Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack

Paper: https://arxiv.org/abs/2309.15807
文章目录
- 1. Introduction
- 2. Method
- 2.1 Latent Diffusion Architecture
- 2.2 Pretraining
- 2.3 High-Quality Alignment Data
- 2.3.1 Automatic Filtering
- 2.3.2 Human Filtering
- 2.4 Quality-Tuning
- 3. Experiments
- 3.1 Evaluation Setting
- 3.2 Results
- 3.3 Ablation Studies
- 4. Summary
1. Introduction
本文提出了quality-tuning,以有效地引导预训练模型仅生成视觉上高度吸引人的图像,同时保持对视觉概念的一般性。
本文的关键发现在于:在一个规模非常小但高度吸引人的图像数据集上进行SFT,可以显著提供图像的生成质量。
具体而言,本文在110亿图文对上首先预训练了一个latent diffusion model,然后在仅几千张精心挑选的高质量图像数据集上进行微调后,得到了Emu。
Emu和仅预训练的latent diffusion model对比,胜率达到82.9%,而与目前最为先进的SDXLv1.0相比,Emu在标准的PartiPrompts和本文的Open User Input benchmark上各自取得了68.4%和71.3%的胜率。
Quality-tuning是一个通用的策略,其对于pixel diffusion和masked generative transformer models等其他架构也一样适用。
Quality-tuning很类似与LLM中的Instruction-tuning:
- Quality-tuning和Instruction-tuning一样,可以显著提升生成模型的能力。
- Quality-tuning和Instruction-tuning一样,相较于Pretraining阶段,只需要非常少量的高质量数据即可。
- Quality-tuning和Instruction-tuning一样,不会导致其在Pretraining阶段习得的知识被遗忘。
Quality-tuning阶段的数据筛选标准是主观的,会受到各自文化的影响。本文则是遵循了摄影中的一些基本原则,包括但不限于构图、光照、色彩、有效分辨率、对焦、故事叙述的指引性等。
Emu的部分生成结果如下:

2. Method
本文将生成模型的训练分为两个阶段:
- Knowledge Learning Stage(Pretraining Stage)
- Quality-Tuning Stage(Finetuning Stage)
正如Introduction中所提,本文的关键洞察在于以下三点:
- 微调数据集可以非常小,仅需几千张图像
- 数据集的质量需要非常高,这使得数据集的完全自动化几乎不可能,需要通过人工进行标注
- 即使使用很小的微调数据集,Quality-Tuning不仅显著提高了生成图像的美感,而且没有牺牲其图文一致性
2.1 Latent Diffusion Architecture
本文设计了一个Latent Diffusion Model,可以生成1024x1024分辨率的图像,和标准的Latent Diffusion Architecture设计一致,Emu也包括一个AutoEncoder(用于将Image编码为Latent Embeddings)以及一个UNet(学习去噪过程)。
本文发现常用的4-channel AutoEncoder(AE-4)由于压缩率过高,会导致重建图像缺乏细节,而将通道数提升至16可以显著提升重建质量。

为了进一步提升重建表现,本文采用对抗损失,并对RGB图像应用一个无需学习的预处理步骤(使用傅里叶变换将输入通道维度从3提升到更大),以更好地捕捉细微结构。
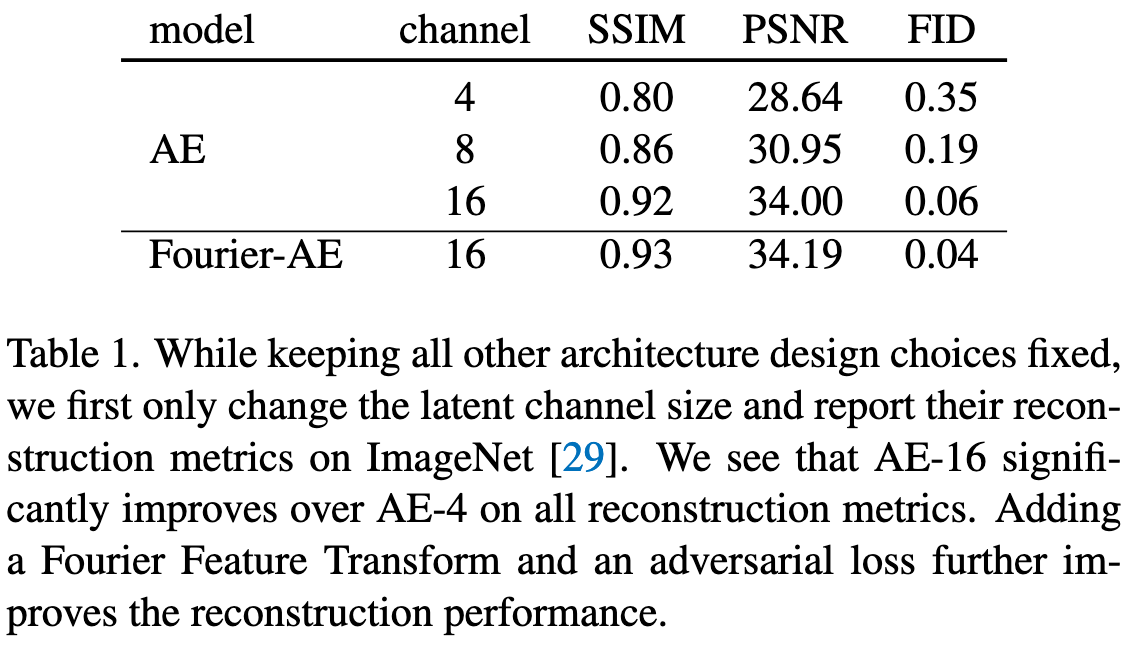
除了VAE以外,本文使用了一个训练参数量为2.8B的大型UNet,具体而言,本文提升了每个Stage中堆叠的残差模块的通道数和模块数,以获取更大的模型容量。
至于Text Encoder,本文使用了CLIP ViT-L和T5-XXL。
2.2 Pretraining
本文精心挑选了一个庞大的内部预训练数据集,包含1.1billion张图像用于进行Diffusion模型的预训练。
和SDXL类似,本文也采用了渐进式地训练策略,分辨率会逐步提升。这种渐进式训练策略使得模型可以在较低分辨率下高效学习高级语义信息,并在高分辨率下改善细节。
在预训练的最后阶段,本文还应用了0.02的噪声偏移。
