[OS_9] C 标准库和实现 | musl libc | offset
在你感觉有困难的时候,计算机 一定有解决办法
操作系统为我们提供了对象和操作它们的 API:我们学习了进程管理的 fork, execve, exit, waitpid;内存管理的 mmap;文件 (对象) 管理的 open, read, write, dup, close, pipe, ……
- 大家观察到这些 API 的设计有一个有趣的原则:“非必要不实现” (“机制与策略分离”、“最小完备性原则”):但凡应用程序能自己搞定的功能,操作系统就不需要提供——在一定程度上
- 这样的设计能防止 “包揽一切” 导致代码膨胀,甚至在长期演化的过程中成为历史的包袱。
本文内容:
在操作系统 API 之上,为了服务应用程序,毋庸置疑需要有一套 “好用” 的库函数。
虽然 libc 在今天的确谈不上 “好用”,但成就了 C 语言今天 “高级的汇编语言” 的可移植地位,以 ISO 标准的形式支撑了操作系统生态上的万千应用。

9.1 libc 简介
从 “最小” 的 C 程序出发
void _start() {__asm__("mov $60, %eax\n" // syscall: exit"xor %edi, %edi\n" // status: 0"syscall");
}我们可以构建 “整个应用世界”
- C 的语言机制
-
- 指针、数组、结构体、函数……
- 系统调用
-
- fork, execve, mmap, open, ...
系统调用是地基,C 语言是框架
C 语言:世界上 “最通用” 的高级语言
- C 是一种 “高级汇编语言”
-
- 作为对比,C++ 更好用,但也更难移植
- 系统调用的一层 “浅封装”
- C语言具有非常好的可移植性
C23: 演进没有完全停止
constexpr int n = 5 + 4; // ???
typeof(n) arr[n]; // ???[[maybe_unused]] auto* ptr = foo(); // ???
ptr = nullptr; // ???解释
// 定义编译期常量n,值为5+4=9(constexpr确保编译时计算)
constexpr int n = 5 + 4; // 等效于 constexpr int n = 9;// 创建n个元素的数组(typeof(n)推导为int,实际等效于int arr[9])
// 注意:typeof是GCC扩展语法,标准C++建议用decltype(n)或直接写int
typeof(n) arr[n]; // 最终展开:int arr[9]// [[maybe_unused]]属性消除未使用变量的警告
// auto* 自动推导foo()返回的指针类型(假设foo()返回某种指针)
[[maybe_unused]] auto* ptr = foo(); // 等效于 int* ptr = foo()(假设返回int*)// 显式置空指针,避免野指针风险
// 注意:此处赋值nullptr会覆盖之前从foo()获取的指针
ptr = nullptr; 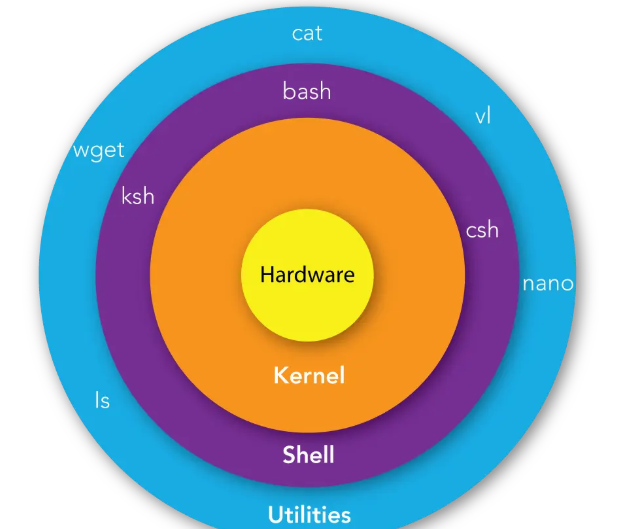
我们现在讲的就是 kernel 部分,shell 部分在脚本语言专栏有串讲
当然:没有库函数,寸步难行
就算有系统调用,也没法编程啊
- 道理上可行,工程上不行
int read(int fd, void *buf, size_t count);
int write(int fd, const void *buf, size_t count);int main() {int a = ???; // 读入 aint b = ???; // 读入 bint sum = a + b;// 输出 sum ???
}The C Standard Library
语言机制上的运行库
- 大部分可以用 C 语言本身实现
- 少部分需要一些 “底层支持”
-
- 例子:体系结构相关的内联汇编
库也被标准化
- ISO IEC 标准的一部分
- POSIX --C Library 的子集
-
- 稳定、可靠 (不用担心升级版本会破坏实现)
- 极佳的移植性:包括你自己的操作系统!
