【T2I】MIGC++: Advanced Multi-Instance GenerationController for Image Synthesis
CODE: TPAMI 2024
https://github.com/limuloo/MIGC
Abstract
我们介绍了多实例生成(Multi-Instance Generation, MIG)任务,其重点是在单个图像中生成多个实例,每个实例都精确地放置在预定义的位置,具有类别、颜色和形状等属性,严格遵循用户规范。MIG面临三个主要挑战:避免实例之间的属性泄漏,支持不同的实例描述,以及在迭代生成中保持一致性。为了解决属性泄漏问题,我们提出了多实例生成控制器(MIGC)。MIGC通过分而治之的策略生成多个实例,将多实例着色分解为具有单一属性的单实例任务,稍后进行集成。为了提供更多类型的实例描述,我们开发了migc++。migc++允许通过文本和图像进行属性控制,通过框和蒙版进行位置控制。最后,我们引入-ent-MIG算法来增强MIGC和migc++的迭代MIG能力。该算法在增加、删除或修改实例时保证了未修改区域的一致性,并在实例属性发生变化时保持了实例的身份。我们介绍了COCO-MIG和Multimodal-MIG基准来评估这些方法。在这些基准测试上进行的大量实验,以及COCO-Position基准测试和DrawBench,表明我们的方法实质上优于现有技术,保持了对位置、属性和数量等方面的精确控制。
INTRODUCTION
SD应用广泛,migc++通过多模态增强-注意(multi - modal enhancement - attention, MEA)机制实现了从边界框定位到更细粒度的掩码。

采用不同的加权增强注意力机制,MAE跨模态处理每个实例并行着色,将位置信息转换为统一的二维位置图,可以跨位置实现精确定位,引入无需训练的着色器。
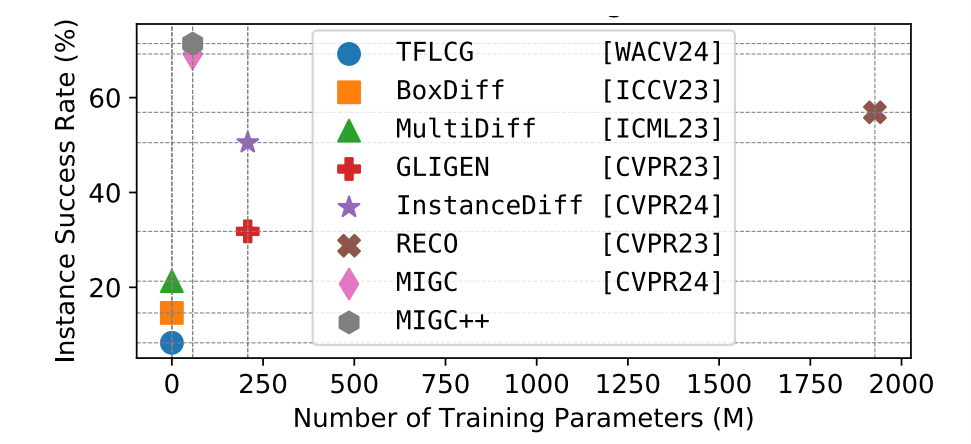
如图所示,在需要训练的方法中,MIGC和MIGC++需要的训练参数最少。
贡献:
• 我们引入了多实例生成(MIG)任务,它将单实例生成扩展到更复杂和现实的视觉生成应用中。
• 利用分而治之的策略,我们提出了新的多边投资组合方法。这个即插即用控制器显著增强了SD模型的MIG功能,提供了对生成图像中实例的位置、属性和数量的精确控制。
• 我们开发了先进的migc++方法,允许同时使用文本和图像来指定实例属性,并使用方框和掩码进行定位。据我们所知,migc++是第一个集成这些特性的方法。
• 我们引入了Consistent-MIG算法,该算法增强了MIGC和MIGC++的迭代MIG能力,确保了非修改区域的一致性和修改实例的身份。
• 建立COCO-MIG基准,研究MIG任务,制定综合评估管道。我们还启动了Multimodal-MIG基准测试,以评估同时使用文本和图像控制实例属性的模型能力。
RELATED WORK
Diffusion models
Layout-to-image 布局到图像生成技术通过整合布局信息来提高文本到图像方法的定位精度。GLIGEN[28]和InstanceDiffusion[26]通过扩展文本标记,将位置数据作为基础标记,进一步集成到图像特征中,通过额外的门通自注意力机制层,从而推进了这种方法。在此基础上,LayoutLLM-T2I[65]通过关系感知关注模块增强了GLIGEN框架,而RECO[27]则有效地将布局和文本信息结合起来,以细化生成过程中的空间控制。此外,某些模型[32],[33],[66]利用交叉注意图计算布局损失,在大规模文本-图像系统中实现了无需训练的布局控制,以分类器引导的方式指导图像生成过程。尽管有这些技术上的改进,在MIG中管理实例的属性仍然是一个挑战,经常导致图像具有混合属性。本文介绍了MIGC和migc++方法,用于在MIG中精细地控制生成实例的位置、属性和数量。
PRELIMINARY: STABLE DIFFUSION
CLIP text encoder.
Cross-Attention layers.

Unet denoising network.
