循环神经网络 - 门控循环单元网络之参数学习
GRU(门控循环单元)的参数学习与其他循环神经网络类似,主要依赖于梯度下降和反向传播通过时间(BPTT)算法。下面我们通过一个简单例子来说明 GRU 参数是如何在训练过程中“自适应”调整的。
一、GRU参数学习
假设我们的任务是对一个简单的时间序列做预测,比如给定输入序列预测下一个数值。
1. GRU 的前向传播
在 GRU 中,每个时间步的计算主要涉及两个门:更新门和重置门。假设 GRU 的计算公式如下(简化形式):
-
更新门:
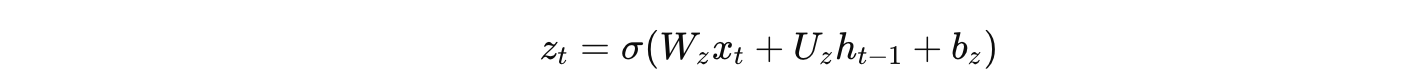
-
重置门:
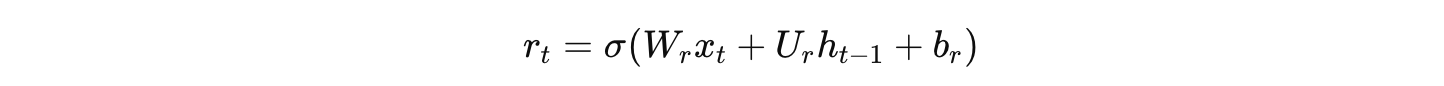
-
候选隐藏状态:
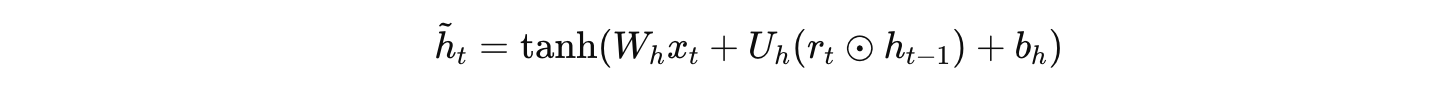
-
最终隐藏状态:

2. 参数学习过程概述
2.1 前向传播(Forward Pass)
-
初始化
对于每个时间步 t,给定输入 xt 和前一时刻隐藏状态 h_{t-1}(初始 h0 通常设为0),网络计算出更新门 z_t、重置门 r_t 和候选隐藏状态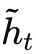 。
。 -
隐藏状态更新
得到最终隐藏状态 h_t,随后可能通过一个输出层产生预测 y_t。
前向传播完成后,我们得到了每个时间步的预测输出,并计算了每个时间步的损失 L_t(例如均方误差: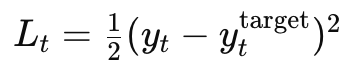 )。
)。
2.2 损失计算
网络的总损失通常为所有时间步损失的总和或均值:
