清华与智谱联合发布TTS模型GLM-4-Voice,支持情绪、语气控制,多语言,实时效果很不错~
项目背景
GLM-4-Voice是由清华大学知识工程组(Tsinghua KEG)和智谱AI(Zhipu AI)联合开发的一个开源端到端语音对话模型,旨在推动语音交互技术的进步,弥合机器与人类自然对话之间的差距。
语音交互的挑战与需求
-
语音是人类最自然的交流方式,但传统语音交互系统(如ASR+LLM+TTS的级联方案)在处理语义理解、情感表达和实时性方面存在局限。例如,传统系统难以捕捉语气、情感变化或处理对话中的中断。
-
随着大语言模型(LLM)在文本处理上的成功,业界开始探索如何将LLM的能力迁移到语音模态,实现更智能、更自然的语音交互。GLM-4-Voice正是在这一背景下应运而生,目标是打造一个支持中英文、实时性强、情感表达丰富的端到端语音对话模型。
智谱AI与GLM系列的积累
-
智谱AI是国内领先的AI研究机构,其GLM系列模型(从GLM-130B到GLM-4)在文本和多模态任务上表现出色。GLM-4-9B是一个开源的多语言模型,训练数据高达10万亿token,支持128K甚至1M token的上下文长度,在语义、数学、代码等领域超越Llama-3-8B。
-
GLM-4-Voice基于GLM-4-9B,进一步扩展到语音模态,继承了GLM-4在语言理解和生成上的强大能力,同时针对语音交互进行了专门的预训练和优化。
目标应用场景
-
