Day09【基于jieba分词和RNN实现的简单中文分词】
基于jieba分词和RNN实现的中文分词
- 目标
- 数据准备
- 主程序
- 预测效果
目标
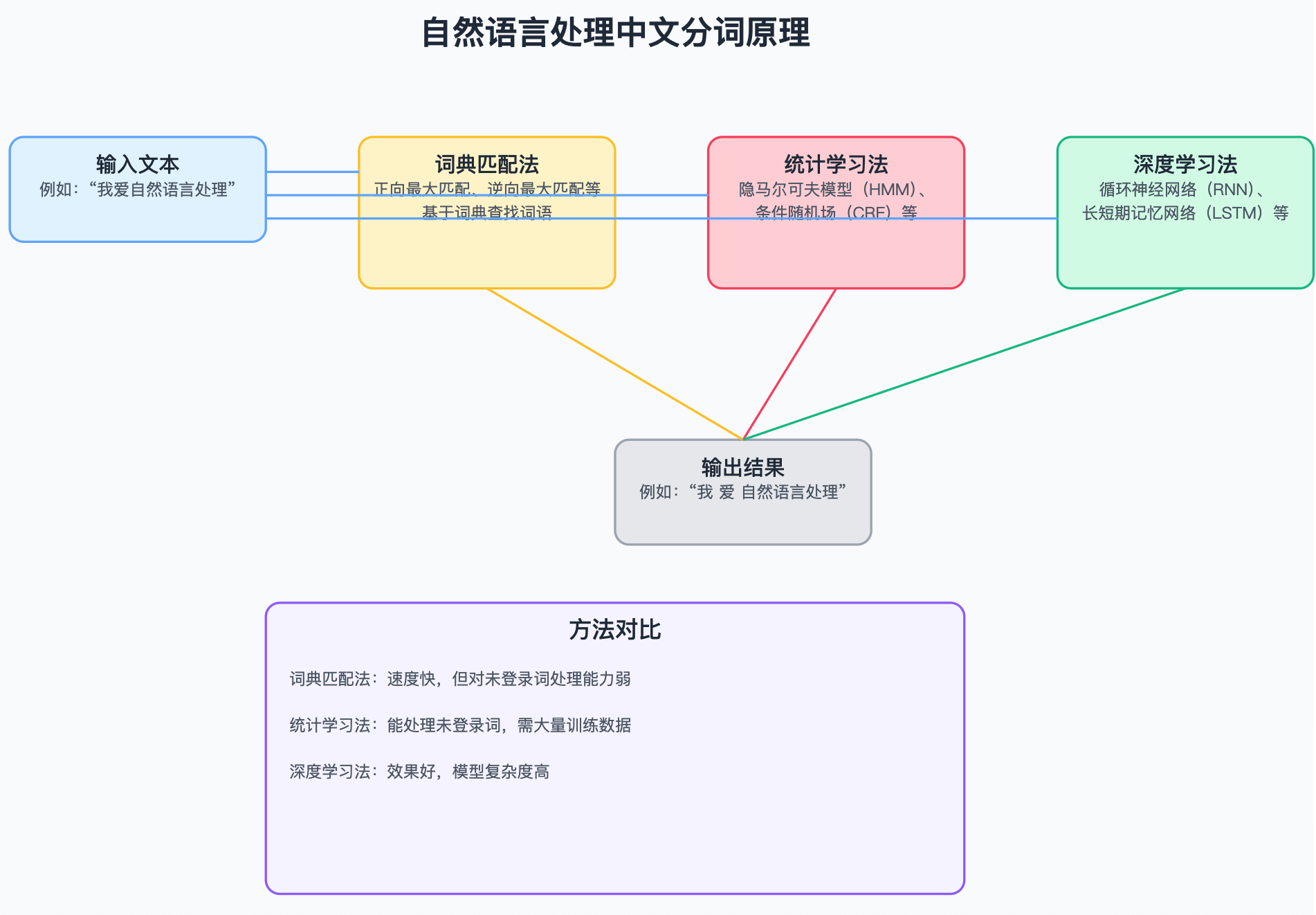
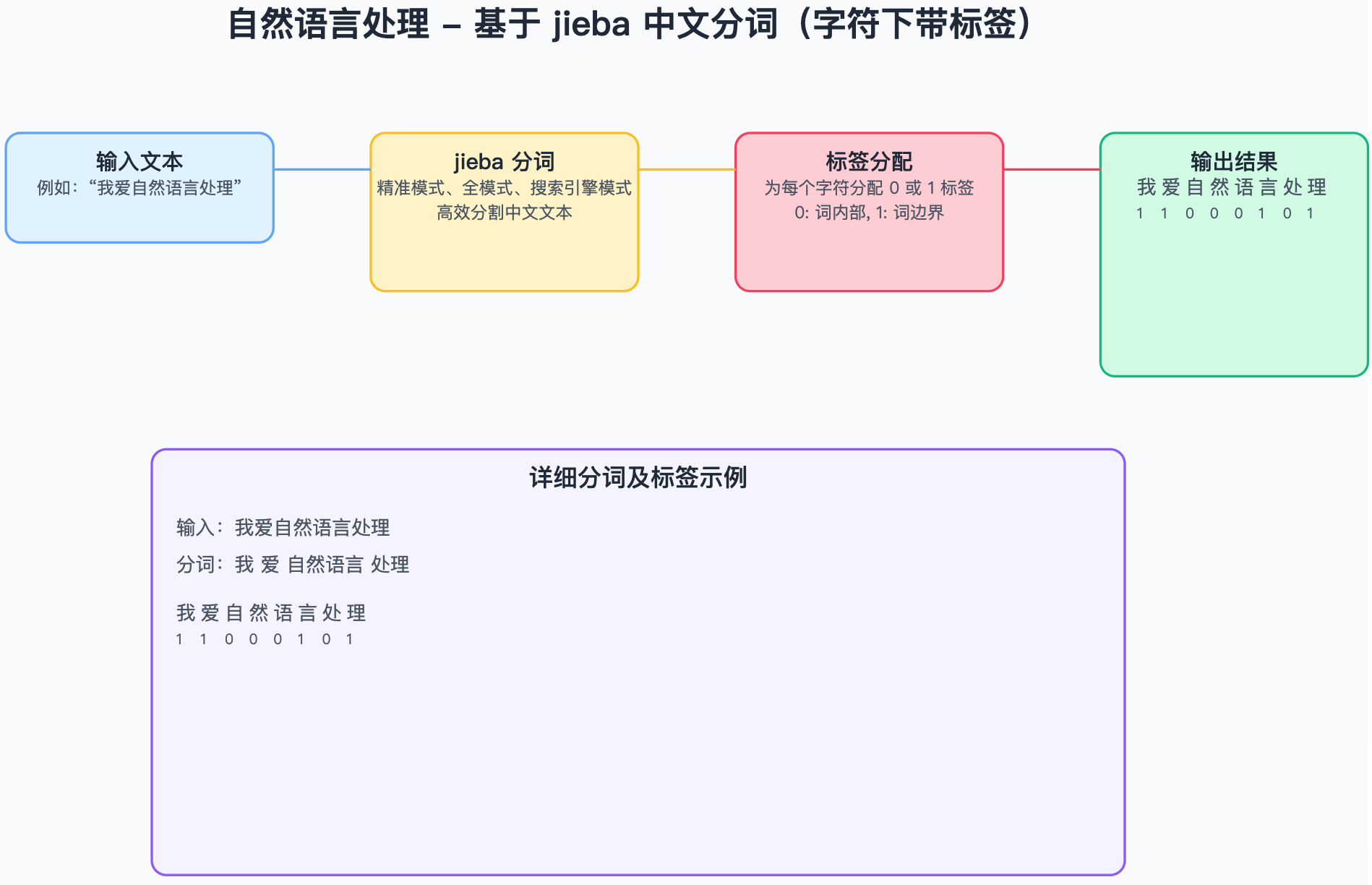
本文基于给定的中文词表,将输入的文本基于jieba分词分割为若干个词,词的末尾对应的标签为1,中间部分对应的标签为0,同时将分词后的单词基于中文词表做初步序列化,之后经过embedding和 RNN循环神经网络等网络结构层,最后输出在两类别(词内部和词边界)标签上的概率分布,从而实现一个简单中文分词任务。
数据准备
词表文件chars.txt
中文语料文件corpus.txt中文语料文件
主程序
#coding:utf8import torch
import torch.nn as nn
import jieba
import numpy as np
import random
import json
from torch.utils.data import DataLoader"""
基于pytorch的网络编写一个分词模型
我们使用jieba分词的结果作为训练数据
看看是否可以得到一个效果接近的神经网络模型
"""class TorchModel(nn.Module):def __init__(self, input_dim, hidden_size, num_rnn_layers, vocab):super(TorchModel, self).__init__()self.embedding = nn.Embedding(len(vocab) + 1, input_dim) #shape=(vocab_size, dim)self.rnn_layer = nn.RNN(input_size=input_dim,hidden_size=hidden_size,batch_first=True,bidirectional=False,num_layers=num_rnn_layers,nonlinearity="relu",dropout=0.1)self.classify = nn.Linear(hidden_size, 2)self.loss_func = nn.CrossEntropyLoss(ignore_index=-100)#当输入真实标签,返回loss值;无真实标签,返回预测值def forward(self, x, y=None):x = self.embedding(x) #output shape:(batch_size, sen_len, input_dim)x, _ = self.rnn_layer(x) #output shape:(batch_size, sen_len, hidden_size)y_pred = self.classify(x) #input shape:(batch_size, sen_len, class_num)if y is not None:#(batch_size * sen_len, class_num), (batch_size * sen_len, 1)return self.loss_func(y_pred.view(-1, 2), y.view(-1))else:return y_predclass Dataset:def __init__(self, corpus_path, vocab, max_length):self.vocab = vocabself.corpus_path = corpus_pathself.max_length = max_lengthself.load()def load(self):self.data = []with open(self.corpus_path, encoding="utf8") as f:for line in f:sequence = sentence_to_sequence(line, self.vocab)label = sequence_to_label(line)sequence, label = self.padding(sequence, label)sequence = torch.LongTensor(sequence)label = torch.LongTensor(label)self.data.append([sequence, label])if len(self.data) > 10000:breakdef padding(self, sequence, label):sequence = sequence[:self.max_length]sequence += [0] * (self.max_length - len(sequence))label = label[:self.max_length]label += [-100] * (self.max_length - len(label))return sequence, labeldef __len__(self):return len(self.data)def __getitem__(self, item):return self.data[item]#文本转化为数字序列,为embedding做准备
def sentence_to_sequence(sentence, vocab):sequence = [vocab.get(char, vocab['unk']) for char in sentence]return sequence#基于结巴生成分级结果的标注
def sequence_to_label(sentence):words = jieba.lcut(sentence)label = [0] * len(sentence)pointer = 0for word in words:pointer += len(word)label[pointer - 1] = 1return label#加载字表
def build_vocab(vocab_path):vocab = {}with open(vocab_path, "r", encoding="utf8") as f:for index, line in enumerate(f):char = line.strip()vocab[char] = index + 1 #每个字对应一个序号vocab['unk'] = len(vocab) + 1return vocab#建立数据集