2.3 反向传播通过时间(BPTT)
由于 GRU 的参数在每个时间步都是共享的,整个序列的梯度更新需要经过以下几个关键步骤:
-
局部梯度计算

-
梯度传递与累积

-
参数梯度更新

-
时间传递
前一部分“梯度传递与累积”其实包含了时间传递的步骤,即将每一时刻计算出的梯度通过状态转移矩阵传递到前一时刻。这样,每个时间步的参数梯度累加后,反映了整个序列上的误差信息。
3. 举例说明
假设我们有一个 GRU 处理一个短序列 x1,x2,x3,目标分别为 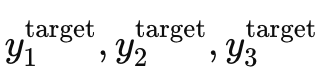 。
。
前向传播示例:
-
时间步 1:
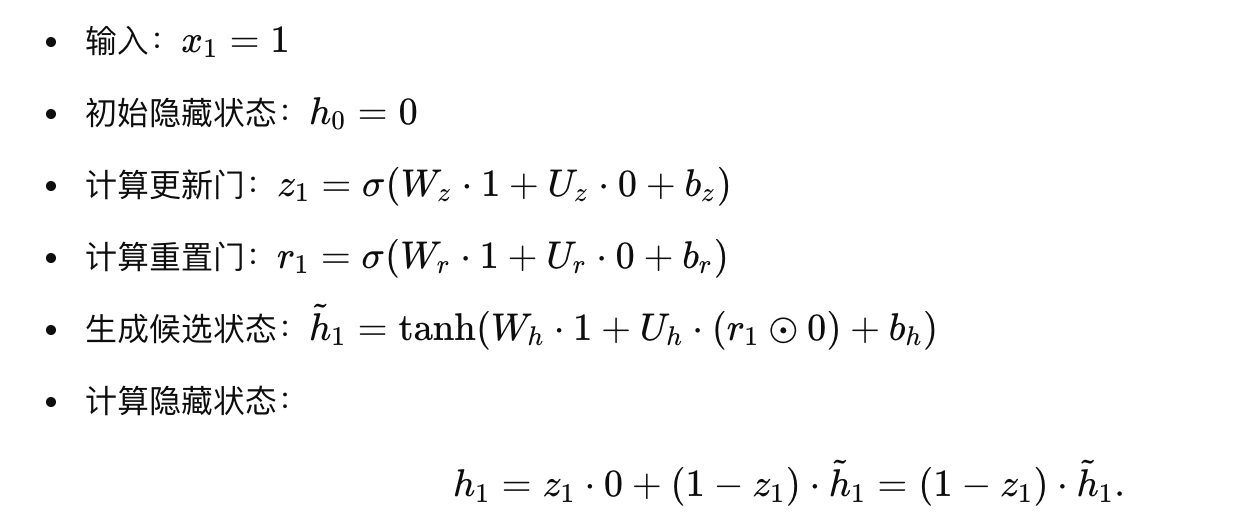
-
时间步 2:
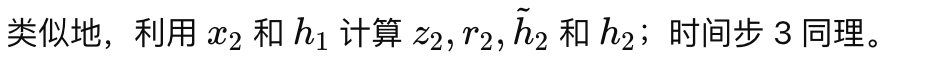
假设输出层将隐藏状态映射到预测值 y_t,并使用 MSE 损失:
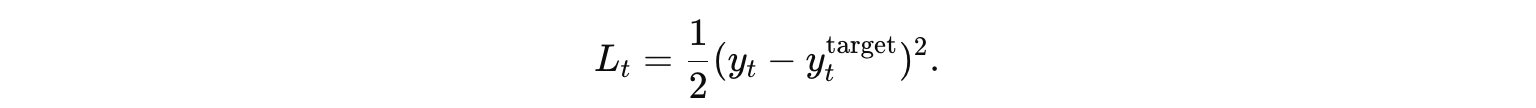
反向传播与参数更新:
-

-
将时间步 3 的梯度传递到时间步 2,计算 ∂h3/∂h2 的影响,并累积计算出时间步 2 的总梯度。
-
同样,传递梯度到时间步 1,并逐步累积。
-
对各时间步中,利用局部梯度与对应输入(或前一隐藏状态)的外积计算出参数的梯度,将这些梯度在整个序列上累加。
-
最后采用优化算法更新所有参数。
这个过程展示了如何在 GRU 中,通过前向传播计算隐藏状态,利用每个时间步局部误差信息和通过时间传递得到的梯度,来实时更新如 Wz,Uz,Wr,Ur,Wh,Uh 及对应偏置项,达到训练模型的目的。