2.3 High-Quality Alignment Data
2.3.1 Automatic Filtering
从数十亿图像的初始集合开始,本文首先使用一些自动过滤器将其缩减至数千万张。
这些自动过滤器包括但不限于:
- 攻击性内容筛选
- 美学评分筛选
- OCR字数筛选
- CLIP得分筛选
- 图像大小筛选
- 长宽比筛选
然后为了平衡来自不同领域和类别的图像,本文使用一个分类器(Billion-scale semi-supervised learning for image classification),对数据进行分类(例如肖像、失误、动物、风景、汽车等)。
最后,再通过一些特殊的信号,例如点赞数等,对数据进行进一步过滤,最终将数据精简到200K条。
2.3.2 Human Filtering
接下来,本文使用了two-stage的人类筛选过程去仅保留高美学度的数据。
- Stage One:在该阶段主要是培训一般标注员,以从图像库中筛选出20K张图像。该阶段的主要目标是优化召回率,确保排除可能通过自动过滤过程的中等或者低级质量的图像。
- Stage Two:在该阶段,本文请来了具有良好摄影原则理解的专家标注员。他们的任务是筛选和选择最高审美质量的图像。这一阶段,专注于优化精度,即仅选择最佳图像。

接下来简单阐述一下关于高质量图像的注释指南。
本文的假设是:遵循高质量摄影的基本原则就能产生在各种风格上更具美学价值的图像。该假设也得到了人类评估得到验证。
以下是五个主要原则:
- 构图。图像应遵循专业摄影构图的某些原则,包括“三分法则”,“深度与层次”等。负面示例可能包括视觉重量不平衡(例如当所有焦点主体集中在画面的某一侧时),或捕捉主体的角度不够吸引人,或主要主体被遮挡,或周围不重要的物体干扰主体的表现等。
- 光照。本文期望寻求具有动感的光照效果,要求曝光平衡、能够提升图像整体的质感。例如,可以在背景和主体的特定区域形成高光的来自一定角度的光线。尽量避免使用人工感强或者平淡无趣的光照,也尽量避免过暗或过曝的光线效果。
- 色彩与对比。本文偏爱色彩鲜艳且对比度强的图像,而避免使用单色图像或者整个画面被单一色彩占据的图像。
- 主体与背景。图像应在前景与背景元素之间展现出一定的层次感。背景应简洁有序,但不应过于单调或乏味。聚焦的主体必须经过有意地构图安排,确保所有关键细节清晰可见、不被遮挡。例如在人像摄影中,图像的主要主体不应超出画面边界或被遮挡。此外,前景主体的细节呈现也极为重要。
- 额外的主观评价。此外,本文还要求标注人员提供主观评价,以确保仅保留具有卓越美学质量的图像。具体方式是回答以下几个问题,例如:
- 这张图像是否传达了引人入胜的故事?
- 这张图像是否还有明显的提升空间?
- 就这一特定内容而言,这是否是你见过的最优秀的照片之一?
基于以上过滤过程,本文最终保留了2K张质量非常高的图像。随后,本文为每一张图像撰写了真实的Caption。
需要注意的是,这些手工挑选的图像有一些低于1024x1024的目标分辨率,本文会训练一个基于Imagen中提出的结构而设计的Pixel Diffusion Upsampler,在必要时,对一些图像进行上采样。
2.4 Quality-Tuning
这些视觉上令人惊叹的图像(例如本文收集的2K张图像)是一个具备相同统计数据的所有图像的一个子集。
本文的假设是:一个经过充分预训练的模型已经具备生成高度美学图像的能力,但在生成过程中没有得到适当的引导,以始终生成符合这些统计特性的图像。Quality-Tuning可以有效地将模型输出限制在一个高质量的子集中。
本文使用64的小batchsize进行微调,并使用0.1的noise-offset。需要注意的是,这里的early stopping是非常重要的,因为在小型数据集上进行长时间的微调会导致显著的过拟合以及一般性的视觉概念的退化。本文最多进行15K轮次的迭代,即使损失依然在下降,这个总的迭代次数是通过经验确定的。
3. Experiments
本文主要对比Emu和SDXLv1.0的生成效果。
3.1 Evaluation Setting
- Prompts
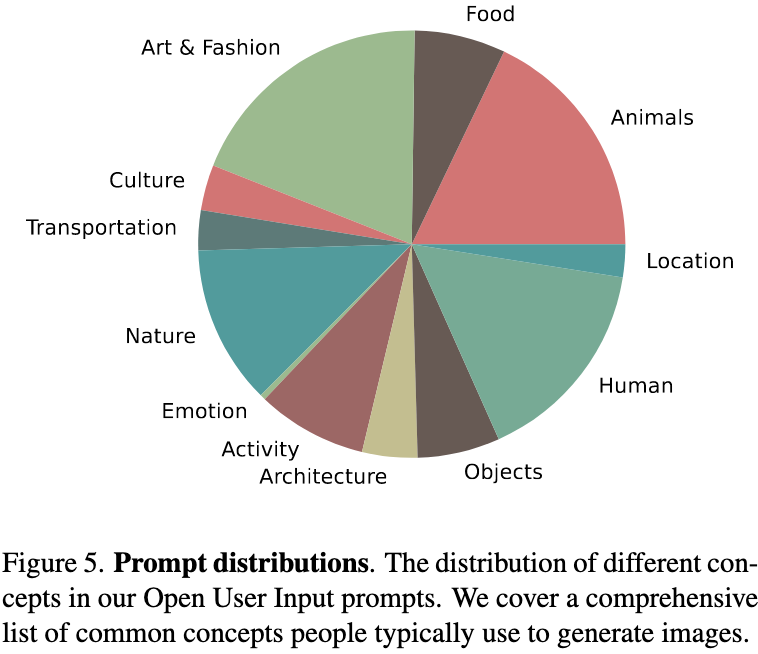
本文在两个大型提示集上进行了评估:1600个 PartiPrompts(这是文本生成图像任务中常用的基准测试集),以及本文自建的2100个Open User Input(OUI)提示集。OUI提示集基于真实世界中的用户输入,涵盖了在文本生成图像模型中广受欢迎的提示,反映了与现实用例相关的视觉概念。下图展示了OUI数据集中不同概念的分布:
这些提示经过大语言模型(LLM)改写,使其更贴近普通用户的表达方式(而不是经过精心设计的工程化提示)。
- Metrics
本文使用两种独立的评估指标:视觉吸引力和文本一致性。
