【并行分布计算】Hadoop伪分布搭建
Hadoop伪分布搭建
1. 修改core-site.xml
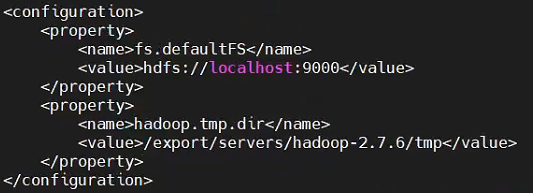
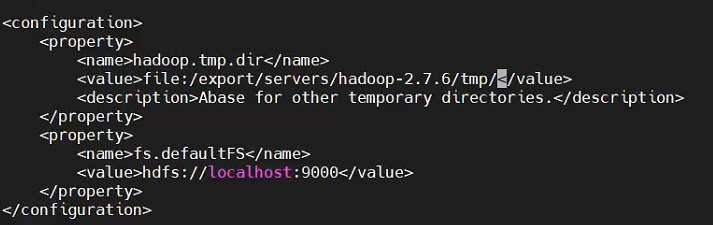
fs.defaultFS设置的是HDFS的地址,设置运行在本地的9000端口上
hadoop.tmp.dir设置的是临时目录,如果没有设置的话默认在/tmp/hadoop-${user.name}中,系统重启后会导致数据丢失,因此修改这个临时目录的路径
创建临时目录:
[root@hadoop00 hadoop]# mkdir -p /export/servers/hadoop-2.7.6/tmp
2.修改hdfs-site.xml
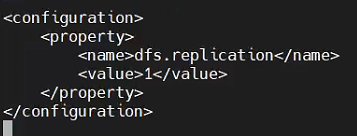
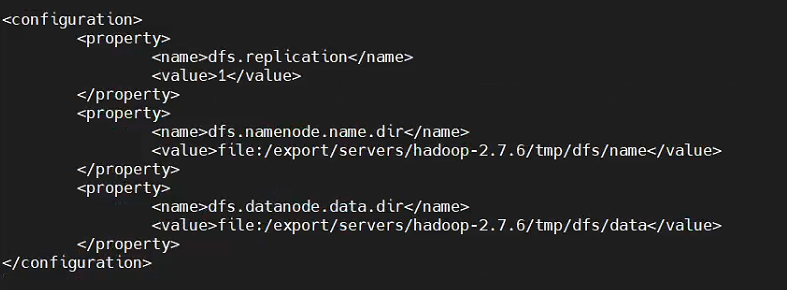
dfs.replication设置的是HDFS存储的临时备份数量,因为伪分布模式中只有一个节点,所以设置为1。
3.修改hadoop-env.sh

4. 本地无密码ssh连接
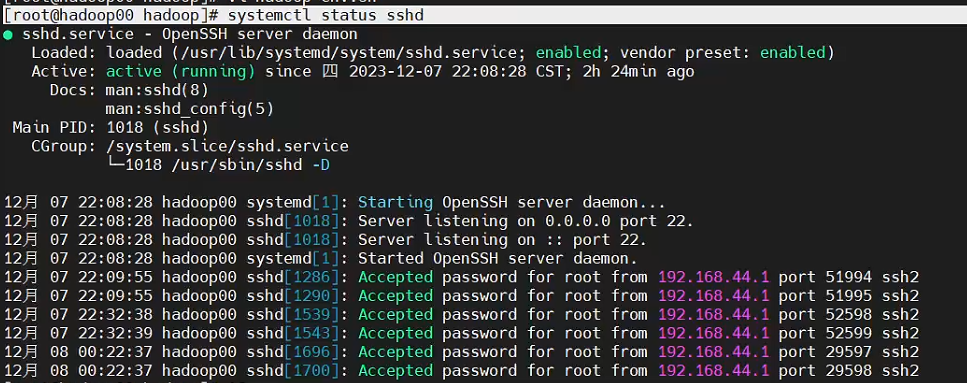
(1)查看是否开启sshd服务
[root@hadoop00 hadoop]# systemctl status sshd
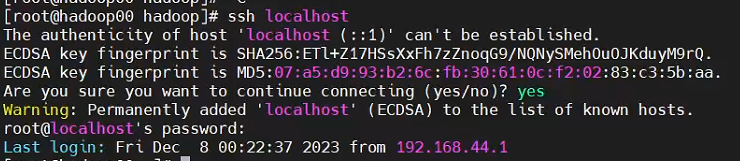
(2)localhost连接
(3)配置密钥认证连接