二、GRU参数学习具体示例
下面提供一个具体的例子,展示如何在一个简单的 GRU 模型上进行参数学习的过程,并说明模型训练完成后如何应用。这个例子以一个序列预测任务为例:给定输入序列 [1, 2, 3],目标输出为 [2, 3, 4],让模型学会“每个数字加 1”这一规律。
我们假设模型的输入和输出均为标量,且隐藏层维度为 2。GRU 的计算公式(简化形式)为:
-
更新门(Update Gate):
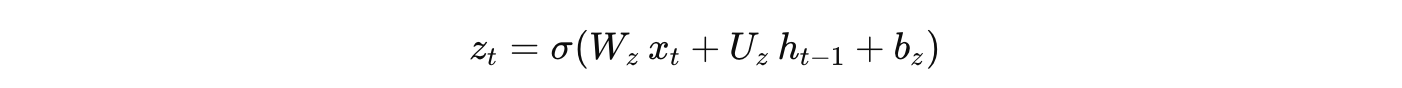
-
重置门(Reset Gate):
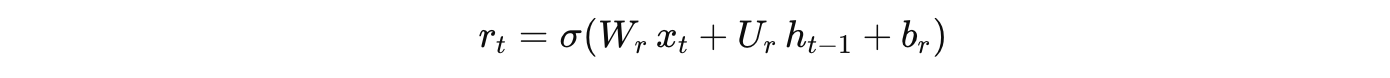
-
候选隐藏状态:
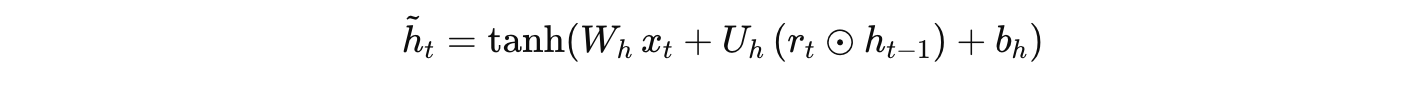
-
最终隐藏状态:
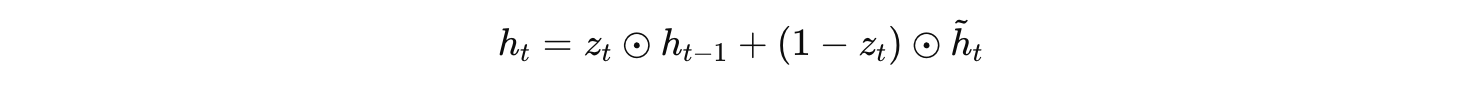
其中,σ(⋅) 表示 sigmoid 函数,将数值压缩到 (0, 1) 区间,“⊙” 表示元素逐乘。
模型参数初始化
假设各个参数初始设置如下(为了简单,我们选用小的数值):
-
更新门参数:
Wz=[0.3]
Wz 为 (1×1) 矩阵:U_z 为 (1×2) 矩阵:
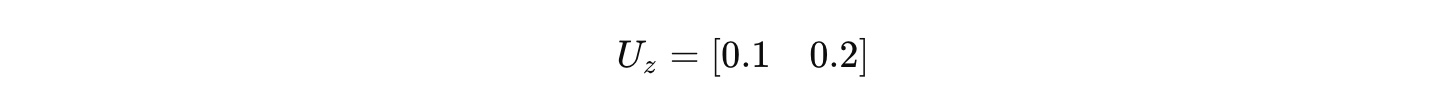
偏置 bz=0.1.
-
重置门参数:

-
候选隐藏状态参数:

-
输出层参数(将隐藏状态映射到输出):
假设隐藏状态维度为 2,输出为标量,所以
Why 为 (1×2) 矩阵: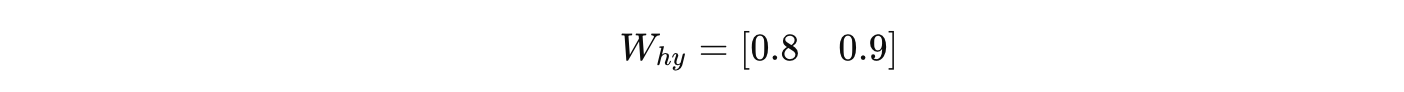
偏置 by=0.1.
