http协议、全站https
一、http协议
1、为何要学http协议?
用户用浏览器访问网页,默认走的都是http协议,所以要深入研究web层,必须掌握http协议
2、什么是http协议
1、全称Hyper Text Transfer Protocol(超文本传输协议)
### 一个请求得到一个响应包
普通文本:文件内存放的是一些人类认识的文字符号(汉字、英语、阿拉伯数字)
超级文本:除了普通文本内容之外,还有视频、图片、语音、超链接
超文本包含:html文件、css、js、图片、视频、语音
http协议都能传输上述内容,所以说http协议是专用于传输超文本的协议
2、http主要用于B/S架构
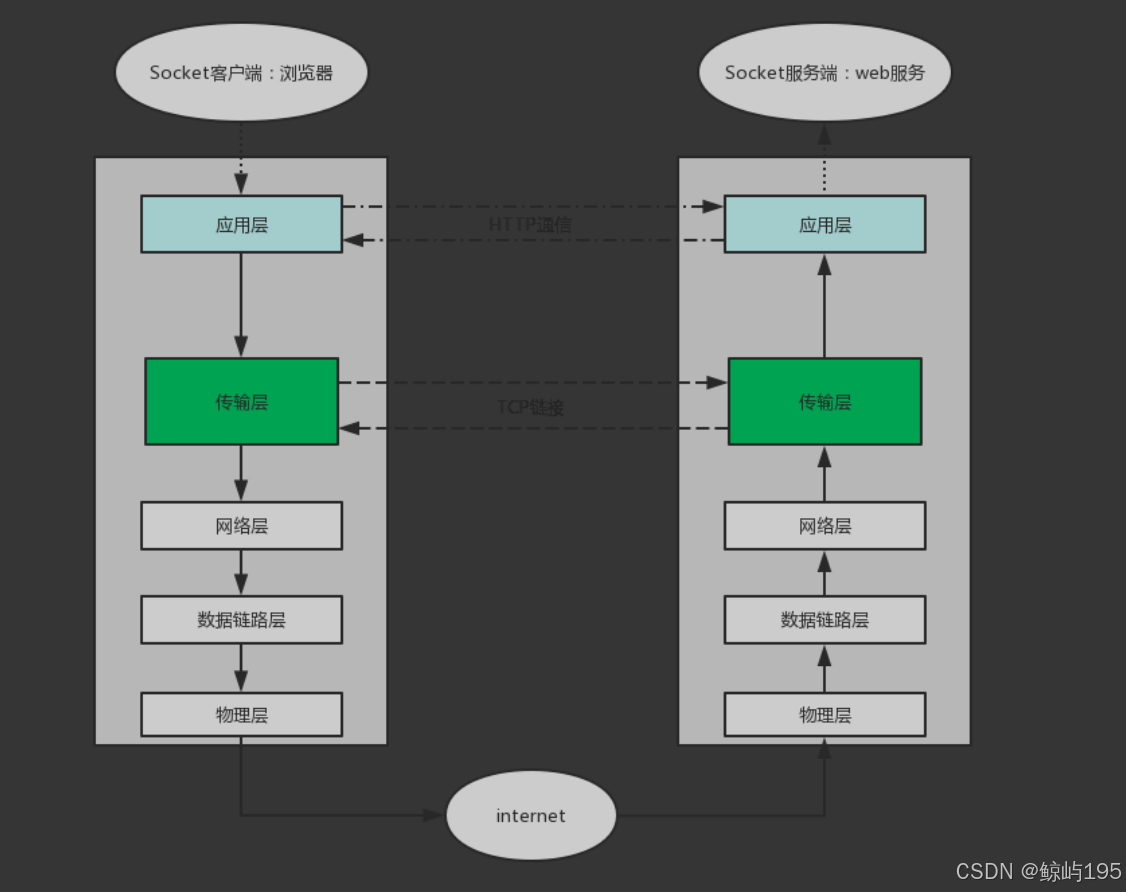
3、http是基于tcp协议的
强调:基于http协议发包之前,必须先建立tcp协议的双向通路
http协议的发展史
网景浏览器(万能客户端)------》各种各样的服务端
http0.9
请求方法:只支持GET方法
请求头:不支持
响应信息:只支持纯文本,不支持图片
无连接/短连接/非持久连接:利用完tcp连接之后会立即回收,所以无连接指的不是说没有连接,而是说没有持久连接/长连接
http协议通信,先建立tcp连接,然后客户端发请求包,服务端收到后发送响应包,服务端一旦发送完响应包之后,服务端会立即主动断开tcp连接,下次http通信还需要重新建立tcp连接
无状态:(一个http协议的请求无法标识自己的身份)
http无法保存状态,比如登录状态----登录之后再次发送的请求无法识别身份
总结:(0.9的时代,下面两个问题都不是问题)
无连接/短连接/非持久连接---->引发的问题
同一个用户在短期内访问多次服务端,那大量的时候都会消耗在重复创建tcp连接上
在高并发场景下,对服务端是非常大的消耗,客户端的访问速度也会非常的慢
无状态:一个http协议的请求无法标识自己的身份---》引发的问题
如果是登录状态的话,http协议无法保存,那意味着每次请求都需要重新输出一次账号 密码来认证
http1.0
请求方法:支持GET(查)、POST(改)、DELETE(删)、PUT(增)
请求头:支持
响应信息:支持超文本
支持缓存
无连接/短连接/非持久连接
问题:
同一个用户在短期内访问多次服务端,那大量的时候都会消耗在重复创建tcp连接上
在高并发场景下,对服务端是非常大的消耗,客户端的访问速度也会非常的慢
目标:
同一个用户在短期内访问多次服务端,不要重复建立tcp连接,而是能够共用一个tcp链接
解决方案:支持持久连接/长连接 keep-alive
前提:
发送完http响应包之后,服务端立即断tcp连接,这是服务端的默认行为