Image Projector. 仅仅使用文本描述是很难描述定制概念的。ELITE[29]、IP-Adapter[68]和SSR-Encoder[30]等方法使用基于学习的投影仪将视觉概念集成到图像特征x中。给定一个参考图像e,这些方法利用CLIP图像编码器[24]将其编码为一系列图像嵌入We = CLIPimage(e)。然后,一个可训练的投影网络对这些嵌入进行细化,以提取细粒度的主题特征W ' e = Proj(We)。最后,遮阳结果Re可表示为

其中键Ke和值Ve是通过新增的线性层fK e(·)、fV e(·)投影特征W ' e而得到的,查询Qc与方程 1保持一致。
METHODOLOGY
Multi-Instance Generation Task
Definition. 多实例生成(Multi-Instance Generation, MIG)任务不仅为目标图像提供全局描述c,而且还包括每个实例i的详细描述,指定其位置posi和属性attri。生成模型必须确保每个实例符合其指定的位置posi和属性attri,并与全局图像描述c保持一致。
Problem.目前的方法在MIG中面临三个主要问题。(i)属性泄漏。(ii) 限制实例说明。(iii)有限的迭代MIG能力。
Solution. 最初引入了MIGC(§4.2)方法来解决属性泄漏问题。随后,提出了它的增强版本,migc++(§4.3),它扩展了实例描述的形式。最后,提出了Consistent-MIG(§4.4)来增强MIGC和migc++的迭代MIG功能。
MIGC
Overview

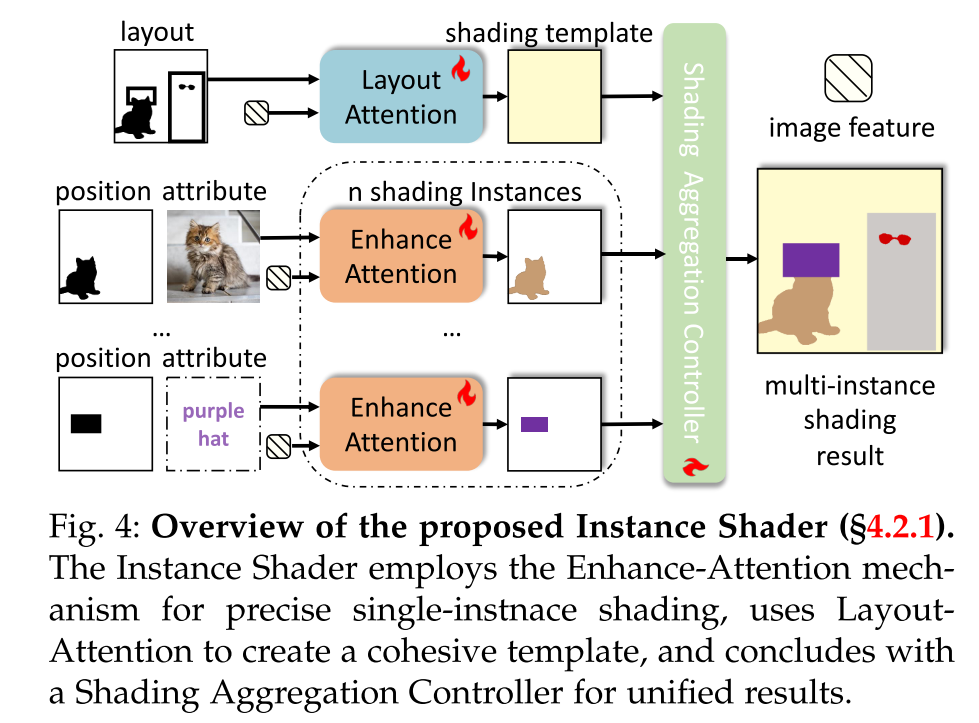
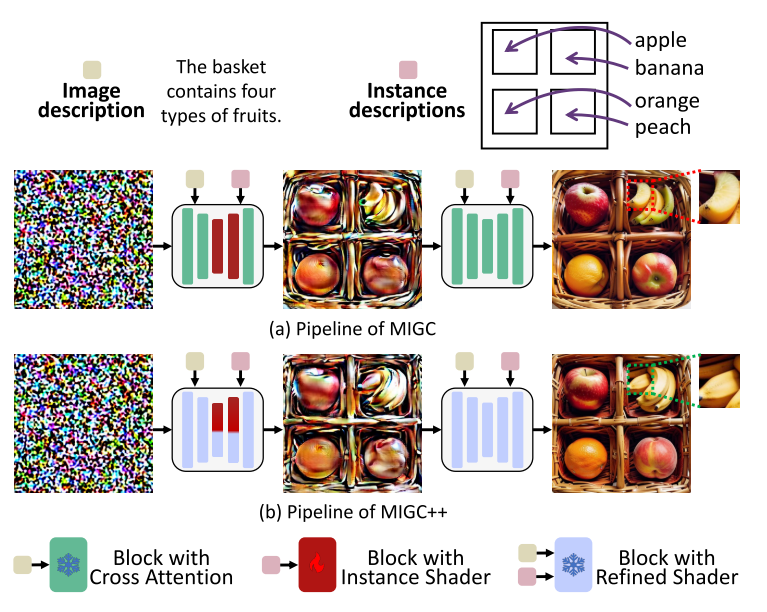
Instance Shader 实例着色器是根据上述分治法设计的,如图图所示。最初,它将多实例着色划分为多个不同的单实例着色任务。随后,增强注意机制(§4.2.2)被应用于单独解决每个任务,产生多个阴影实例。在此之后,一个布局注意机制(§4.2.3)被实现来设计一个阴影模板,方便各个实例的集成。最后,一个着色聚合控制器(§4.2.4)结合这些实例和模板来产生全面的多实例着色结果。如图所示,MIGC在U-Net架构的中间块和深层块中用实例着色器替换了CrossAttention层,以便在高噪声水平的采样步骤中对图像特征执行多实例着色,以提高多实例生成的准确性(第4.2.5节)。
Enhance Attention
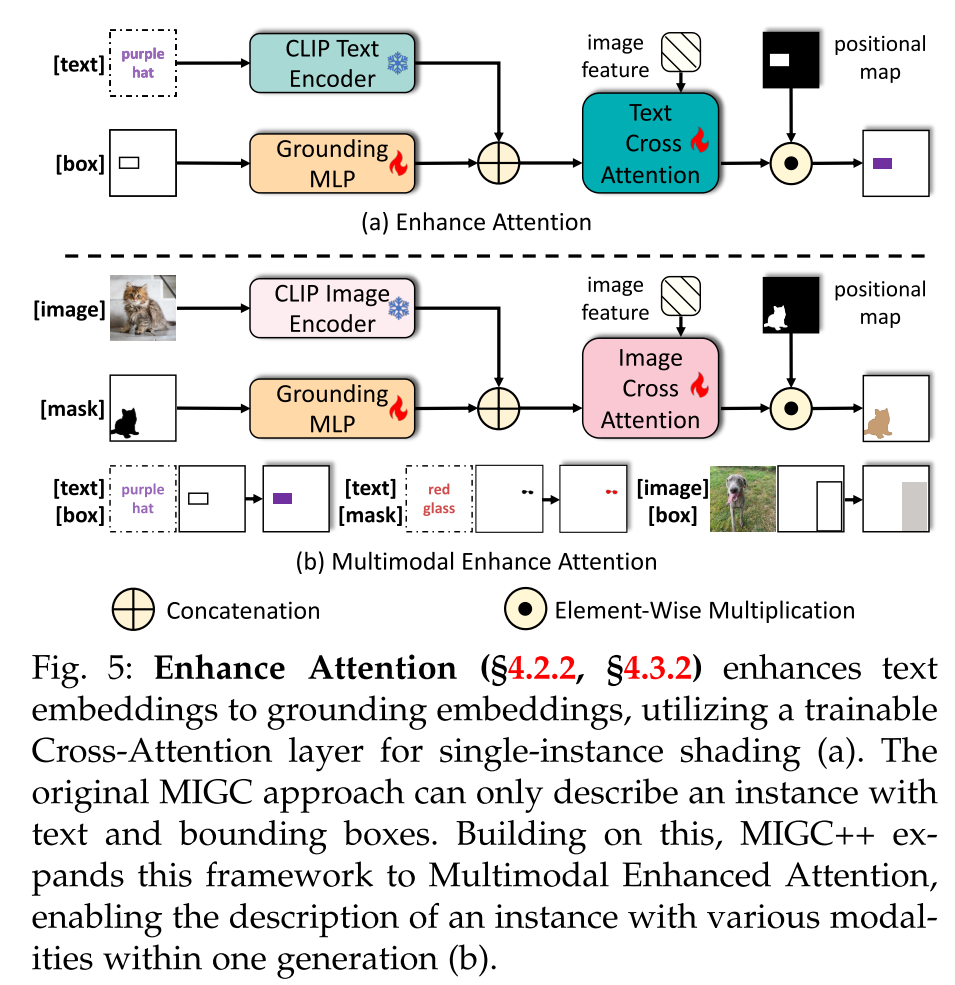
Motivation. 为了实现单实例着色,一个简单的方法可能涉及利用SD中预训练的交叉注意层。然而,这种方法遇到了两个重要的问题,即
(i)实例合并:方程 1说明,当两个实例共享相同的属性时,它们在着色期间拥有相同的键K和值V。如果这些实例位置很近或重叠,后一种组合可能会错误地将它们合并为单个实例(参见图(e))。
(ii)缺少实例:初始编辑[69]方法表明,初始噪声在很大程度上影响了SD输出中的图像布局。如果初始噪声不支持指定位置的实例,则其着色结果较弱,导致实例缺失(参见图(a))。如图图所示,为了实现精确的单实例着色,设计了Enhance Attention (EA),解决了上述两个问题。