5.配置文件
(1)配置core-site.xml
[root@hadoop00 hadoop]# vi core-site.xml
(2)配置hdfs-site.xml
[root@hadoop00 hadoop]# vi hdfs-site.xml
对hdfs-site.xml进行同样的替换操作,属性的含义分别为复制的块的数量、DFS管理节点的本地存储路径、DFS数据节点的本地存储路径
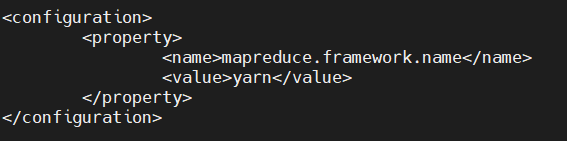
(3)配置mapred-site.xml
[root@hadoop00 hadoop]# vi mapred-site.xml
yarn 是一种资源管理和作业调度技术,作为Hadoop 的核心组件之一,负责将系统资源分配给在 Hadoop 集群中运行的各种应用程序,并调度要在不同集群节点上执行的任务,其基本思想是将资源管理和作业调度/监视的功能分解为单独的 daemon,总体上yarn是 master/slave 结构,在整个资源管理框架中,ResourceManager 为 master,NodeManager 是 slaver。
(4)配置yarn-site.xml
[root@hadoop00 hadoop]# vi yarn-site.xml
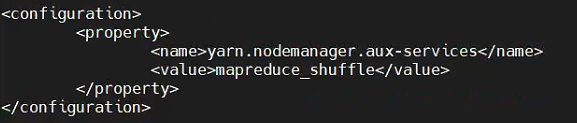
配置yarn-site.xml文件,这里修改NodeManager上运行的附属服务即可:
6. 格式化后启动、调用实例、停止所有运行的hadoop进程
(1)格式化并启动
[root@hadoop00 hadoop-2.7.6]# bin/hdfs namenode -format

(2)启动全部进程
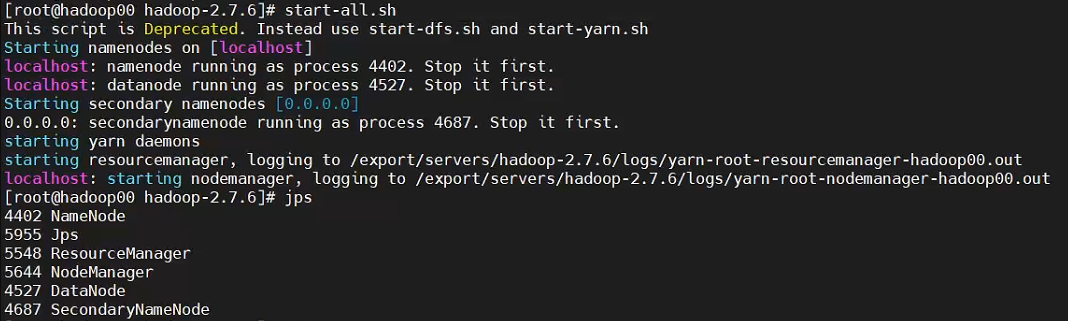
[root@hadoop00 hadoop-2.7.6]# start-all.sh
7.测试
(1)生成输入目录
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/root
bin/hdfs dfs -mkdir input
bin/hdfs dfs -put etc/hadoop/*.xml input(2)测试
(2)测试
hdfs dfs -put /export/servers/hadoop-2.7.6/etc/hadoop/*.xml input
(3)获取输出
