【MySQL从入门到精通】之基础概念详解
MySQL 基础概念详解
- MySQL 基础概念详解
- 什么是数据库?
- 1. 客户端与服务端架构
- 2. 数据存储位置
- 3. 数据库 vs 文件存储
- 主流数据库概览
- 1. 关系型数据库
- MySQL
- PostgreSQL
- Oracle Database
- Microsoft SQL Server
- 2. NoSQL 数据库
- MongoDB
- Redis
- Cassandra
- 3. 云原生数据库
- Amazon Aurora
- Google Cloud Spanner
- 4. NewSQL 数据库
- TiDB
- CockroachDB
- 5. 数据库选择建议
- 总结
- 数据库与表的创建本质
- 1. 创建数据库
- 2. 数据库初始文件
- 3. 创建表
- 关系图
- MySQL 的逻辑存储
- 示例:学生表
- 1. 创建表
- 2. 插入数据
- 3. 查询数据
- MySQL 架构概述
- 存储引擎与查询处理
- 查询处理器
- 存储引擎
- 概念
- 常用存储引擎
- InnoDB
- MyISAM
- 实验:对比存储引擎文件
- 常用 SQL 语句
- 总结
MySQL 基础概念详解
MySQL 是一个功能强大的开源关系型数据库,广泛应用于各种应用场景。本文从数据库的基本概念入手,逐步介绍 MySQL 的架构、存储引擎及常用 SQL 语句,适合初学者快速入门。
目录
- MySQL 基础概念详解
- 什么是数据库?
- 1. 客户端与服务端架构
- 2. 数据存储位置
- 3. 数据库 vs 文件存储
- 主流数据库概览
- 1. 关系型数据库
- MySQL
- PostgreSQL
- Oracle Database
- Microsoft SQL Server
- 2. NoSQL 数据库
- MongoDB
- Redis
- Cassandra
- 3. 云原生数据库
- Amazon Aurora
- Google Cloud Spanner
- 4. NewSQL 数据库
- TiDB
- CockroachDB
- 5. 数据库选择建议
- 总结
- 数据库与表的创建本质
- 1. 创建数据库
- 2. 数据库初始文件
- 3. 创建表
- 关系图
- MySQL 的逻辑存储
- 示例:学生表
- 1. 创建表
- 2. 插入数据
- 3. 查询数据
- MySQL 架构概述
- 存储引擎与查询处理
- 查询处理器
- 存储引擎
- 概念
- 常用存储引擎
- InnoDB
- MyISAM
- 实验:对比存储引擎文件
- 常用 SQL 语句
- 总结
什么是数据库?
数据库是按照特定结构组织、存储和管理数据的一套系统,通常存储在内存或磁盘中。以下是数据库的核心要点:
1. 客户端与服务端架构
MySQL 采用 C/S(客户端/服务端)架构:
- 服务端(mysqld):负责数据存储、查询处理、事务管理、并发控制等核心功能。
- 客户端(mysql):提供用户交互接口,发送 SQL 查询到服务端并展示结果。
在 Linux 系统中,安装 MySQL 后会启动两个进程:
mysqld:服务端进程,管理数据存储和操作。mysql:客户端进程,用户通过它与数据库交互。

MySQL 的网络服务架构如下:

