SEER: Self-Aligned Evidence Extraction for Retrieval-AugmentedGeneration
一、动机
如何从检索到的段落中提取证据,以降低计算成本并提升最终的RAG性能,然而这一问题仍然具有挑战性。
现有方法 严重依赖于基于启发式的增强,面临以下几个问题:
(1)由于手工制作的上下文过滤,导致泛化能力差;
(2)由于基于规则的上下文分块,导致语义不足;
(3)由于句子级别的过滤学习,导致长度偏差。
不完美的检索器,会检索到无关的段落,误导LLM
二、解决方法
我们提出了一种基于模型的证据提取学习框架——SEER,通过自对齐学习优化一个基础模型,使其成为具有所需特性的证据提取器。
自对齐学习利用模型自我改进,并将其响应与期望的属性对齐,这可以缓解对手工设计的上下文过滤、基于规则的上下文分块和句子级过滤学习的高度依赖。
鉴于提取的证据,再次出现一个问题:如何正确评估证据的质量?原则上,证据应该是忠实的(即避免内在的幻觉),与检索到的段落一致(Rashkin et al., 2021;Maynez et al., 2020);应有助于解决用户输入的问题(Adlakha et al., 2023);并且简洁,以促进推理速度(Ko et al., 2024)。
我们提出了一种基于模型的证据提取学习框架——SEER:它包括三个主要阶段:
(1)证据提取:为了缓解上述问题,我们提出通过响应采样提取语义一致且长度多样化的证据,从而为对齐提供充分的偏好数据。
三、任务表述
通过基础提取器E和固定生成器G来提升生成任务的性能。
基础提取器E:用于提取证据的模型,是从检索到的文档中提取相关的证据或信息。骨干网络使用Llama2-7B-Chat
固定生成器G:根据提取的证据生成回答,生成器是固定的,权重不更新。
检索到的段落:给定一个查询q从一个检索系统中获取一组相关的段落
自动对齐和微调:通过自对齐(通过模型自身的学习来改善提取过程)来微调基础提取器E,使其提取到的证据更加符合生成器G的需求
![]()
两种上下文过滤优化:
1.基于启发式的
2.基于模型的(本文)
四、方法
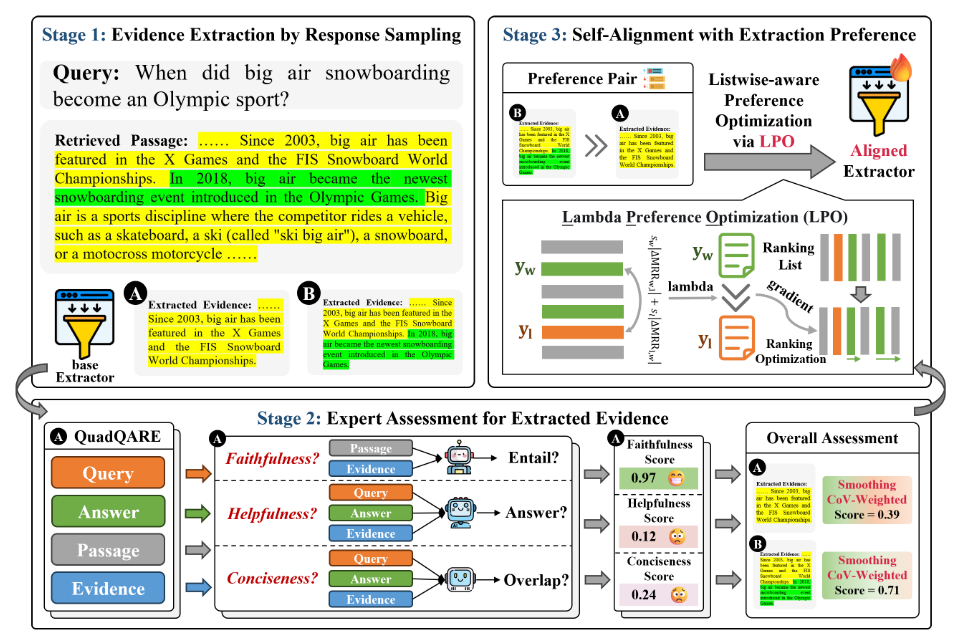
三个阶段:1.证据提取 2.专家评估 3.自对齐
1.证据提取
能不能让模型“自我学习”,自动提取更好的证据,而不是靠人写的死板规则?
🔍 怎么做?
