Java集合及面试题学习
知识来源沉默王二、小林coding、javaguide
1、ArrayList
list.add("66") list.get(2) list.remove(1) list.set(1,"55")
List<String> list=new ArrayList<>(); 底层是动态数组
添加元素流程:判断是否扩容,无需扩容则直接加元素。否则计算新容量与10比较,取较大值,然后执行grow()方法,扩容至原来的1.5倍,如果还不够则扩到指定容量,调用Arrays.copyOf方法最后回到add函数里面。返回boolean
设置元素流程:检查索引越界,然后替换新值并返回旧值。
删除元素流程:(下标删除)检查索引越界,移动元素使用Syetem.arraycopy(),最后size--,末尾为null让GC回收,返回删除的元素。(元素删除)根据是否为null来分别判断,null用==,其它用equals方法,返回boolean
查找元素流程:根据是否为null来分别判断,null用==,其它用equals方法,返回元素索引,未找到为-1
list.add(1,"66")
list.remove("66")
list.indexOf("66")
list.lastIndexOf("66")
2、LinkedList
LinkedList<String> list = new LinkedList(); 底层是链表实现的
list.add("33") list.addFirst("11") list.addLast("33")
remove(int):删除指定位置的节点remove(Object):删除指定元素的节点- set(0,"33")
- indexOf(Object):查找某个元素所在的位置
- get(int):查找某个位置上的元素
poll()方法用于删除并返回第一个元素peekFirst()方法用于返回但不删除第一个元素。
3、HashMap
put(1,"11")//增加或修改
remove("1")//删除
get(1) //查询
HashMap 是通过拉链法来解决哈希冲突的,也就是当哈希冲突时,会将相同哈希值的键值对通过链表的形式存放起来,采用的是头插法。
hash方法:hash 方法是用来做哈希值优化的,把哈希值右移 16 位之后与原哈希值做异或运算,增大了随机性。其中调用了键的hashcode方法
扩容机制:
当我们往 HashMap 中不断添加元素时,HashMap 会自动进行扩容操作(条件是元素数量达到负载因子(load factor)乘以数组长度时),以保证其存储的元素数量不会超出其容量限制。在进行扩容操作时,HashMap 会先将数组的长度扩大一倍,然后将原来的元素重新散列到新的数组中。由于元素的位置是通过 key 的 hash 和数组长度进行与运算得到的,因此在数组长度扩大后,元素的位置也会发生一些改变。一部分索引不变,另一部分索引为“原索引+旧容量”。
加载因子:
HashMap 的加载因子是指哈希表中填充元素的个数与桶的数量的比值,当元素个数达到负载因子与桶的数量的乘积时,就需要进行扩容。这个值一般选择 0.75,是因为这个值可以在时间和空间成本之间做到一个折中,使得哈希表的性能达到较好的表现。因为容量是2的n次幂,所以与加载因子乘积后最好是整数,而0.75最合适。
4、ArrayDeque、PriorityQueue