关于 posix:基于 C 语言对汇编的封装,在 C 语言专栏中有介绍过,平时我们也经常用到
Prompt: 为什么称 C 语言是高级的汇编语言?
C语言被称为“高级的汇编语言”,主要因其兼具高级语言的抽象能力和接近硬件的底层控制特性:
- 硬件级操作
C语言支持指针、直接内存访问和位操作,能精准控制硬件资源(如寄存器、内存地址),这与汇编语言相似。 - 高效性
C代码经编译后生成的机器指令效率接近汇编,且可通过内联汇编进一步优化关键代码,适合系统级开发。 - 结构化抽象
相比汇编的指令式编程,C语言提供函数、循环、条件分支等结构化语法,显著提升了代码可读性和可维护性。 - 跨平台与可移植
C语言通过编译器实现硬件适配,避免了汇编语言对特定架构的强依赖,同时保留了对底层细节的控制权。
这一设计使C语言成为操作系统、嵌入式系统等对性能和(A why) 底层控制要求较高场景的理想选择。
如何 “实现” 一个 libc?

借助 cursor 来实现
minilibc: 一个用于教育目的的 C 标准库的简化实现 (claude-3.7-sonnet Cursor IDE),展示了 C 库的核心组件,包括程序的启动和结束、基本的内存管理、字符串操作以及简化的 I/O 功能。该库实现了 _start 函数以设置环境,并提供了简单的 malloc, free, strlen 和 strcpy。构建该库只需运行 make 命令,生成静态库和测试程序。
可见 cursor 专栏中的实现和踩坑
Prompt: 我希望学习 libc 中一些重要函数的实现,但 glibc 太复杂了。有哪些更简单的 libc,让我能链接、调试库的代码?
推荐以下几个轻量级 libc 实现,适合学习核心函数源码:
- musl-libc(推荐这个)
✅ 代码简洁规范,模块化设计
✅ 支持动态/静态链接,调试符号完整
✅ 常用函数如malloc,strlen实现清晰
使用:gcc -static -nostdlib -I musl/include -L musl/lib链接
- dietlibc
✅ 极简设计(约 100KB)
✅ 适合嵌入式场景,POSIX 兼容
✅ 提供diet工具链简化编译
示例:diet gcc -o program program.c
- pdclib (Public Domain C Library)
✅ 专为教学设计的微型实现
✅ 仅实现 ISO C 标准函数
✅ 代码注释详细,适合逐行分析
调试建议:
- 编译时添加
-g保留调试符号 - 使用
gdb单步跟踪函数调用 objdump -d反汇编观察指令级实现- 结合标准文档 (如 POSIX) 对照源码理解设计逻辑
9.2 基础编程机制的抽象
学习已有 libc 的实现
调试 glibc?
- 不,你不想
- glibc 的代码有非常沉重的历史包袱
-
- 以及非常多的优化——都是对 “理解原理” 的阻碍
- 新手阅读体验极差
基本原则:总有办法的
- 让 AI Copilot 帮你解释代码 (这个可以有)
- 是否有比 glibc 更适合学习的 libc 实现?
-
- (人的知识储备是跟不上 AI 的,更跟不上有 RAG 的 AI)
- 幸好我还做了正确的选择:musl
学习已有 libc 的实现 (cont'd)
下载源码不难,难的是怎么 “使用” 下载的 libc
- 我们知道可以使用 gcc 和 ld
- 但到底应该用什么编译选项?
如何使用我自己的 clang、musl 替代 glibc 编译程序?