作者的方法就是用一种叫 响应采样(response sampling) 的策略来让模型自己动手练。
我们把这个问题 q 和这段文档 P 拼接在一起,喂给模型,提示它从中提取出 可能作为答案依据的证据(也就是e)。让模型尝试从这段文档中,提取出 M 个不同版本的证据。
⚠️ 问题:模型太“自信”,老是产出一样的东西
大语言模型(LLM)有个“毛病”:它太自信了,总觉得它知道哪条最靠谱。
于是,它在多次采样的时候,总是生成那几条“它最喜欢的答案”:
📊 这导致了一个现象:生成结果的分布很不平衡,叫做“幂律分布”(power-law distribution)
-
热门答案(头部响应)出现非常频繁
-
其他少见但可能有价值的答案(长尾响应)出现得很少
🔧 解决办法:去重 + 均匀分布
-
去重
用一种叫 n-gram 相似度 的方法(就是比较字词相似度),把重复或者非常相似的答案剔除掉。 -
保留不重复、分布更均匀的一组证据
得到新的候选集合 {ei}₁ⁿ,这个集合里的答案就更“多样化”,不会被几个高频答案垄断。
2.专家评估
提取器提取的证据可能:不忠实、没有帮助、不简洁
设置三个专家分别评估提取证据在忠实性、有用性、简洁性方面的质量,之后针对每个提取的证据的多个评分,设计一个平滑的CoV-加权方案,以便得到最终的评估分数。
假设你和朋友们一起评分一部电影,大家的评分有高有低。为了得出一个合理的电影评分,我们可以用CoV-加权来“调节”
加权的意思就是根据评分的不稳定程度给每个评分一个“重要性”分数。
**波动大(不稳定)**的评分,权重会低。
**波动小(稳定)**的评分,权重会高。
1.获得专家的评分
首先收集一组QuadQARE<q, a, p, e>查询、答案、检索到的段落、提取的证据,设计三个可插拔的专家,并行评估提取证据的质量。
忠实专家:将检索到的文档 P 和相应的提取证据 e 视为前提和假设。然后,我们使用 ALIGNSCORE(NLI自然语言推理模型) 来衡量提取证据 e 是否能够从检索到的文档 P 中推导出来
sf∈[0,1]是忠实性评分。如果假设 e 对前提 P 是忠实的,则评分接近 1,否则接近 0。
有用性专家:通过计算在包含提取证据 e 前后生成黄金答案 a 的对数概率变化来评估其对大语言模型(LLMs)的潜在影响
[0,1] 是有用性评分Sig(⋅) 是 sigmoid 函数
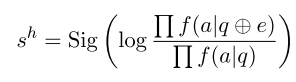
简洁性专家:首先将查询 q 和黄金答案 a 转换为完整答案 t,该答案表示回答查询所需的最小信息。随后,我们利用 SBERT(Reimers 和 Gurevych,2019)来衡量完整答案和提取证据之间的语义重叠程度
[−1,1] 是简洁性评分,通过计算完整答案 t 和提取证据 e 之间的余弦相似度来衡量,提示 GPT-3.5-turbo 根据查询 q 和答案 a 生成完整答案 t
完整答案是通过将问题及其对应的答案转化为陈述句的形式生成的
获得每个专家的评估分数后,怎么用这些分数合并成一个综合评分来评估每个证据的总体质量
简单的方法:直接求平均值,但是每个评估的学习难度和重要性不一样,所以,不能直接使用平均值,使用CoV加权(变异系数加权)的方法
变异系数(CoV):
变异系数(Coefficient of Variation, CoV)是衡量分数变异程度的一个指标,公式为:
CoV的作用是:当某个分数的变动范围较大时,它的影响更大。
计算加权:用 softmax 函数 来将 CoV 转化为权重,并通过“温度”τ\tauτ来控制这种平滑性,防止某些异常的分数权重过大。softmax 函数会根据 CoV 的大小分配不同的权重。温度参数的作用是控制权重分配的平滑度。
CoV加权分数是通过如下公式计算的:
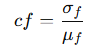

3.自对齐
获得偏好数据:(问题+背景,好的证据,不太好的证据)
![]()
获得数据后,开始对齐微调:
对齐训练中,以前的工作通常采用近端策略优化(PPO)(Schulman et al., 2017) 或直接偏好优化(DPO)(Rafailov et al., 2023)。
PPO(近端策略优化):“你告诉我 A 比 B 好,那我就尽量学着多选 A,少选 B。”它确实能学偏好,但它有个局限:它根本 不关心这俩在总排名里的位置!
DPO(直接偏好优化):“你喜欢 A 胜过 B?OK,我来微调模型倾向 A。”但 DPO 不在乎这个,它就是“谁赢就训谁”,不考虑这俩交换对整体排名有多大影响。
🎯 所以问题出在哪?
PPO & DPO 的共同问题是:
它们都不够“在乎排名位置”⚠️
→ 就像一个不太懂“差距感”的评委。✅ LPO(Lambda Preference Optimization):
如果我把第 2 名换到第 1 名,会让整体排名提升多少?”它会根据这个**“排名提升的收益”**来给每对偏好打不同的“训练权重”。LPO 是一种更聪明的训练方法,不仅知道“e1 比 e2 好”,还知道“让 e1 在前面对整体排名帮助更大”
根据Lambda 损失方法的启发我们提出了 一种基于列表感知的 Lambda 偏好优化算法(LPO):
通过为每对候选项分配一个 lambda 权重,将排名位置无缝地引入 DPO:它在 DPO 的基础上加了一个“排名感知”的增强项 —— lambda 权重(λ₍w,l₎),让训练更精准、更聪明!