-
初始隐藏状态 h0=[0,0].
这里为了说明问题,我们将隐藏层维度简单设为 2,而输入和输出为标量。
前向传播过程
我们逐时间步计算 GRU 的输出。
时间步 1
-
输入:x1=1、
-
前一隐藏状态:h0=[0,0]、
计算更新门:
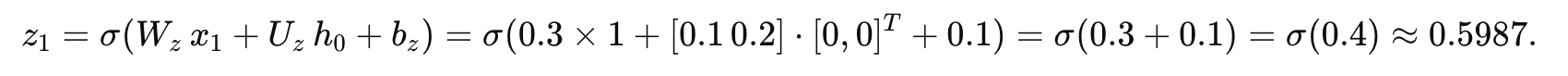
由于输出是标量,但更新门这里需要与隐藏状态相乘,对齐维度时,考虑其实每个时间步更新门影响隐藏状态的每个维度。为简化,我们令更新门的输出在每个维度都为 0.5987(实际实现中通常为一个标量乘以向量)。
计算重置门:
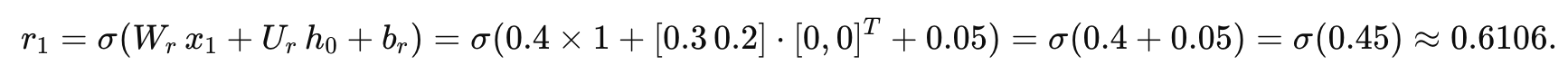
同理,输出复制到每个隐藏单元,也记为 [0.6106, 0.6106].