GLM-4-Voice支持实时语音对话、情感控制、语速调整和方言生成,适用于虚拟助手、数字人、智能客服、教育助手、游戏角色互动等场景。
-
其低延迟和高表达力使其在需要高互动性和情感共鸣的场景中具有潜力,例如心理陪伴或沉浸式娱乐。
GLM-4-Voice技术架构
- GLM-4-Voice的架构设计围绕端到端语音处理,整合了语音识别、语言理解和语音生成,摒弃了传统的级联方案(Speech-to-Text → LLM → Text-to-Speech)。
整体架构
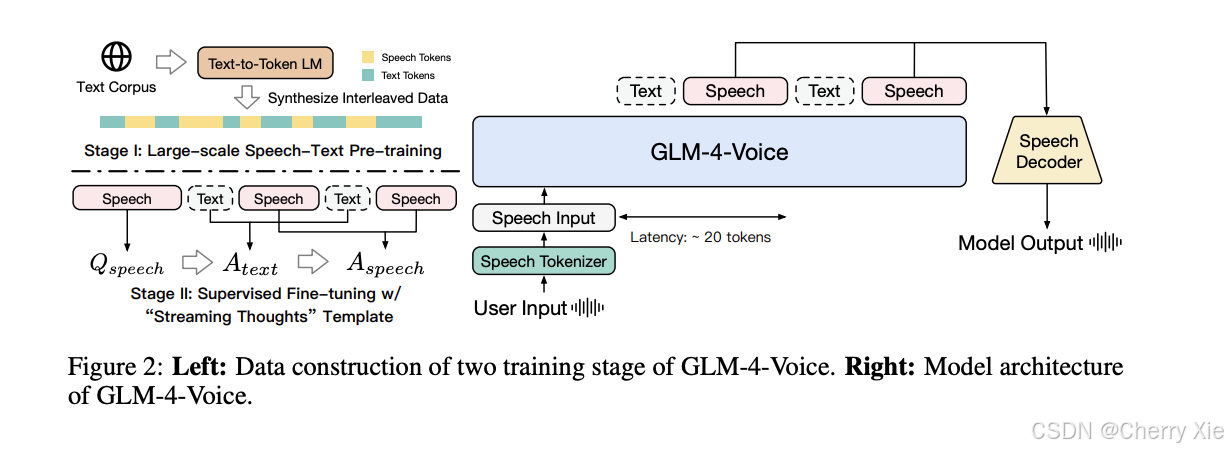
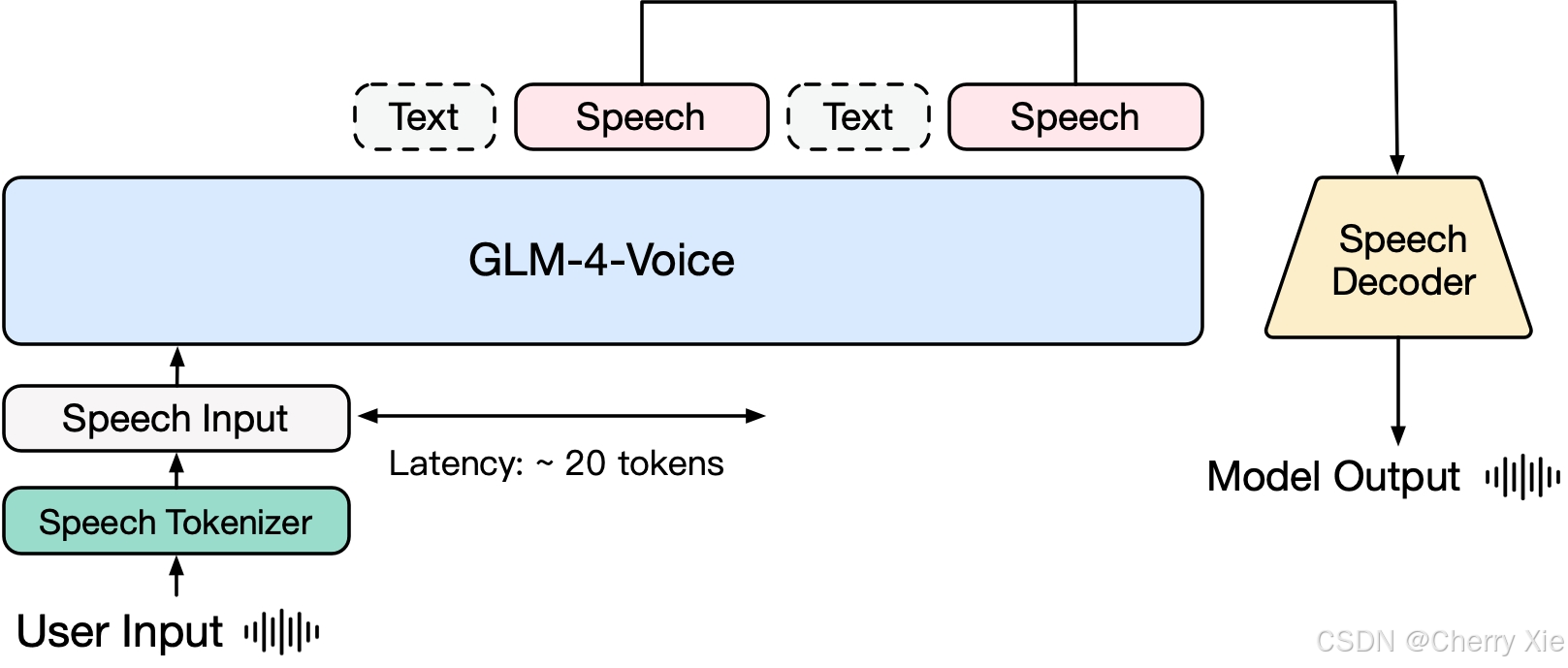
GLM-4-Voice由以下三个主要模块组成,协同实现从语音输入到语音输出的端到端处理:
-
GLM-4-Voice-Tokenizer:负责将连续语音信号转化为离散token。
-
GLM-4-Voice-9B:基于GLM-4-9B的语音模态语言模型,处理离散token的理解与生成。
-
GLM-4-Voice-Decoder:将离散token解码为连续语音输出,支持流式推理。
整个流程为:
-
用户语音输入 → Tokenizer转换为离散token。
-
GLM-4-Voice-9B处理token,生成文本和语音token的响应。
-
Decoder将语音token解码为连续语音输出,同时支持情感、语调等属性调整。
这种端到端设计减少了传统级联方案的模块间误差,降低了延迟,并提升了对话的自然度。