Solution. 为了解决实例合并问题,EA在每个实例的属性嵌入中增加位置嵌入,以识别具有相同属性但不同位置的实例。如图(a)所示,对于由texti和boxi描述的实例i, EA首先使用CLIP文本编码器[24]将文本属性描述texti编码为嵌入Wi文本的文本序列。随后,EA使用接地MLP将位置描述boxi = [xi1, yi1, xi2, yi2]编码为位置嵌入Wipos,该接地MLP包含傅里叶嵌入变换和MLP层:
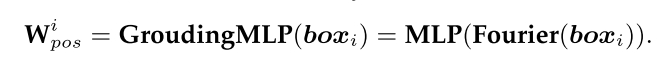
EA将属性嵌入与位置嵌入相结合,形成grounding embedding:
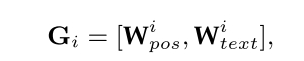 [·,·]表示连接操作
[·,·]表示连接操作
为了解决实例缺失问题,EA使用了一种新的可训练的Cross Attention进行增强着色,着色结果可表示为:
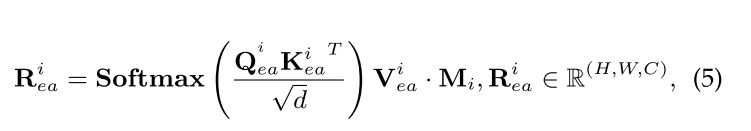
其中,一个可学习线性层fqea(·)将图像特征X投影为查询,两个可学习线性层fqea(·)、fVea(·)将接地嵌入Gi投影为键和值,可以根据盒子生成位置图Mi,盒子区域内的值设为1,其他值设为0。在训练阶段,这些位置地图有助于精确的空间定位。这种精确的定位确保了EA产生的阴影效果被精确地限制在目标区域,这使得EA能够在不同的图像特征上一致地应用阴影增强,并有效地解决了实例缺失问题。
Layout Attention

Motivation. 利用增强注意对图像特征执行单实例着色,我们产生了多个单独的实例。然而,在将它们合并到多实例的着色结果之前,一个着色模板是必不可少的桥梁,因为每个实例的着色过程是独立的。如图所示,实例着色器使用布局注意来生成着色模板,这取决于所有实例的布局。
Solution.
![]()
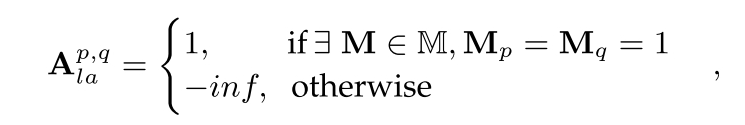
其中Apqla的值决定了图像令牌p在注意操作中是否注意到图像令牌q,布局注意可以表示为:
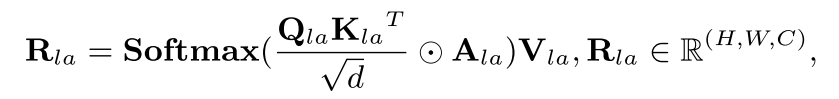
其中⊙表示Hadamard积,可学习线性层fKla(·)、fQla(·)、fVla(·)将图像特征X投影为键Kla、查询Qla和值Vla。
Shading Aggregation Controller
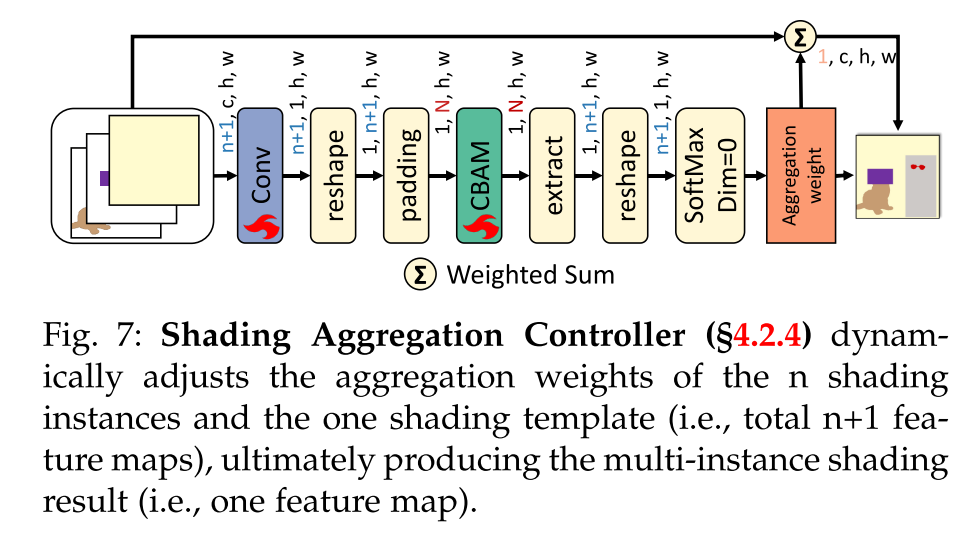
Motivation. 为了生成最终的多实例着色结果,我们将通过Enhance Attention获得的着色实例与Layout Attention的着色模板结合起来。跨块和采样步骤动态调整聚合权值至关重要。因此,我们提出了一个阴影聚合控制器(SAC)来管理这个过程。
