NCCL使用指南-进阶篇
前文 NCCL使用指南-基础篇 介绍了NCCL的常用环境变量,本文介绍了NCCL-test性能基准测试,以及一些大规模集群测试的经验数据。
NCCL test
安装nccl
方式1 安装发行版本:
选择与cuda对应版本
https://developer.nvidia.com/nccl/nccl-legacy-downloads
rpm -ivh ***
yum install libnccl-2.18.5-1+cuda12.2 libnccl-devel-2.18.5-1+ cuda12.2 libnccl-static-2.18.5-1+cuda12.2
方式2 编译安装
https://github.com/NVIDIA/nccl
cd nccl
make src.build -j 100 CUDA_HOME=/usr/local/cuda-12.1
yum install rpm-build rpmdevtools
make pkg.redhat.build
cd build/pkg/rpm/x86_64
rpm安装即可
在物理机上ld版本过低
wget https://ftp.gnu.org/gnu/binutils/binutils-2.27.tar.gz
./configure --prefix=/usr/local/binutils
make -j 100
make install
vim ~/.bashrc
添加如下配置
export PATH=/usr/local/binutils/bin:$PATH
source ~/.bashrc
再次查看Binutils 版本
ld -v
安装openmpi
wget https://download.open-mpi.org/release/open-mpi/v4.1/openmpi-4.1.3.tar.gz
tar -xzf openmpi-4.1.3.tar.gz
apt install libnuma-dev
cd openmpi-4.1.3
./configure
make -j100 && make install
ldconfig
安装 nccl-test (两台机器的目录需要一样)
git clone git@github.com:NVIDIA/nccl-tests.git
make MPI=1 MPI_HOME=/usr
会在build目录下生成一些二进制文件
配置机器之间的ssh免密登录
ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub ${ip}
例如两台机器198.18.0.4,198.18.4.5,以198.18.0.4为master,那么需要在master上,以下命令
ssh 198.18.0.4
ssh 198.18.4.5
都可以直接执行。 这里给出一个测试是否连通的脚本,如果不通,检查两台机器(包括ssh自己)是否可连通,检查安全组是否放开
mpirun -np 2 -H 10.226.130.236,10.226.130.237 --allow-run-as-root hostname
在master机器上执行
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
mpirun --allow-run-as-root -np 16 \
-H 198.18.0.4:8,198.18.4.5:8 \
-x NCCL_DEBUG=INFO \
-x NCCL_DEBUG_FILE=debug.log \
-x NCCL_SOCKET_IFNAME=enp88s0f0 \
-x UCX_IB_TRAFFIC_CLASS=96 \
-x NCCL_P2P_DISABLE=0 \
