复旦大学、百度联合开源数字人项目hallo2,支持高分辨率(可达4K)、长视频生成(最多1小时)
项目背景与概述
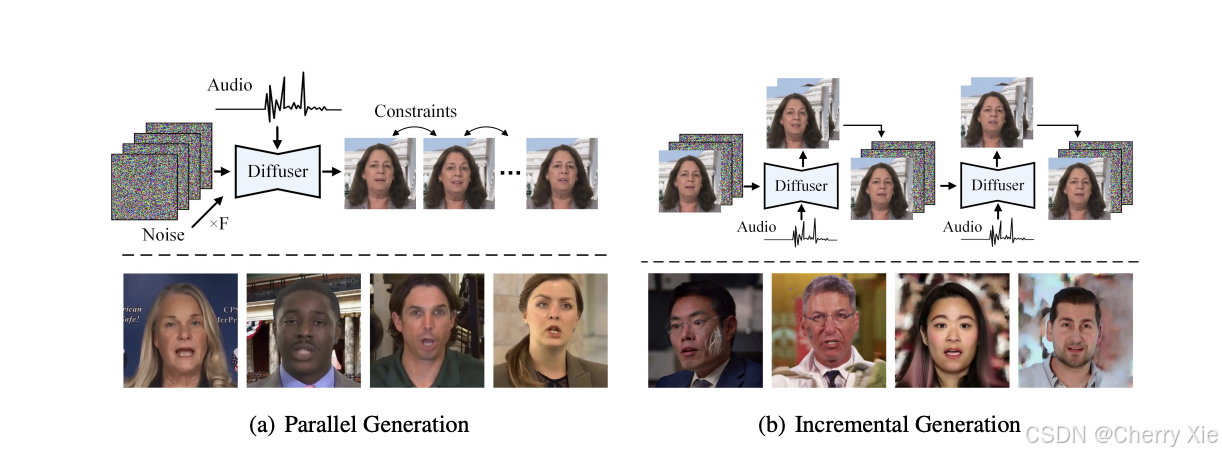
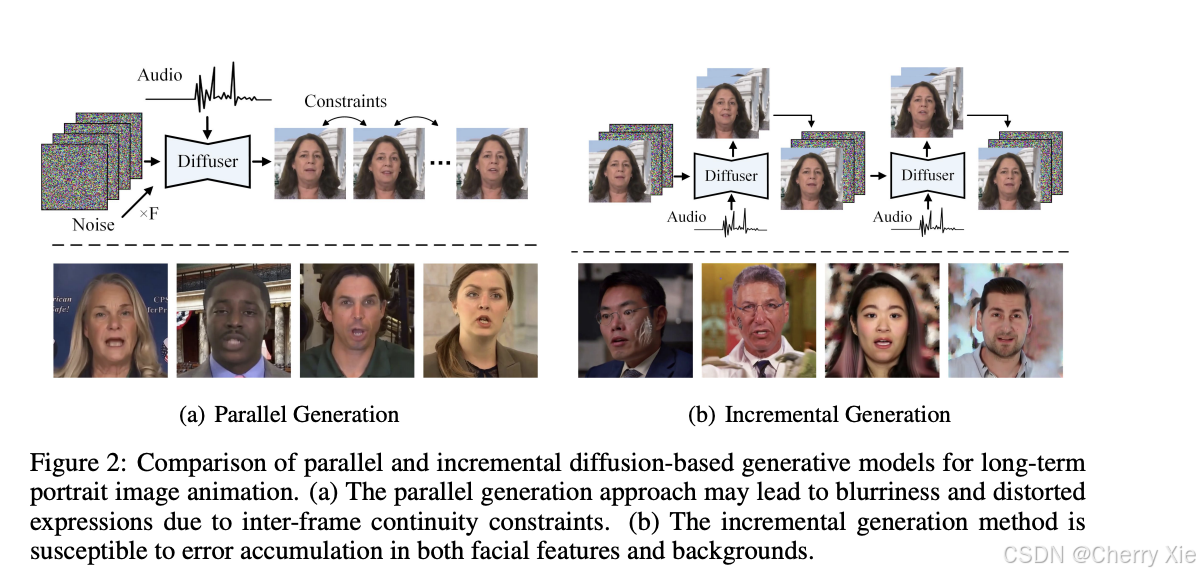
hallo2是一个由复旦大学、百度公司和南京大学的研究团队共同开发的开源项目,专注于音频驱动的肖像图像动画生成技术。该项目于2024年10月首次在ArXiv上发布论文,并于2025年1月被国际机器学习会议ICLR 2025接收,标志着其在学术界的重要地位。hallo2旨在突破现有方法在时长和分辨率上的限制,为娱乐、教育和虚拟现实等领域提供创新解决方案。
目的与应用场景
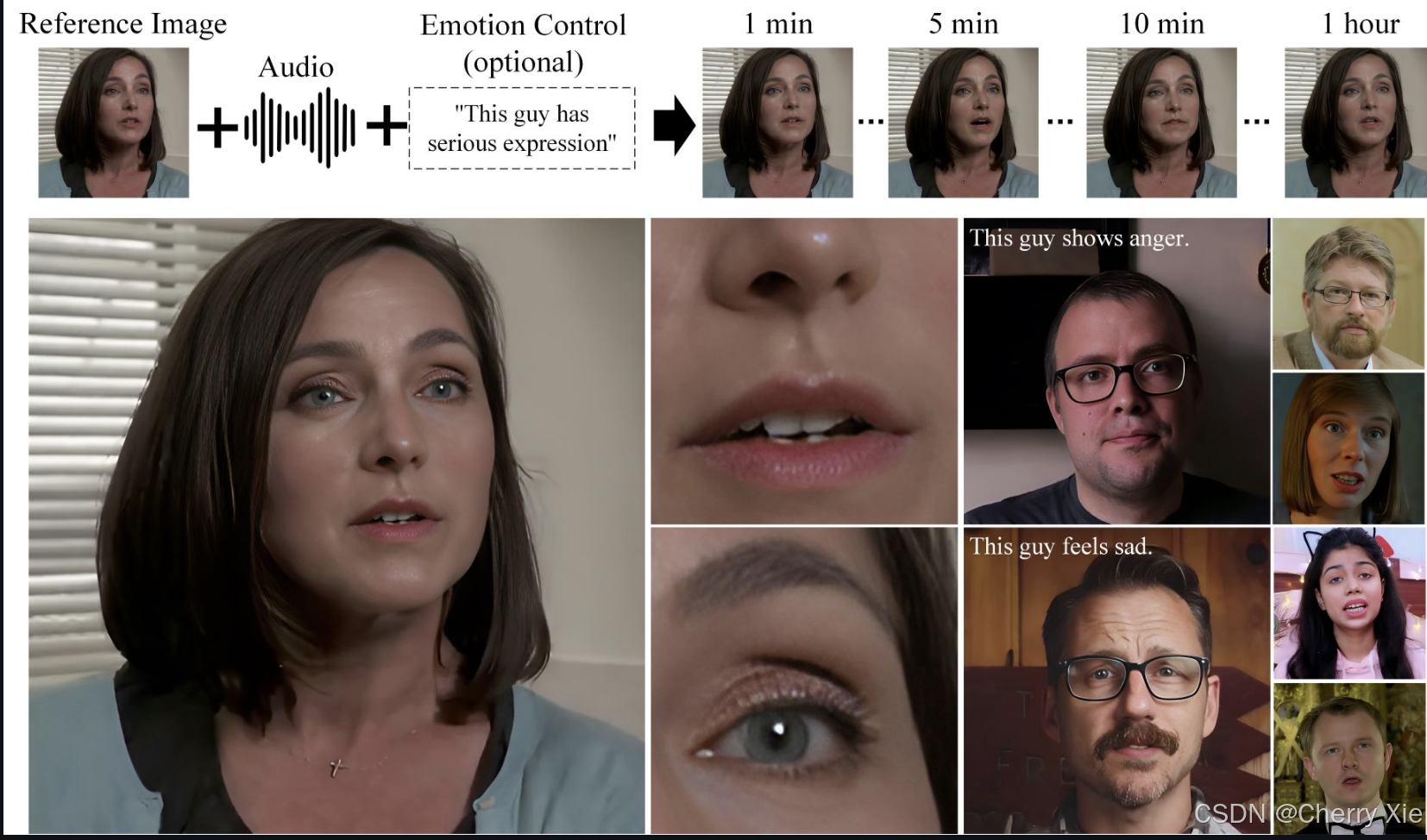
hallo2的核心目标是实现**长时长(最高1小时)、高分辨率(4K)的肖像动画生成,这些动画能够与输入音频同步,确保唇部动作和面部表情与声音完美匹配。这种技术突破了现有方法在时长和分辨率上的限制,为多个领域提供了广泛的应用前景。
-
娱乐:可用于创建逼真的数字头像,增强虚拟角色互动。
