【C++】Stack和Queue的底层封装和实现
目录
- stack
- 容器适配器
- stack的模拟实现
- queue的模拟实现
- deque
- 了解deque的结构
- deque的管理方式和遍历元素方式
- deque的缺陷
- 为啥库里面的stack和queue使用deque
- end
stack
容器适配器
Stack可以封装成前面三个变量的形式,但是这里我们提出一个概念叫容器适配器,回归我们生活中的适配器,比如电源适配器,就是把电流转换成对应w数的,如67w,120w,而容器适配器简单来说就是复用已有的容器,在他的基础上改成完理想容器的特性和功能,就把旧容器转化成了一个新容器。比如我们用vector来适配,那么我们在栈里面插入数据的时候由于复用vector是不是就不需要考虑扩容问题,vector会自动扩容。这就很方便‘
’

- 配成我们栈需要出栈入栈的功能
- 注意:只能用vector有的接口模拟实现,如果使用push_front的vector就不行了
stack的模拟实现
#pragma once
#include<iostream>
#include<queue>
#include<vector>
using namespace std;
namespace bit
{template<class T, class Container = deque<T>> //模板参数也快吃缺省参数class stack{public:void push(const T& x){_con.push_back(x); //在尾部进行插入和删除模拟栈顶出栈和入栈的功能}void pop(){_con.pop_back(); }const T& top() const{return _con.back();}size_t size() const{return _con.size();}bool empty() const{return _con.empty();}private:Container _con;};