Solution. 图给出了SAC框架。我们首先连接n个着色实例R1,···,Rn和一个着色模板Rla作为输入。SAC使用1x1卷积层从每个实例中提取初始空间特征。然后,它重新排列特征维度,并应用卷积块注意模块(CBAM)进行实例智能注意。聚合权重,每个空间像素归一化,确定每个实例的阴影强度,导致最终结果。为了适应可变数量的阴影实例,我们为CBAM设置了一个预定义的通道计数N,这比典型的实例数量要高。在推理过程中,特征对该通道计数进行零填充,以确保CBAM处理的一致性。这种方法可以动态适应实际的着色实例数量,SAC可以促进多实例着色结果:
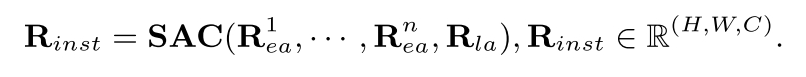
Deployment of MIGC
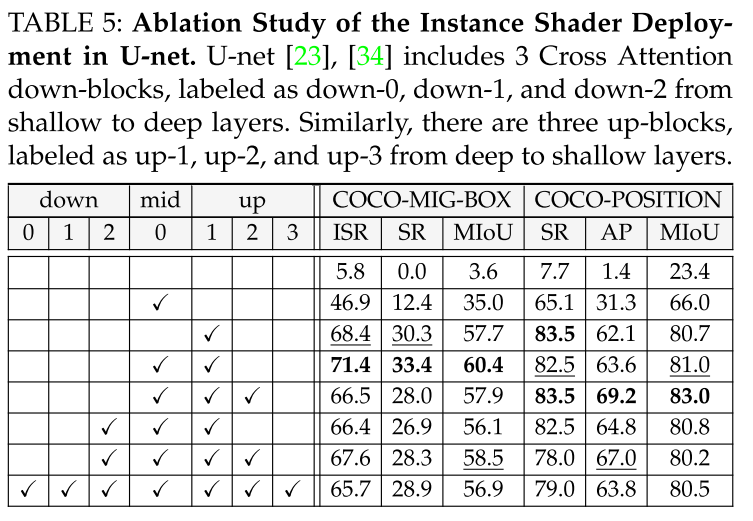
用建议的实例着色器(§4.2.1)取代U-net中原始的交叉注意层,MIGC部署在中间块和深度上块,用于高噪声级采样步骤。剩余的Cross-Attention层根据图像描述执行全局着色,如图图(a)所示。这种部署提供了关键优势:1)由于参数较少,训练成本降低,训练速度更快。2)通过将阴影聚焦在关键图像特征上提高性能,提高语义完整性。MIGC部署策略的有效性也通过消融研究得到验证(见表5)。
MIGC++
Overview

Multimodal Enhance Attention
For various position descriptions, 包括边界框和掩码,MEA首先生成相应的2D位置图Mi,其中实例区域内的像素被指定为1,而所有其他像素都被设置为0。此2D位置图用于对阴影区域进行精确控制,确保有针对性和准确的增强,如方程 5所示。然后,为了推导位置嵌入,MEA将所有位置格式标准化为边界框格式,并利用方程 3中描述的GroundingMLP来获得位置嵌入。
For various attribute descriptions, 包括文本和图像,MEA利用单独的交叉注意机制来优化阴影。如图(a)和图5(b)所示,MEA不是对两种模式使用单一层,而是对每种模式应用量身定制的交叉注意层,从而增强每种模式的结果。
Refined Shade
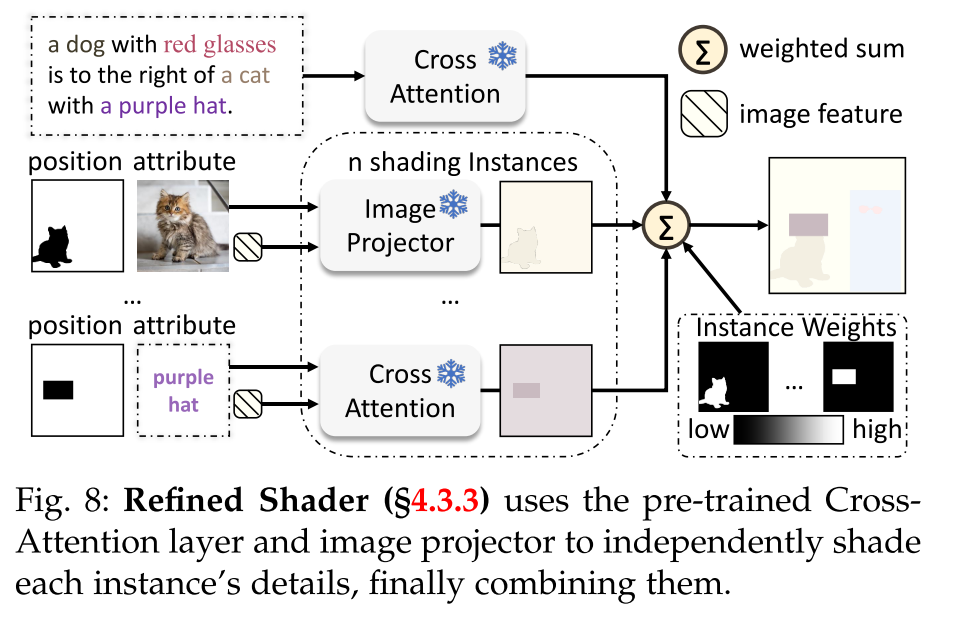
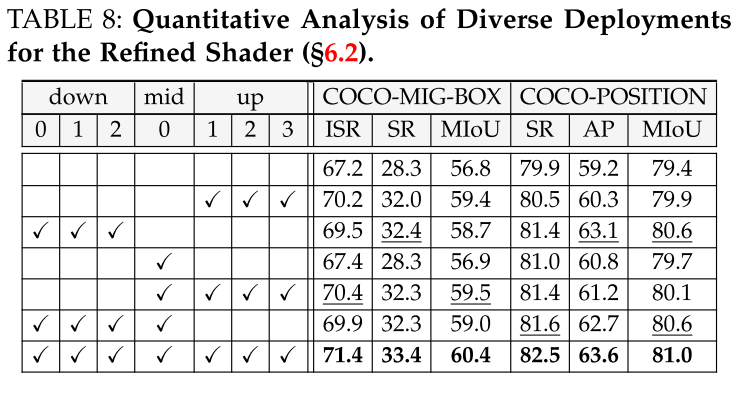
Motivation.而不是统一应用实例着色器(§4.2.1)跨所有块和样本步骤,MIGC战略性地把它放在中间块和U-net架构的深层上块。这种布局可以最佳地控制布局和粗糙属性,如类别、颜色和形状,如表5所示。然而,正如图(a)所示,一些块保留了标准的Cross-Attention层,导致细节着色不准确,例如用苹果状的细节渲染香蕉。当需要精确遵守参考图像时,这些差异至关重要,导致实例偏离其预期外观(图)。为了解决这个问题,我们提出了一个无需训练的精炼着色器来取代SD中的所有交叉注意层,提高多实例细节着色的准确性。

Solution. 如图所示,细化着色器也在分而治之的框架下运行,在集成之前独立地为每个实例着色。鉴于实例着色器已经准确地将每个实例定位在其指定的位置,并在粗粒度上具有正确的属性,精细着色器使用预训练的交叉注意层或图像投影仪进行精细着色。利用预训练模型生成详细视觉效果的能力。给定图像描述,细化着色器最初根据方程 1使用预训练的Cross-Attention层来导出全局着色结果Rcref。然后,对于每个具有属性描述attri的实例i,细化着色器根据方程 1和方程 2获得着色结果:
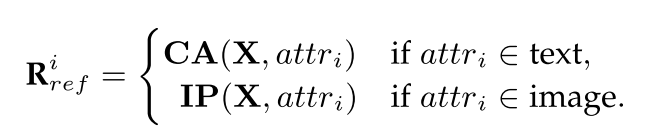
然后使用加权和函数对这些结果{Rcref, R1ref,···,Rnref}进行积分。具体来说,为每个实例构建一个2D权重映射。在实例i的权重映射mi中,实例定义的区域posi中的像素被赋值为α,而所有其他像素被设为值0。相反,全局着色结果的权重映射mc统一假设值为β。在2D空间中,对这些权重图{mc,m1,···,mn}应用softmax函数,建立它们的最终权重{¯mc,¯m1,···,¯mn},然后使用这些权重来计算总遮光结果:
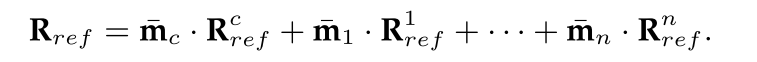
Deployment of MIGC++
图(b)概述了migc++的部署策略。MIGC++定位实例着色器类似于MIGC,并装备所有块与精制着色器。对于包含实例着色器和精炼着色器的块,migc++使用一个学习标量来有效地合并来自这两个着色器的多实例着色结果:
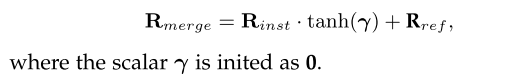
Consistent-MIG
Consistent-MIG算法改进了MIGC和MIGC++的迭代MIG能力,便于修改MIG中的某些实例,同时保持未修改区域的一致性,并最大化修改实例的ID一致性,如图1(c)所示。
Consistency of Unmodified Areas. 受Blended Diffusion的启发,Consistent-MIG在迭代MIG中通过将未修改区域的结果替换为前一次迭代的结果来保持未修改区域的一致性。具体而言,在迭代生成过程中,我们通过比较两次迭代的实例描述的差异来获得掩码修正,其中修改的区域标记为1,未修改的区域标记为0。假设在前一次迭代中采样的结果是zt,prev,我们使用掩码修改来更新当前迭代的采样结果zt,在未修改区域保持一致性:
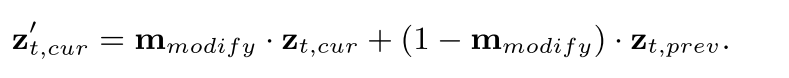
Consistency of Identity. 当修改实例的属性(如颜色)时,ID一致性是必不可少的。我们的方法Consistent-MIG借鉴了从文本到视频生成的技术来确保时间一致性,采用了一种特定的策略来确保ID一致性。在SelfAttention阶段,前一次迭代的键和值都与当前的键和值相连接,以增强对前一次迭代的ID信息的利用,从而保持身份连续性。
Loss Function
原始噪声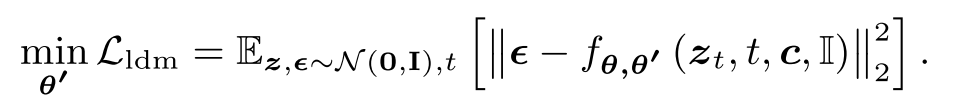
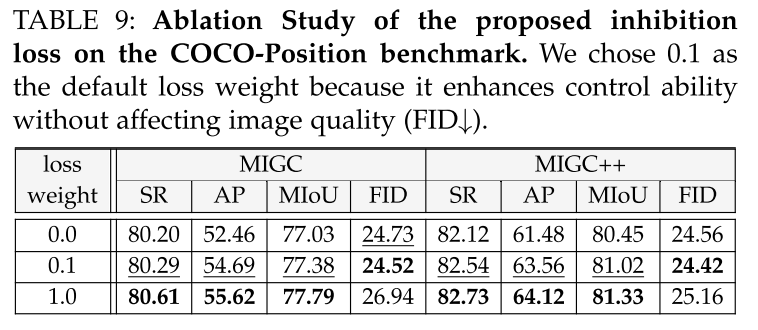
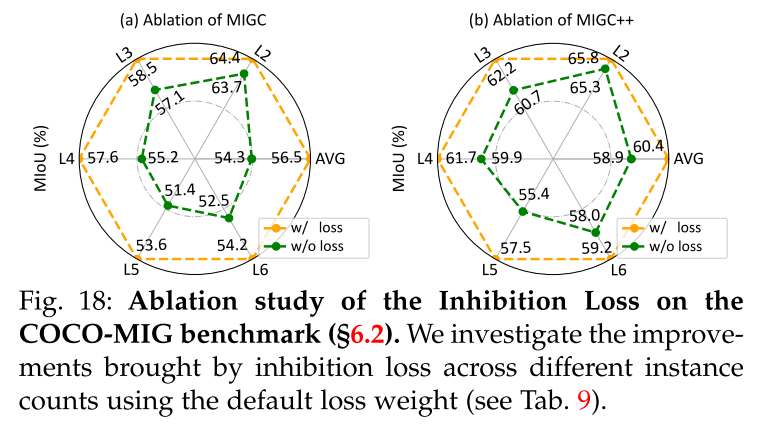
此外,为了确保n个生成的实例保持在指定的位置,并防止在后台无意中创建无关的实例,开发了抑制损失。这个损失函数是专门为避免背景区域的高注意权重而设计的:
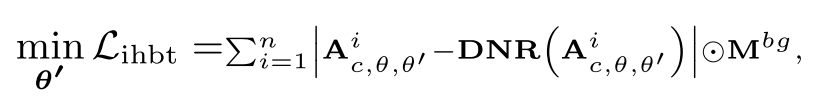
