【T2I】Region-Aware Text-to-Image Generation via Hard Binding and Soft Refinement
code:
https://github.com/NJU-PCALab/RAG-Diffusion
Abstract
区域提示,或组成生成,能够实现细粒度的空间控制,在实际应用中越来越受到关注。然而,以前的方法要么引入了额外的可训练模块,因此只适用于特定的模型,要么使用注意掩模在跨注意层内的分数图上进行操作,导致当区域数量增加时控制强度有限。为了解决这些限制,我们提出了基于区域描述的区域感知文本到图像生成方法RAG。RAG将多区域生成解耦为两个子任务,一个是确保区域提示正确执行的单个区域构造(区域硬绑定),另一个是对区域进行整体细节细化(区域软细化),消除视觉边界,增强相邻交互。此外,RAG新颖地使重绘成为可能,用户可以在上一代中修改特定的不满意区域,同时保持所有其他区域不变,而无需依赖额外的油漆模型。我们的方法无需调优,并且可以应用于其他框架,作为对prompt following属性的增强。定量和定性实验表明,RAG在属性绑定和对象关系方面的性能优于以往的无调优方法。
Introduction
此外,采用更鲁棒的文本编码器,包括T5-XXL[23],已经证明能够呈现视觉文本并显着提高提示依从性
贡献:
• 本文在基于dit模型(FLUX.1-dev)的基础上提出了一种无需调优的区域感知文本到图像生成框架RAG,该框架采用了区域硬绑定和区域软细化两个新组件,实现了精确和谐的区域控制。
• RAG新颖地使图像重绘可行,允许用户修改上一代中特定的不满意区域,同时保持所有其他区域完整,而无需额外的油漆模型。
• 广泛的定性和定量实验表明,在t2iccompbench基准测试中,RAG在属性绑定、对象关系和复杂组合方面表现出比以前更优越的性能。
Related Work
Tuning-based Regional Control.
Tuning-Free Regional Control.
Method
Preliminaries
Diffusion Transformer (DiT). DiT[21]是一种将变压器作为骨干网络集成到潜在扩散模型(Latent Diffusion Model, LDM)中的新架构,已成为最近的文本到图像生成模型(如Stable Diffusion 3/3.5[8]和Flux[3])的主要选择。通过利用转换器,DiT可以有效地捕获数据中的复杂依赖项,从而生成高质量的图像。与LDM的设计理念一致,DiT也直接在潜在空间中运行,允许模型生成符合指定条件的高保真图像,同时减少计算开销。
Attention Mechanism.
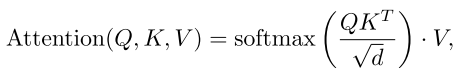
Overview of RAG
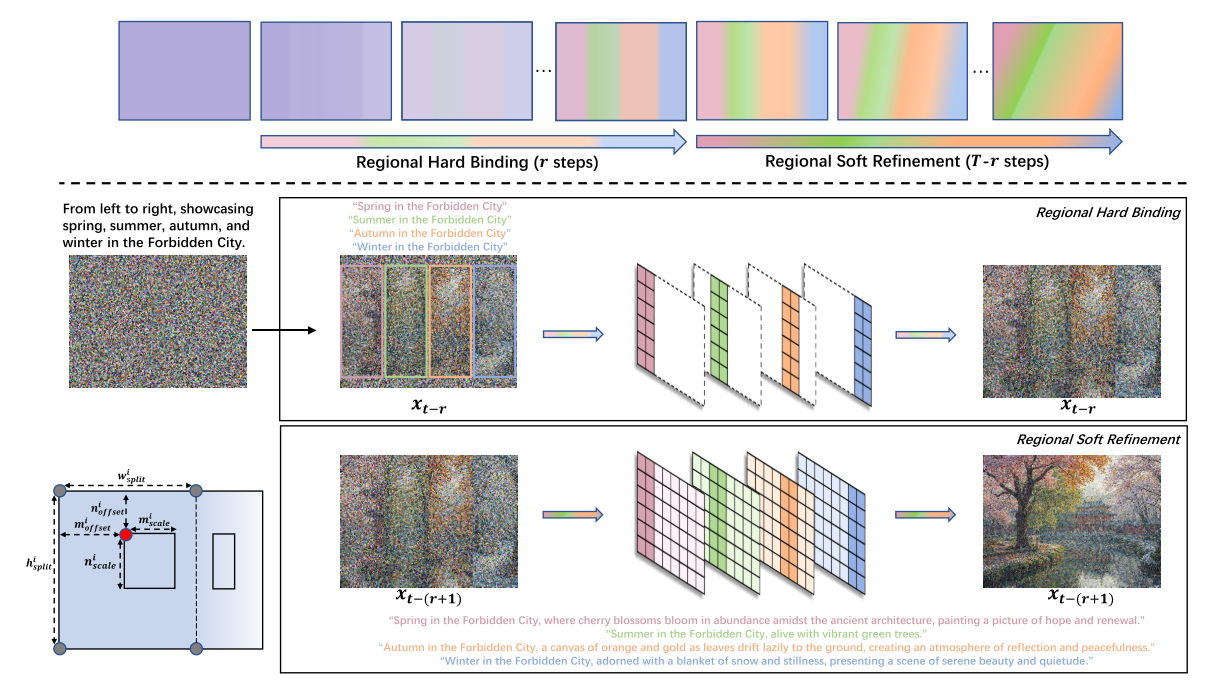
Regional Hard Binding

Regional Soft Refinement


Image Repainting