}- 可以看到,我们直接复用deque的接口就行了,这里deque是啥?为啥用deque我后面解释
queue的模拟实现
queue是队列,也是一样的可以用容器适配器来复用已经有的接口来完成需要的功能。这里我们队列要满足先进先出的特性,那我们就可以使用deque的尾插来插入数据,头删来删除数据,达到
先进先出的特性
#pragma once
#include<iostream>
#include<list>
#include<queue>
using namespace std;
namespace bit
{template<class T, class Container = deque<T>>class queue{public:void push_back(const T& x){_con.push_back(x);}void pop_back(){_con.pop_front();}const T& front() const{return _con.front();}const T& back() const{return _con.back();}size_t size() const{return _con.size();}bool empty() const{return _con.empty();}private:Container _con;};
}
deque
- 大家都看到了,我们模拟实现stack和queue的时候都选的dque这个东西来适配,接下来我们来了解一下deque是啥。
库里面的也是用的deque


了解deque的结构
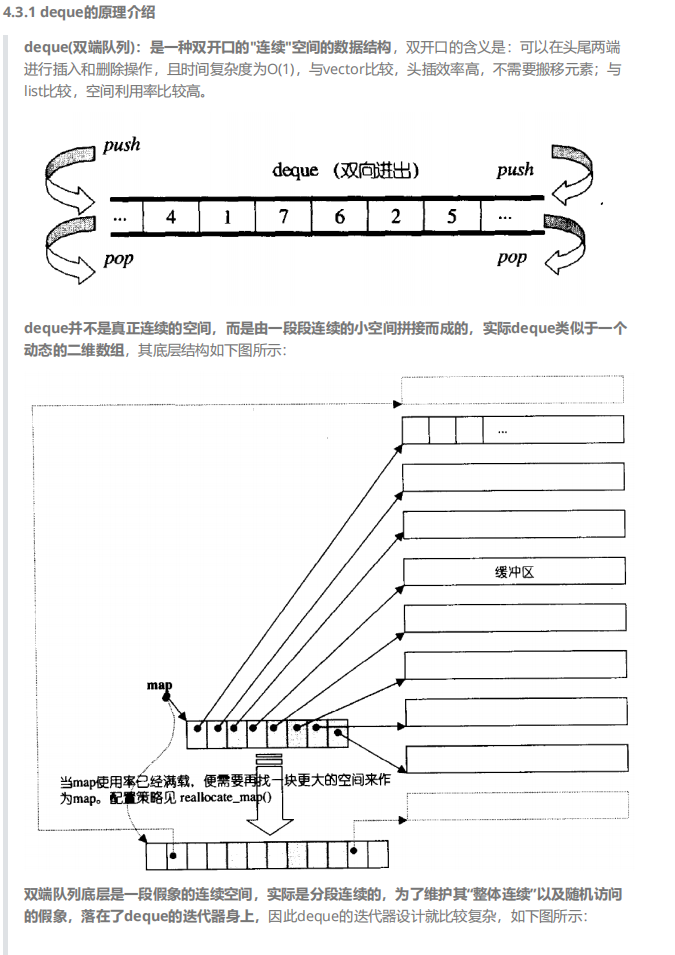
deque的管理方式和遍历元素方式

deque的缺陷
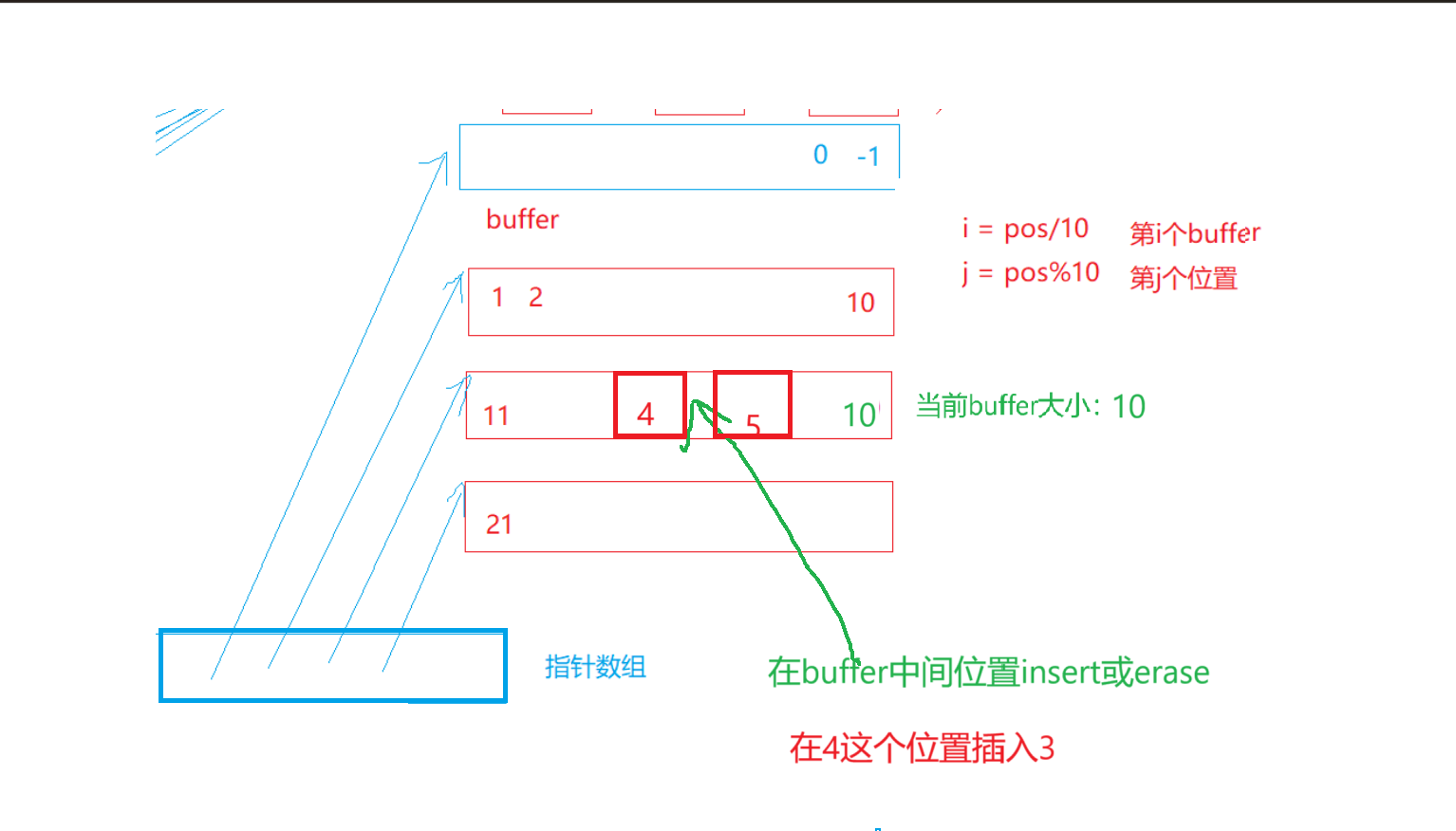
第一种:
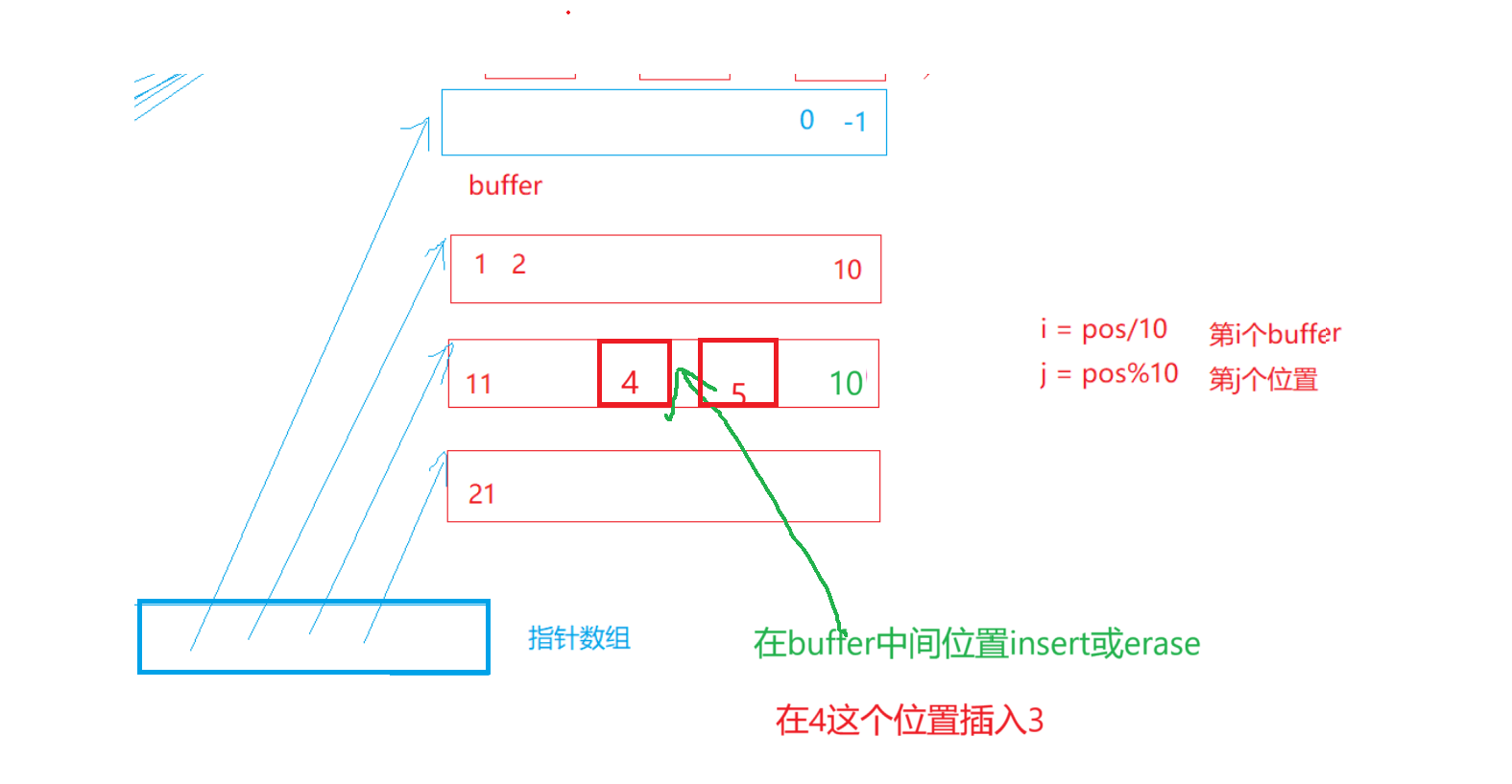
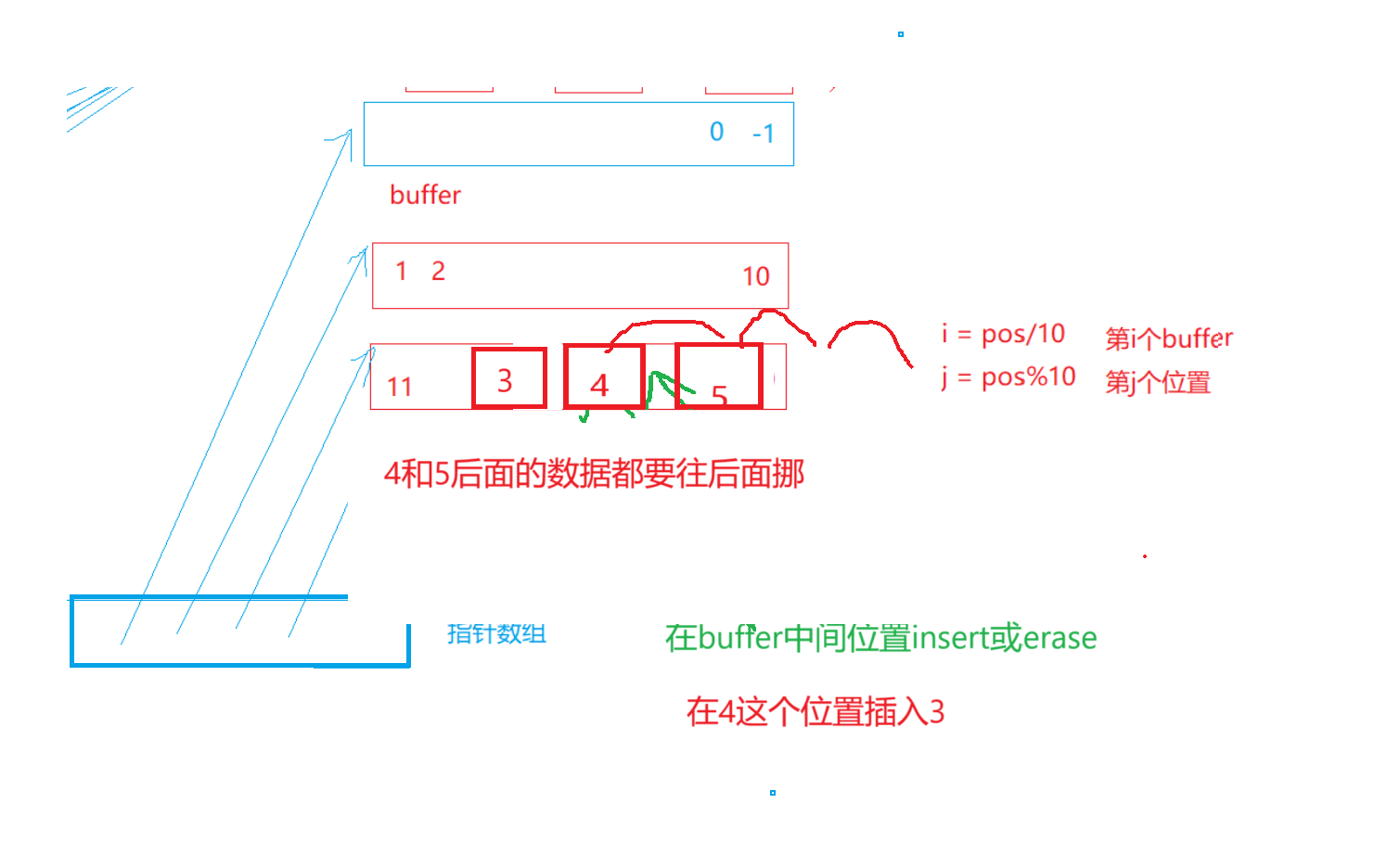