候选隐藏状态: 由于 h0=[0,0],重置门作用不大:
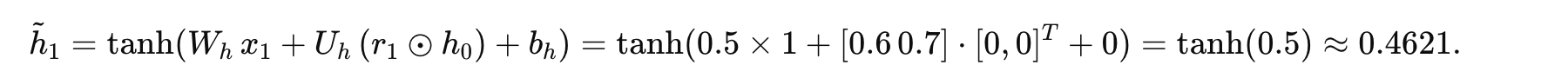
为了适应隐藏状态维度 2,我们假设候选隐藏状态在两个单元上均为 0.4621,记作 [0.4621,0.4621]。
最终隐藏状态:

输出:
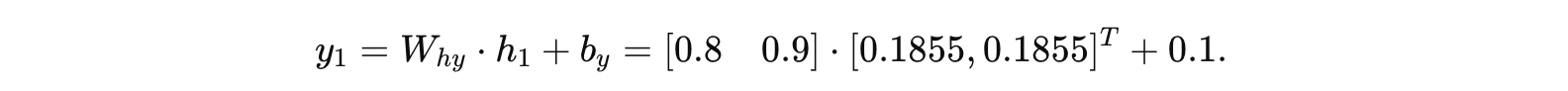
计算内积:
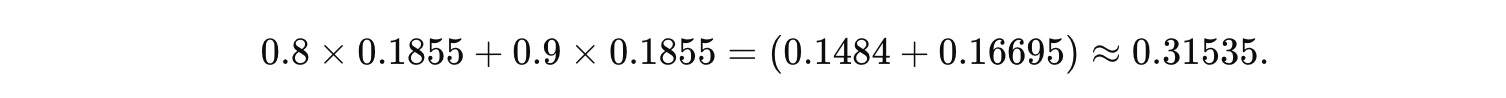
加偏置:
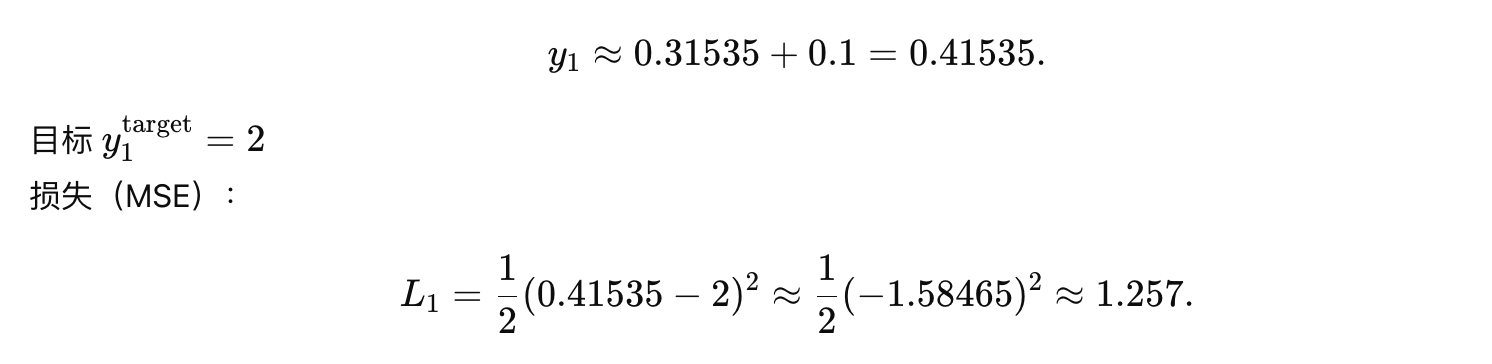
时间步 2
-
输入:x2=2
-
上一隐藏状态:h1=[0.1855,0.1855]
计算更新门:
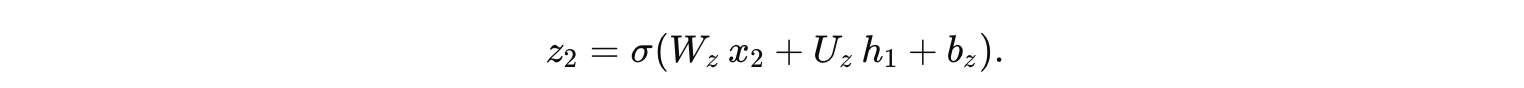
计算细节:
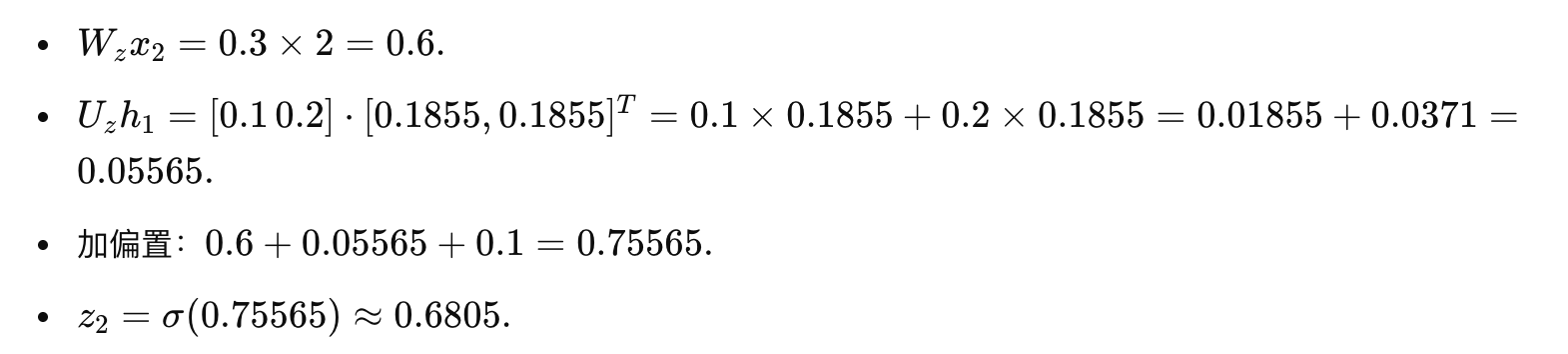
计算重置门:
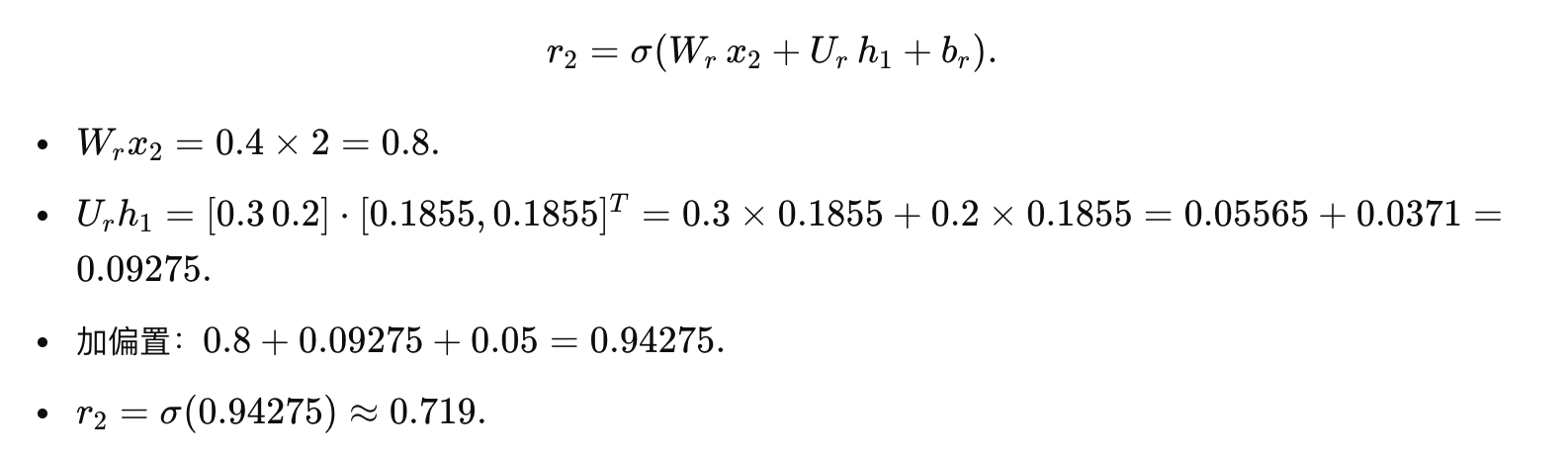
候选隐藏状态:

最终隐藏状态:

输出:
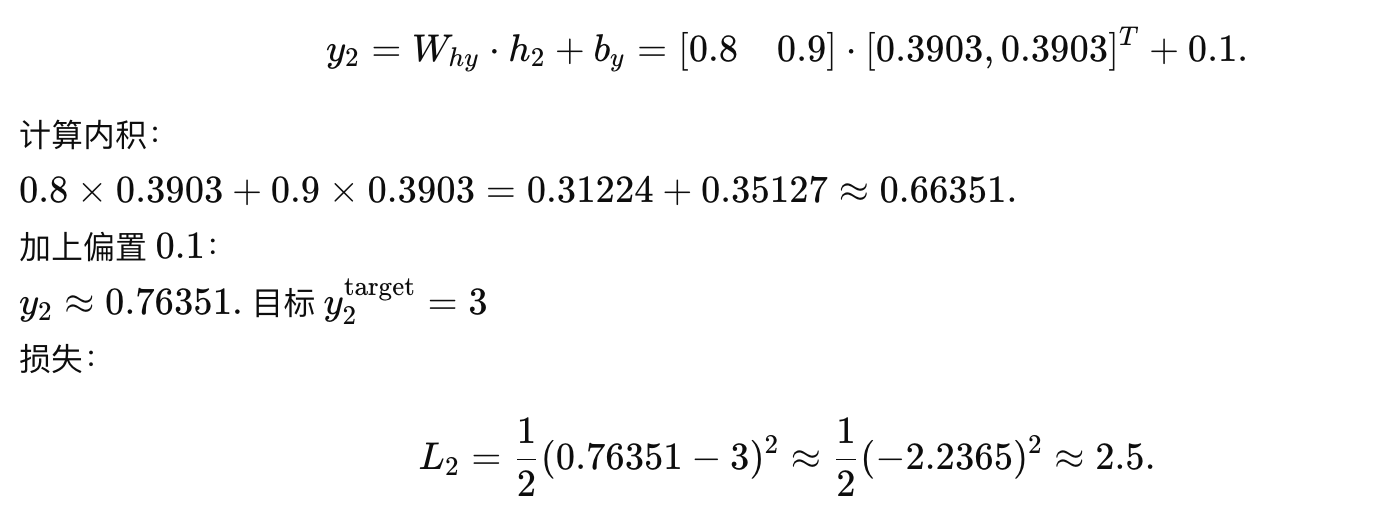
时间步 3
-
输入:x3=3
-
上一隐藏状态:h2=[0.3903,0.3903]
更新门:
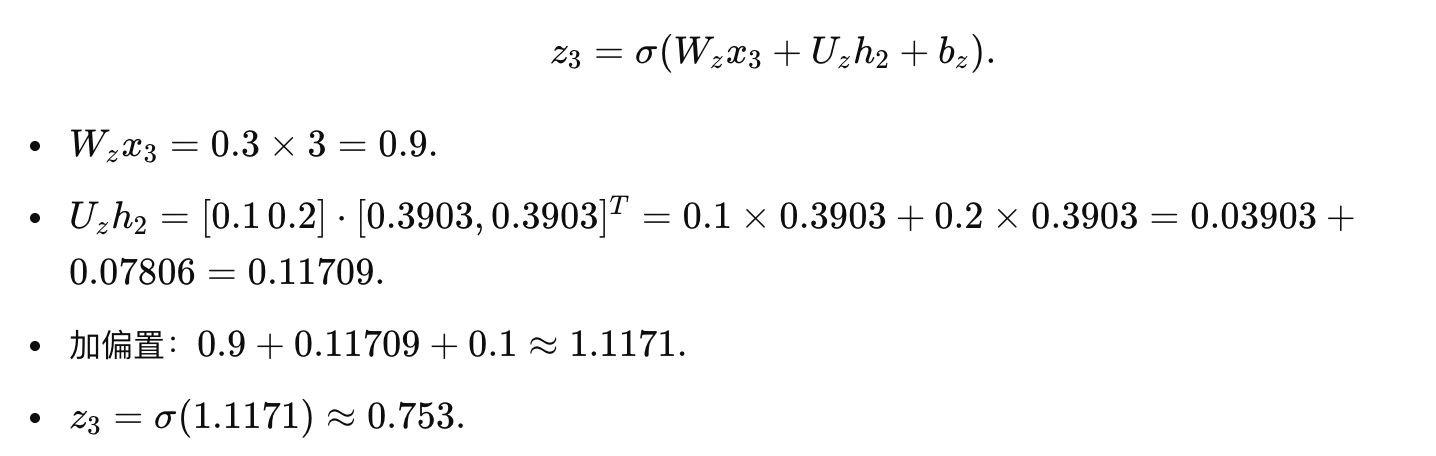
重置门:
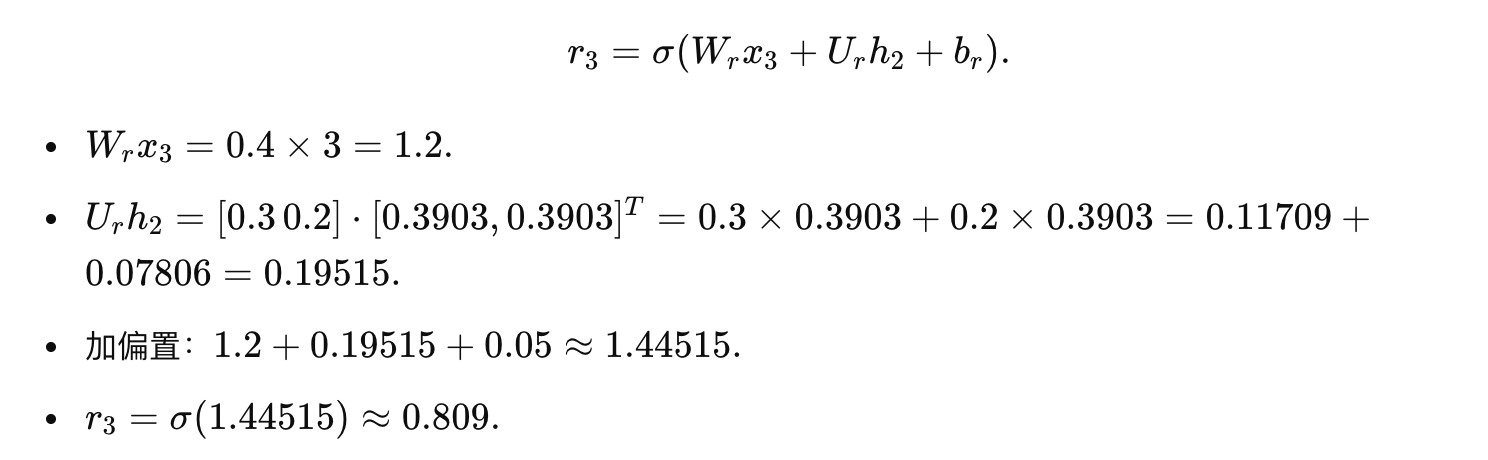
