FlinkCDC初始化时报错“IllegalArgumentException: Unexpected input: “异常定位与原理分析
本篇是纯技术文章,是排查线上问题的真实记录。这个异常我在网上没搜到相同案例,所以特此记录下,方便后期回顾。
一、背景
利用FlinkCDC3.0动态监听数据库Schema变更的能力开发了一个生产数据库DDL语句变更审计告警的服务,这两天突然发现服务一直报错,经过4个小时的排查,找到了告警原因和为什么会导致服务异常。
二、报错原因
通过观察下面这张图的堆栈信息,能够发现 FlinkCDC 在底层运用的是debezium中的io.debezium.relational.TableIdParser类,而该类抛出了参数不合法异常,具体表现为 “Unexpected input: d” 这一提示信息。
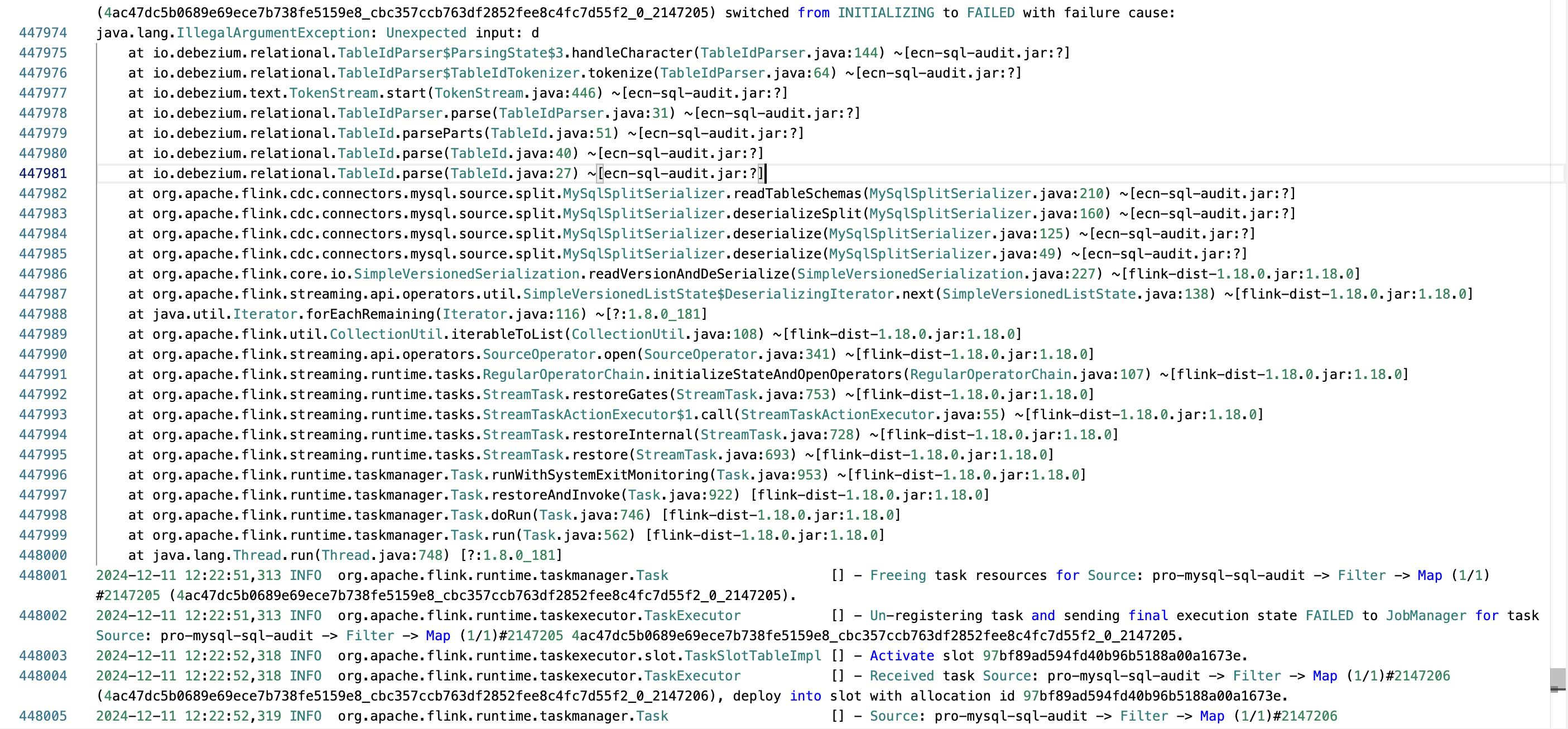
