强化学习之RLHF
1.简单介绍强化学习?
强化学习(Reinforcement Learning,RL)研究的问题是智能体(Agent)与环境(Environment) 交互的问题,其目标是使智能体在复杂且不确定的环境中最大化奖励(Reward)。
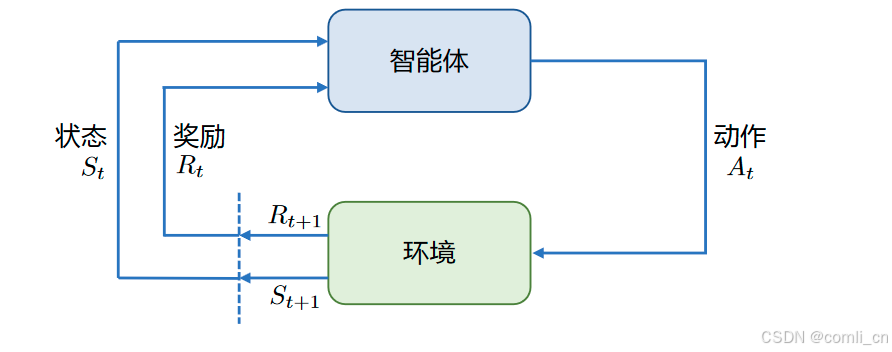
强化学习基本框 架如图所示,主要由两部分组成:智能体和环境。在强化学习过程中,智能体与环境不断交互。 智能体在环境中获取某个状态后,会根据该状态输出一个动作(Action),也称为决策(Decision)。 动作会在环境中执行,环境会根据智能体采取的动作,给出下一个状态以及当前动作所带来的奖 励。智能体的目标就是尽可能多地从环境中获取奖励。本节中将介绍强化学习的基本概念、强化 学习与有监督学习的区别,以及在大语言模型中基于人类反馈的强化学习流程。
强化学习在大语言模型上的重要作用可以概括为以下几个方面:
- 强化学习比有监督学习更可以考虑整体影响:有监督学习针对单个词元进行反馈,其目标是要求模型针对给