ArrayDeque<String> stack = new ArrayDeque<>();
offer("6")
String top = stack.peek(); //获取
String pop = stack.poll(); //出队
PriorityQeque:堆
PriorityQueue<String> queue = new PriorityQueue<>();
peek()
offer("s")
poll()
5、HashSet
HashSet<String> set = new HashSet<>();
set.add("陈清扬");
boolean containsWanger = set.contains("王二");
boolean removeWanger = set.remove("王二");
修改=增加+删除
6、Java面试算法常用api
算法题常用语法(Java篇) - 知乎
Java常用函数总结_java函数-CSDN博客
List<String> rets1 = new ArrayList<>(Arrays.asList(intro));
Arrays.sort()
Arrays.equals()
String[] revised = Arrays.copyOf(intro, 3);
Collections.reverse(list);
Collections.sort(list);
Collections.swap(list, 2,4);
max(Collection coll)
min(Collection coll)
frequency(Collection c, Object o) //返回指定对象出现的频次
集合通用:
toArray()
size()
isEmpty()
contains()
clear()
数组用nums.length 集合用list.size(),String用length()
面试题
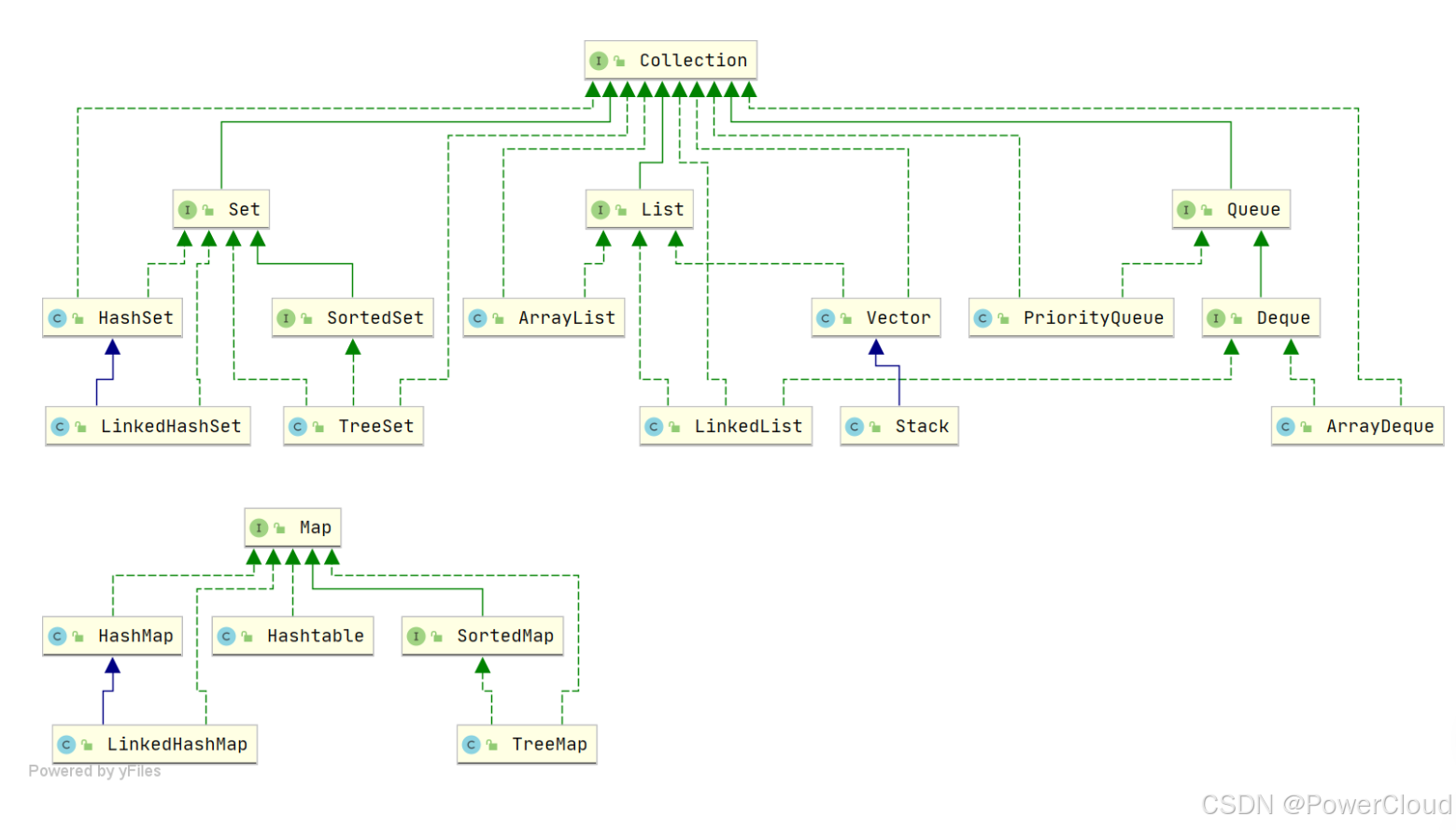
1、 Java集合类有哪些
集合主要有两条大的支线:
一条是Collection,由List\Set\Queue组成。
List代表有序可重复的集合,有封装了动态数组的ArrayList,封装了链表的LinkedList
Set代表无序不可重复的集合,主要有HashSet、TreeSet
Queue代表队列,典型的有双端队列ArrayDeque,优先级队列PriorityDeque
第二条线就是Map,表示键值对的集合,主要代表就是HashMap
2、 用过哪些集合类?它们的优劣?
我常用的集合类有 ArrayList、LinkedList、HashMap、LinkedHashMap。
ArrayList 可以看作是一个动态数组,可以在需要时动态扩容数组的容量,只不过需要复制元素到新的数组。访问速度快但是插入和删除元素可能需要移动或者复制元素。
LinkedList 是一个双向链表,适合频繁的插入和删除操作。缺点是访问元素时需要遍历链表。
HashMap 是一个基于哈希表的键值对集合。可以根据键的哈希值快速查找到值,但有可能会发生哈希冲突,并且不保留键值对的插入顺序。
LinkedHashMap 在 HashMap 的基础上增加了一个双向链表来保持键值对的插入顺序
3、队列和栈说说?有什么区别?