核心组件详解
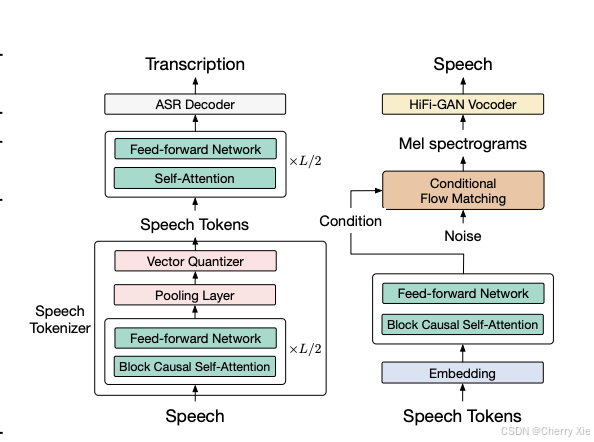
(1) GLM-4-Voice-Tokenizer
-
功能:将连续语音信号转化为离散token,作为模型的输入。
-
技术细节
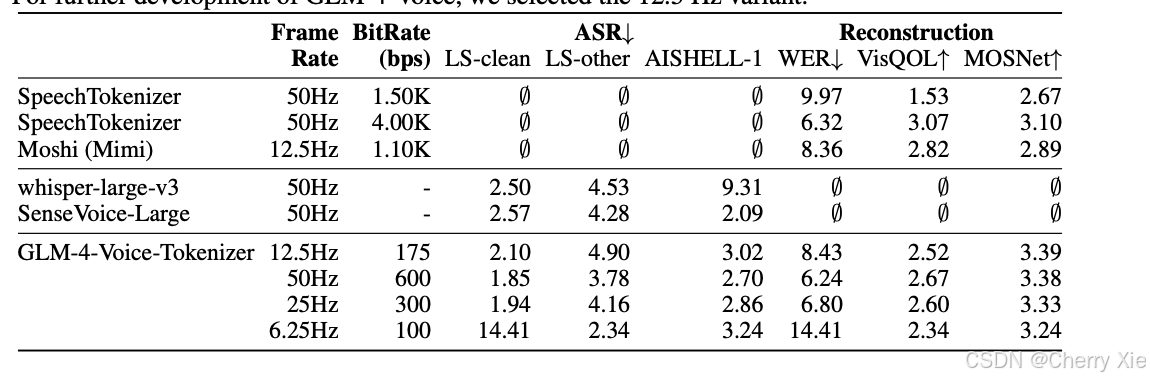
- 基于Whisper的编码器(Encoder)改进,添加了**向量量化(Vector Quantization, VQ)**层,形成单码本(single-codebook)语音分词器。
- 分词器以12.5Hz的帧率运行,平均每秒音频生成12.5个离散token,超低比特率(175bps)确保高效处理。
- 通过在自动语音识别(ASR)数据上进行有监督训练,分词器能有效捕捉语音的语义和声学特征。
-
创新点
- 相比传统ASR,GLM-4-Voice-Tokenizer直接生成离散token,避免了文本中间表示,减少信息损失。
- 低比特率设计降低了计算和存储需求,适合在资源受限设备上运行。
(2) GLM-4-Voice-9B
-
功能:核心语言模型,负责理解输入token并生成响应(包括文本和语音token)。
-
技术细节
- 基于GLM-4-9B(90亿参数的预训练文本模型)进行语音模态的继续预训练和对齐。
-
预训练数据包括:
- 数百万小时的无监督语音数据。
- 基于文本预训练语料合成的语音-文本交错数据(通过文本到token模型生成)。