要改变这种默认行为,要客户端通知服务端才行
实现:
客户端在发送http的请求时,需要再请求头里带上connection: keep-alive这个参数
服务端的keepalive_timeout设置要大于0
服务端收到后读取该参数,服务端会保持与这一个客户端tcp连接一段时间,响应时也会响应头里放connection: keep-alive这个参数
该tcp会保持一段时间 直到达到服务端设置的keepalive_timeout时间
补充:
在http1.0协议例还需要你发请求时你自己加上connection: keep-alive这个参数
在http1.1协议里所有的请求都会自动加上connection: keep-alive,也就是说在http1.1客户端默认就开启了长连接支持
配套的服务端也要开启(服务端的keepalive_timeout设置要大于0,等于0相当于关掉)
----如果用的是nginx 修改/etc/nginx/nginx.conf
http1.1(主要)
1、默认所有请求都启用长连接,对应服务端需要设置keepalive_timeout大于0
2、Pipelining(请求流水线化/管道化)-----可以连续发送多个请求,但响应也必须按照顺序来
3、分块传输编码chunked----不使用分块传输:先告知规定大小,当数据包大小到达指定值后就能知道到这里一个包的内容就结束了
使用分块传输:允许服务器在不知道全部响应大小的情况,(比如由数据库动态产生的数据)通过多个小"块"的形式逐步发送HTTP响应给客户端的技术。除非使用了分块编码Transfer-Encoding: chunked,否则响应头首部必须使用Content-Length首部
http2.0(未来)
http协议的格式
储备知识:什么是URI、URL
URI:统一资源标识符
# Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的
URL:统一资源定位服务,是uri的一种具体实现
http://192.168.71.10:8080/a/b/1.txt?x=1&y=2&page=10#_label5
所有部分:
http:// 协议部分
不写协议,默认http协议
192.168.71.10:8080 ip+port部分
不写端口默认服务端的端口是80
/a/b/1.txt 路径部分
不写路径,默认加一个/结尾
?x=1&y=2&page=10 请求参数部分 通常用于get请求
#_label5 锚 直接跳转到页面的某个部分
一个url地址的路径部分也称之为uri路径
URN:也是uri的一种具体实现 例如:mailto:java-net@java.sun.com。
请求request
包含四部分:
请求首行
GET /