先说结论:这个错的原因就是数据库中的表名出现了空格导致的。
三、报错根因
从源码角度去分析。
第一步:
在任务初始化阶段,会通过Debezium的io.debezium.relational.TableId.parse(String str, boolean useCatalogBeforeSchema)静态方法调用io.debezium.relational.TableId.parseParts(str)方法对数据库内所有表名包含的字符进行校验工作。前文所提到的报错情况,实际上就是在这一校验步骤中出现的。如下图:
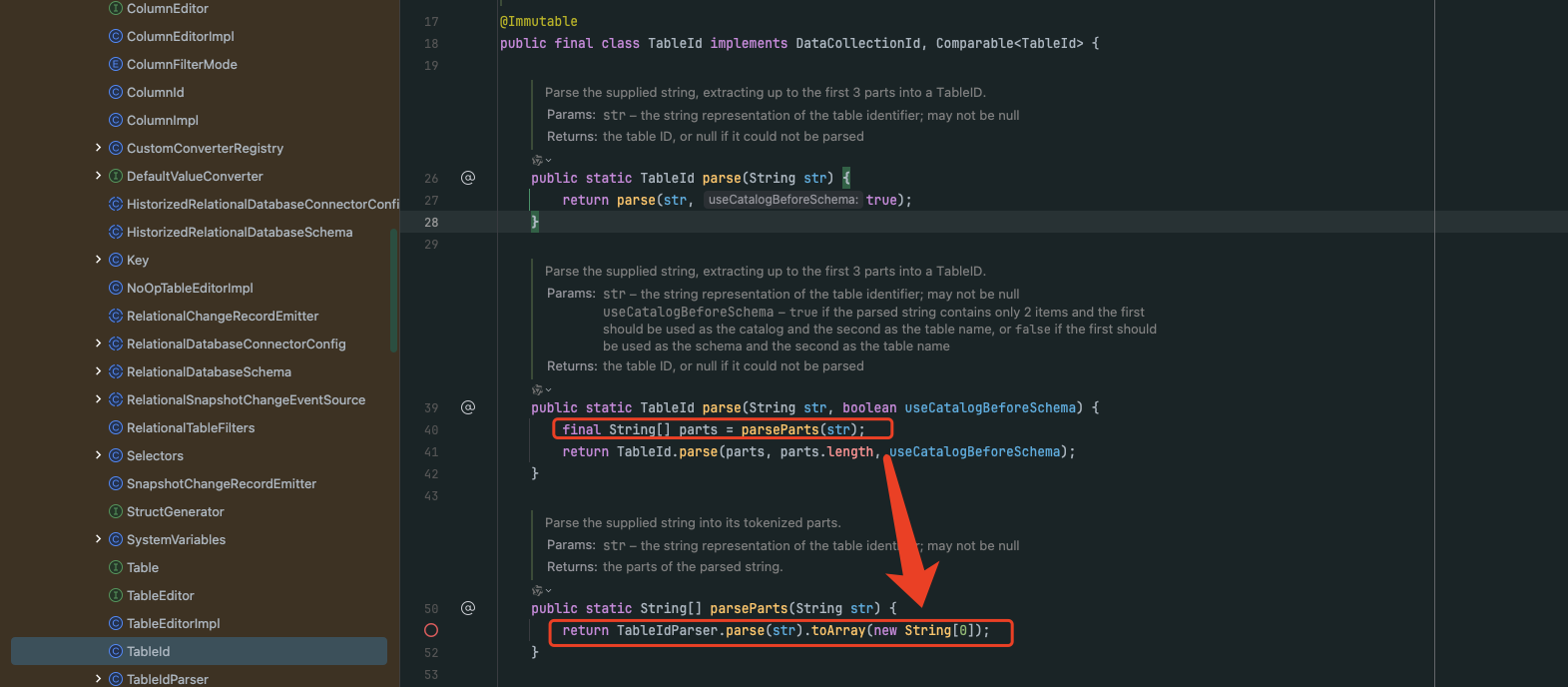
第二步:
io.debezium.relational.TableIdParser类主要用于解析库表信息。在数据库环境中,我们都知道表名通常具有一定的结构,可能包含数据库名、模式(schema)名和表的实际名称等多个部分。这个类能够将一个完整的表标识符(如包含数据库、模式和表名的字符串)分解为这些组成部分。