候选隐藏状态:

最终隐藏状态:

输出:

总损失:
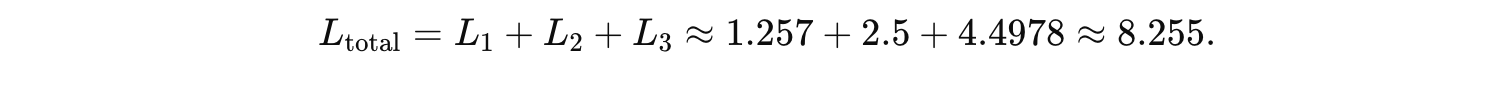
参数更新(以 Why 为例)

模型训练完成后的应用
在经过多次训练迭代、参数稳定后,模型学会了“数字加 1”这一规律。此时训练好的 GRU 模型可以应用于新的输入序列,比如输入 [4, 5, 6],模型通过前向传播输出预测序列,应当得到 [5, 6, 7]。
具体步骤:
-
对新输入进行前向传播,依次计算每个时间步的更新门、重置门、候选隐藏状态和最终隐藏状态。
-
得到每个时间步的输出 yt,这些值便是模型的预测结果。
例如,当输入 [4,5,6] 时,经过上述计算过程(使用更新后的参数),模型应该输出近似 [5, 6, 7] 的序列,从而完成预测任务。
总结
-
前向传播:以具体数值参数,逐时间步计算 GRU 内各门的输出,并得到隐藏状态和预测输出。
-
损失计算:将预测输出与目标值比较,计算 MSE 损失。
-
反向传播(BPTT):
-
计算每个时间步局部梯度(结合门控机制和激活函数导数),
-
利用链式法则将时间步误差传递并累积,
-
对各参数(更新门、重置门、候选状态及输出层)的梯度求和累加。
-
-
参数更新:使用梯度下降或其他优化算法更新所有共享参数。
-
应用:训练完成后,在新的输入上进行前向传播输出预测结果,实现序列预测任务。
这个例子展示了 GRU 从前向传播到 BPTT 再到参数更新的具体数值流程,帮助理解模型如何通过学习逐步调整参数,最终在应用中实现准确的预测。