def build_dataset(corpus_path, vocab, max_length, batch_size):dataset = Dataset(corpus_path, vocab, max_length) #diy __len__ __getitem__data_loader = DataLoader(dataset, shuffle=True, batch_size=batch_size) #torchreturn data_loaderdef main():epoch_num = 10 #训练轮数batch_size = 20 #每次训练样本个数char_dim = 50 #每个字的维度hidden_size = 100 #隐含层维度num_rnn_layers = 3 #rnn层数max_length = 20 #样本最大长度learning_rate = 1e-3 #学习率vocab_path = "chars.txt" #字表文件路径corpus_path = "corpus.txt" #语料文件路径vocab = build_vocab(vocab_path) #建立字表data_loader = build_dataset(corpus_path, vocab, max_length, batch_size) #建立数据集model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型optim = torch.optim.Adam(model.parameters(), lr=learning_rate) #建立优化器#训练开始for epoch in range(epoch_num):model.train()watch_loss = []for x, y in data_loader:optim.zero_grad() #梯度归零loss = model(x, y) #计算lossloss.backward() #计算梯度optim.step() #更新权重watch_loss.append(loss.item())print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))#保存模型torch.save(model.state_dict(), "model.pth")#保存词表writer = open("vocab.json", "w", encoding="utf8")writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))writer.close()return#最终预测
def predict(model_path, vocab_path, input_strings):#配置保持和训练时一致char_dim = 50 # 每个字的维度hidden_size = 100 # 隐含层维度num_rnn_layers = 3 # rnn层数vocab = build_vocab(vocab_path) #建立字表model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型model.load_state_dict(torch.load(model_path)) #加载训练好的模型权重model.eval()for input_string in input_strings:#逐条预测x = sentence_to_sequence(input_string, vocab)# print(x)with torch.no_grad():result = model.forward(torch.LongTensor([x]))[0]result = torch.argmax(result, dim=-1) #预测出的01序列print(result)#在预测为1的地方切分,将切分后文本打印出来for