[推荐]AI驱动的知识图谱生成器(AI Powered Knowledge Graph Generator)
网址:https://github.com/robert-mcdermott/ai-knowledge-graph#
一、介绍
简介:以非结构化文本文档为输入,使用您选择的LLM以主语-谓语-宾语 (SPO) 三元组的形式提取知识,并将这些关系可视化为交互式知识图谱
特点:可与任何 OpenAI 兼容 API 端点配合使用
二、项目的部署
1、从github下载项目
git clone https://github.com/robert-mcdermott/ai-knowledge-graph.git2、配置环境
cd ai-knowledge-graphpip install -r requirements.txt3、修改配置文件
此处用deepseek的api作示例
deepseek-api官网:DeepSeek
修改ai-knowledge-graph/config.toml
[llm]
model = "deepseek-chat" #此处修改为deepseek-chat
#model = "claude-3.5-sonnet-v2"
#model = "gpt4o"
#model = "llama3-2-90b-instruct-v1:0"
api_key = "sk-1234" # 将此处的api替换为自己真实的api-key
#base_url = "http://localhost:11434/v1/chat/completions"
#base_url = "http://localhost:4000/v1/chat/completions"
base_url ="https://api.deepseek.com/chat/completions"
max_tokens = 8192
#max_tokens = 4096
temperature = 0.8也可使用部署在本机的模型进行使用,如ollama+deepseek模型,具体操作请自我探索。
4、启动项目
在启动项目前需要准备一段文字,保存为txt.
python generate-graph.py --input /content/input.txt --output knowledge_graph.html示例数据:
主题:人工智能技术
人工智能(AI)是以机器学习、深度学习和自然语言处理为核心技术的计算机科学分支。机器学习通过算法使计算机从数据中学习规律,代表性方法包括监督学习(如线性回归)和无监督学习(如聚类)。深度学习是机器学习的分支,依赖神经网络模型(如CNN、RNN),由杰弗里·辛顿等学者推动发展。
自然语言处理(NLP)使机器能理解人类语言,关键技术包括词嵌入(Word2Vec)和Transformer架构(如BERT)。知名AI框架有TensorFlow(由Google开发)和PyTorch(由Meta开发)。AI广泛应用于医疗(如影像诊断)、金融(如风控模型)和自动驾驶(如Tesla Autopilot)等领域。
伦理问题如数据隐私和算法偏见是当前AI发展的挑战,欧盟通过《人工智能法案》对其进行规范。数据结果:
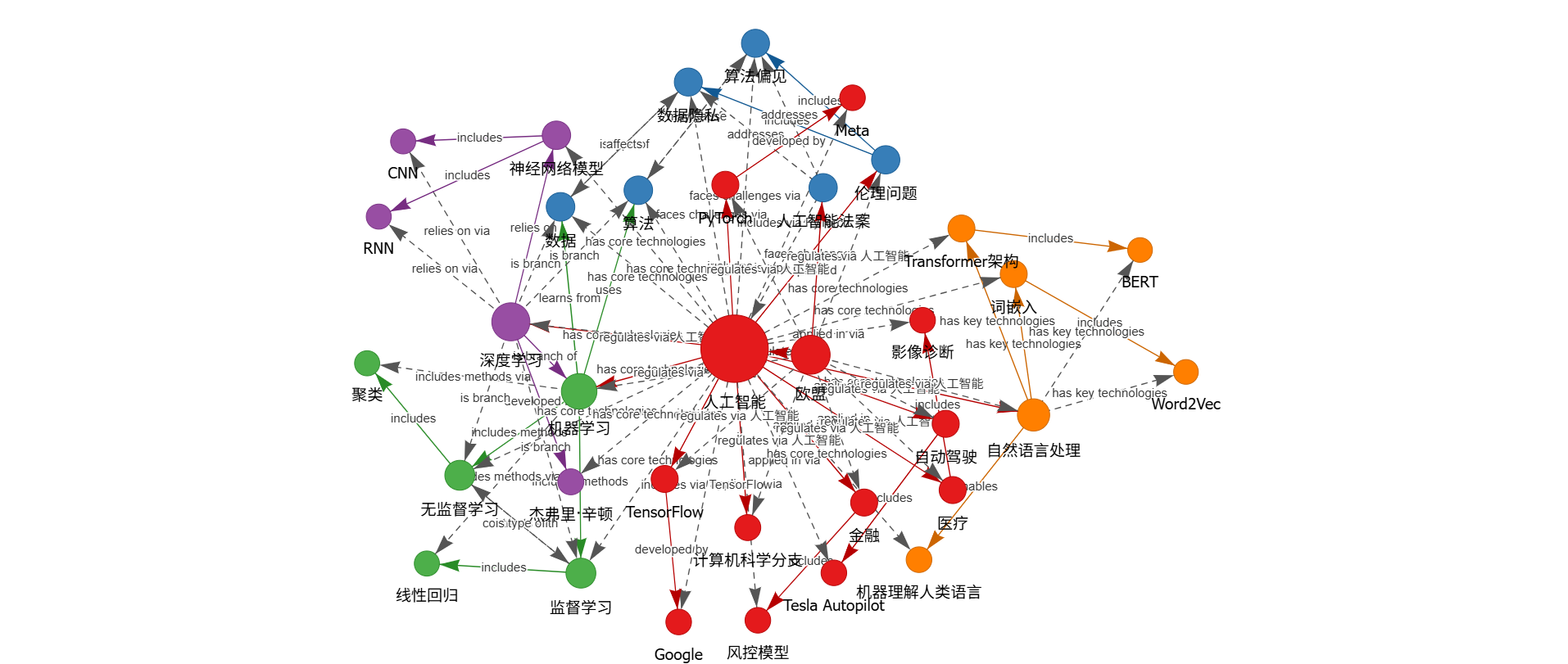
执行完命令会生成一个html文件,使用浏览器打开即可进行交互式操作。