视觉吸引力指的是生成图像的整体美学质量。它综合了颜色、形状、纹理和构图等多种视觉元素,以呈现令人愉悦且吸引人的外观。视觉吸引力本质上是主观的,不同人对美感的判断可能不同。因此,本文请五位标注人员对每个样本进行评分。具体来说,本文向标注人员并排展示由不同模型在相同描述下生成的两张图像 A 和 B,不显示文字描述,让标注人员根据个人感受选择更具视觉吸引力的图像,选项为“A”、“B”或“持平”。
文本一致性指的是生成图像与文字描述之间的相似程度。在此任务中,本文再次并排展示由不同模型生成的图像 A 和 B,但这次同时展示图像对应的文字描述。本文要求标注人员忽略图像的视觉吸引力,仅根据哪张图像更好地体现了文字描述来进行选择,选项为“A”、“B”、“两者皆是”或“两者皆否”,其中“两者皆是”与“两者皆否”统一视为“持平”。该任务中,每个样本对由三位标注人员进行评估。
本文不报告诸如 FID 分数等“标准”指标。正如多篇近期论文所指出的,FID 分数与人类对生成模型表现的主观评估之间并无良好相关性。
3.2 Results
- Effectiveness of Quality-Tuning
首先,本文将经过质量调优的模型 Emu 与预训练模型进行了比较。
下图展示了在质量调优前后的随机(非精挑细选)生成结果示例:

请注意其中存在一些高度美观的非写实风格图像,这也验证了本文的假设:在构建质量调优数据集时遵循一定的摄影原则,能够提升多种风格图像的美学效果。
下图则是展示了定量的对比结果:
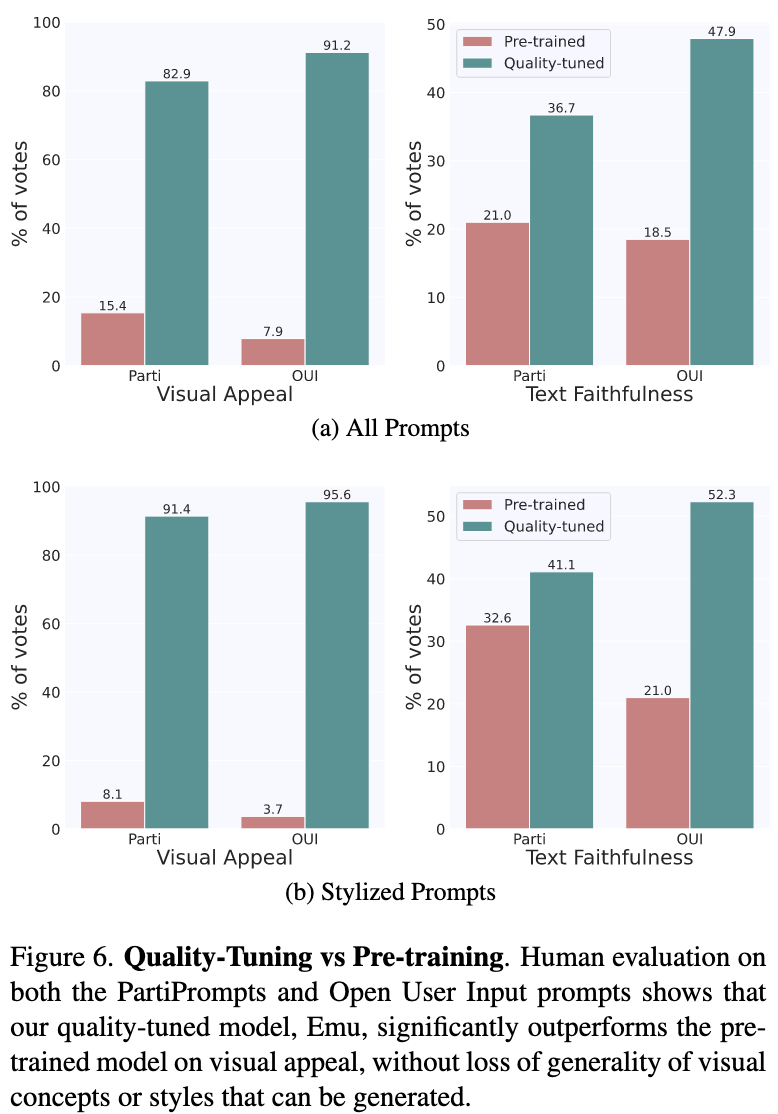
在经过Quality-Tuning后,Emu在视觉吸引力和文本一致性上都显著优于预训练模型,而在视觉吸引力上提升得更为明显,文本一致性提升的原因可能在于微调训练集中的Caption都是来自于人工编写,预训练数据集中的Captions可能包含大量噪声。
测试集中包含了各种领域各种类型的Prompts,本文没有发现Emu出现了视觉概念泛化性的下降。
本文还分析了一些非写实风格的Prompts的结果,在多种风格上,Quality-Tuning都能带来提升。
- Visual Appeal in the Context of SoTA
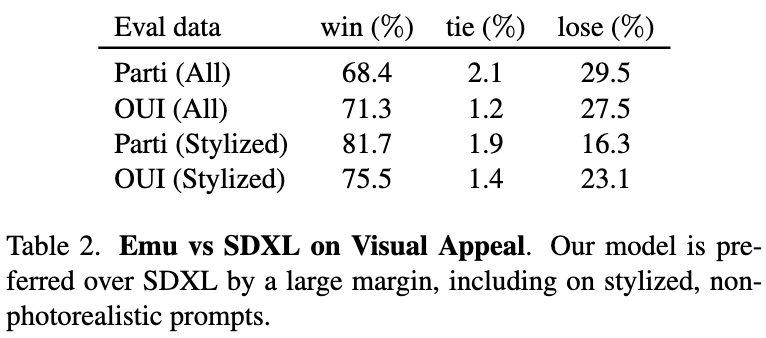
在下表中,本文对比了Emu和SDXLv1.0的视觉吸引力:
- Quality-Tuning Other Architectures
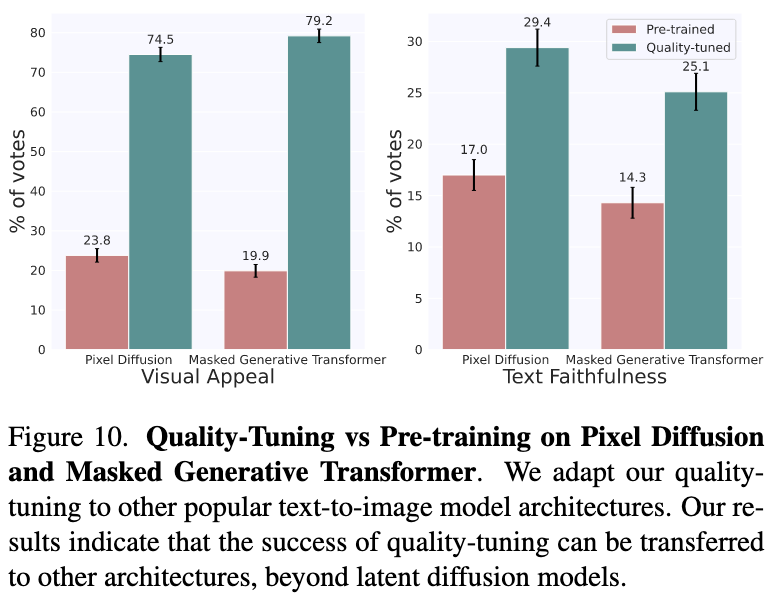
接下来,本文展示Quality-Tuning还可以应用于其他流行架构,如Pixel Diffusion Models和Masked Generative Transformer Models。
具体而言,本文重新实现和重新从头训练了一个和Imagen类似的Pixel Diffusion Model和一个和Muse类似的Masked Generative Transformer Model,然后在2K图像上对其进行Quality-Tuning。
下图展示了这两个模型在随机抽取1/3的PartiPrompts上的视觉吸引力和文本一致性:
3.3 Ablation Studies
下表重点研究了微调数据集大小对结果的影响:
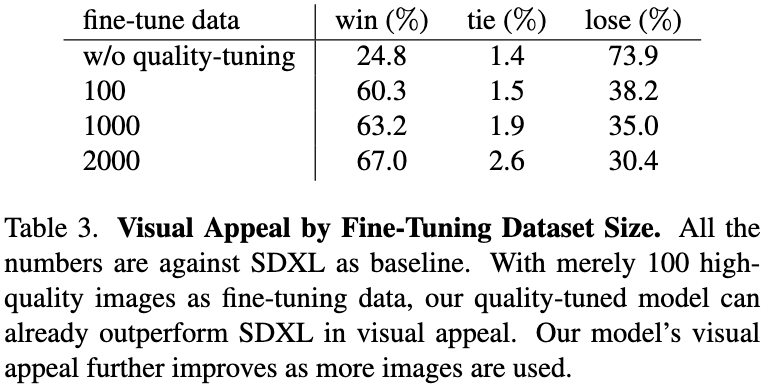
只要有100个微调图像,Emu就已经可以被引导生成视觉上吸引人的图像,与SDXL相比,胜率也从24.8%跃升至60%。
4. Summary
这篇论文的主要内容可以总结如下:
- 问题定义
论文旨在解决文本到图像模型在生成高美学质量图像方面的挑战。尽管预训练的模型能够从文本生成各种视觉概念的图像,但这些模型在生成高度美学的图像方面经常面临挑战。
- 方法提出
提出了一种名为Quality-Tuning的方法,通过使用少量高质量的图像对预训练模型进行微调,以提高生成图像的视觉效果。
- 模型架构
使用了一个潜在扩散模型(Latent Diffusion Model, LDM)作为基础架构,并对其进行了优化以提高图像质量。
- 数据筛选
通过自动和人工筛选过程,从大量图像中精选出少量高质量的图像用于微调。
- 实验验证
通过与预训练模型和现有最先进模型SDXLv1.0的比较,验证了Quality-Tuning模型在视觉吸引力和文本一致性方面的有效性。展示了Quality-Tuning方法在不同模型架构(包括Pixel Diffusion Models和Masked Generative Transformer Models)上的通用性。
-
主要贡献
- 构建了一个显著优于现有模型的高质量图像合成模型Emu。
- 强调微调配方对于提高文本到图像模型美学对齐的重要性。
- 证明质量调整方法可以提升不同架构的模型性能。
-
未来方向
论文指出了一些可以进一步探索的方向,包括更大规模的数据集、多样性与公平性、自动化图像筛选等。