队列是先进先出,栈是先进后出的
4、哪些是线程安全的容器,哪些不安全?(后续补充
Vector:线程安全的动态数组,其内部方法基本都经过synchronized修饰
Hashtable(不推荐):线程安全的哈希表,HashTable 的加锁方法是给每个方法加上 synchronized 关键字,不过现在推荐使用ConcurrentHashMap
还有JUC里有很多线程安全的容器:
ConcurrentHashMap:1.7使用了分段锁,而1.8 中取消了 Segment 分段锁,采用 CAS + synchronized 来保证并发安全性,使用了拉链法存放冲突节点,当冲突节点超过8时转为红黑树
CopyOnWriteArraySet:是线程安全的Set实现,它是线程安全的无序的集合
CopyOnWriteArrayList:它是 ArrayList 的线程安全的变体,其中所有写操作(add,set等)都通过对底层数组进行全新复制来实现,允许存储 null 元素。
ArrayList、LinkedList、HashSet、HashMap: 这些集合类是非线程安全的。在多线程环境中,如果没有适当的同步措施,对这些集合的并发操作可能导致不确定的结果。
5、ArrayList和Array有什么区别
1、数组创建时必须指定大小且不能更改,而ArrayList是动态数组实现的,会自动扩容
2、数组不支持泛型,ArrayList支持泛型
3、数组元素可以为基本类型也可以为对象,但ArrayList只能为对象
4、ArrayList有丰富的增删改查的方法,而数组没有
6、ArrayList和LinkedList区别
1、ArrayList是基于数组实现的,LinkedList是基于链表实现的
2、ArrayList实现了RamdomAccess接口,支持随机访问,查找复杂度为O(1),适用于频繁访问读取的场景
而LinkedList不支持随机访问,因为他是双向链表,插入删除效率为O(1),使用于频繁的增删场景
3、ArrayList是空间占用少,使用的是连续的内存空间,而LinkedList包含了节点的引用,占用会更多。,一般而言ArrayList性能会更加高一些
7、ArrayList扩容机制
因为它底层是基于数组实现的,所以没添加元素时它还是个空数组,当添加第一个元素时,默认初始化容量为10.
当往ArrayList中添加元素时,如果超过当前容量的限制则会进行扩容(如果已经达到了Integer,MAX_VALUE则抛出异常)。扩容是通过一个grow方法,扩容后新数组的长度是原来的1.5倍,如果1.5倍不够,则直接扩容到当前所需的大小。最后再把原数组的值拷贝到新数组中。
8、有哪几种实现ArrayList线程安全的方法?
常用的有两种
1、使用Collections的synchronizedList,会返回一个线程安全的集合,其内部是通过synchronized加锁来实现的
2、使用JUC的CopyOnWriteArrayList,使用写时复制技术,每当对列表进行修改时,都会创建一个新副本,这个新副本会替换旧的列表,而对旧列表的所有读取操作仍然在原有的列表上进行,这样并发读时无需加锁就实现了线程安全。
9、ArrayList和Vector的区别
Vector是线程安全的,是1.0时期的遗留类,现在基本已经不使用了。所有方法都使用synchronized进行同步,单线程环境效率很低。
ArrayList是1.2时期引入的,不支持多线程安全,但在单线程下效率很高
10、Map接口有哪些实现类
比较常用的有 HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap。
如果无需排序则使用HashMap,因为它的性能最好。
如果考虑到多线程安全的问题则使用ConcurrentHashMap,使用了分段锁和CAS机制,性能好于Hashtable
如果考虑到顺序则可以用LinkedhashMap,因为它额外维护了一个双向链表记录插入和访问顺序。
如果需要范围查询按自定义顺序排列则可以用TreeMap,因为它是基于红黑树实现的。
11、详细说说HashMap及其底层原理?
HashMap是将数据以键值对的形式存储的,是线程不安全的。
jdk7是使用数组+链表来实现的,Hash冲突时会使用拉链法将冲突元素放进一个链表中。
jdk8引入了红黑树,链表长度超过8会将链表转换为红黑树,具有更好的性能。
HashMap 的初始容量是 16,如果传入的容量参数不为2的幂次方,则会增大到2的幂次方
随着元素的不断添加,HashMap 就需要进行扩容,阈值是capacity * loadFactor,capacity 为容量,loadFactor 为负载因子,默认为 0.75
12、了解红黑树吗?简单说说
红黑树是一种自平衡的二叉查找树,每个节点只能是红色或黑色其中一种。其中根和叶子节点必须是黑色。从任一节点到叶子节点的简单路径都包含相同数目的黑色节点。红色节点的子节点一定是黑色。
13、为什么超过8会变为红黑树小于6变为链表?