- 这时候的缺陷:1.Insert/erase把数据往后面/前面挪动,不改变每个buffer的大小,buffer的存储数据量大了,那和我们vector中一样数据多了就要移动后面的所有数据(这里是当前buffer和后面的buffer),效率不高
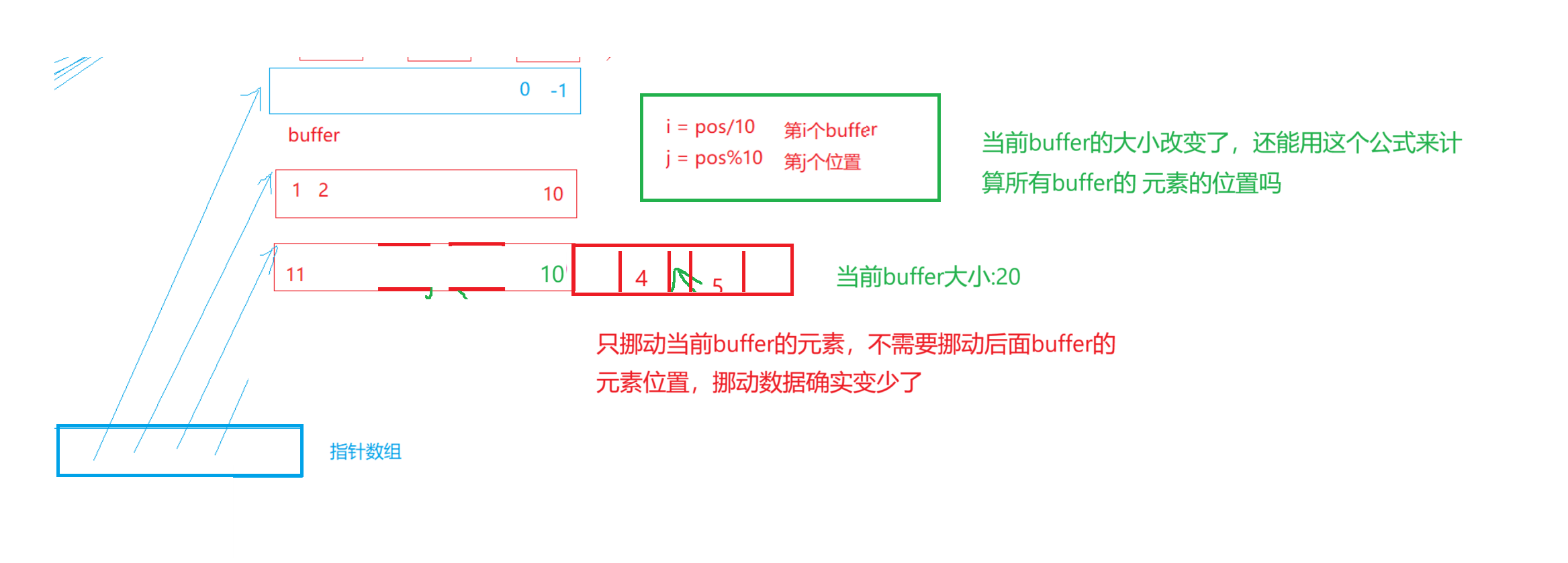
第二种缺陷:
总结:
Deque能替代vector和list吗
Deque的头插效率确实比vector高,只需要在第一个buffer前面再开一个buffer,然后让中控数组(指针数组)添加一个指针指向这个buffer就行了
但是vetor中在中间位置insert和erase的问题仍然存在
1.Insert/erase把数据往后面/前面挪动,不改变每个buffer的大小,buffer的存储数据量大了,那和我们vector中一样数据多了就要移动很多,效率不高
2.只把insert/erase位置buffer数据往后面/前面挪动,后面的buffer不动,又要改变当前buffer的大小,那我们[]访问的效率又变低了
