOCUMENT:
{doc_content}Here is the chunk we want to situate within the whole document
CHUNK:
{chunk_content}Provide a concise context for the following chunk, focusing on its relevance within the overall document for the purposes of improving search retrieval of the chunk.
Answer only with the generated context and nothing else.
Output your answer after the phrase "The document provides an overview".
Think step by step.Here there is an example you can look at.
EXAMPLE:
{examples}"""
这个提示语(prompt)是一个用于 上下文检索(contextual retrieval) 的模板,目的是帮助大语言模型(LLM)为给定的文本片段(chunk)生成一个简洁的上下文描述,从而提升检索效果。以下是它的详细解析:
参考资料
- https://arxiv.org/pdf/2504.19754
- https://github.com/disi-unibo-nlp/rag-when-how-chunk