- 有监督的语音-文本对齐数据。
- 总计1万亿token的训练规模。
-
模型支持中英文语音的理解和生成,能够根据用户指令调整情感、语调、语速和方言。
-
创新点
- 语音-文本交错预训练:通过合成语音-文本交错数据,将文本模态的知识高效迁移到语音模态,解决了语音数据稀缺的问题。
- 流式思考架构:模型交替输出文本和语音模态内容,文本作为参照确保回复质量,语音则根据用户指令动态调整属性。最低只需20个token即可开始语音合成,大幅降低延迟。
- 在语音语言建模和语音问答任务中达到SOTA(state-of-the-art)性能。
(3) GLM-4-Voice-Decoder
-
功能:将离散语音token解码为连续语音输出,支持流式生成。
-
技术细节:
- 基于CosyVoice的Flow Matching模型结构重新训练,支持流式推理。
- 最低只需10个语音token即可开始生成,显著降低端到端对话延迟。
- 支持情感、语调、语速和方言的动态调整,增强语音输出的表现力。
-
创新点
- 流式推理能力使得模型在实时对话中表现更自然,适合低延迟场景。
- 相比传统TTS(Text-to-Speech)系统,Decoder直接处理离散token,避免了文本到语音的额外转换步骤。
与现有模型的对比
与传统级联方案(ASR+LLM+TTS)
-
级联方案(如Whisper + GPT + Alltalk TTS)在语义理解上依赖文本中间表示,难以捕捉语音中的语气和情感。GLM-4-Voice的端到端设计直接处理语音token,保留了更多声学信息。
-
级联方案的延迟较高,而GLM-4-Voice通过流式推理实现低至3秒的首包延迟。
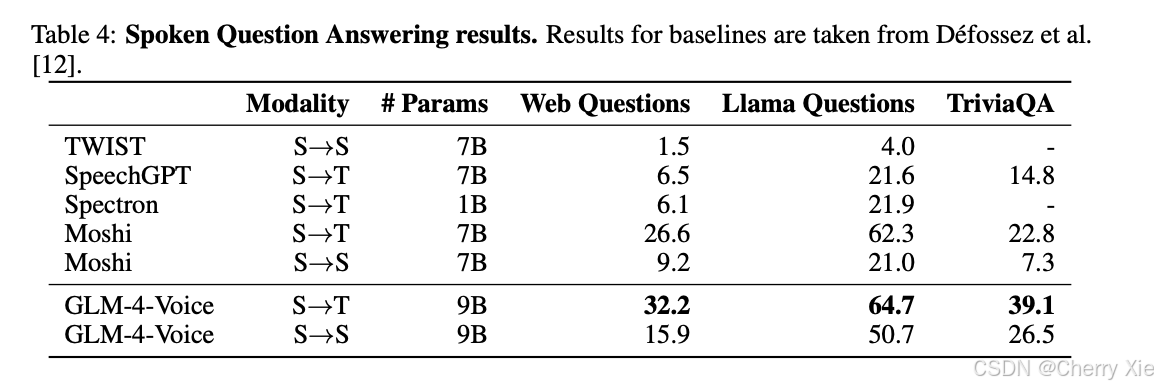
与ChatGPT Advanced Voice
-
ChatGPT Advanced Voice在情感共鸣和实时性上表现出色,但为闭源且需订阅。GLM-4-Voice作为开源替代品,提供类似功能,且支持本地部署,适合隐私敏感场景。
-
GLM-4-Voice在中文对话中表现更优,受益于智谱AI在中文预训练上的积累。
与SpiritLM、Moshi等开源模型
-
SpiritLM在端到端语音生成上表现一般,需额外微调才能完成复杂指令。GLM-4-Voice在预训练规模和对话质量上更具优势。
-
Moshi等模型专注于实时性,但情感表达能力较弱。GLM-4-Voice在情感控制和多语言支持上更全面。
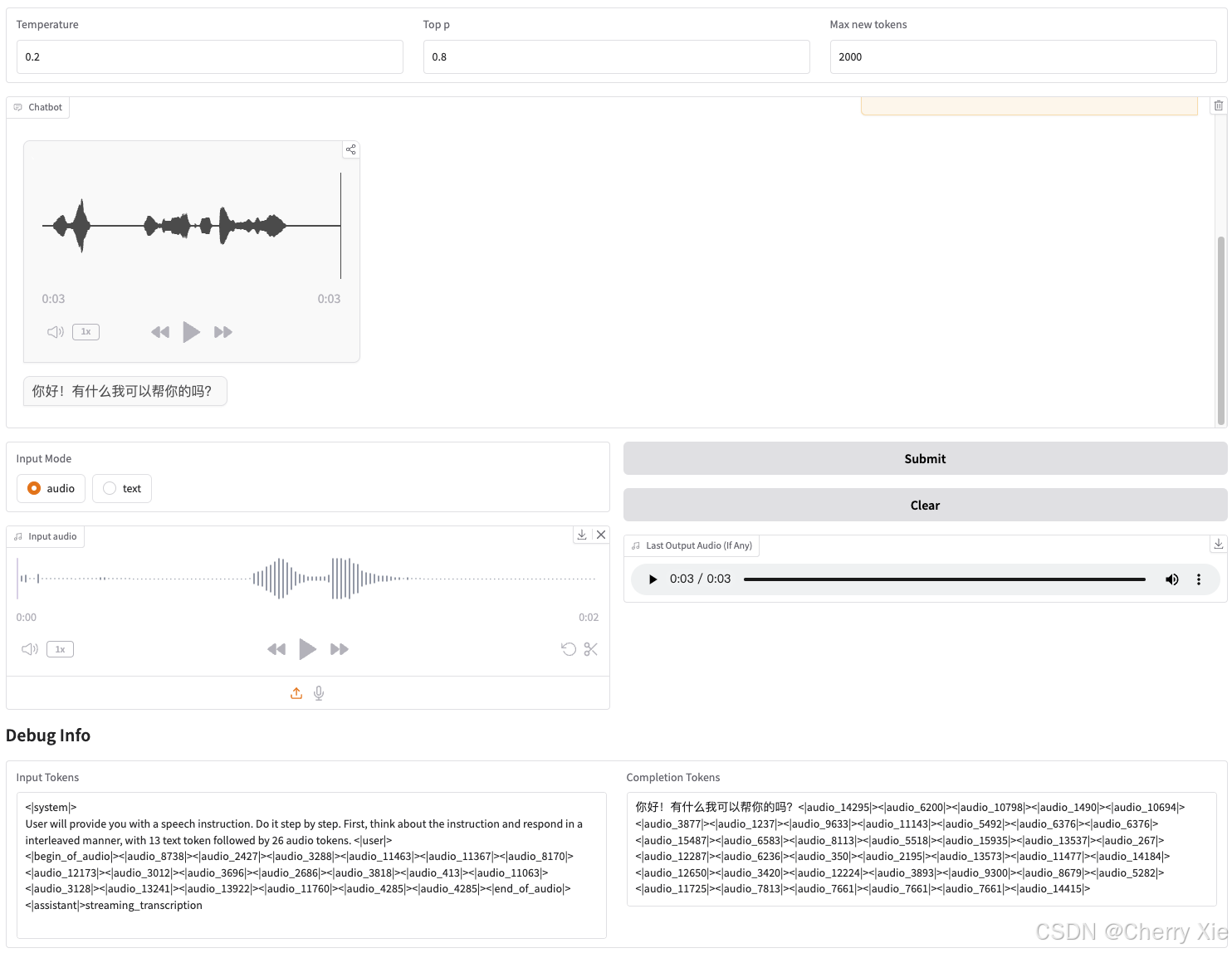
看看效果
相关文献
github地址:https://github.com/THUDM/GLM-4-Voice
demo地址:https://modelscope.cn/studios/ZhipuAI/GLM-4-Voice-Demo
技术报告:https://arxiv.org/pdf/2412.02612