假设每个buffer的长度是10
[]访问计算下标:i = pos / 10(第n个buffer), j = pos % 10(第n个buffer的第j个元素)
大多数选择舍弃第一种方法,因为[]使用频率更高,insert和erase用的更少
为啥库里面的stack和queue使用deque
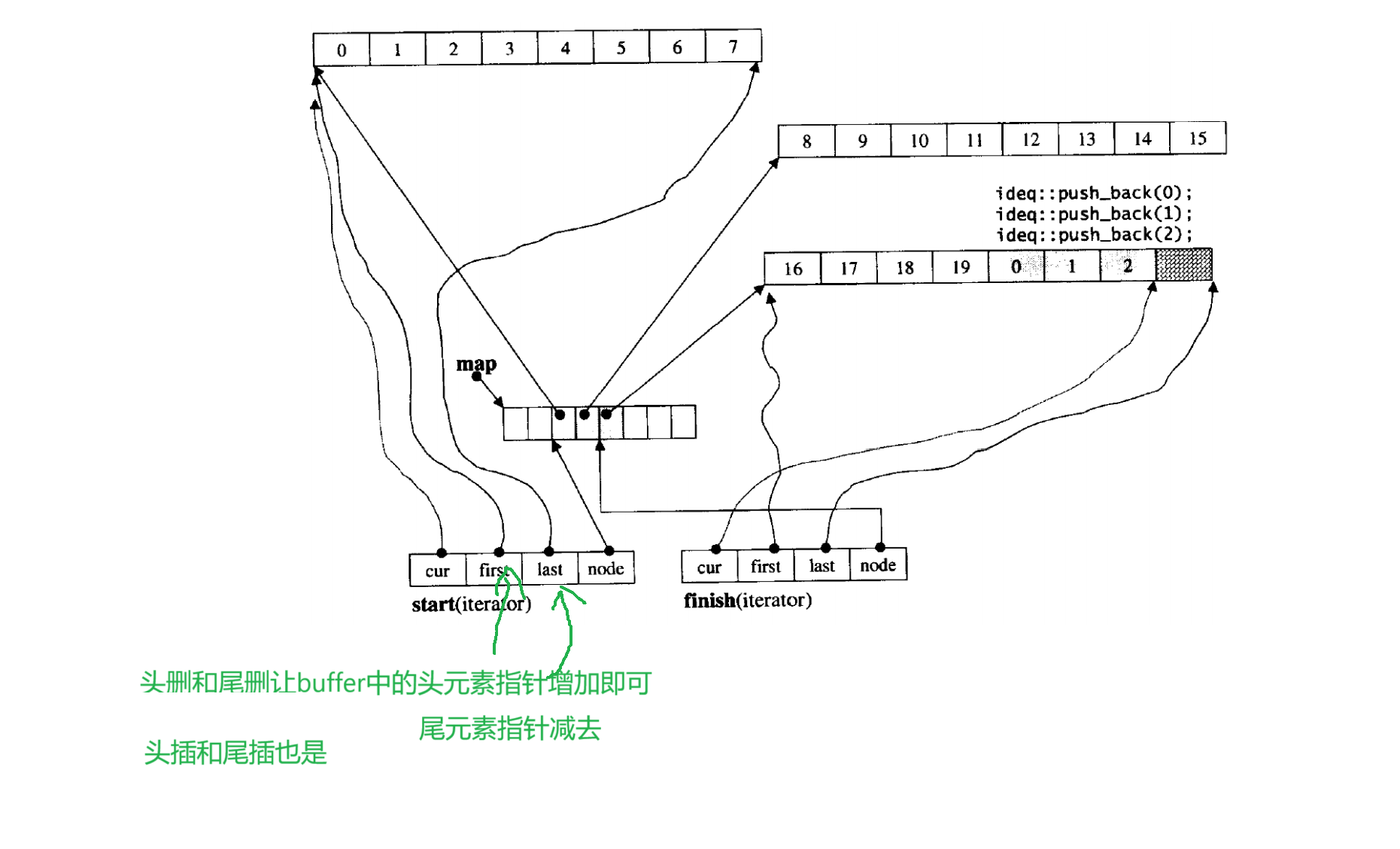
那为啥Stack和queue要用deque当容器适配器呢?
原因:deque的头删头插和尾插尾删效率很高
1.对于vector头删效率很低,需要把头元素后面的元素全部往前挪
2.对于list,尾插的时候,如果要大量插入数据,则需要一个一个的去开空间,而deque通过buffer这个机制,一下开出很多空间,避免了频繁开空间,对于系统来说开一个空间和开一块空间的效率是一样的,
3.所以stack需要尾插头删,queue需要尾插尾删,deque都可以高效率满足
end
感谢大家的阅读,希望对你有帮助,谢谢