其中Ai,θ,θ '表示第i个实例的注意力图,来自于在16 × 16解码器块内的拟议精制着色器模型中冻结的交叉注意层,DNR(·)表示背景区域的去噪,使用平均操作实现。最终训练损失的设计如下:
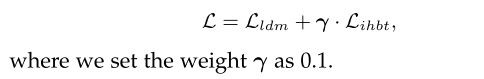
Implementation Details
Data Preparation. 在COCO 2014上训练MIGC和migc++,每个图像都有一个注释的图像描述。使用Stanza来解析图像描述中的实例文本描述。基于实例文本描述,使用GroundingDINO检测每个实例的边界框,并进一步使用Grounded-SAM获得每个实例的掩码。利用每个实例的边界框,裁剪出每个实例作为实例图像描述。
Training Text Modality. 为了将数据放在同一个批处理中,在训练期间将实例数设置为6。如果一个图像包含超过6个实例,其中6个将被随机选择。如果数据包含少于6个实例,用空文本完成它,用[0.0,0.0,0.0,0.0]的边界框或全零掩码指定位置。基于预训练的SD1.4来训练我们的MIGC和migc++。我们使用AdamW优化器,其恒定学习率为1e−4,衰减权值为1e−2,训练模型300次,批大小为320。
Training Image Modality. 冻结了文本模态中预训练的权重,并为图像模态引入了一个新的EnhanceAttention层,使migc++能够基于参考图像执行着色。与文本模态的训练一致,为了将数据放在一个批次中,在训练时将文本描述实例的数量固定为6个,将图像描述实例的数量固定为4个。如果数据中的实例少于4个,用空白的白色图像填充图像描述的实例。使用恒定学习率为1e−4,衰减权值为1e−2的AdamW优化器,训练图像模态的Enhance-Attention层200次,批大小为312。
Inference. 使用eulerdiscretesscheduler和50个样本步骤。我们选择CFG刻度为7.5。对于由图像描述的实例,将其遮罩,即用空白替换背景区域。使用ELITE作为图像投影仪。MIGC和migc++的部署细节可以从(§4.2.5)和(§4.3.4)中导出。
MIG BENCHMARK
COCO-MIG Benchmark
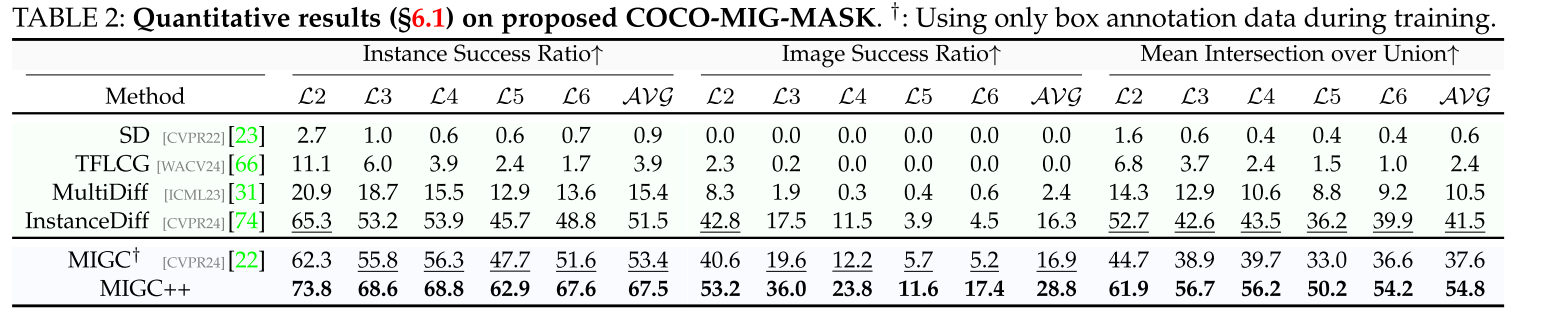
Overview. 引入COCO-MIG基准来研究多实例生成(MIG)任务。为了获得MIG中所需的实例描述,即实例的位置和属性,从COCO数据集中对布局进行采样,以确定每个实例的位置,并为每个实例分配颜色以确定其属性。这个基准规定每个生成的实例必须符合预定义的位置和属性。我们基于实例定位方法将基准改进为两个变体:coco - migg - box和COCO-MIGMASK,如图图所示。
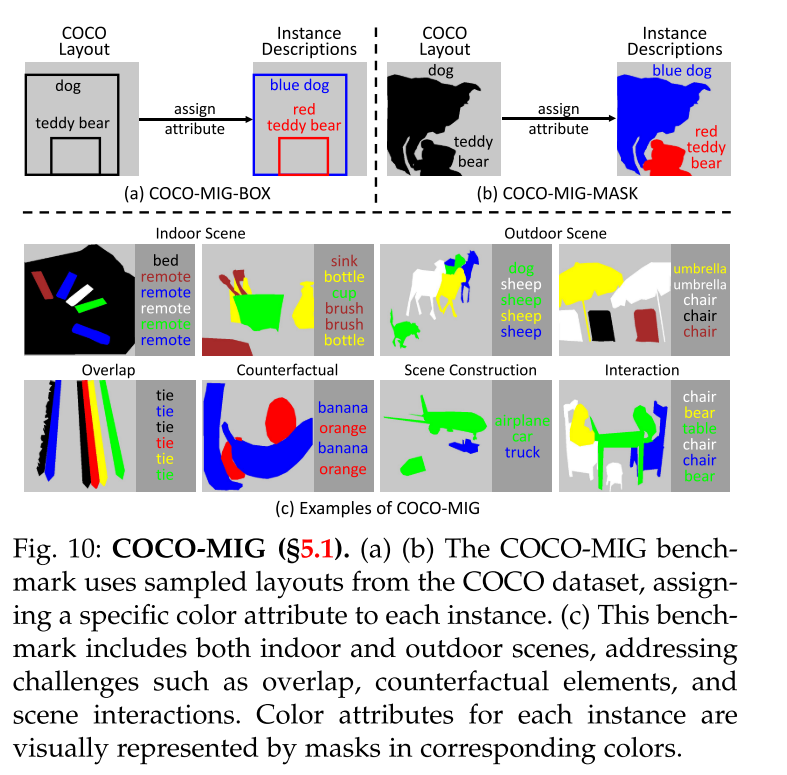
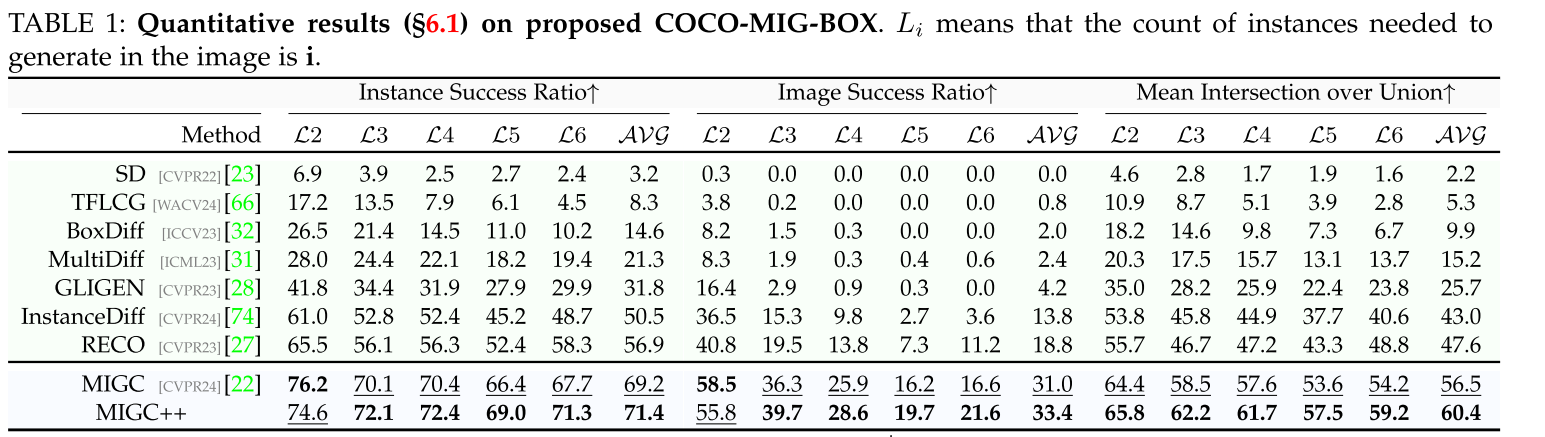