- 当然,我们还是选择自己编译
-
- 比较重要的选项
-
-
- -O1: 减少优化级别,便于查看状态
- -g3: 增加调试信息
-
-
- 使用 musl-gcc 静态编译
- 后面章节,我们会讲到动态链接的巧妙
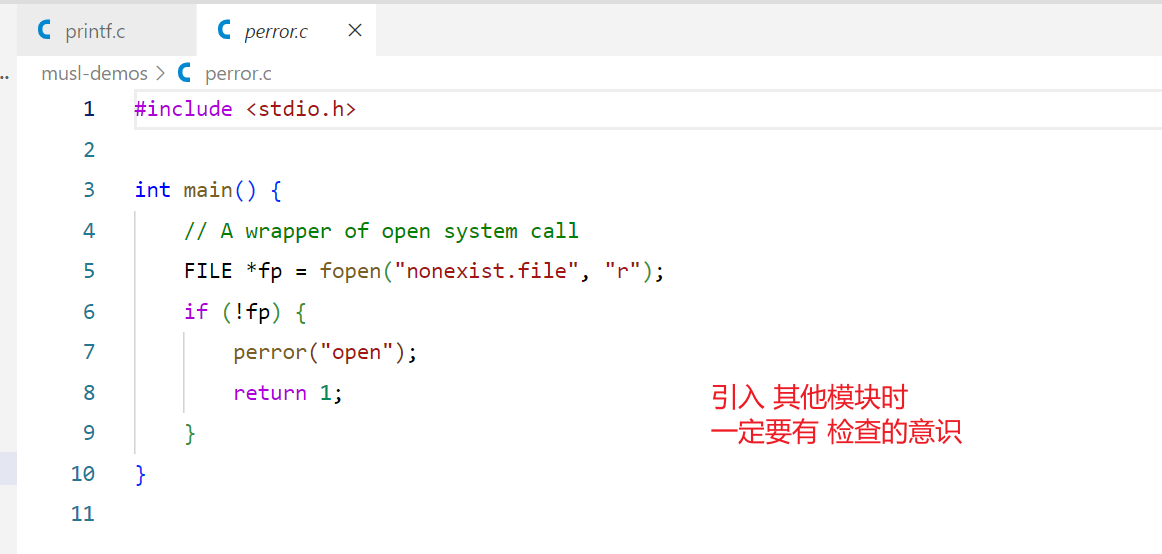
调试
基础数据的体系结构无关抽象
Freestanding 环境下也可以使用的定义
- stddef.h -
size_t
-
- 还有一个有趣的 “offsetof” (Demo; 遍历手册的乐趣)
- stdint.h -
int32_t,uint64_t - stdbool.h -
bool,true,false - float.h
- limits.h
- stdarg.h
- inttypes.h
-
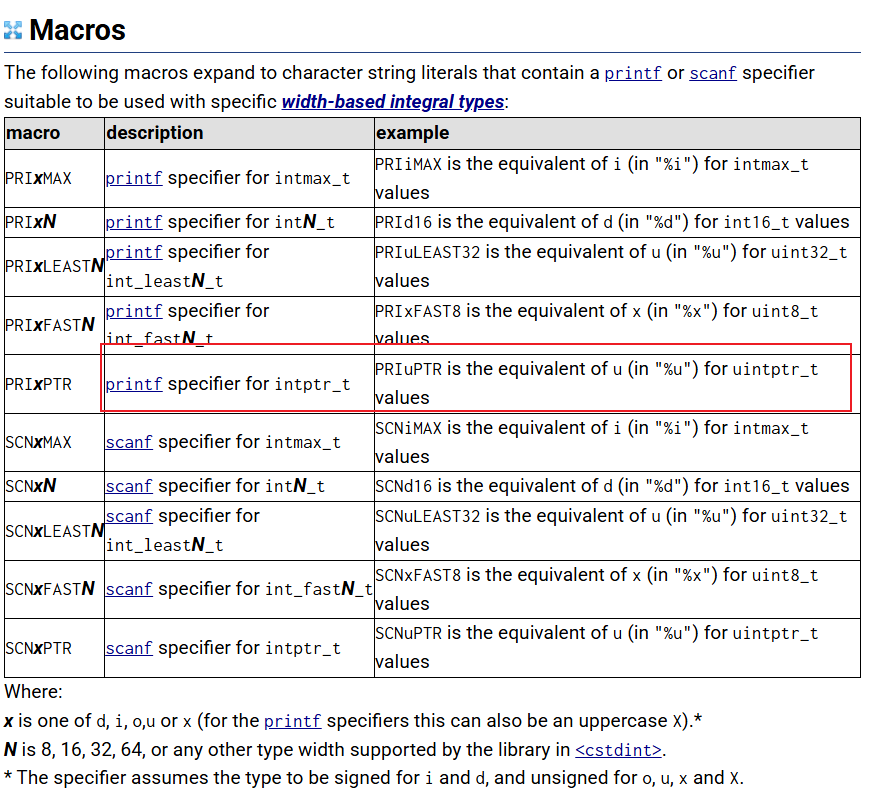
- 打印 intptr_t 变量 printf 的格式字符串是什么?
字符串和数组操作
string.h: 字符串/数组操作
- memcpy, memmove, strcpy, ...
stdlib.h: 常用功能
- rand, abort, atexit, system, atoi, ...
- 看起来就不像是人用的
// C
void qsort(void*, size_t, size_t, int (*)(const void*, const void*));// C++
std::ranges::sort(xs, [](const auto& x, const auto& y) { ... });这些 api 在 C 语言专栏我们许多都用到过,感兴趣的可以去看看~
在 AI 的指导下阅读手册
- 更多的 stdlib.h 中的例子
-
- atoi, atol, atoll, strtoull, ...
- rand (注意线程安全), ...