LPO(Lambda Preference Optimization) 是一种让模型在「学习偏好排序」时,同时关注:
-
谁更好(偏好对比)
-
谁的位置更重要(排名影响)
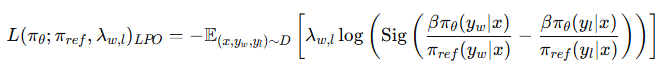
L_LPO = - 期望值[ λ_w,l * log(Sigmoid( ... )) ]
这句话可以解释为:
我们在训练时,对每一对 evidence(ei vs ej),计算一个“偏好损失”,然后根据“他们交换会带来多少排名变化(λ_w,l)”来调节训练强度。
这个结构其实和 DPO 很像,但多了一个 λw,l:每对样本的训练力度是按“交换是否很重要”来动态调整的!
🧠 Lambda 损失是个啥?
Lambda Loss(λ-Loss)是一种用于排序任务的训练方法
核心思想:
🗣️「我不直接告诉模型要学什么分数,我告诉你:如果你把两个样本的位置换了,排名效果会提升多少 —— 然后你根据这个信息来训练!」
Lambda 其实是给每一对候选项的“交换”打的一个分数,也就是“交换这俩值的 收益权重”。
对每一对组合,算出如果我们交换了它们的位置,对某个评价指标(如 NDCG、MRR)影响多大
这个影响值(也可以叫“梯度引导值”)就是 λ,用来指引模型参数往更好的排序方向更新!
✳️ 2. Lambda 权重 λ₍w,l₎ 怎么算的?
λw,l = sw * ΔMRR(w,l) + sl * ΔMRR(l,w)
你可以这样理解:
如果 ei 和 ej 的排名互换后,整体排序的“倒数排名提升”比较大,那说明这两个项的位置很关键,我们就更强烈地用它们来训练模型!

所以,lambda 权重的含义就是:
🌟「这两个证据的排序变化,会对整体排名带来多少提升?」如果越关键,我们就越强化训练。
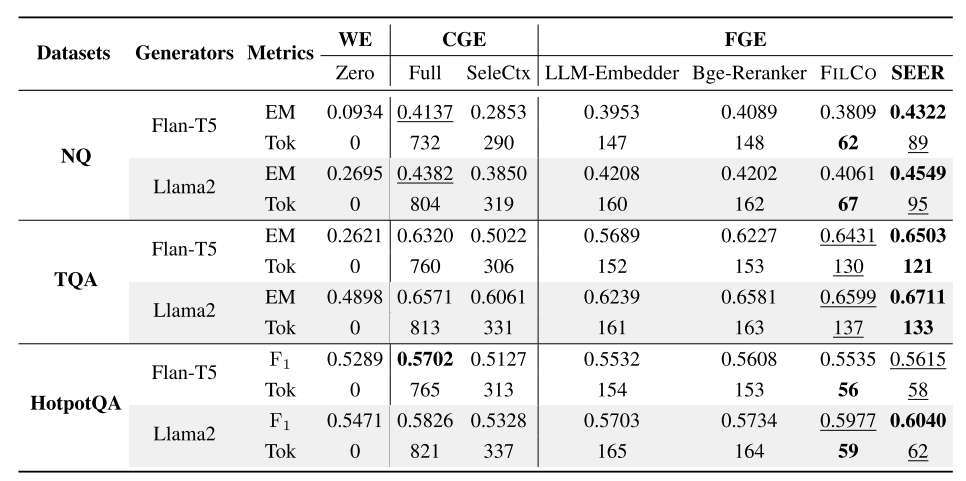
五、实验
1.数据集
NaturalQuestions (NQ)(Kwiatkowski 等,2019)、TriviaQA (TQA)(Joshi 等,2017)和 HotpotQA(Yang 等,2018)。
2.评估指标
NQ 和 TQA 属于抽取式问答任务,我们采用 Exact Match(EM,精确匹配) 作为它们的评估指标:如果问答模型的回答中至少包含一个正确答案,则得分为 1;否则为 0。
HotpotQA 属于生成式问答任务,我们使用 unigram F1 分数 来评估答案的正确性。
3.基线
1.零样本(Zero-shot, Zero):不向大语言模型(LLM)传入任何证据,仅依靠问题本身进行回答。
2.粗粒度证据类(Coarse-grained Evidence, CGE):
-
(i) 全文段(Full Passage, Full):
直接将检索得到的最相关整段文本传给 LLM。 -
(ii) 上下文选择(Select-Context, SeleCtx)(Li 等,2023b):
基于困惑度(perplexity)指标,从检索到的段落中识别并剪除冗余部分,只保留更有信息量的上下文内容。
3.细粒度证据类(Fine-grained Evidence, FGE):
-
(i) LLM-Embedder(Zhang 等,2023):
从检索到的段落中提取与查询最相似的子段落,作为证据。 -
(ii) Bge-Reranker-Large(Bge-Reranker)(Xiao 等,2023):
对检索段落中的所有子句进行重排序,选出得分最高的句子作为证据。 -
(iii) FILCO(Wang 等,2023):
学习如何通过句子级别的精度过滤检索段落,借助启发式增强(heuristic-based augmentation)方法来标注真实标签(ground-truth)。