-x NCCL_SHM_DISABLE=0 \
-x UCX_TLS=rc,sm \
-x CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
-x UCX_NET_DEVICES=mlx5_2:1 \
-x NCCL_COLLNET_ENABLE=0 \
-x UCX_IB_GID_INDEX=3 \
-x NCCL_IB_TC=96 \
-x NCCL_BUFFSIZE=16777216 \
-x NCCL_IB_ADAPTIVE_ROUTING=1 \
-x LD_LIBRARY_PATH \
-x PATH \
-x NCCL_IB_GID_INDEX=3 \
-x MELLANOX_VISIBLE_DEVICES=2,3,4,8,9,10,11,5 \
-x NCCL_IB_HCA=mlx5_2:1,mlx5_3:1,mlx5_4:1,mlx5_8:1,mlx5_9:1,mlx5_10:1,mlx5_11:1,mlx5_5:1 \
-x NCCL_IB_DISABLE=0 \
-bind-to numa --gmca btl tcp,self \
/root/zzh/nccl-tests-master/build/broadcast_perf --minbytes 8G --maxbytes 8G -f2 -g1 -n20 -c0 -i1000 -w 20
具体性能数据涉密,这里给一下大体的性能推导,在一台有100Gb * 8 网卡的hpc 8 卡gpu机器上。
两台机器 allreduce: busbw = 2 * min(nvswitch/2, nic) * 0.8 = 160G 左右
多台机器 allreduce: busbw = min(nvswitch/2, nic) * 0.8 = 80G左右
这个公式怎么来的?需要区分ring allreduce和tree allreduce, 了解一部分nccl基本原理。
首先需要区分什么是algbw,什么是busbw
参考官方文档:
https://github.com/NVIDIA/nccl-tests/blob/master/doc/PERFORMANCE.md
在allreduce中,数据需要流转2*(n-1)次才能完成一次规约,平均到busbw就是2*(n-1)/n, 一般n比较大,就默认2倍关系就可以。
algbw = 处理的数据大小/时间 = 处理的数据大小 / (计算时间+传输延迟+处理的数据大小/real_busbw)
计算时间与sharp或者gpu本身计算能力有关,而延迟与拓扑有关
先看ring allreduce
当rank比较小时,延迟并不重要,重要的是提升带宽,当两台机器时,使用ring(两台机器tree会退化成ring)
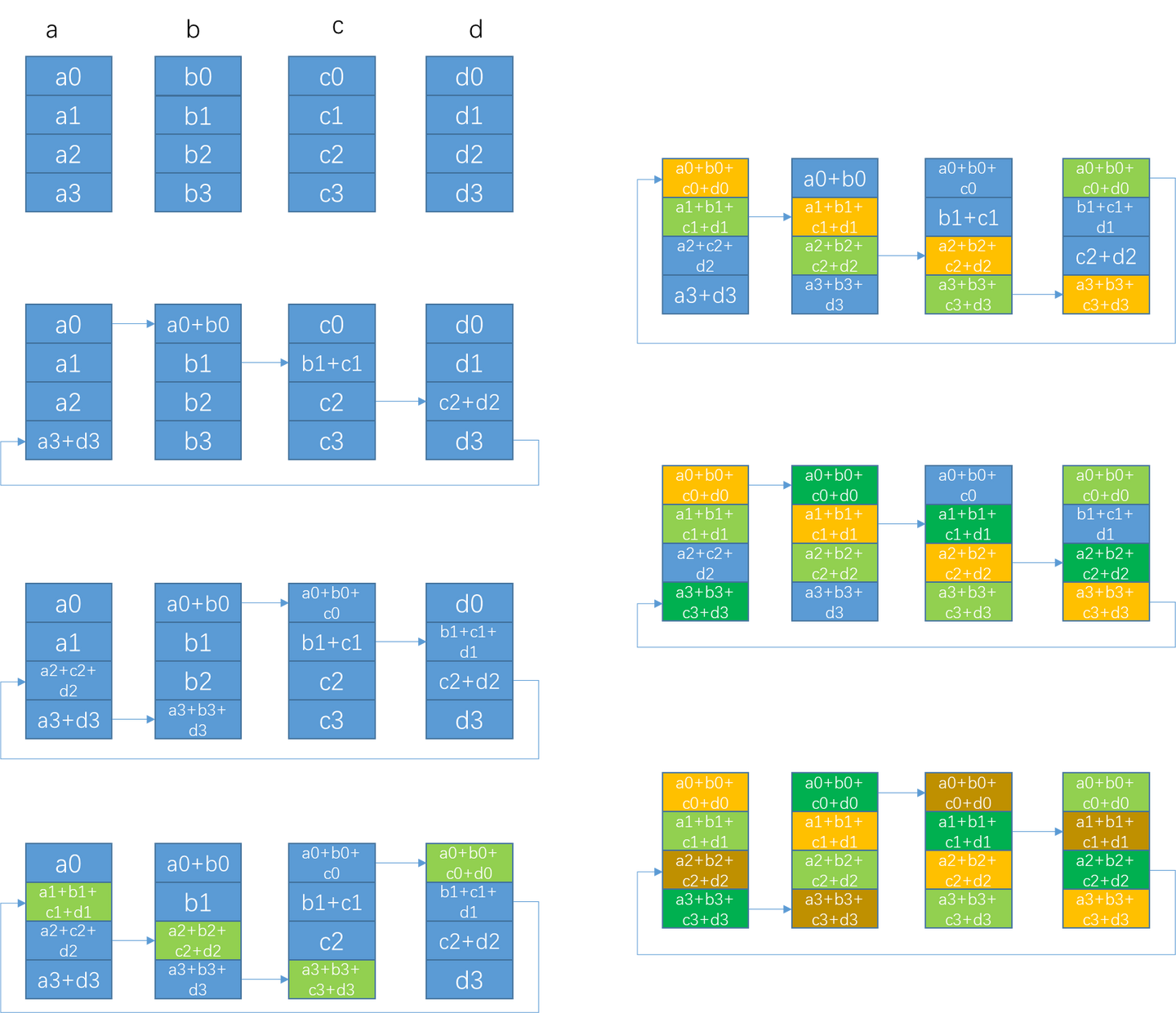
可以看出,一个数据经过一个完整的传输,一收一发就结束了reduce,机器较少忽略延迟
那么algbw = real_busbw = min(nvswitch/2, nic)
busbw = 2algbw = 2 min(nvswitch/2, nic)
实际上计算,延迟是不可忽略的,而且标称100Gb的网络,从来只能跑到95…再加上pcie延迟,经验值是需要乘0.8了。
这里有一个问题real_busbw 和 busbw。
busbw是通过algbw计算得来,并非是真实硬件的监控数据。通过监控(有一个计算rdma速率的脚本),real_busbw也就是网卡带宽差不多就是90G。nvswitch虽然强大,但是受限于水管较细的部分,也不会超常发挥。
为什么两者不一致,个人认为是allreduce公式推导的是tree reduce,ring算是特例。