SuperPoint论文及源码解读
SuperPoint论文及源码解读
- 论文解读
- 源码解读
论文:SuperPoint: Self-Supervised Interest Point Detection and Description
源码:https://github.com/magicleap/SuperPointPretrainedNetwork.git - 论文团队pytorch版
https://github.com/rpautrat/SuperPoint.git - Tensorflow版
论文解读
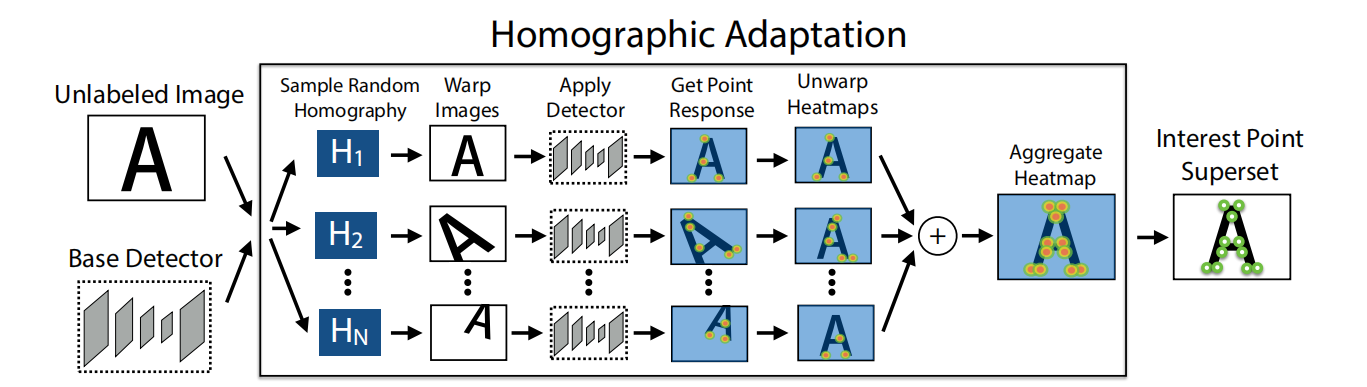
模型框架如下图,(a)、(b)只提取角点,(a)是由合成图片标记的角点(MagicPoint),相对真实图片角点不够丰富;(b)将图片进行不同缩放、旋转等单应变换(warp),使用(a)训练base detector提取角点自标注,再将所有角点变换到原图,得到SuperPoint(单指角点);©增加描述子网络联合训练。
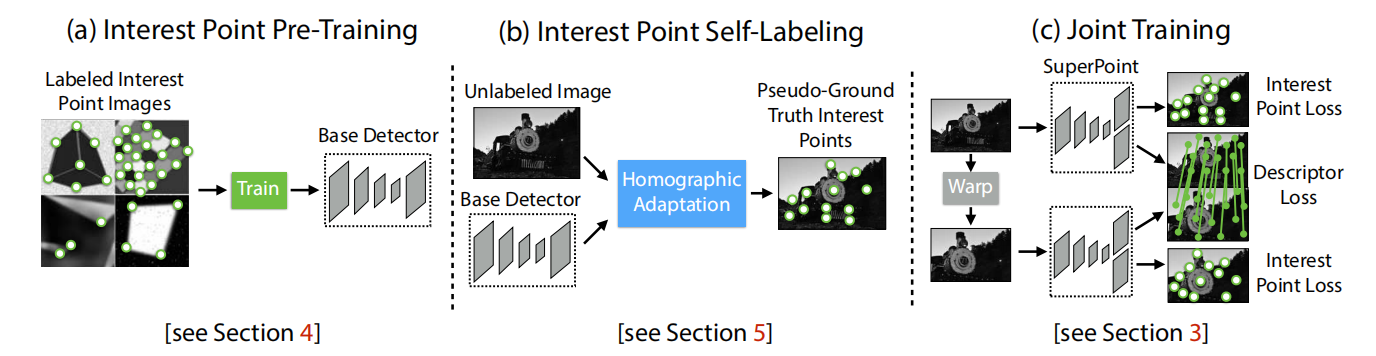
© Joint Training
模型如下图,输入为HW原始图片,输出为2个头,1个角点HW1图片,1个为HWD描述子图片,描述子维度固定为D。
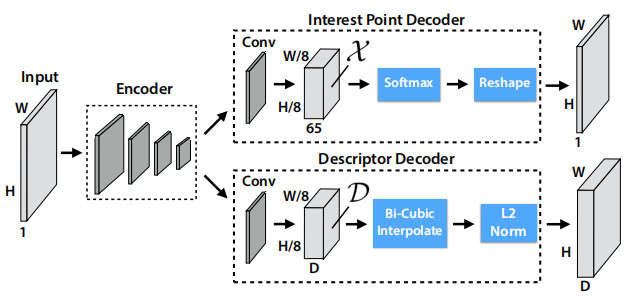
3.1 Shared Encoder
类似VGG(Very deep convo lutional networks for large-scale image recognition),使用池化层(22非重叠)和激活层降采样将图片编码为Hc = H/8 * Wc = W/8 * F维tensor,每个cell包含 8 × 8 原始像素
3.2 Interest Point Decoder