index, p in enumerate(result):if p == 1:print(input_string[index], end=" ")else:print(input_string[index], end="")print()if __name__ == "__main__":print(torch.backends.mps.is_available())main()input_strings = ["同时国内有望出台新汽车刺激方案","沪胶后市有望延续强势","经过两个交易日的强势调整后","昨日上海天然橡胶期货价格再度大幅上扬"]predict("model.pth", "chars.txt", input_strings)主要实现了一个基于jieba分词的中文分词模型,模型采用 RNN(循环神经网络)来处理中文文本,通过对句子进行分词,预测每个字是否为词的结尾。具体内容如下:
-
模型结构(
TorchModel):- 使用
nn.Embedding层将每个字符映射到一个高维空间。 - 通过
nn.RNN层处理字符序列,提取上下文信息,使用单向RNN(bidirectional=False)。 - 最后通过
nn.Linear层将 RNN 输出转化为每个字符的分类结果,分类为0(非词结尾)或1(词结尾)。 - 损失函数为
CrossEntropyLoss,计算预测与真实标签的差异。
- 使用
-
数据处理(
Dataset):- 使用
jieba分词工具将文本切分为词,并为每个字符标注一个标签。标签为1表示该字符是词的结尾,0表示不是词结尾。 - 将文本转换为数字序列,并根据最大句子长度进行填充,使得输入数据的形状一致。
- 使用
-
训练过程:
- 数据通过
DataLoader按批加载,使用Adam优化器进行训练。 - 在每一轮训练中,计算损失并通过反向传播优化模型权重,训练 10 轮。
- 数据通过
-
预测功能(
predict):- 加载训练好的模型,使用
torch.no_grad()禁用梯度计算,提高推理速度。 - 对每个输入字符串进行分词预测,输出每个字是否为词的结尾。若为词结尾,则切分该词并打印。
- 加载训练好的模型,使用
-
核心流程:
sentence_to_sequence将文本转换为字符序列,sequence_to_label生成对应的标签序列。- 训练完成后,保存模型和词表,以便后续加载和预测。
代码实现了一个简单的中文分词模型,通过标注每个字符是否为词的结尾,结合 RNN 提取上下文信息,从而实现文本分词功能。
预测效果
输入语句:
“同时国内有望出台新汽车刺激方案”,
“沪胶后市有望延续强势”,
“经过两个交易日的强势调整后”,
“昨日上海天然橡胶期货价格再度大幅上扬”
中文分词后结果:
tensor([0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1])
同时 国内 有 望 出台 新 汽车 刺激 方案
tensor([1, 1, 0, 1, 1, 1, 0, 1, 0, 1])
沪 胶 后市 有 望 延续 强势
tensor([0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1])
经过 两个 交易 日 的 强势 调整 后
tensor([0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1])
昨日 上海 天然 橡胶 期货 价格 再度 大幅 上扬