Construction Process. 从COCO数据集中提取布局,排除边长小于图像大小八分之一的实例和包含少于两个实例的布局。评估模型的能力调整实例的数量,将这些布局分为五个级别,从L2到L6。每个级别Li对应于每个图像i个实例的目标生成。这些级别的布局分布包括L2为155个,L3为153个,L4为148个,L5为140个,L6为154个,总计750个布局。当对特定级别Li的布局进行采样时,如果实例数量超过i,将选择具有最大区域的i个实例。相反,如果实例数量少于i,则进行重采样过程。对于每个布局,从7种颜色的调色板中为每个实例分配一种特定的颜色:红、黄、绿、蓝、白、黑和棕色。此外,将图像描述构建为“a <attr1> <obj1>, a <attr2> <obj2>,…”还有一个……”每个提示生成8个图像,每个方法生成6000个图像进行比较。
Evaluation Process. 使用以下管道来确定实例是否已正确生成:
(1)首先使用ground - dino在生成的图像中检测实例的边界框,然后计算目标边界框的交集(Intersection over Union, IoU)。如果IoU为0.5或更高,则认为实例的位置正确生成。如果检测到多个边界框,选择最接近目标边界框的一个进行IoU计算。如果实例的位置由掩码指示,通过检查掩码的IoU是否超过0.5来确认其正确的位置生成。
(2)对于验证为Position correct Generated的实例,接下来使用ground - sam评估其颜色精度,将该实例在图像中的区域分割为M。然后计算M在HSV空间中与指定颜色匹配的比例,记为O。该实例被视为完全正确生成。
Metric. COCO-MIG的评估指标包括:
(1)实例成功率,衡量完全正确生成的实例的比例(参见§5.1中的评估过程)。
(2)图像成功率,衡量生成的图像中所有实例都完全正确生成的比例。
(3) Mean Intersection over Union (MIoU),量化每个定位和属性实例的实际位置与目标位置之间的对齐。重要的是要注意,任何未完全正确生成的实例的MIoU都被记录为零。
Multimodal-MIG Benchmark
为了评估MIG中对文本和图像的多模态控制,引入了multimodal -MIG基准。受DrawBench的启发,该基准要求模型管理实例的位置、属性和数量,并将一些实例与参考图像的属性对齐。例如,如图第一行所示,提示符可能使用参考图像来指定“包”的自定义属性,并为其他实例指定文本描述,如“蓝色表”和“黑苹果”。为这个基准设计了20个提示,每个提示生成10个图像,每种方法总共生成200个图像用于评使用GPT4来创建migc++所需的实例描述,形成一个自动化的两阶段管道。
EXPERIMENTAL RESULTS
COCO-MIG and Multimodal-MIG benchmarks and COCO-Position and Drawbench
Compare with State-of-the-art Competitors
COCO-MIG-BOX.

COCO-MIG-MASK.
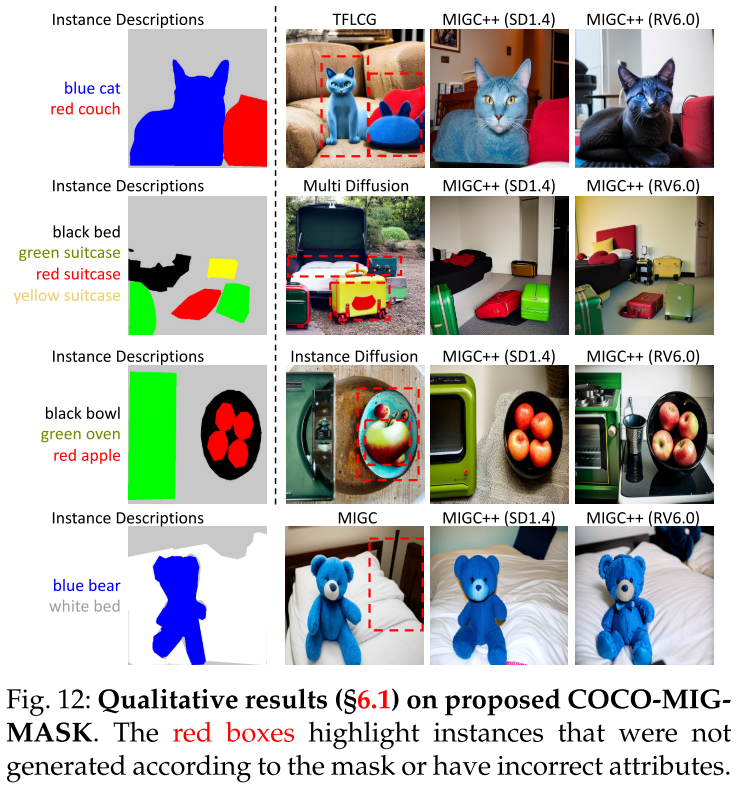
Robustness to Increasing Instance Number.