-
教育:生成交互式讲师动画,提升学习体验,例如斯坦福大学的1小时LLM课程。
-
虚拟现实:实现更具沉浸感的数字互动,例如历史人物演讲视频,如丘吉尔的“铁幕演讲”(4分钟)或泰勒·斯威夫特的演讲(23分钟)。
此外,hallo2支持通过文本提示(如情绪或风格描述)增强生成内容的多样性和可控性,允许用户定制动画的表达方式,例如指定情感或艺术风格。
技术细节与实现
音频处理
-
输入音频通过 wav2vec2-base-960h 模型提取特征,存储在 pretrained_models/wav2vec/wav2vec2-base-960h/ 目录下。
-
使用 MDX-Net 的 KimVocal_2 模型(pretrained_models/audio_separator/)分离人声和背景音乐,确保音频输入的清晰度。
面部分析
-
使用 InsightFace 和 MediaPipe 的模型进行面部检测和关键点提取。这些模型存储在 pretrained_models/face_analysis/models/,包括 face_landmarker_v2_with_blendshapes.task 和 1k3d68.onnx 等。
-
面部分析模块负责检测面部位置、提取 2D/3D 关键点,为后续动画生成提供基础。
运动生成
-
借助 AnimateDiff 的运动模块(pretrained_models/motion_module/mm_sd_v15_v2.ckpt),生成面部和头部的动态效果。
-
该模块支持长时长动画的连续性,确保 1 小时视频的流畅性。
图像合成
-
使用 Stable Diffusion V1.5 和 sd-vae-ft-mse 模型生成高质量图像,存储在 pretrained_models/stable-diffusion-v1-5/ 和 pretrained_models/sd-vae-ft-mse/。
-
去噪 UNet(pretrained_models/hallo2/net_g.pth)和面部定位器(pretrained_models/hallo2/net.pth)进一步优化动画生成,支持文本提示(如情绪或风格描述)增强内容的可控性。
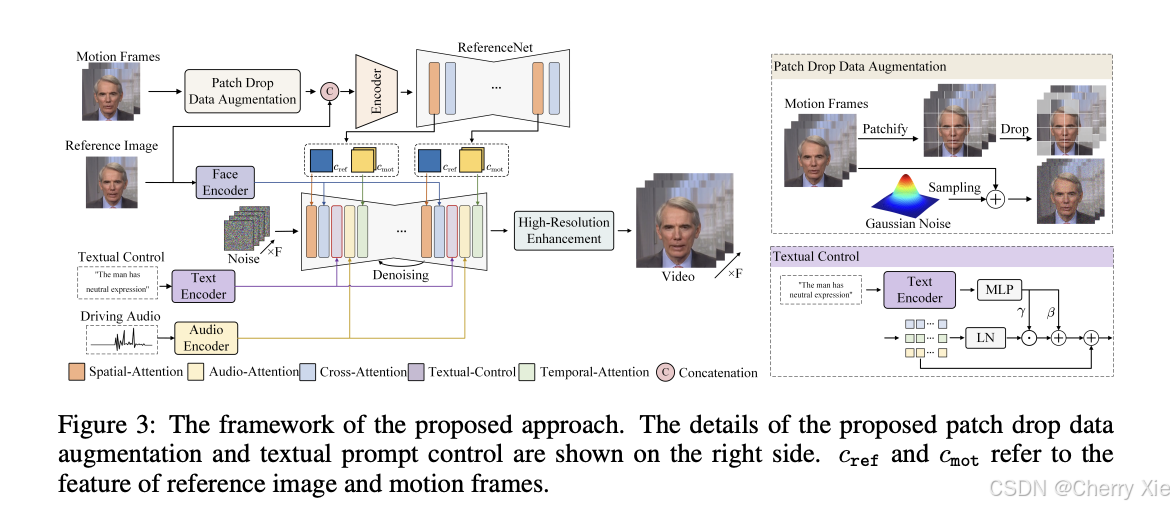
