一周学会Pandas2 Python数据处理与分析-Pandas2数据读取
锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

Pandas将数据加载到DataFrame后,就可以使用DataFrame对象的属性和方法进行操作。这些操作有的是完成数据分析中的常规统计工作,有的是对数据的加工处理。无论是在分析统计方面还是在加工处理方面,Pandas都提供了丰富且实用的功能。
Pandas可以将指定格式(CSV,Excel,SQL等)的数据读取到DataFrame中,并将DataFrame输出为指定格式(CSV,Excel,SQL等)的文件。
Pandas 是一个强大的 Python 库,用于数据处理和分析。它提供了许多函数来读取和导入数据,支持多种文件格式,如 CSV、Excel、SQL 数据库、JSON 等。以下是一些常用的数据读取和导出方法:
| 格式 | 文件格式 | 读取函数 | 写入(导出)函数 |
|---|---|---|---|
| binary | Excel | read_excel | to_excel |
| text | CSV | read_csv | to_csv |
| text | JSON | read_json | to_json |
| text | 网页表格 | HTML | to_html |
| text | 剪切板 | read_clipboard | to_clipboard |
| SQL | SQL | read_sql | to_sql |
其中:
读取函数一般会赋值给一个变量 df, df = pd.read_()
输出函数是将变量自身进行操作并输出 df.to()
常用函数方法 Excel 对象 ~ pd.ExcelFile 对象 ~ pd.ExcelWriter 对象 ~ pd.ExcelWriter 对象的属性和方法 读取数据 ~ pd.read_csv() ~ pd.read_excel() ~ pd.json_normalize() ~ pd.read_pickle() ~ pd.read_table() ~ pd.DataFrame.from_dict() 从字典创建 DataFrame ~ pd.read_clipboard() 从剪贴板读取数据 ~ pd.read_json() 读取 JSON ~ pd.read_sql() 读取数据库数据 ~ pd.read_fwf() 读取固定宽度格式文件 ~ pd.read_html() 从 HTML 文档提取表格数据 ~ pd.read_parquet() 读取 Parquet 文件 导出数据 ~ to_csv() 导出为 CSV文件 ~ to_excel() 导出为 Excel 文件 ~ to_dict() 输出字典 ~ to_pickle() 序列化为 pickle 文件 ~ to_json() 转换为 JSON 格式字符串 ~ to_html() 转换为 HTML 表格格式 ~ to_sql() 写入到关系型数据库 ~ to_parquet() 保存为 parquet 文件
1.读取CSV文件
CSV(Comma-Separated Values)是用逗号分隔值的数据形式,有时也称为字符分隔值,因为分隔字符也可以不是逗号。CSV文件的一般文件扩展名为.csv,用制表符号分隔也常用.tsv作为扩展名。CSV不仅可以是一个实体文件,还可以是字符形式,以便于在网络上传输。
CSV不带数据样式,标准化较强,是最为常见的数据格式。
下面student_scores.csv可以看下格式。

参考代码:
import pandas as pd
df = pd.read_csv('student_scores.csv')2.读取Excel文件
参考代码:
import pandas as pd
df = pd.read_excel('student_scores.xlsx') # 默认读取第一个标签页Sheet
df = pd.read_excel('student_scores2.xlsx', sheet_name="Sheet2") # 指定标签Sheet页3.从SQL数据库读取
Pandas需要引入SQLAlchemy库来支持SQL,在SQLAlchemy的支持下,它可以实现所有常见数据库类型的查询、更新等操作。
首先第一步要安装pymysql,作为连接mysql的驱动,pip安装命令:
pip install pymysql -i https://mirrors.aliyun.com/pypi/simple然后再安装下sqlalchemy库:pip安装命令
pip install flask-sqlalchemy -i https://mirrors.aliyun.com/pypi/simple安装后,Python Interpreter里面里面可以看到