三、项目的简单分析(本人较菜勿喷)
├── config.toml # 系统主配置文件
├── generate-graph.py # 直接运行时作为脚本的入口点
├── pyproject.toml
├── requirements.txt # 供'pip'用户使用的Python依赖项
├── uv.lock # 供'uv'用户使用的Python依赖项锁定文件
└── src/
├── generate_graph.py # 作为模块运行时的主入口脚本
└── knowledge_graph/
├── __init__.py
├── config.py
├── entity_standardization.py # 实体标准化算法模块
├── llm.py # 大语言模型交互与响应处理模块
├── main.py # 主程序流程与调度模块
├── prompts.py # 集中管理的LLM提示词库
├── text_utils.py # 文本处理和分块工具集
├── visualization.py # 知识图谱可视化生成器
└── templates/ # 可视化HTML模板目录
└── graph_template.html # 交互式图谱基础模板`entity_standardization.py`文件
主要进行实体标准化 、实体关系推理,和其他一些辅助操作。比如使用LLM解析实体、对谓词进行限制、以及基于规则的关系推理等。
`llm.py `文件
主要进行和大模型的交互和对input文件的简单处理。
`text_utils.py `文件
主要是对txt文件进行分块操作,处理txt为chunks,方便llm进行理解和分析。
`visualization.py`文件
主要是对分析出的结果做可视化操作。
`prompts.py`文件
主要通过不同阶段的提示词进行对实体和关系进行不断的优化。
四、prompt解析(对prompts.py解析)
阶段1:主提取提示词
系统提示词
-
role:知识提取和知识图谱生成的专家AI系统
-
skill:识别一致的实体引用和有意义的文本关系
-
output:所有关系谓词(predicate)不得超过3个单词(最好是1-2个单词)
用户提示词
-
target:从文本中识别主语-谓语-宾语(S-P-O)关系
-
rule:
-
实体一致性:对同一实体使用统一命名(如"John Smith"的各种变体统一为标准形式)
-
原子性术语:保持术语最小化,不合并多个概念
-
代词消解:将代词替换为实际指代的实体
-
成对关系:为每个有意义的实体对创建三元组
-
谓词限制:严格保持谓词1-3个单词
-
术语标准化:对同一概念的不同表达使用最常用形式
-
大小写处理:所有文本转为小写
-
- output:仅输出JSON格式的三元组数组
阶段2:实体标准化提示词
系统提示词
-
role:实体解析和知识表示专家
-
task:标准化知识图谱中的实体名称以确保一致性
用户提示词
-
input:实体名称列表(可能包含同一实体的不同表达形式)
-
rule:
-
识别指向同一实体的变体名称(如"AI"和"artificial intelligence")
-
为标准名称选择最完整或最常用的形式
-
仅对需要标准化的实体进行分组
-
-
output:
-
JSON格式,键为标准名称,值为所有变体名称的数组
-
阶段3:社区关系推理提示词
