强化学习之基于无模型的算法之蒙特卡洛方法
1、蒙特卡洛方法(Monte Carlo)
蒙特卡洛方法(Monte Carlo Method, MC)是强化学习中的一种无模型(Model-Free)学习算法,其核心思想是通过 采样完整的交互轨迹(Episode) ,基于 实际回报的平均值 来估计状态价值或动作价值,从而逐步优化策略。与动态规划等基于模型的方法不同,蒙特卡洛方法不需要知道环境的转移概率和奖励函数,而是直接从与环境交互的经验中学习。
基本原理
蒙特卡洛方法的核心是通过 多次采样来估计期望值。在强化学习中,智能体与环境交互产生多条完整的轨迹(从初始状态到终止状态),每条轨迹的回报(Return)是该轨迹中所有奖励的累加(可能带折扣因子)。通过对多条轨迹的回报进行平均,可以估计状态价值或动作价值。
- 状态价值估计:对于策略 π,状态 s 的价值 Vπ(s) 是从 s 出发,遵循 π 获得的期望回报。蒙特卡洛方法通过多次访问 s 并记录每次访问后的回报,计算这些回报的平均值来估计 Vπ(s)。
- 动作价值估计:类似地,动作价值 Qπ(s,a) 可以通过记录在状态 s 采取动作 a 后的回报平均值来估计。
1)蒙特卡洛方法(Monte Carlo Method,MC)
核心思想
蒙特卡洛方法是一种通过 随机采样和 统计平均来估计期望值的数值计算方法。在强化学习中,蒙特卡洛方法通过 完整轨迹的回报平均来估计状态价值或动作价值,适用于 偶发任务(Episodic Tasks)。其核心思想是通过大量采样来逼近真实值,无需知道环境模型,仅依赖与环境交互产生的轨迹数据。
伪代码
初始化
给出初始策略 π 0 (随机或启发式策略)。
目标
寻找最优策略。
循环过程
当价值估计未收敛时,在第 k 次迭代执行以下操作:
- 遍历所有状态 s∈S(S 为状态集合):
- 遍历所有可行动作 a∈A(s)(A(s) 为状态 s 下的可行动作集合):
- 蒙特卡洛策略评估步骤:
- 遵循当前策略 πk,从状态-动作对 (s,a) 开始收集足够多的轨迹(episode)。
- 计算 qπk(s,a):
- qπk(s,a) 定义为所有从 (s,a) 开始的轨迹的平均回报(即折扣累积奖励的均值)。
- 策略改进步骤:
- 对状态 s,找到使 qπk(s,a) 最大的动作 ak∗(s):ak∗(s)=argmaxqπk(s,a)
- 更新策略 πk+1:
- 蒙特卡洛策略评估步骤:
- 遍历所有可行动作 a∈A(s)(A(s) 为状态 s 下的可行动作集合):
若动作 a 是最优动作 a k∗( s),则设定 π k+1( a∣ s)=1;
若动作 a 不是最优动作 a k∗( s),则设定 π k+1( a∣ s)=0。
实现代码
import time
import numpy as np
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def obtain_episode(self, policy, start_state, start_action, length):f""":param policy: 由指定策略产生episode:param start_state: 起始state:param start_action: 起始action:param length: episode 长度:return: 一个 state,action,reward,next_state,next_action 序列"""self.env.agent_location = self.env.state2pos(start_state)episode = []next_action = start_actionnext_state = start_statewhile length > 0:length -= 1state = next_stateaction = next_action_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)next_action = np.random.choice(np.arange(len(policy[next_state])),p=policy[next_state])episode.append({"state": state, "action": action, "reward": reward, "next_state": next_state,"next_action": next_action})return episodedef mc_basic(self, length=30, epochs=10):""":param length: 每一个 state-action 对的长度:return:"""time_start = time.time()for epoch in range(epochs):for state in range(self.state_space_size):for action in range(self.action_space_size):episode = self.obtain_episode(self.policy, state, action, length) #收集episodeg = 0for step in range(len(episode) - 1, -1, -1):g = episode[step]['reward'] + self.gama * g #计算q_pi_kself.qvalue[state][action] = gqvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)self.policy[state] = np.zeros(shape=self.action_space_size)self.policy[state, action_star] = 1 #更新策略time_end = time.time()print("mc cost time:" + str(time_end - time_start))def show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.mc_basic()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
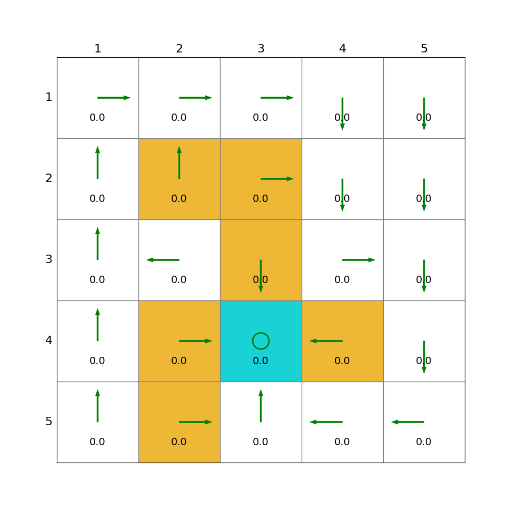
2)蒙特卡洛起始探索法(MC Exploring Starts)
核心思想
蒙特卡洛起始探索法是一种 策略改进方法,通过 强制从所有可能的状态-动作对开始采样来保证探索性。其核心思想是:在每次采样时,随机选择初始状态和动作,确保每个状态-动作对都有机会被访问,从而避免陷入局部最优。
关键点:
- 探索性保证:通过随机初始化状态和动作,确保所有可能的状态-动作对都被探索。
- 适用性:在理论分析中常用,但在实际应用中难以实现,因为需要预先知道所有可能的状态-动作对。
- 局限性:难以扩展到连续状态空间或大规模问题,仅作为算法设计的参考。
伪代码
初始化
- 给出初始策略猜测:π0
目标
- 寻找一个最优策略π∗
对每一个轨迹(episode)执行以下操作
1. 轨迹生成(Episode Generation)
- 随机选择一个起始状态-动作对(s0,a0)
- 确保所有可能的状态-动作对都有机会作为起点被选中
- 根据当前策略 π 生成一个长度为T 的轨迹:s0,a0,r1,⋯,sT−1,aT−1,rT其中:
- st 表示第 t 步的状态
- at 表示第 t 步采取的动作
- rt+1 表示从状态st 执行动作 at 后获得的即时奖励
2. 策略评估与策略改进
初始化
- 设置累计回报g←0
反向处理轨迹中的每一步(从最后一步倒推至第一步)
- 对于时间步t=T−1,T−2,⋯,0,依次执行:g←γ⋅g+rt+1
其中 γ∈[0,1] 是折扣因子。
首次访问法(First-Visit Method)
- 如果状态-动作对(st,at) 在该轨迹前面的部分未出现过(即不是第一次访问):
Returns( s t, a t)← Returns( s t, a t)+ g
q( s t, a t)←average( Returns( s t, a t))
即:
- 将当前的累计回报g 加入到该状态-动作对的历史回报列表中
- 计算其平均值作为该状态-动作对的动作价值函数估计值q(st,at)
策略更新
- 对于每个状态st,将策略更新为贪婪策略:

即:
- 在状态 st 下,仅以概率 1 选择使q(st,a) 最大的动作,其余动作的概率为 0
实现代码
import time
import numpy as np
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def obtain_episode(self, policy, start_state, start_action, length):f""":param policy: 由指定策略产生episode:param start_state: 起始state:param start_action: 起始action:param length: episode 长度:return: 一个 state,action,reward,next_state,next_action 序列"""self.env.agent_location = self.env.state2pos(start_state)episode = []next_action = start_actionnext_state = start_statewhile length > 0:length -= 1state = next_stateaction = next_action_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)next_action = np.random.choice(np.arange(len(policy[next_state])),p=policy[next_state])episode.append({"state": state, "action": action, "reward": reward, "next_state": next_state,"next_action": next_action})return episodedef mc_exploring_starts(self, length=10):time_start = time.time()policy = self.mean_policy.copy()qvalue = self.qvalue.copy()returns = [[[0 for row in range(1)] for col in range(5)] for block in range(25)]self.policy = self.random_policy()while np.linalg.norm(policy - self.policy, ord=1) > 0.001:policy = self.policy.copy()for state in range(self.state_space_size):for action in range(self.action_space_size):visit_list = []g = 0episode = self.obtain_episode(policy=self.policy, start_state=state, start_action=action,length=length) #轨迹生成for step in range(len(episode) - 1, -1, -1):reward = episode[step]['reward']state = episode[step]['state']action = episode[step]['action']g = self.gama * g + reward# first visitif [state, action] not in visit_list:visit_list.append([state, action])returns[state][action].append(g)qvalue[state, action] = np.array(returns[state][action]).mean()qvalue_star = qvalue[state].max()action_star = qvalue[state].tolist().index(qvalue_star)self.policy[state] = np.zeros(shape=self.action_space_size).copy()self.policy[state, action_star] = 1print(np.linalg.norm(policy - self.policy, ord=1))time_end = time.time()print("mc_exploring_starts cost time:" + str(time_end - time_start))def random_policy(self):"""生成随机的策略,随机生成一个策略:return:"""policy = np.zeros(shape=(self.state_space_size, self.action_space_size))for state_index in range(self.state_space_size):action = np.random.choice(range(self.action_space_size))policy[state_index, action] = 1return policydef show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.mc_exploring_starts()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
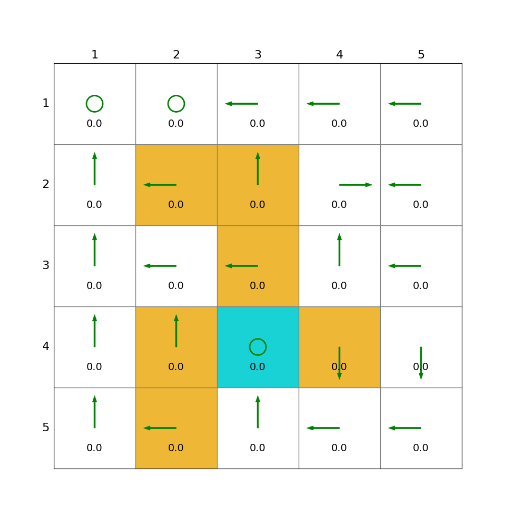
3)蒙特卡洛ε-贪婪法(MC ε-greedy)
核心思想
蒙特卡洛ε-贪婪法是一种 探索与利用平衡策略,通过 以概率ε随机选择动作来保证探索性,同时以概率 1− ϵ 选择当前最优动作。其核心思想是:在策略改进过程中,通过引入随机性来避免陷入局部最优,同时利用已有知识选择最优动作。
关键点:
- 探索与利用:
- 探索:以概率 ϵ 随机选择动作。
- 利用:以概率 1−ϵ 选择当前最优动作 argmaxaQ(s,a)。
- 动态调整:ε可随时间递减(如从0.1逐渐降至0.01),平衡早期探索和后期利用。
- 无偏性:在无限采样下,ε-贪婪策略可保证价值估计的无偏性。
伪代码
初始化
- 给出初始策略猜测 π0
- 给定一个参数 ε∈[0,1],表示探索的概率
目标
- 寻找一个最优策略
对每个轨迹(episode)执行以下操作
1. 轨迹生成(Episode Generation)
- 随机选择一个起始状态-动作对(s0,a0)
- 根据当前策略 π,生成一个长度为 T 的轨迹:s0,a0,r1,⋯,sT−1,aT−1,rT
2. 策略评估与策略改进(Policy Evaluation and Policy Improvement)
初始化
- 设置累计回报 g←0
反向处理轨迹中的每一步(从最后一步倒推到第一步)
- 对时间步 t=T−1,T−2,…,0,依次执行:g←γ⋅g+rt+1
其中 γ 是折扣因子。
使用每次访问法(Every-Visit Method)
- 将当前的累计回报g 添加到对应状态-动作对 (st,at) 的回报列表中:
Returns( s t, a t)← Returns( s t, a t)+ g
- 计算该状态-动作对的动作价值函数估计值:
q( s t, a t)←average( Returns( s t, a t))
策略更新(ε-Greedy 改进)
- 找出当前状态下最优动作:
a∗=arg amax q( s t, a)
- 更新策略π(⋅∣st) 如下:
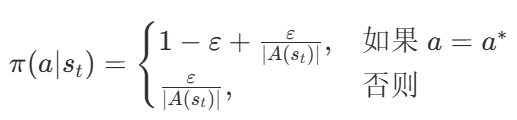
其中:
- ∣A(st)∣ 表示在状态st 下可选动作的数量
- π(a∣st) 表示在状态 st 下选择动作a 的概率
实现代码
import time
import numpy as np
import grid_env
import randomclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def obtain_episode(self, policy, start_state, start_action, length):f""":param policy: 由指定策略产生episode:param start_state: 起始state:param start_action: 起始action:param length: episode 长度:return: 一个 state,action,reward,next_state,next_action 序列"""self.env.agent_location = self.env.state2pos(start_state)episode = []next_action = start_actionnext_state = start_statewhile length > 0:length -= 1state = next_stateaction = next_action_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)next_action = np.random.choice(np.arange(len(policy[next_state])),p=policy[next_state])episode.append({"state": state, "action": action, "reward": reward, "next_state": next_state,"next_action": next_action})return episodedef mc_epsilon_greedy(self, length=1000, epsilon=1, tolerance=1):norm_list = []time_start = time.time()qvalue = np.random.random(size=(self.state_space_size, self.action_space_size))returns = [[[0 for row in range(1)] for col in range(5)] for block in range(25)]while True:if epsilon >= 0.01:epsilon -= 0.01print(epsilon)length = 20 + epsilon * lengthif len(norm_list) >= 3:if norm_list[-1] < tolerance and norm_list[-2] < tolerance and norm_list[-3] < tolerance:breakqvalue = self.qvalue.copy()state = random.choice(range(self.state_space_size))action = random.choice(range(self.action_space_size))episode = self.obtain_episode(policy=self.policy, start_state=state, start_action=action,length=length)g = 0for step in range(len(episode) - 1, -1, -1):reward = episode[step]['reward']state = episode[step]['state']action = episode[step]['action']g = self.gama * g + reward# every visitreturns[state][action].append(g)self.qvalue[state, action] = np.array(returns[state][action]).mean()qvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size):if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilonprint(np.linalg.norm(self.qvalue - qvalue, ord=1))norm_list.append(np.linalg.norm(self.qvalue - qvalue, ord=1))time_end = time.time()print(len(norm_list))print("mc_exploring_starts cost time:" + str(time_end - time_start))def show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.mc_epsilon_greedy()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
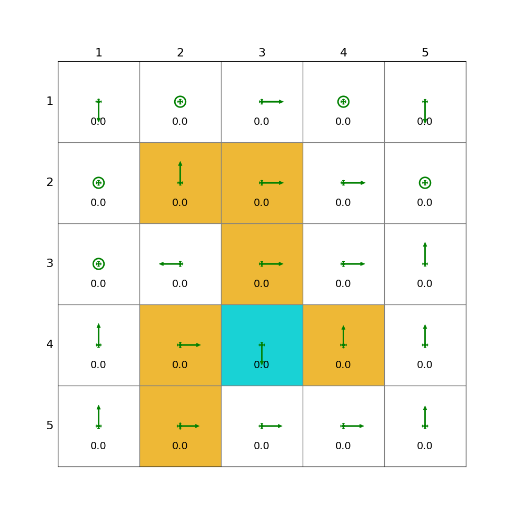
总结
- 蒙特卡洛方法是强化学习中基于完整轨迹的无模型学习算法,通过采样和统计平均估计价值函数。
- 蒙特卡洛起始探索法通过随机初始化保证探索性,但难以实际应用。
- 蒙特卡洛ε-贪婪法通过在策略中引入随机性平衡探索与利用,更适用于实际场景,是强化学习中常用的策略改进方法。