当前位置: 首页 > news >正文 Spark-Streaming核心编程 news 2025/11/3 13:51:14 Kafka数据源 需求:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台 2. 导入依赖 编写代码 5.开启Kafka集群 6.开启Kafka生产者,产生数据 查看全文 http://www.dtcms.com/a/153515.html 相关文章: Java集成【邮箱验证找回密码】功能 聊聊Spring AI Alibaba的OneNoteDocumentReader 实现Variant AI赋能Python长时序植被遥感动态分析、物候提取、时空变异归因及RSEI生态评估 系统高性能设计核心机制图解:缓存优化、链表调度与时间轮原理 白鲸开源WhaleStudio与崖山数据库管理系统YashanDB完成产品兼容互认证 麒麟系统离线安装软件方法(kazam录屏软件为例) SEO的关键词研究与优化 第一章 AI | 最近比较火的几个生成式对话 AI YOLO训练时到底需不需要使用权重 【AI提示词】私人教练 昆仑万维开源SkyReels-V2,解锁无限时长电影级创作,总分83.9%登顶V-Bench榜单 使用正确的 JVM 功能加速现有部署 Kaamel视角下的MCP安全最佳实践 python-69-基于graphviz可视化软件生成流程图 文件操作、流对象示例 用 Python 实现基于 Open CASCADE 的 CAD 绘图工具 碰一碰发视频源码文案功能,支持OEM VulnHub-DC-2靶机渗透教程 编译型语言、解释型语言与混合型语言:原理、区别与应用场景详解 【C++】STL之deque flutter 中各种日志 无感字符编码原址转换术——系统内存(Mermaid文本图表版/DeepSeek) express查看文件上传报文,处理文件上传,以及formidable包的使用 深入浅出 Python 协程:从异步基础到开发测试工具的实践指南 了解低功耗蓝牙中的安全密钥 JavaScript性能优化实战(4):异步编程与主线程优化 从被动运维到智能预警:某省人防办借力智和信通运维方案实现效能跃升 NXP----SVR5510芯片layout设计总结 2025年04月24日Github流行趋势
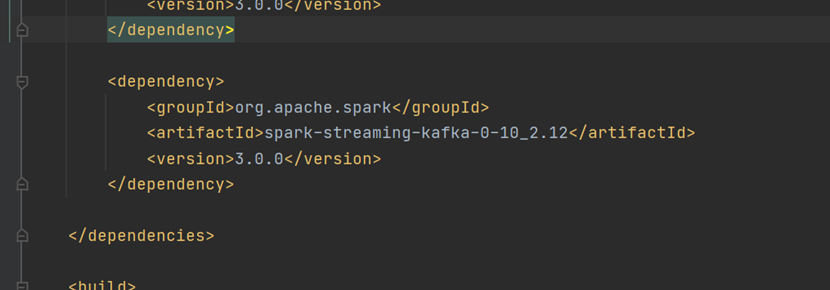
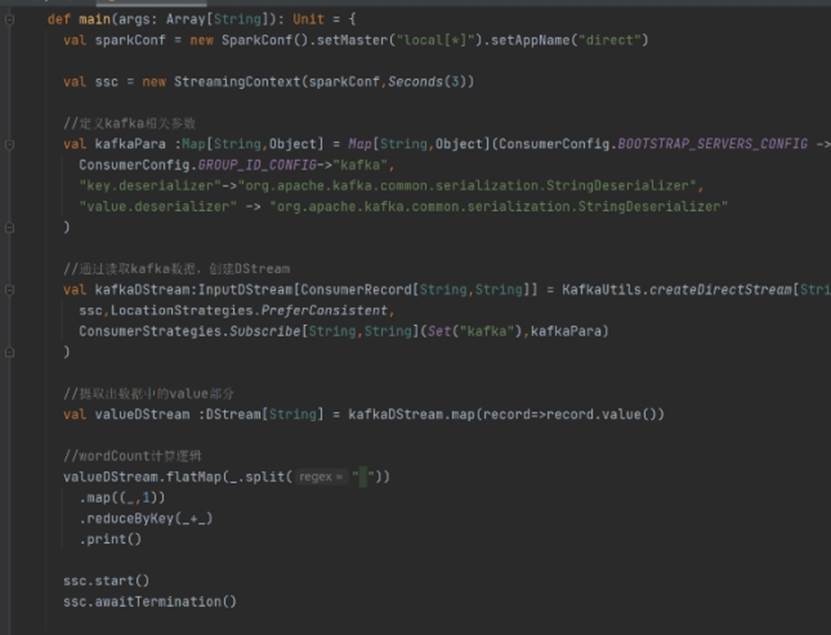
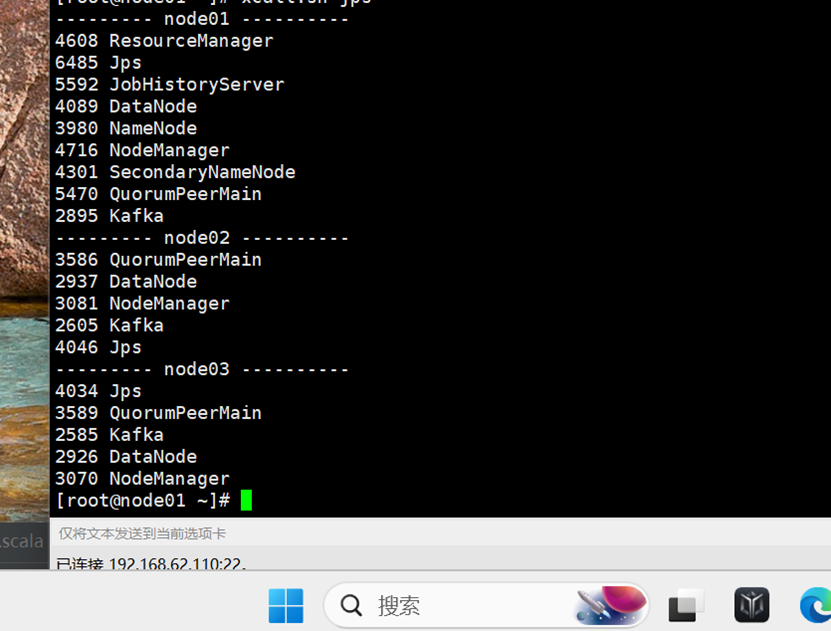
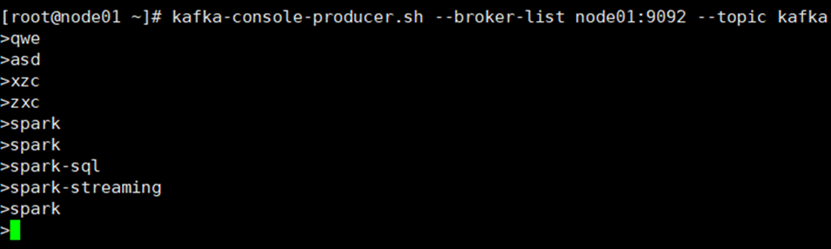
Kafka数据源 需求:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台 2. 导入依赖 编写代码 5.开启Kafka集群 6.开启Kafka生产者,产生数据