Dify智能体平台源码二次开发笔记(7) - 优化知识库pdf识别(2)
目录
前言
设计方案
代码具体优化
前言
补充前篇的一些优化。
场景是识别pdf文档,但还需要把pdf文档中的图片也保存下来,在知识库增强检索的时候,直接可以显示图片。
设计方案
1、保存知识库中的图片
2、存入我们的文件服务器中,比如minio
3、名称规则为:image_files/年/月/日/文件
4、在知识库中用[Image 图片路径]
5、在前端知识库增强检索中,根据这个默认替换成图片可以访问的方法
代码具体优化
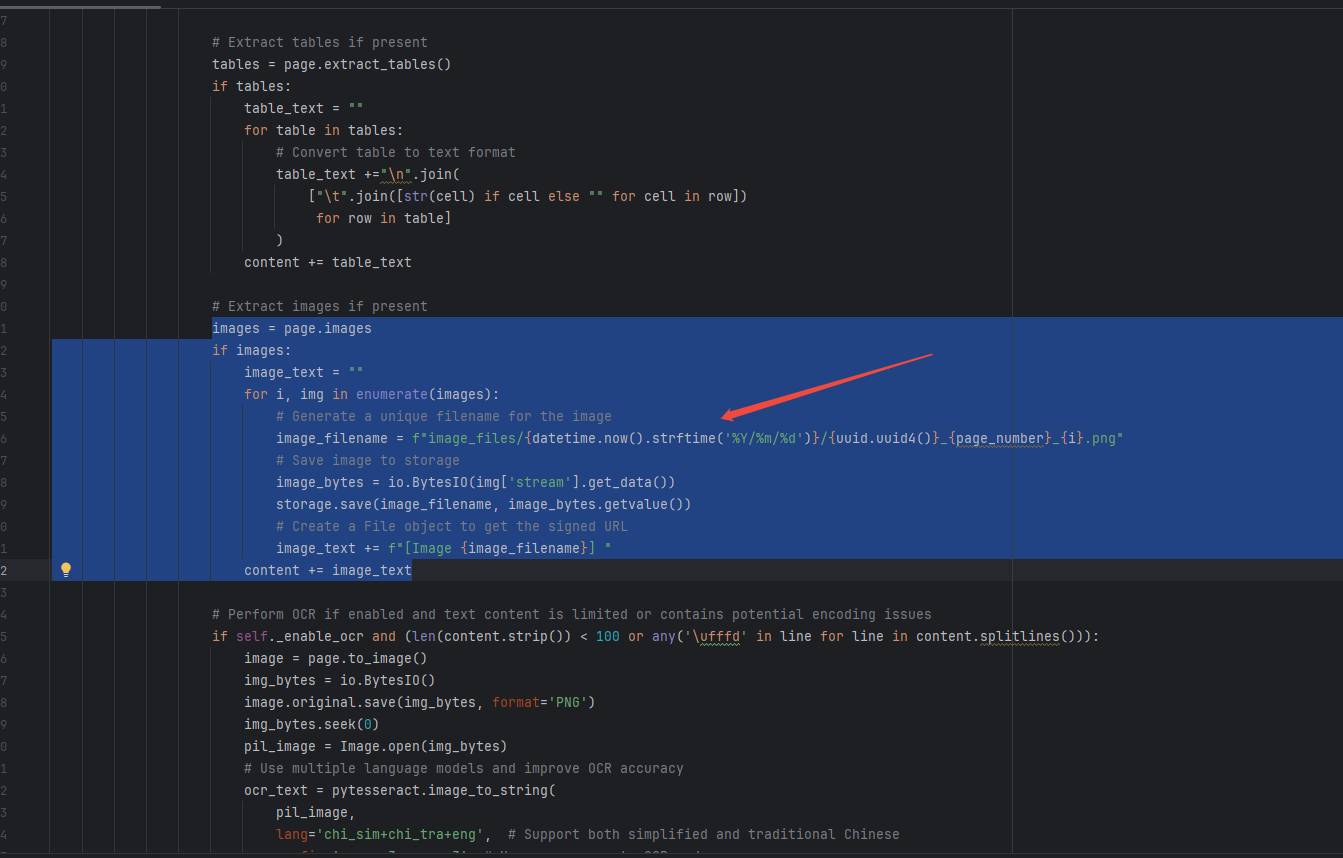
主要在上一篇的基础上,添加这一段代码
images = page.imagesif images:image_text = ""for i, img in enumerate(images):# Generate a unique filename for the imageimage_filename = f"image_files/{datetime.now().strftime('%Y/%m/%d')}/{uuid.uuid4()}_{page_number}_{i}.png"# Save image to storageimage_bytes = io.BytesIO(img['stream'].get_data())storage.save(image_filename, image_bytes.getvalue())# Create a File object to get the signed URLimage_text += f"[Image {image_filename}] "content += image_text