例如,在一个复杂的数据库系统中,表的完整标识符可能是 “mydatabase.myschema.mytable” 的形式。io.debezium.relational.TableIdParser类可以将这个字符串解析为 “mydatabase”(数据库名)、“myschema”(模式名)和 “mytable”(表名)这几个单独的部分,以便在后续的操作中(如数据同步、变更追踪等)能够准确地识别和处理这些不同层次的信息。
在io.debezium.relational.TableIdParser.parse(String identifier)方法接收到需要解析的表名字符串(也就是identifier参数所传入的内容)后,其重点调用了io.debezium.relational.TokenStream.start()方法,该方法是整个表名解析流程的起始触发点。
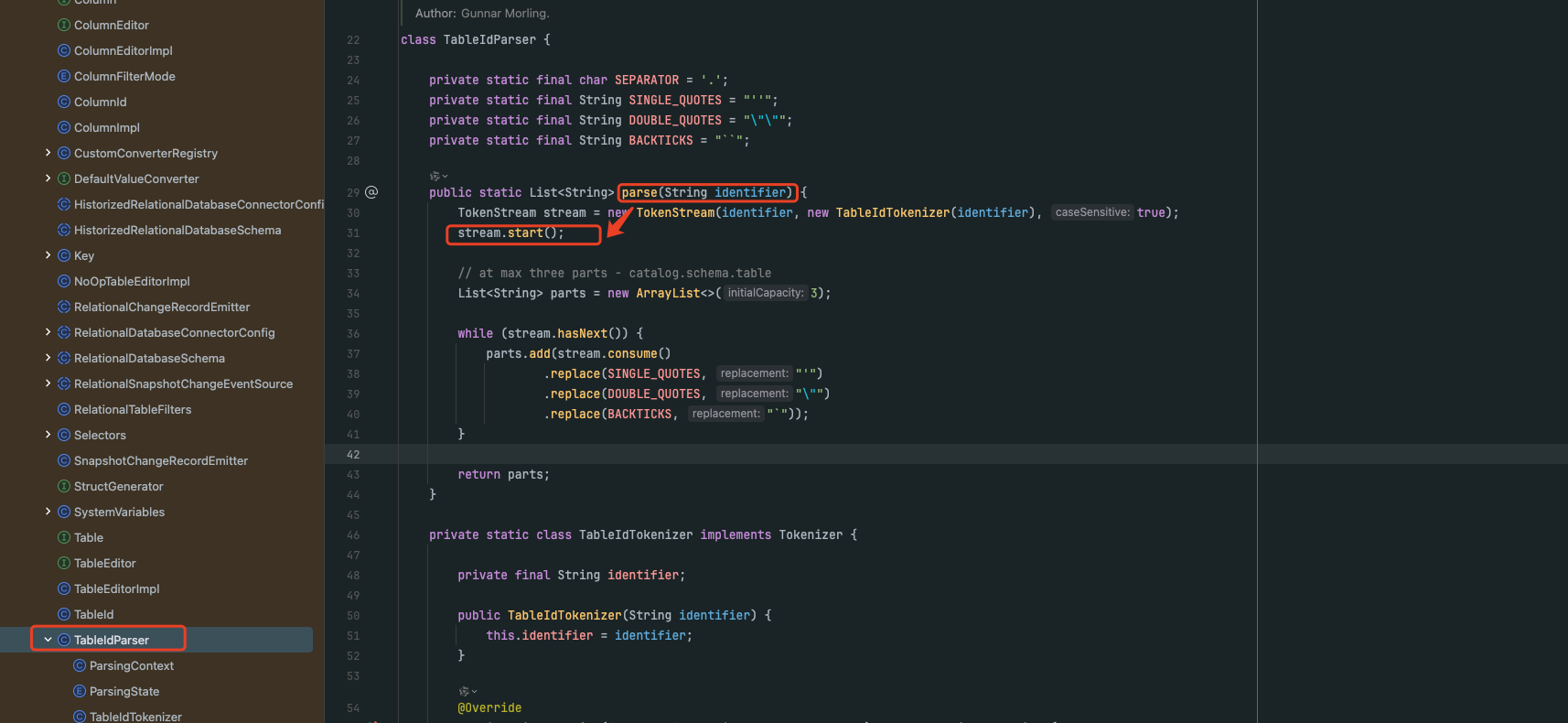
第三步:
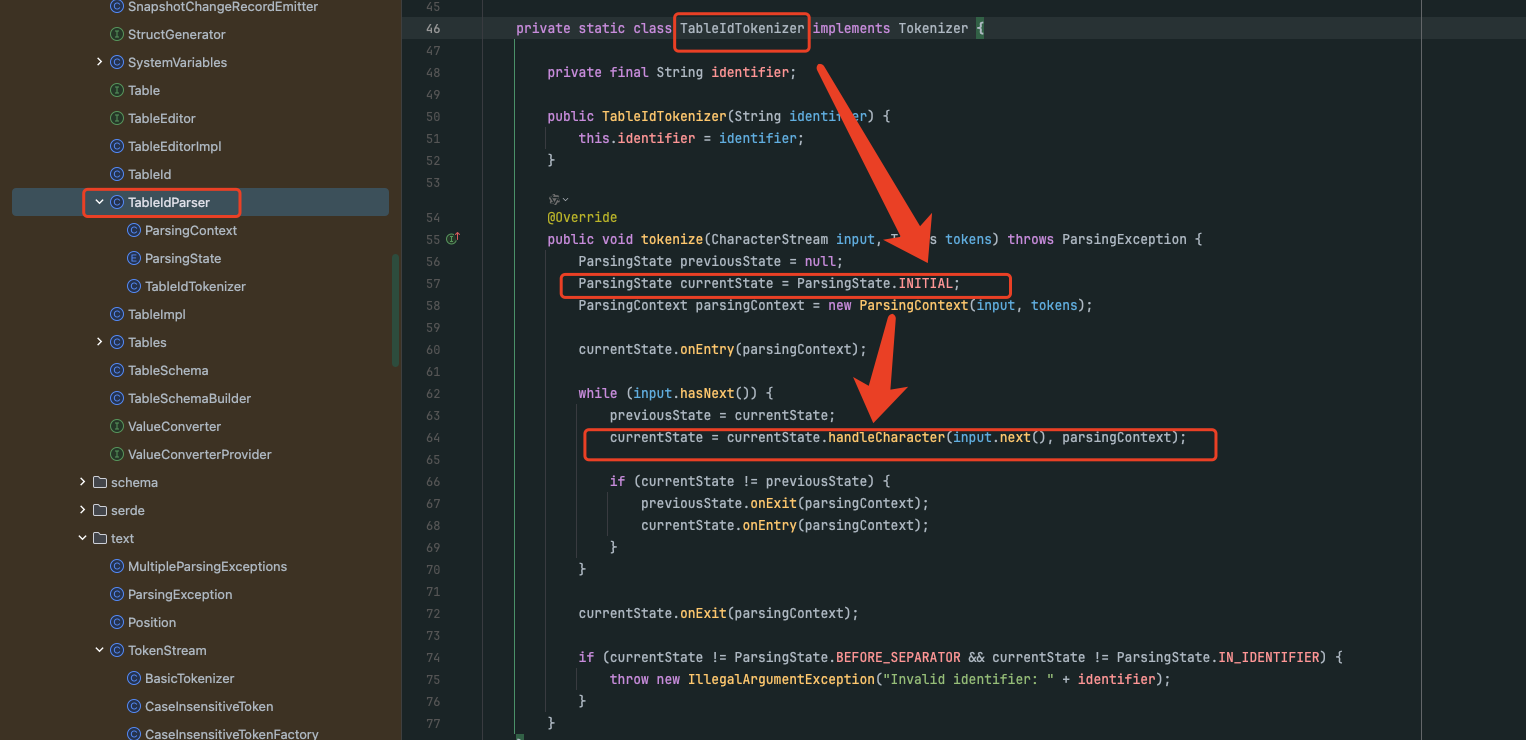
在创建io.debezium.relational.TokenStream对象时,会把接收到的表名转换为字符数组,然后调用tokenizer.tokenize(characterStream, tokenFactory)接口针对字符数组里的每一个字符展开校验工作。这个接口具体有着三种不同的实现方式,重点关注io.debezium.relational.TableIdTokenizer实现即可。
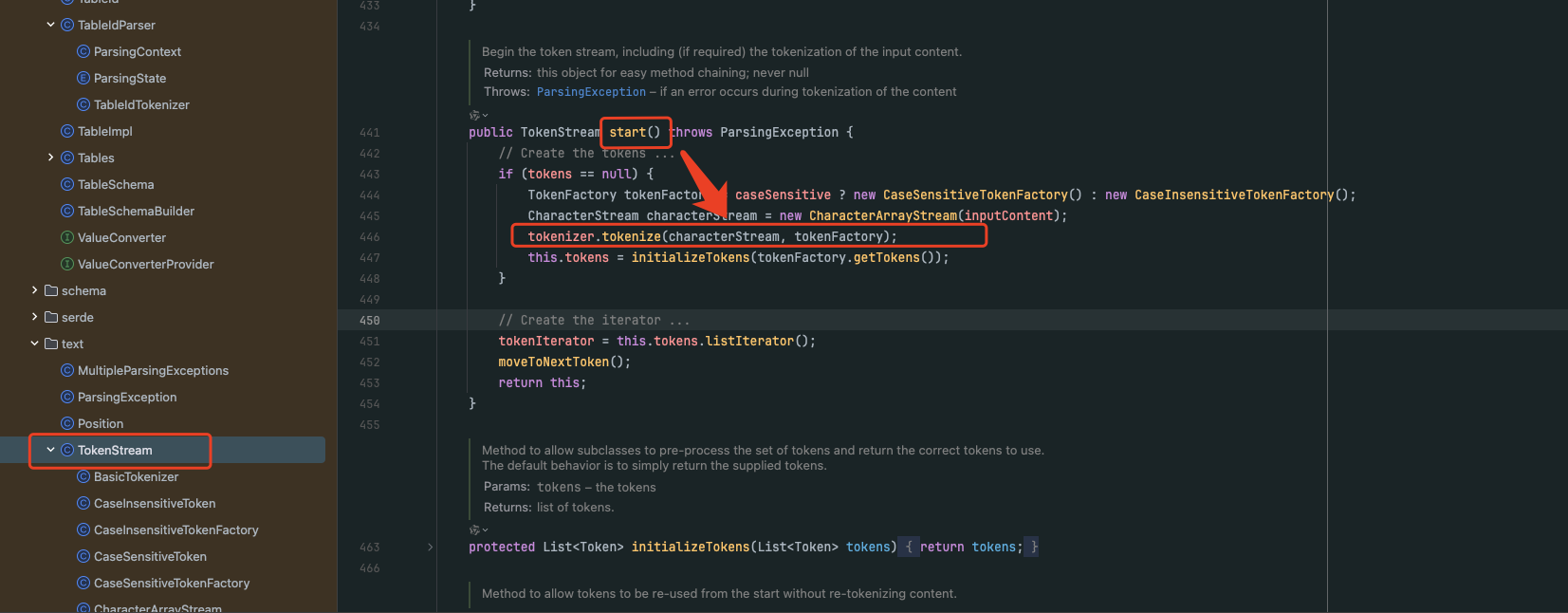
第四步:
Debezium通过一个枚举定义了INITIAL,IN_IDENTIFIER,BEFORE_SEPARATOR,AFTER_SEPARATOR,IN_QUOTED_IDENTIFIER5种表名解析时的状态。在TableIdTokenizer类的tokenize()方法中,默认将解析状态ParsingState设定为INITIAL,然后在一个while循环中,调用currentState.handleCharacter(input.next(), parsingContext)方法,来针对每一个字符展开校验工作。
当针对某一个字符的校验工作完成之后,会对ParsingState进行更新,进行下一次校验。
以下为5种枚举值的定义逻辑:
INITIAL {@OverrideParsingState handleCharacter(char c, ParsingContext context) {if (Character.isWhitespace(c)) {return INITIAL;}else if (c