2. 数据存储位置
MySQL 数据默认存储在磁盘的特定目录,通常为 /var/lib/mysql。你可以在 MySQL 配置文件(如 /etc/my.cnf)中查看或修改数据存储路径。
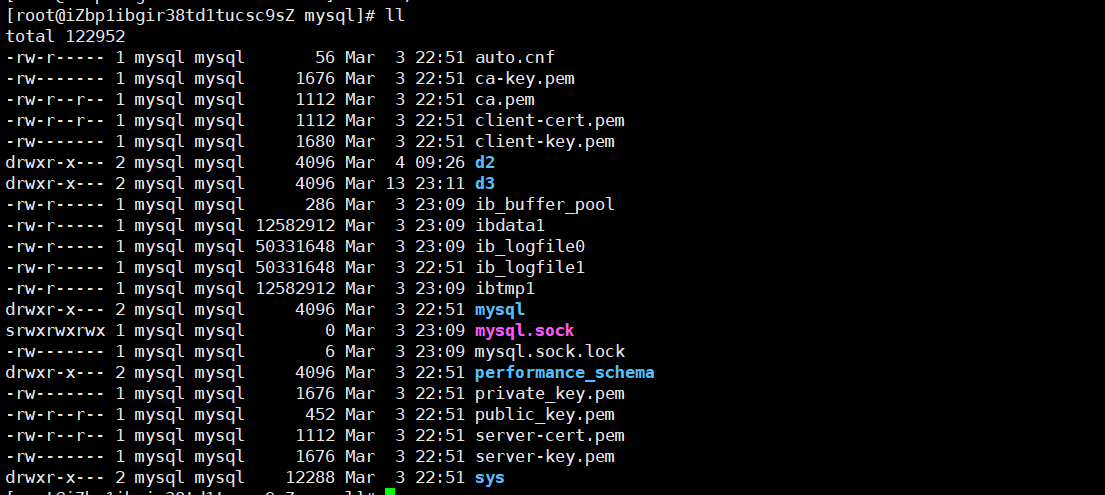
3. 数据库 vs 文件存储
相比直接使用文件存储数据,MySQL 有以下优势:
- 简化操作:无需手动编写查询逻辑,程序员只需通过 SQL 语句操作数据。
- 高效管理:提供事务支持、索引优化和并发控制,远超文件系统。
- 标准接口:SQL 语句作为统一接口,简化开发和维护。
提示
数据库通过结构化的存储和标准化的操作接口,大幅提升数据管理的效率和可靠性。
主流数据库概览
以下是常见数据库的分类和特点,涵盖关系型、NoSQL、云原生和 NewSQL 数据库。
1. 关系型数据库
MySQL
- 类型:开源关系型数据库
- 特点:
- 轻量级,易于部署,适合中小型应用。
- 支持事务(ACID)、主从复制和分区表。
- 默认存储引擎 InnoDB 支持行级锁和外键。
- 适用场景:Web 应用、电商平台、内容管理系统(CMS)。
- 代表用户:Facebook、Twitter、Airbnb。
- 缺点:复杂查询性能较弱,集群扩展性有限。
PostgreSQL
- 类型:开源关系型数据库
- 特点:
- 支持高级功能,如 JSON 数据类型、全文搜索和 GIS 地理数据。
- 事务一致性高,严格遵循 SQL 标准。
- 支持自定义函数和存储过程(PL/pgSQL)。
- 适用场景:复杂查询、GIS 应用、金融系统。
- 代表用户:Apple、Reddit、Instagram。
- 缺点:高并发写入性能略低于 MySQL。
Oracle Database
- 类型:商业关系型数据库
- 特点:
- 企业级功能:高可用性(RAC)、数据仓库、分区表。
- 支持 PL/SQL 编程,适合复杂业务逻辑。
- 强大的 OLTP(联机事务处理)性能。
- 适用场景:大型企业 ERP、银行核心系统、电信计费。
- 缺点:成本高,学习曲线陡峭。
Microsoft SQL Server
- 类型:商业关系型数据库
- 特点:
- 深度集成 Windows 生态,支持 C# 等开发语言。
- 提供 BI 工具(SSIS、SSAS、SSRS)。
- 支持内存优化表(In-Memory OLTP)。
- 适用场景:企业级 Windows 应用、数据分析。
- 缺点:仅支持 Windows/Linux 部署,扩展性受限。
2. NoSQL 数据库
MongoDB
- 类型:文档型数据库
- 特点:
- 数据以 BSON 格式(类似 JSON)存储,模式灵活。
- 支持二级索引、聚合管道和地理空间查询。
- 分片集群支持横向扩展。
- 适用场景:日志存储、实时分析、内容管理。
- 代表用户:eBay、Adobe、Forbes.
Redis
- 类型:内存键值数据库
- 特点:
- 数据存储在内存,读写性能极高(10 万+ QPS)。
- 支持多种数据类型:字符串、哈希、列表、集合、有序集合。
- 提供持久化(RDB/AOF)、发布/订阅和 Lua 脚本。
- 适用场景:缓存、会话管理、排行榜、消息队列。
- 代表用户:Twitter、GitHub、StackOverflow.