参考代码:
import pandas as pd
from sqlalchemy import create_engine
# 创建数据库引擎
# 注意:替换下面的用户名、密码、主机名和数据库名
engine = create_engine('mysql+pymysql://root:123456@localhost:3308/db_xuanke')
# 使用SQLAlchemy引擎读取数据到DataFrame
query = "SELECT * FROM rc_admin"
df = pd.read_sql_query(query, con=engine)
print(df)运行结果:
admin_id admin_username admin_password admin_privilege
0 1 admin 123456 255
1 2 jwadmin 123456 964.读取JSON文件
JSON是互联网上非常通用的轻量级数据交换格式,是HTTP请求中数据的标准格式之一。Pandas提供的JSON读取方法在解析网络爬虫数据时,可以极大地提高效率。
json文件示例:
[
{
"name": "Alice",
"age": 25,
"city": "New York"
},
{
"name": "Bob",
"age": 30,
"city": "Los Angeles"
},
{
"name": "Charlie",
"age": 35,
"city": "Chicago"
}
] 参考代码:
import pandas as pd
df = pd.read_json('file.json')
print(df)运行输出:
name age city
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago5.读取HTML表格
pd.read_html()函数可以接受HTML字符串、HTML文件、URL,并将HTML中的<table>标签表格数据解析为DataFrame。如返回有多个df的列表,则可以通过索引取第几个。如果页面里只有一个表格,那么这个列表就只有一个DataFrame。
操作html,必须要安装lxml库:
pip install lxml -i https://mirrors.aliyun.com/pypi/simplehtml表格文件示例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Example Table</title>
</head>
<body>
<table>
<thead>
<tr>
<th>Name</th>
<th>Age</th>
<th>City</th>
</tr>
</thead>
<tbody>
<tr>
<td>Alice</td>
<td>25</td>
<td>New York</td>
</tr>
<tr>
<td>Bob</td>
<td>30</td>
<td>Los Angeles</td>
</tr>
<tr>
<td>Charlie</td>
<td>35</td>
<td>Chicago</td>
</tr>
</tbody>
</table>
</body>
</html>参考代码:
import pandas as pd
try:
# 读取 HTML 文件
dfs = pd.read_html('example.html')
# 打印每个表格的基本信息和内容
for i, df in enumerate(dfs):
print(f"第 {i + 1} 个表格基本信息:")
df.info()
rows, columns = df.shape
if rows < 10:
print(f"第 {i + 1} 个表格全部内容信息:")
print(df.to_csv(sep='\t', na_rep='nan'))
else:
print(f"第 {i + 1} 个表格前几行内容信息:")
print(df.head().to_csv(sep='\t', na_rep='nan'))
except FileNotFoundError:
print("错误: 文件未找到,请检查文件路径。")
except ValueError:
print("错误: 文件中未找到有效的表格。")
except Exception as e:
print(f"错误: 发生了未知错误: {e}")运行输出:
第 1 个表格基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 3 non-null object
1 Age 3 non-null int64
2 City 3 non-null object
dtypes: int64(1), object(2)
memory usage: 204.0+ bytes
第 1 个表格全部内容信息:
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago6.从剪切板读取
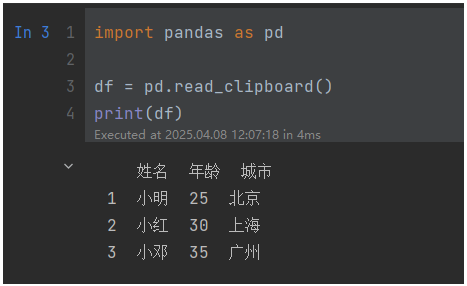
剪贴板(Clipboard)是操作系统级的一个暂存数据的地方,它保存在内存中,可以在不同软件之间传递,非常方便。Pandas支持读取剪贴板中的结构化数据,这就意味着我们不用将数据保存成文件,而可以直接从网页、Excel等文件中复制,然后从操作系统的剪贴板中读取,非常方便。
复制下内容到剪切板:
姓名 年龄 城市
1 小明 25 北京
2 小红 30 上海
3 小邓 35 广州 示例代码:
import pandas as pd
df = pd.read_clipboard()
print(df)运行结果: