【技术白皮书】外功心法 | 第四部分 | 数据结构与算法基础(常用的数据结构)
数据结构与算法基础
- 什么是算法?
- 算法效率
-
- 查询和排序
- 为什么排序如此重要?
- 思考问题
- 如何确定复杂性
- 数据结构
-
- 连续或链接的数据结构
-
- 链表的优点
- 数组的优点
- 数组
- 集合
-
- Set 声明的一些方法有
- Multiset多元集合
- 栈和队列
-
- 何时使用栈和队列
- 数据字典
-
- 字典Hash的实现
- 时间复杂度对时间的影响
什么是算法?
算法是解决计算问题的一系列步骤或规则。计算问题是计算机可能能够解决的问题的集合。一个简单算法的例子可能是咖啡机使用的算法,它可能看起来像这样:
if (clock.getTime() == 7am){
coffeMaker.boilWater();
if(water.isBoiled()){
coffeMaker.addCoffee();
coffeMaker.pourCoffee();
}
} else{
coffeMaker.doNothing();
}
算法效率
算法效率是对算法使用的资源量的研究。
算法使用的资源越少,效率越高。然而,为了更好地比较不同的算法,我们可以根据它使用的资源进行比较:它需要多少时间来完成,它使用多少内存来解决一个问题,或者为了解决这个问题它必须做多少操作
- 时间效率:算法解决一个问题所需时间的度量。
- 空间效率:算法解决问题所需内存量的度量。
- 复杂性理论:基于语句计数成本函数的算法性能研究。
查询和排序
根据 S. Skiena 的说法,从历史上看,计算机在排序上花费的时间比做其他任何事情都要多。在实践中,排序仍然是最无处不在的组合算法问题。
为什么排序如此重要?
处理数据的第一步是排序,一旦一组元素的数据被排序,许多任务就会变得更容易。一些算法,如二分查找,是围绕着已排序的数据结构构建的。
思考问题
- 如何排序:降序还是升序?
- 根据什么进行排序?对象名称(按字母顺序)、由其字段/实例变量定义的某个数字。或者也许比较日期、生日等。
- 如果遇到相等的键,例如有多个同名的人:约翰,那么按照姓氏对他们进行排序。
- 排序算法是原地排序还是需要额外的内存来保存要排序的数组的另一个副本呢?‘
如何确定复杂性
我们可以根据程序所使用的语句类型来确定复杂性。
以下示例是用Java编写的,但如果你有基本的编程经验并使用大O表示法(我们稍后将解释为什么大 O 表示法被广泛使用),则可以很容易地理解这些示例。
数据结构
数据结构是构建应用程序所围绕的基本结构。一种数据结构决定了数据在计算机中的存储和组织方式。只要有数据存在,为了能存储在计算机中,它就必须具备某种数据结构。
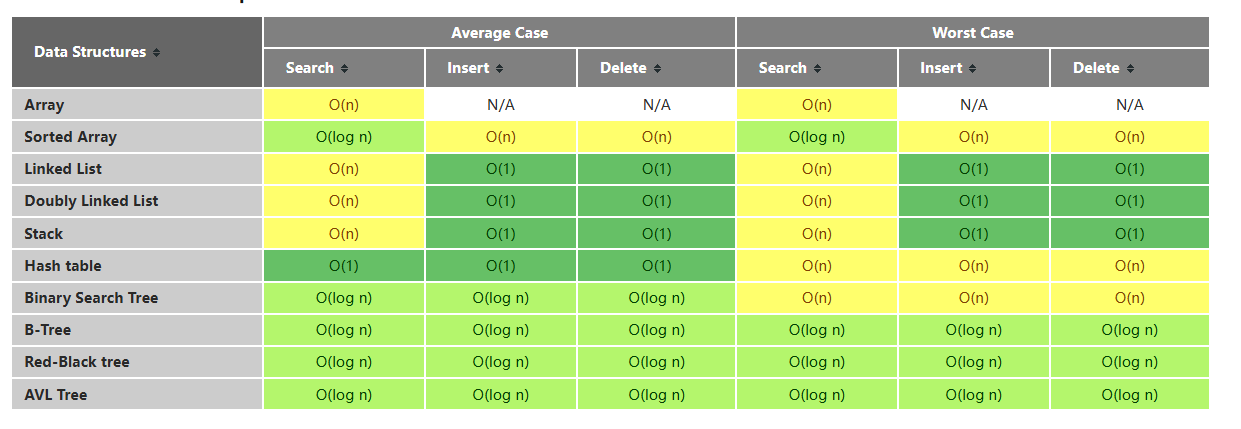
连续或链接的数据结构
数据结构可以分为连续的或链式的,这取决于它们是基于数组还是指针(引用)。
- 连续分配结构:由单块内存组成,其中一些数据结构是数组、矩阵、堆和哈希表。
- 链接数据结构:由不同的内存块组成,这些内存块通过指针(引用)链接在一起,其中一些数据结构是列表、树和图的邻接列表。
链表的优点
- 链表结构上的溢出比数组更难发生。只有当内存实际上已满时才会发生。
- 插入和删除比连续数据结构(如数组)更简单。
- 链表在初始化时不需要知道大小。
数组的优点
- 链接结构需要为存储指针分配额外的空间。
- 数组允许高效地访问任何项。
数组
数组是基本的连续分配的数据结构。
它们具有固定的大小,并且每个元素都可以通过其索引高效地定位。想象一下,数组就像一条满是房屋的街道,一个紧挨着一个,每个房屋都可以通过其地址(索引)轻松定位。
/*
* We can determine at the moment of instantiation the capacity
* of the ArrayList this gives a little boost in performance,
* instead of making the array resize constantly
*/
List<String> exampleList = new ArrayList<>(100);
/*
* Don't confuse capacity with size, the following
* statement outputs 0, as currently the ArrayList
* size is 0, but it's capacity is 100
*/
System.out.println(exampleList.size());
exampleList.add("first");
exampleList.add("second");
exampleList.add("third");
System.out.println(exampleList.size());//prints 3
集合
集合是一种无序且不能包含重复元素的集合类型。
在 Java 中,Set 接口包含从 Collection 继承的方法,并增加了禁止重复元素的限制。Java 还对 equals () 和 hashCode () 方法的行为添加了更强的约定,允许Set 实例即使实现类型不同也能进行有意义的比较。
Set 声明的一些方法有
add( ) 将一个对象添加到集合中
clear( ) 从集合中移除所有对象
contains( ) 从集合中移除所有对象
isEmpty( ) 如果集合中没有元素,则返回 true
iterator( ) 返回一个用于集合的迭代器对象,该对象可用于检索一个对象
remove( ) 从集合中移除指定的对象
size( ) 返回集合中的元素数量
让我们以 Java 中集合的实现为例来理解它是如何工作的。首先,我们需要定义数据类型并覆盖 equals () 和 hashCode () 方法。
public class DataType {
private String name;
private int number;
public DataType(String name, int number){
this.name = name;
this.number = number;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 :
name.hashCode());
return result;
}
/*
* We override method equals so that objects
* with same name can't be added to the set,
* but objects with same numbers can be added
*/
@Override
public