Cassandra
- 类型:宽列存储数据库
- 特点:
- 分布式架构,无单点故障,支持跨数据中心复制。
- 高写入吞吐量(百万级/秒),适合时间序列数据。
- 数据模型灵活,支持动态列。
- 适用场景:物联网(IoT)、日志存储、实时推荐系统。
- 代表用户:Netflix、Apple、Instagram.
3. 云原生数据库
Amazon Aurora
- 类型:云原生关系型数据库(兼容 MySQL/PostgreSQL)
- 特点:
- 存储与计算分离,自动扩展至 128TB。
- 性能是 MySQL 的 5 倍,支持全球数据库(多区域复制)。
- 按需付费,免硬件维护。
- 适用场景:云上高可用 Web 应用、企业级 SaaS.
Google Cloud Spanner
- 类型:全球分布式关系型数据库
- 特点:
- 强一致性 + 水平扩展,支持全球级事务。
- 无需分片,自动负载均衡。
- 兼容 SQL 标准,支持 OLTP 和 OLAP.
- 适用场景:跨国金融系统、实时库存管理。
- 缺点:成本较高,适合大型企业。
4. NewSQL 数据库
TiDB
- 类型:分布式 HTAP 数据库
- 特点:
- 兼容 MySQL 协议,支持混合事务/分析处理(HTAP)。
- 自动水平扩展,强一致性(Raft 协议)。
- 内置 TiSpark 组件,对接 Hadoop 生态。
- 适用场景:高并发 OLTP、实时数据分析。
CockroachDB
- 类型:分布式关系型数据库
- 特点:
- 兼容 PostgreSQL 协议,支持全球分布式部署。
- 自动数据分片、多副本冗余,抗区域故障。
- 提供 Serializable 隔离级别的事务。
- 适用场景:全球化应用、多活架构。
5. 数据库选择建议
| 需求场景 | 推荐数据库 |
|---|---|
| 传统 Web 应用 | MySQL、PostgreSQL |
| 高并发缓存 | Redis |
| 灵活文档存储 | MongoDB |
| 企业级复杂事务 | Oracle、SQL Server |
| 全球化分布式系统 | Google Cloud Spanner、CockroachDB |
| 实时分析 + 事务混合负载 | TiDB、Amazon Aurora |
总结
- 关系型数据库:适合结构化数据和强一致性场景,如金融系统。
- NoSQL 数据库:适合半结构化数据和高扩展性需求,如社交网络。
- 云原生数据库:适合弹性扩展、免运维的云上应用。
- NewSQL 数据库:结合 SQL 和 NoSQL 优势,适合分布式混合负载。
数据库与表的创建本质
1. 创建数据库
执行创建数据库的 SQL 语句(如 CREATE DATABASE dbname;)时,MySQL 会在数据目录(datadir,默认 /var/lib/mysql)下新建一个子目录,表示新数据库。

2. 数据库初始文件
新数据库目录初始包含一个 .opt 文件,存储默认字符集和排序规则。例如:
default-character-set=utf8
default-collation=utf8_general_ci
- 字符集:
utf8,用于存储和处理字符串。 - 排序规则:
utf8_general_ci,表示大小写不敏感(ci为 case-insensitive),如A和a在比较时视为相同。

3. 创建表
创建表(如 CREATE TABLE tablename ...)会在数据库目录下生成表相关的文件(通常为二进制格式,无法直接读取)。

提示
数据库和表的创建本质是对文件系统的操作,由mysqld服务端自动完成,开发者无需关心底层细节。
关系图
数据库、服务端、客户端和表之间的关系如下:
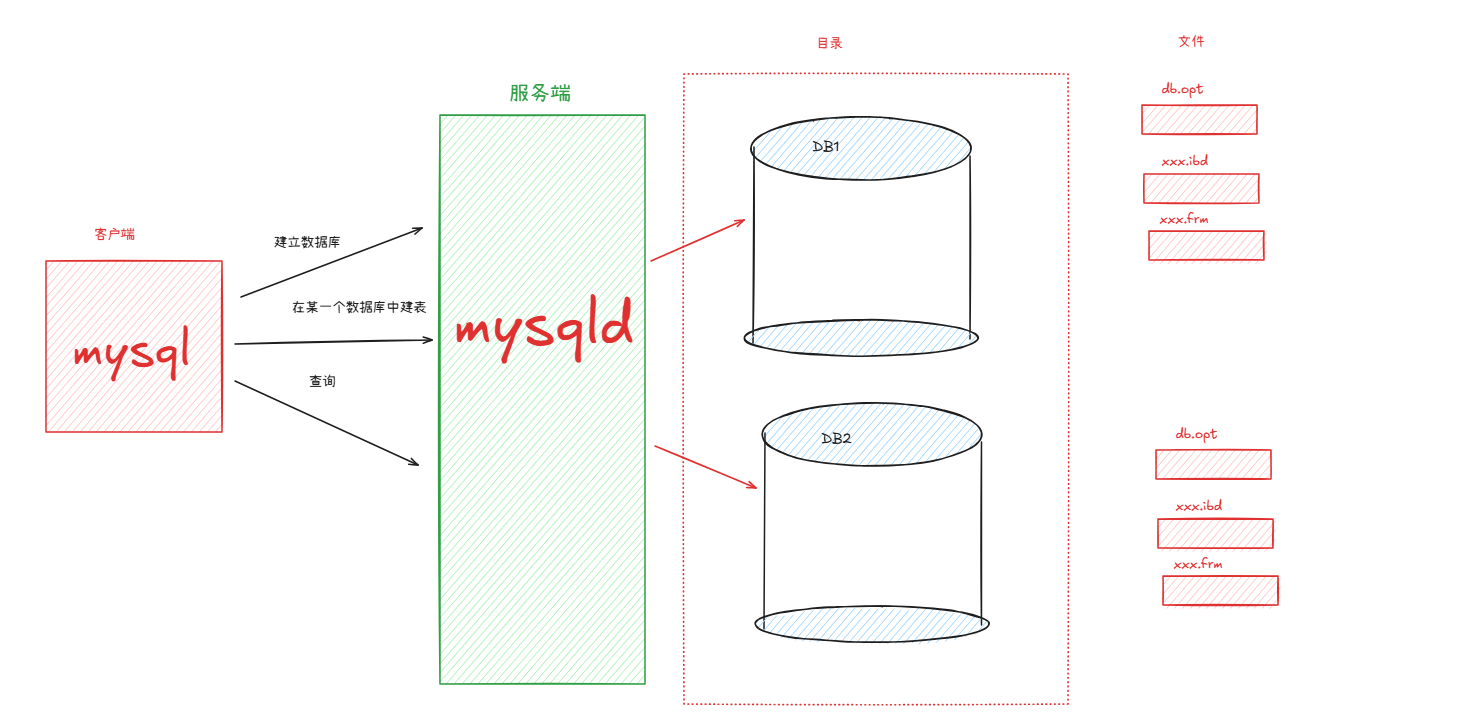
MySQL 的逻辑存储
MySQL 以行列式结构(表)呈现数据,开发者通过 SQL 操作表,而实际存储由服务end管理。
示例:学生表
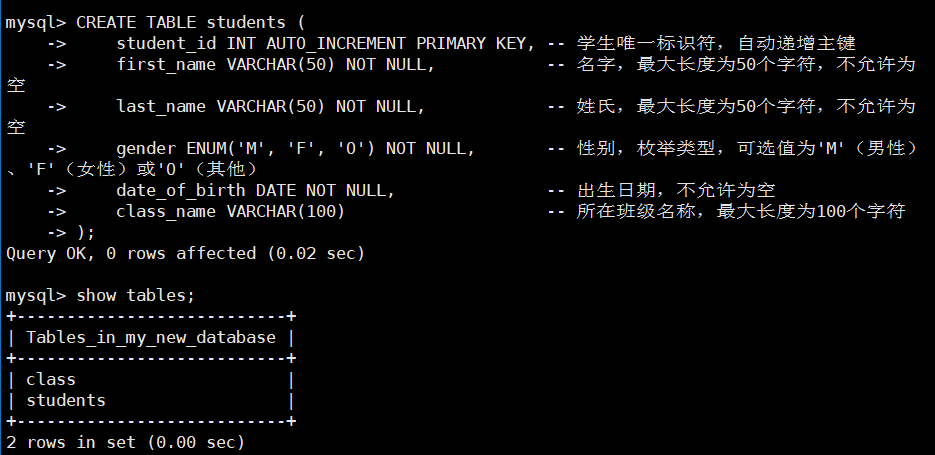
1. 创建表
CREATE TABLE students (
student_id INT AUTO_INCREMENT PRIMARY KEY, -- 学生唯一标识,自动递增主键
first_name VARCHAR(50) NOT NULL, -- 名字,最长 50 字符,非空
last_name VARCHAR(50) NOT NULL, -- 姓氏,最长 50 字符,非空
gender ENUM('M', 'F', 'O') NOT NULL, -- 性别,枚举类型(M/F/O),非空
date_of_birth DATE NOT NULL, -- 出生日期,非空
class_name VARCHAR(100) -- 班级,最长 100 字符
);
2. 插入数据
INSERT INTO students (first_name, last_name, gender, date_of_birth, class_name) VALUES
('张', '三', 'M', '2005-08-15', '高一A班'),
('李', '四', 'F', '2004-12-23', '高二B班'),
('王', '五', 'M', '2006-03-17', '高三C班');
3. 查询数据
SELECT * FROM students;
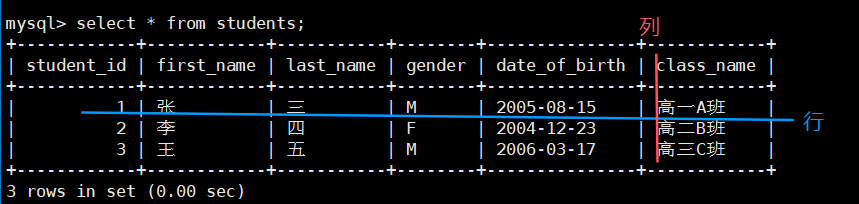
提示
用户看到的是逻辑上的行列结构,底层存储(如文件格式)由mysqld管理,开发者无需关心。
MySQL 架构概述
MySQL 采用模块化架构,分为以下层次:
- 应用层:提供客户端、API 等与 MySQL 交互的方式。