因为它链表节点数量遵从泊松分布,当超过8时概率小于百万分之一,然后才转换为红黑树。如果数量变少的话使用链表更加方便,而如果7就转换的话会产生不小开销,甚至容易产生链表与红黑树的不断转换你。选择6的话是兼顾时间和空间比较合适的数字。
14、为什么使用红黑树,不使用二叉搜索树和AVL树?
二叉树容易出现极端情况,比如插入的数据是有序的,那么二叉树就会退化成链表,查询效率就会变成 O(n)
而AVL树每个节点的左右子树的高度最多相差 1,这种高度的平衡保证了极佳的查找效率,但在进行插入和删除操作时,可能需要频繁地进行旋转来维持树的平衡,维护成本更高
使用红黑树更像是一种折中的方案,查找插入删除的效率都是O(logN)
15、HashMap的put流程
先判断数组是否为空,为空则进行初始化。
然后计算哈希值,(n-1)&hash计算下标位置,构造Node节点放入
如果发生哈希冲突则判断是否为同一个key,如果key不同就要根据数据结构放入节点
如果是红黑树就构造树形节点插进去,链表的化就是Node节点插进去,这里看看是否需要转为红黑树。
最后判断节点数是否大于阈值,大于则扩容为原数组的两倍。
16、为什么hashMap的容量是2的幂次方?
因为hashmap计算下标使用hash&(n-1),n为数组大小,n-1之后恰好产生低位全是1的掩码,保证能很好利用容量空间,并尽量的均匀分布。
(计算hash时利用高16位与低16位异或运算)
实际这里hashmap是将取模运算优化成了位运算,而容量只有为2的幂次方时,两者结果才一致,由于位运算比取模运算快,所以采用位运算+2的幂次方来完美替代取模运算
17、 Hash冲突有哪些解决方式?
有线性探测法:如果发生冲突则顺序查看该下标的下一个位置,直到该下标未被使用
二次探测法:发生冲突则交替变化正负x的平方移动,x从1开始递增。
伪随机探测法:预先生成一个伪随机序列,根据序列的值来进行移动
最后还有链地址法,HashMap就是基于这种方法实现的,冲突的话会放在对应下标的链表上。
这里冲突的判断方式是先判断hashcode,再判断equals,如果都一样则认为key一样,更新value
18、HashMap的扩容机制说说?
jdk1.8中扩容会先生成新数组,其容量是原来的两倍,然后遍历旧哈希表元素
如果是链表的话,则重新计算下标放入新数组中,放置的结果等效于hash&(n-1),n为新的容量大小。
如果是红黑树的话,会遍历红黑树计算出新的下标位置。
如果该位置下元素超过8则生成新的红黑树放进去。
如果没超过8则生成一个链表将元素放进去
最后将新数组赋值给HashMap的table属性
19、负载因子是多少?为什么用这个数?
负载因子是0.75,当HashMap里元素的数量超过容量*负载因子时会发生扩容至原来的2倍。
负载因子如果太低,比如0.5则会浪费很多空间,如果是0.9则会发生太多冲突导致性能下降。
0.75 是 JDK 作者经过大量验证后得出的最优解,能够最大限度减少 rehash 的次数。
而且由于容量是2的幂,所以算出来的数恰好都为整数。虽然0.625,0.875也能整除,但折中考虑0.75更加恰当
20、jdk8对HashMap做了哪些优化
1、底层数据结构由数组+链表转为数组+链表+红黑树
2、链表的插入方式由头插法改为尾插法,能不改变链表的顺序
3、扩容的时机由插入时判断改为插入后判断,避免了覆盖旧值时不必要的扩容问题
4、hash算法进行了优化,原来是多次移位和异或实现,jdk8则是高16位与低16位异或实现
21、HashMap是线程安全的吗?
不是线程安全的,多个线程同时读写时可能会出现并发修改问题。而且它的一些操作不是原子性的,在多线程下可能会出现竟态条件。
比如Jdk7里会出现死锁问题,因为多线程操作HashMap并触发扩容时,可能会形成环形链表,后续遍历链表则会发生死循环。
jdk虽然使用头插法解决了死锁问题,但并发修改导致的数据异常依然没有解决
22、HashMap如何实现线程安全?