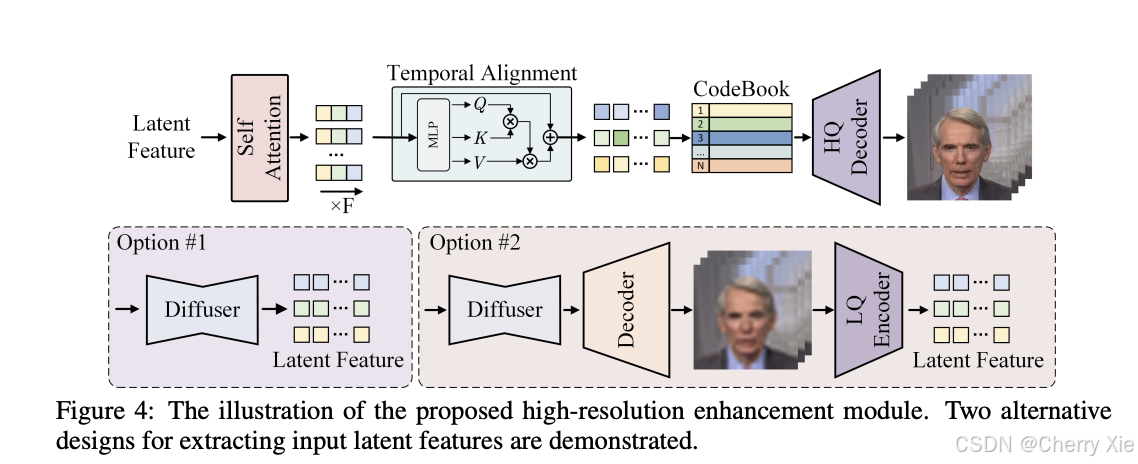
超分辨率
- 通过 CodeFormer(pretrained_models/CodeFormer/codeformer.pth)和 RealESRGAN(pretrained_models/realesrgan/RealESRGAN_x2plus.pth)提升视频分辨率,支持 4K 输出。
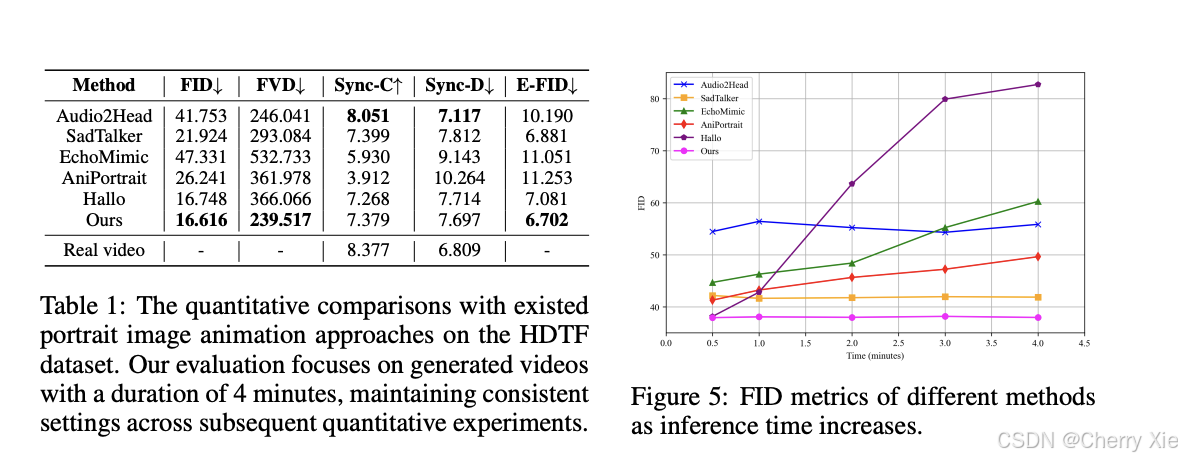
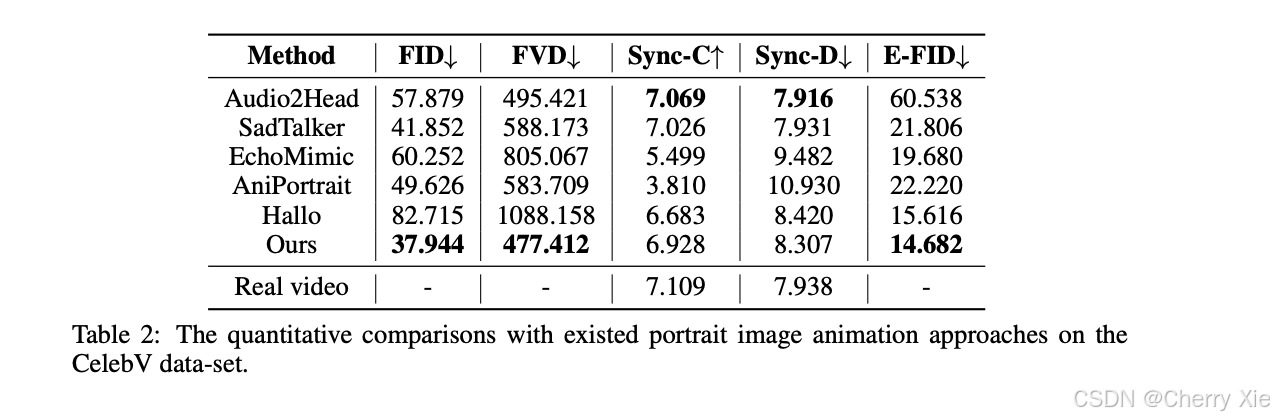
性能对比
详情见技术报告,此处仅仅选择性展示一些内容:
看看效果
相关文献
技术报告:https://arxiv.org/pdf/2410.07718
官方地址:https://fudan-generative-vision.github.io/hallo2/#/
github地址:https://github.com/fudan-generative-vision/hallo2
相关模型下载:https://huggingface.co/fudan-generative-ai/hallo2