优先级队列(1)——处理数据流的中位数
欢迎来到博主专栏:算法解析
博主ID:代码小豪
文章目录
- leetcode295——数据流中的中位数
- 题目解析
- 算法原理
- 题解代码
leetcode295——数据流中的中位数
题目解析

题目要求我们设计一个MedianFinder类。该类中存在两个public成员函数,如果在类外调用addNum。就会向类中容器添加一个num。如果调用findMedian。就会返回当前容器中的中位数。
算法原理
如果我们使用vector作为容器,那么我们很容易的就能找到数组的中间的数。

但是一个数组中的中间数,一定就是中位数吗?当然不是了,中位数是在所有数据中,处于中间大小的数,因此一个无序数组的中间数未必是中位数,但是一个有序数组的中间数就是一个中位数了。因此我们的第一个方法就是,每当一个数插入进vector时,我们就让vector进行一次排序,以保持数组的有序性,此时数组中的中位数就很好找了。
但是关于有序数组中的中位数,我们分两种情况进行讨论:
- 1 当数组元素个数是奇数时
- 2 当数组元素个数是偶数时
当数组元素个数是偶数时,我们假设左半数组的元素个数为n,右半数组的元素个数为m。由于是对偶数数组进行折半,因此左右部分的数组元素个数一致,即n==m。
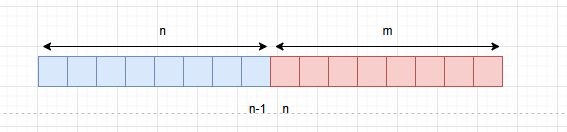
此时中位数为:(nums[n-1]+nums[n])/2
当数组元素个数为奇数时,此时左右数组的个数就不同了,要么左半数组的个数比右半数组多一个,要么反过来,让右半数组比左半数组多一个。我们可以规定让左半数组的个数比右半数组多一个,即n==m+1。
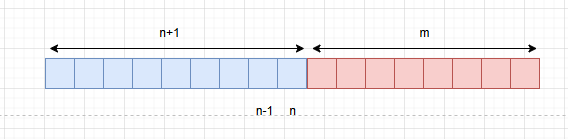
因此此时数组的中位数为nums[n]。
但是一个问题也随之而来,如果我们每次插入一个新的元素,就要进行一次排序,一次排序的时间复杂度为N(logN).如果插入N个数据,那么这个时间复杂度也就来到超过O(N2)的程度。
因此我们需要对插入的排序方法进行优化:
首先,我们要保证在数据插入时,前面的所有数据都是有序的,因此我们可以用二分查找算法找到这个数的插入位置,此时时间复杂度则优化成了O(N)。第二个,我们可以仅对这个元素进行插入排序,此时时间复杂度也优化成了O(N)。
但是这并非是最优化方法,我们可以利用大小堆来完成中位数的查找,首先我们可以回顾一下大堆和小堆的性质,对于大堆,其堆顶元素是堆中所有元素的最大值,对于小堆,其堆顶元素是堆中所有元素的最小值。因此,我们可以用一个大堆,来装左半部分的数组,用一个小堆,来装右半部分的数组。此时我们很容易就能发现,左大堆的堆顶,是左半部分的数组的最大值,右大堆的堆顶,是右半部分数组元素的最小值。
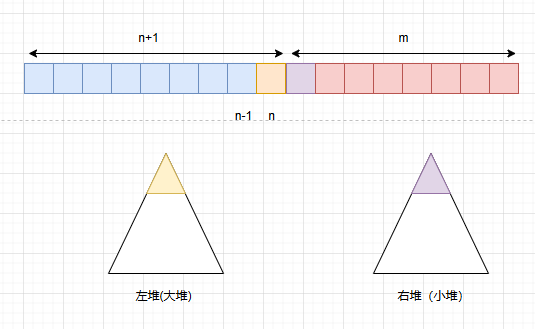
假设左堆的大小为n,右堆的大小为m,根据上面的分析,左堆中的元素个数与右堆的元素个数的关系为:mn或者m+1n。
如果m==n,那么数据流的中位数为(左堆的堆顶+右堆的堆顶)/2。如果m+1==n,那么数据流的中位数为左堆的堆顶。
那么接下来就是左右堆的数据维护问题。根据我们的规定,左堆元素个数总是等于右堆,或者比右堆多一个,而且左堆的堆顶永远不会大于右堆的值。
因此我们可以直接将元素放入左堆,当左堆的元素个数不比右堆的元素个数多两个时,不对左堆进行处理,如果左堆的元素比右堆多两个时,我们让左堆的堆顶元素,插入进右堆。然后删除左堆的堆顶元素。
如果左堆的堆顶比右堆的堆顶大,我们就让左堆的堆顶插入到右堆,让右堆的堆顶插入进左堆,然后让左堆删除堆顶元素,右堆删除堆顶元素。
题解代码
class MedianFinder {
public:
MedianFinder() {
}
void addNum(int num) {
l_heap.push(num);
if(l_heap.size()>r_heap.size()+1) {
r_heap.push(l_heap.top());
l_heap.pop();
}
while(r_heap.size()&&l_heap.top()>r_heap.top()){
r_heap.push(l_heap.top());
l_heap.push(r_heap.top());
r_heap.pop();
l_heap.pop();
}
}
double findMedian() {
if(l_heap.size()==r_heap.size()){
return (l_heap.top()+r_heap.top())/2.0;
}
else return l_heap.top();
}
private:
priority_queue<int> l_heap;//左堆(大堆)
priority_queue<int,vector<int>,greater<int>> r_heap;//右堆(小堆)
};