- 查询处理器:解析、优化和执行 SQL 语句。
- 存储引擎层:管理数据的存储和访问方式。
- 数据存储层:负责数据持久化和高效存取。
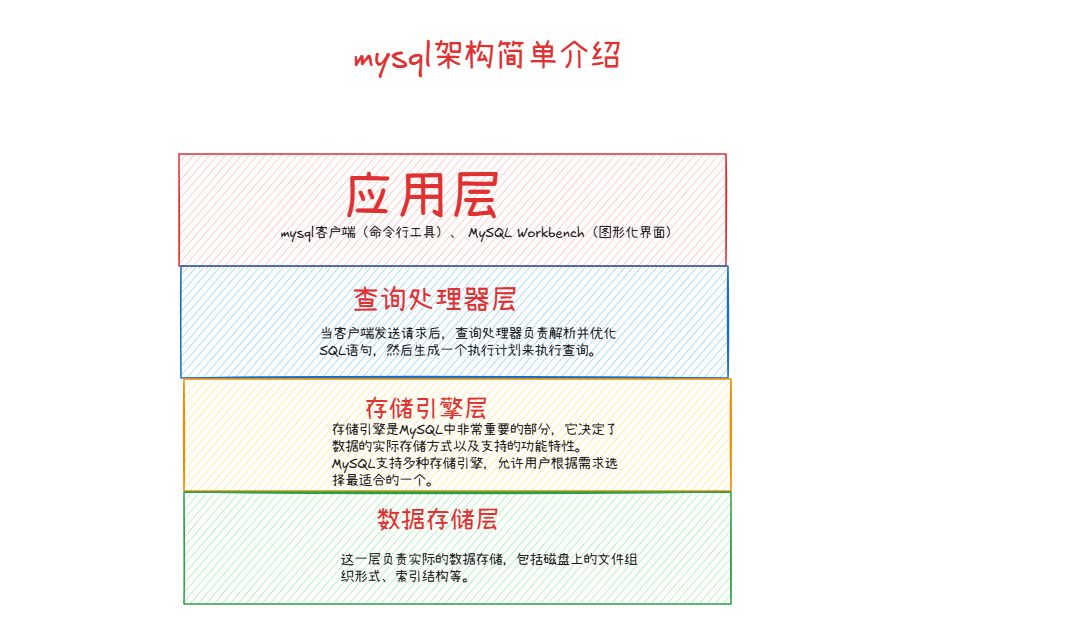
存储引擎与查询处理
查询处理器
查询处理器负责解析、优化和执行 SQL 语句,包含以下模块:
-
解析器(Parser)
- 解析 SQL 语句,检查语法是否正确。若有错误,直接返回错误信息。

-
预处理器(Preprocessor)
- 验证表名、列名等对象是否存在,以及用户是否具有访问权限,确保语句逻辑上可执行。
-
查询优化器(Optimizer)
- 分析多种执行路径,选择最优计划(如选择索引或优化表连接顺序)。
-
执行引擎(Execution Engine)
- 根据优化后的计划,从存储引擎检索或修改数据。
实验:验证查询优化器
-
创建表
t1:CREATE TABLE t1 ( id INT AUTO_INCREMENT PRIMARY KEY, -- 唯一标识,自动递增主键 name VARCHAR(100) NOT NULL, -- 名称,最长 100 字符,非空 description TEXT -- 描述,文本类型 ); -
查看建表语句:
SHOW CREATE TABLE t1;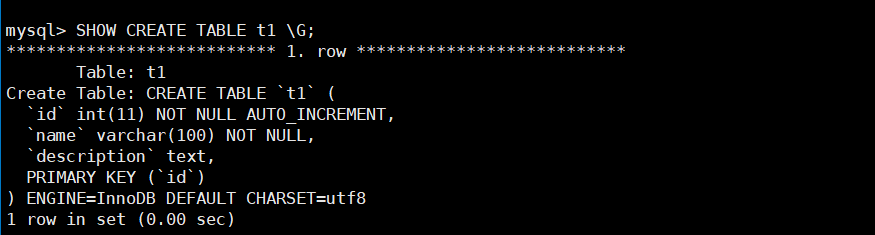
提示
输出语句与输入不完全一致,说明优化器添加了默认字符集和存储引擎(如InnoDB),提升规范性。
存储引擎
概念
存储引擎决定数据的存储方式、索引结构和访问方法。MySQL 支持插件式存储引擎,允许用户根据需求选择。
类比:图书馆管理书籍:
- InnoDB:每本书有唯一编号,快速定位,支持并发借阅(行级锁)和借阅撤销(事务)。
- MyISAM:索引集中存储,适合快速查找,但多人借阅时需排队(表级锁),不支持撤销。
查看支持的存储引擎:
SHOW ENGINES;
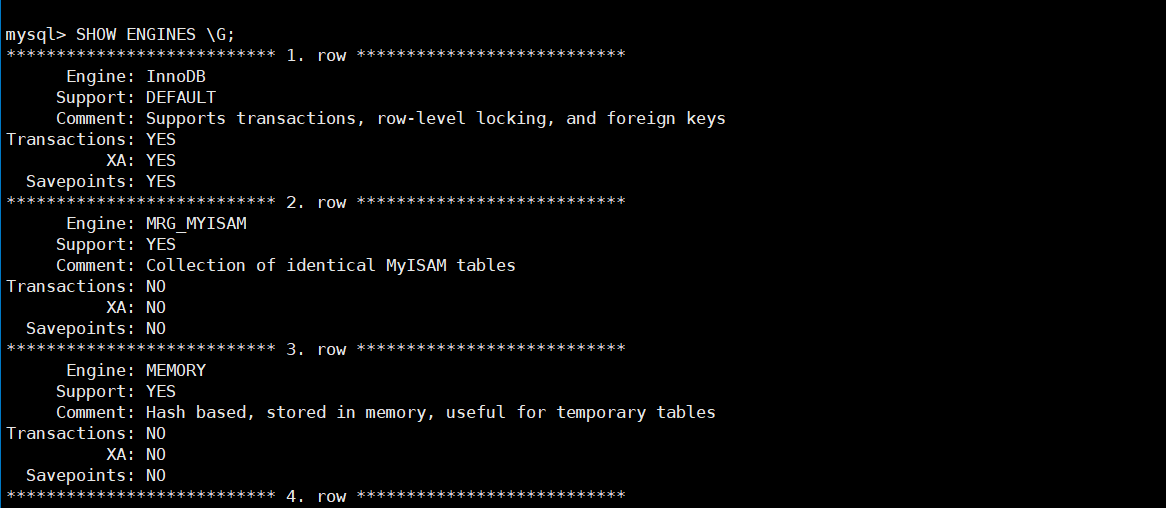
- Support:支持级别(
DEFAULT、YES、NO、DISABLED)。 - Transactions:是否支持事务。
- XA:是否支持分布式事务。
- Savepoints:是否支持保存点。
Default storage engine can be viewed in the configuration file /etc/my.cnf:
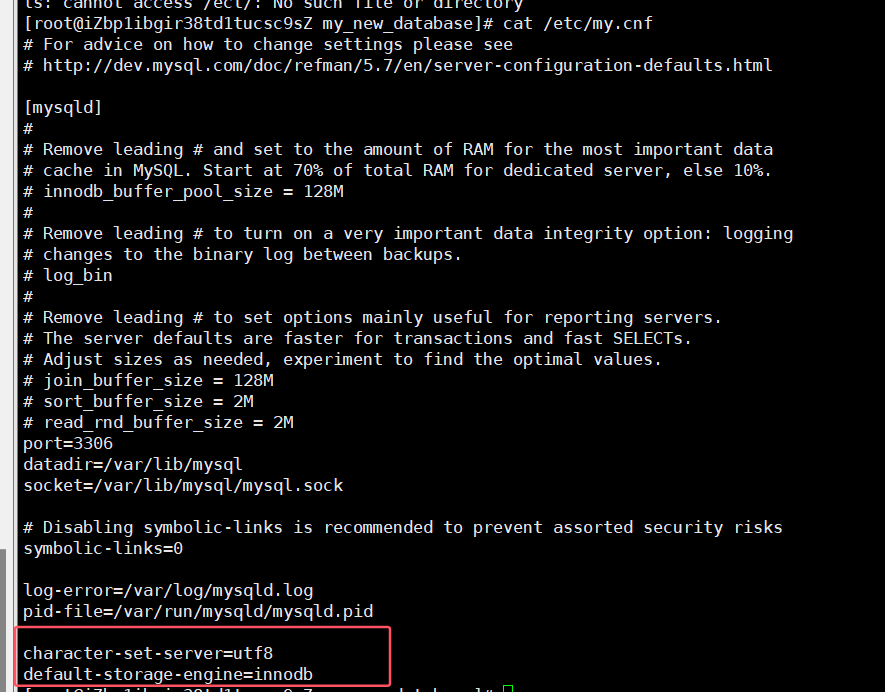
常用存储引擎
InnoDB
- 默认引擎:MySQL 5.5 及以上版本。
- 特点:
- 支持事务(ACID 特性),确保数据一致性。
- 行级锁,允许多用户并发修改不同行。
- 支持外键,维护引用完整性。
- 提供崩溃恢复(通过日志文件)。
- 兼容 MySQL Cluster。
- 适用场景:事务密集型应用,如电商、银行系统。
MyISAM
- 历史默认:MySQL 5.5 之前。
- 特点:
- 表级锁,适合读多写少场景。
- 不支持事务,数据一致性要求较低。
- 读取速度快,支持全文索引(MySQL 5.6 前优势)。
- 适用场景:数据仓库、日志记录等只读场景。
实验:对比存储引擎文件
-
创建表,分别使用 MyISAM 和 InnoDB:
CREATE TABLE test1 ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100) NOT NULL, description TEXT ) ENGINE=MyISAM; CREATE TABLE test2 ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100) NOT NULL, description TEXT ); -- 默认 InnoDB -