类似SegNet(SegNet: A deep convolutional encoder-decoder architecture for image segmentation),decoder为HcWc65(64-1个cell对应原图像素、1-表示cell有无特征点),减少计算量,最后通过softmax和reshape变为HW1输出
3.3 Descriptor Decoder
与Interest Point Decoder相似,变为HcWcD(描述子维度),通过Bi-cubic Interpolate插值上采样为HWD,最后使用类似UCN(Universal Correspondence Network)输出L2-normalizes的HWD描述子图片。
3.4 Loss Functions
使用合成图片已知1)图片的角点;2)通过不同变换后,变换图像的角点及匹配关系已知。训练时需要输入2张图片,每张图片可构建角点代价函数Lp,2张图片相互之间可构建描述子目标函数。同一个cell,选择最近的像素作为真值角点。
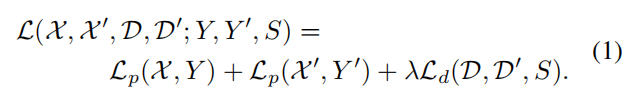
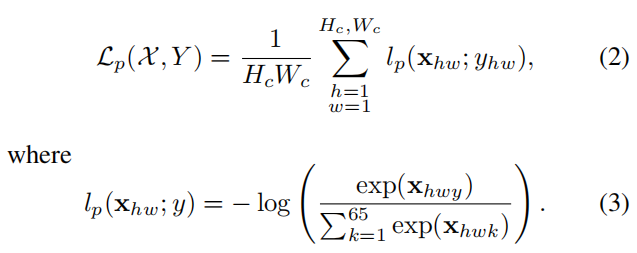
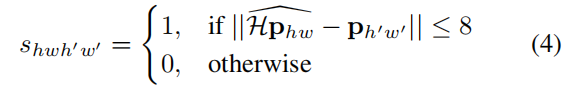
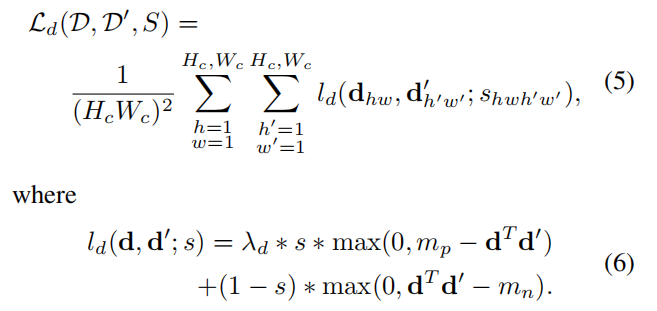
(a) Interest Point Pre-Training(只是角点)
合成以下不同形状物体,并标记角点,通过变换图像得到更多图像数据。
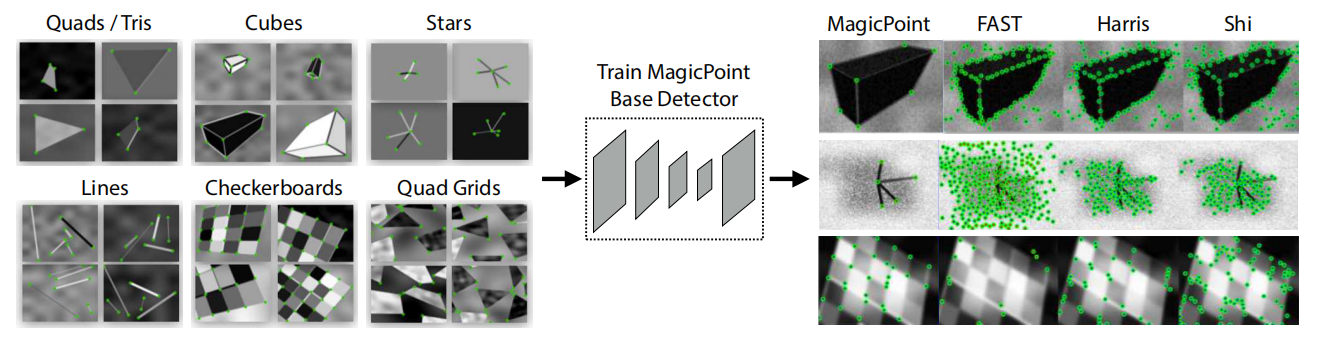
(b) Interest Point Self-Labeling(只是角点)
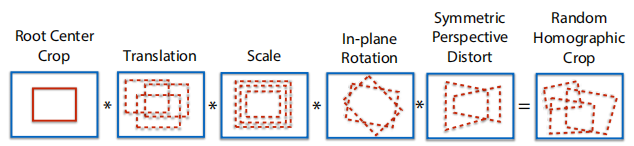
原图通过不同变换用base detector检测不同的角点,最后变换到原图,得到更多的角点(SuperPoint)