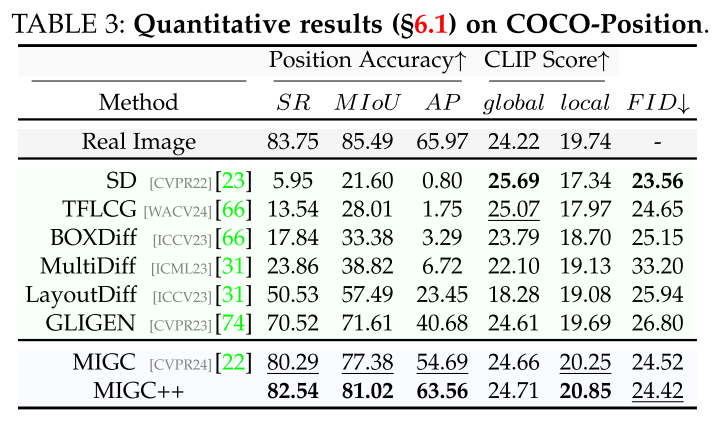
COCO-POSITION.

DrawBench.
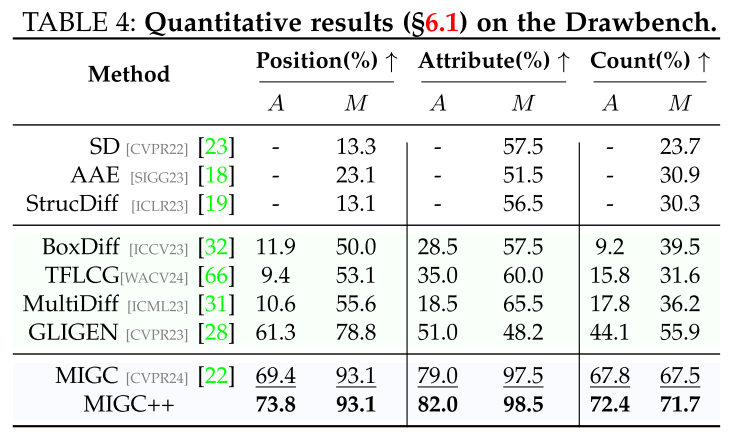
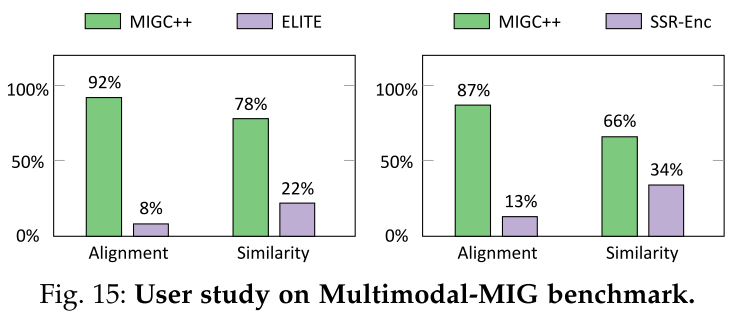
Multimodal-MIG.

Ablation Study
Deployment Position of Instance Shader.
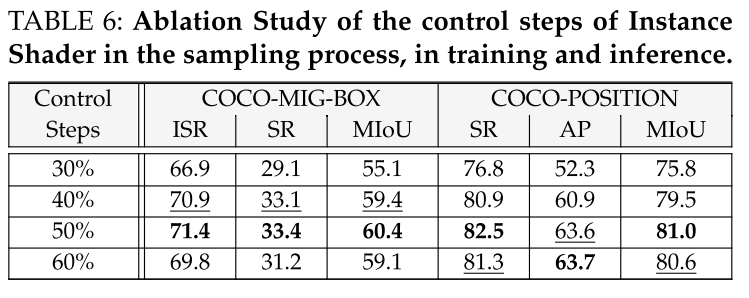
Control steps of Instance Shader.
Enhancement Attention.
Layout Attention.
Shading Aggregation Controller.
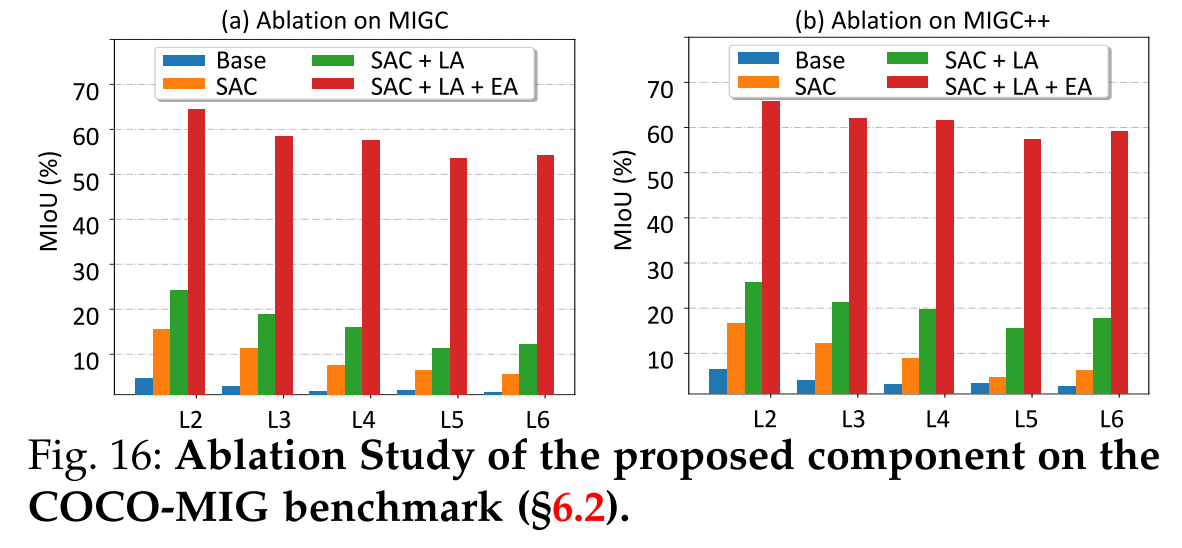

Inhibition Loss.
Refined Shader.
Consistent-MIG.


Visualization of Multi-Instance Shading