1、使用Collections下的synchronizedMap来创建,返回一个同步的Map包装器,所有的Map操作都是同步的。内部是通过 synchronized 对象锁来保证线程安全的
2、使用ConcurrentHashMap,使用了分段锁机制,允许多个线程同时读,提高并发性能。
使用了CAS和synchronized来保证线程安全
3、自己使用显式的锁,比如ReentrantLock来保证线程安全
23、 讲讲HashMap和TreeMap
①、HashMap 是基于数组+链表+红黑树实现的,put 元素的时候会先计算 key 的哈希值,然后通过哈希值计算出元素在数组中的存放下标,然后将元素插入到指定的位置,如果发生哈希冲突,会使用链表来解决,如果链表长度大于 8,会转换为红黑树。
②、TreeMap 是基于红黑树实现的,put 元素的时候会先判断根节点是否为空,如果为空,直接插入到根节点,如果不为空,会通过 key 的比较器来判断元素应该插入到左子树还是右子树。
在没有发生哈希冲突的情况下,HashMap 的查找效率是
O(1)。适用于查找操作比较频繁的场景。TreeMap 的查找效率是
O(logn)。并且保证了元素的顺序,因此适用于需要大量范围查找或者有序遍历的场景。
24、讲讲HashMap和Hashtable
1、 Hashtable 是同步的,即它的方法是线程安全的。这是通过在每个方法上添加同步关键字来实现的,而HashMap 不是同步的,因此它不保证在多线程环境中的线程安全性。
2、Hashtable 不允许键或值为 null。 HashMap 允许键和值都为 null
3、现在HashTable已经不常用了,一般考虑线程安全都会使用ConcurrentHashMap
25、讲讲HashSet的底层实现
HashSet 是由 HashMap 实现的,只不过值由一个固定的 Object 对象填充,而键用于操作。
实际上HashSet并不常用,如果需要去重会考虑使用它,否则会用HashMap或ArrayList来替代它
26、HashSet和ArrayList区别
- ArrayList 是基于动态数组实现的,HashSet 是基于 HashMap 实现的。
- ArrayList 允许重复元素和 null 值。HashSet 保证每个元素唯一,不允许重复元素,基于元素的 hashCode 和 equals 方法来确定元素的唯一性。
- ArrayList 保持元素的插入顺序,可以通过索引访问元素;HashSet 不保证元素的顺序,元素的存储顺序依赖于哈希算法,并且可能随着元素的添加或删除而改变。
27、HashMap和HashSet的区别?
1、HashMap 使用键值对的方式存储数据,通过哈希表实现。 HashSet 实际上是基于 HashMap 实现的,它只使用了 HashMap 的键部分,将值部分设置为一个固定的常量。
2、HashMap 用于存储键值对,其中每个键都唯一,每个键关联一个值。 HashSet 用于存储唯一的元素,不允许重复。
28、HashMap和ConcurrentHashMap区别
1、HashMap 不是线程安全的。在多线程环境中,如果同时进行读写操作可能会导致数据不一致。 ConcurrentHashMap 是线程安全的,它使用了分段锁的机制,将整个数据结构分成多个段,每个段都有自己的锁。这样不同的线程可以同时访问不同的段,提高并发性能。
2、HashMap 在实现上没有明确的同步机制,需要在外部进行同步,例如通过使用 Collections.synchronizedMap() 方法。
3、在单线程或低并发环境下,HashMap 的性能会比 ConcurrentHashMap 稍好,因为 ConcurrentHashMap 需要维护额外的并发控制。 在高并发情况下,ConcurrentHashMap 的性能通常更好,因为它能够更有效地支持并发访问。
高频自测:
- Java的集合类有哪些
- 哪些是线程安全的?哪些是线程不安全的?
- ArrayList 和 Array 有什么区别?
- ArrayList 和 LinkedList 的区别是什么?底层实现是怎么样的?
- ArrayList 扩容机制
- Map 接口有哪些实现类
- Java中的HashMap了解吗?HashMap 的底层实现 【重要】
- Hash 冲突有什么解决方式? HashMap 是如何解决 hash 冲突的
- HashMap 的 put 方法流程
- HashMap 的扩容机制
- HashMap 为什么是线程不安全的? 如何实现线程安全
- concurrentHashMap 如何保证线程安全
- HashSet 和 HashMap 和 HashTable 的区别
- HashMap和ConcurrentHashMap