系统提示词
-
role:知识表示和推理专家
-
task:推断知识图谱中不连接实体间的合理关系
用户提示词生成函数
-
input:
-
两个不连接社区的实体列表
-
涉及这些实体的现有关系(上下文)
-
-
rule:
-
仅推断高度合理的关系(避免猜测)
-
谓词严格限制为1-3个单词(如"invented by"、"located in")
-
避免自引用(subject ≠ object)
-
-
output:
-
JSON数组,每个对象为三元组(subject-predicate-object)
-
阶段4:社区内关系推理提示词
系统提示词
-
role:知识表示和推理专家
-
task:推断语义相关但未直接连接的实体间关系
用户提示词生成函数
-
input:
-
可能相关的实体对列表(如共享词汇或语义相似)
-
涉及这些实体的现有关系(上下文)
-
-
rule:
-
基于语义相似性推断关系(如"capitalism"和"capitalist economy")
-
谓词严格限制为1-3个单词(如"type of"、"related to")
-
避免自引用(subject ≠ object)
-
-
output:
-
JSON数组,每个对象为三元组(subject-predicate-object)
-
五、什么是提示词(prompt)
prompt,简单的理解它是给 AI 模型的指令。
任何你希望解决的问题通过文字形式表达出来,作为Prompt传递给AI模型(在ChatGPT等GPT产品中目前是文字形式,未来可能有图像,语音,视频等多形式),AI 模型会基于 prompt 所提供的信息,生成对应的文本、图片甚至视频等信息。
比如,在 ChatGPT 里最下方的对话框Send a message... 处,这里就是我们输入Prompt的位置,所输入的内容就是Prompt。
提示词特点
1)清晰
清晰的提示词能让 ChatGPT 更准确地理解用户的问题和需求,从而提供更精确的答案和建议。模糊或含糊不清的提示词可能导致AI理解错误或给出不相关的回答。
✅ 正面例子:如何提高英语口语水平?(这个提示词明确表达了用户想了解的信息,即提高英语口语的方法。)
❌ 反面例子:我怎么学英语啊?(这个提示词模糊,没有明确指出是要提高哪方面的英语能力,如听力、口语、阅读还是写作。)
2)聚焦
聚焦的提示词有助于ChatGPT快速定位用户的需求,从而提供更具针对性的回答。如果提示词包含多个问题或太过宽泛,AI可能无法全面解答,或给出过于笼统的回应。
✅ 正面例子:哪些因素会影响房价?(这个提示词明确了关注点,即房价的影响因素。)
❌ 反面例子:房子怎么样?(这个提示词过于宽泛,没有明确关注的方面,如房价、地理位置、建筑质量等。)
3)相关
相关的提示词能确保AI提供的信息和建议与用户的需求密切相关,提高用户满意度。不相关的提示词可能导致ChatGPT给出与用户需求无关的回答,浪费时间和资源。
✅ 正面例子:如何有效管理时间?(这个提示词与提高时间管理能力密切相关,有助于获得实用的建议。)
❌ 反面例子:我今天好累,怎么办?(这个提示词与实际问题关联不大,可能导致AI给出与用户需求无关的回答。)(摘自下面的推荐课程)
注 :优秀的提示词能让大模型的回答上一个台阶
提示词推荐课程 推荐课程 :https://www.datawhale.cn/learn/summary/1