查看数据库目录:
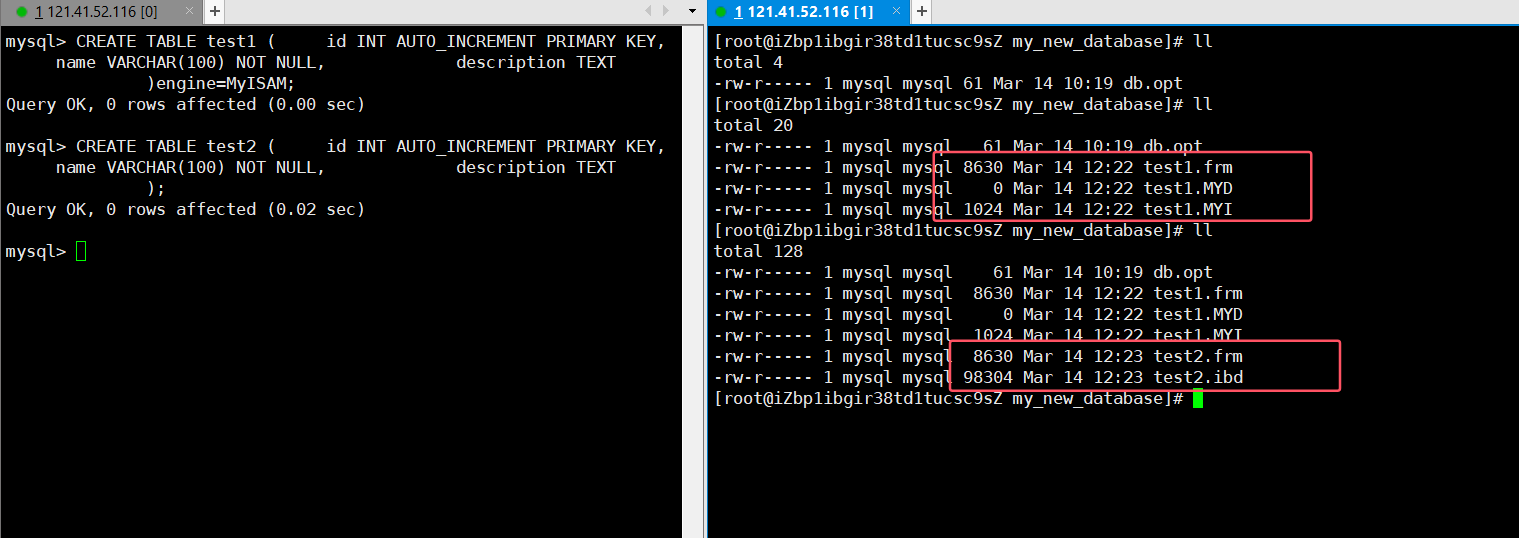
结果:
- MyISAM:
.frm:表元数据。.MYD:表数据。.MYI:表索引。
- InnoDB:
.frm:表元数据。.ibd:表数据和索引(独立表空间模式)。
提示
不同存储引擎生成的文件数量和类型不同,反映了其数据管理方式的差异。
常用 SQL 语句
SQL(Structured Query Language,结构化查询语言)是操作关系型数据库的核心工具。MySQL 主要通过 SQL 语句管理数据,以下是常见分类:
-
数据查询语言(DQL, Data Query Language)
- 用于检索数据。
- 代表语句:
SELECT,从表中提取数据。
-
数据操作语言(DML, Data Manipulation Language)
- 用于插入、更新、删除表中数据。
- 代表语句:
INSERT、UPDATE、DELETE。
-
数据定义语言(DDL, Data Definition Language)
- 用于创建、修改、删除数据库结构(如表、索引、数据库)。
- 代表语句:
CREATE、ALTER、DROP。
注意
项目开发完成后,数据库结构通常固定不变,因为修改结构可能影响相关代码,需谨慎操作。
试一试
创建一个简单表,插入几行数据并查询,体验 DQL 和 DML 的基本操作!
总结
MySQL 是一个功能强大且灵活的数据库系统,其核心优势在于:
- C/S 架构:客户端与服务端分离,易于扩展和维护。
- 插件式存储引擎:支持 InnoDB、MyISAM 等,适应不同场景。
- 标准 SQL 接口:简化开发,提升跨平台兼容性。
通过本文,你了解了 MySQL 的基本概念、架构、存储引擎和 SQL 操作。建议在实际项目中多实践,如创建数据库、表,尝试不同存储引擎,逐步掌握 MySQL 的精髓。