- math.h
-
- FP8: E4M3/E5M2; Quantization
- 一个原本就深奥的课题;AI 时代变得更复杂困难
- setjmp.h
-
- 这个好玩!要用状态机去理解
- 实现库函数 = C 语言课程习题🙂
talk with ai 专栏中有讨论过
关于 AI 擅长做什么、不擅长做什么
“Attention is all you need.”
- 你需要给他 “关键词” (prompt engineering)
- 推理模型降低了对 “关键词” 的依赖
-
- 但 “神来之笔” 的关键词仍然能起决定性的作用

Prompt: 解释 C 标准库中的 offsetof,以及它有什么应用?
offsetof 是 C 标准库中的一个宏,定义在 <stddef.h> 头文件中。它用于计算结构体中某个成员的偏移量(相对于结构体起始地址的字节数)。
语法:
offsetof(type, member)参数:
type:结构体类型。member:结构体中的成员名称。
返回值: 返回 member 在 type 中的偏移量,类型为 size_t。
应用:
- 内存布局分析:用于了解结构体内部的内存布局,便于调试或优化。
- 低级编程:在需要直接操作内存或与硬件交互时,计算偏移量可以避免硬编码。
- 序列化/反序列化:在将结构体数据转换为字节流时,可以利用偏移量精确访问特定字段。
看越多的书之后,会发现许多知识之间都是环环相扣的,我们应始终坚信“源码之下无秘密”
示例:
#include <stdio.h>
#include <stddef.h>struct Example {int a;char b;double c;
};int main() {printf("Offset of 'a': %zu\n", offsetof(struct Example, a)); // 输出 0 //占用4字节 0-3printf("Offset of 'b': %zu\n", offsetof(struct Example, b)); // 输出 4//占用1字节 4//填充 5-7//因为 char 内存对齐 要为8的倍数printf("Offset of 'c': %zu\n", offsetof(struct Example, c)); // 输出 8return 0;
}这个宏在需要精确控制内存布局或进行底层操作时非常有用。
至于为什么偏移这么多,C 语言内存对齐部分有详细讲过
19.(C进阶)结构体(全)
- 总的来说,结构体的内存对齐是拿空间来换取时间的做法
- 还有 Redis 中的 bitfield 和 C 中的位域,非常相似的!!
这里简要概述一下,结构体内存偏移现象由 数据对齐规则 和 编译器内存填充 共同导致:
一、核心原因
- 对齐规则(Alignment)
-
int类型通常需要4字节对齐(地址是4的倍数)double类型通常需要8字节对齐(地址是8的倍数)char类型无对齐要求(地址任意)
- 编译器填充(Padding)
编译器会在成员之间插入空白字节,确保下一个成员满足对齐要求。
二、内存布局详解
内存地址 | 成员 | 占用字节 | 说明
----------------------------------------
0x00 | a | 4字节 | int从0开始对齐(满足4字节对齐)
0x04 | b | 1字节 | char无需对齐
0x05-0x07| 填充 | 3字节 | 确保下一个double从8开始(满足8对齐)
0x08 | c | 8字节 | double对齐完成- 结构体总大小
总内存 = 4(int) + 1(char) + 3(填充) + 8(double) = 16字节
三、编译指令控制对齐
可通过 #pragma pack 修改对齐规则(慎用,可能影响性能):
#pragma pack(1) // 强制1字节对齐(无填充)
struct PackedExample {int a; // 0-3char b; // 4double c; // 5-12(但访问会有性能损耗)
}; // 总大小=13字节再来看文档中的这个例子,就变得很清晰了
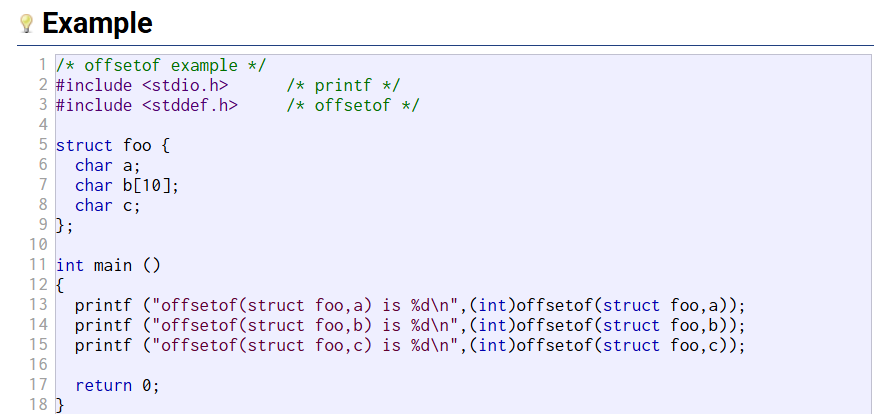
运行:
