数据结构——哈希技术及链地址法
目录
一、哈希的定义
二、哈希冲突定义
三、构造哈希函数的方法
四、四种解决哈希冲突的方法
4.1 开放地址法
4.2 链地址法
4.3 再散列函数法
4.4 公共区溢出法
五、链地址法结构体设计
六、基本操作的实现
6.1 哈希函数
6.2 初始化
6.3 插入值
6.4 删除值
6.5 查找值
6.6 打印
6.7 测试用例
一、哈希的定义
哈希(Hash)是一种将任意长度的输入数据通过哈希算法转换成固定长度(通常是固定长度的字符串)输出的过程。哈希算法通常会将输入数据映射为一个固定长度的字符串,这个字符串通常称为哈希值或摘要。
也就是说,我们只需要通过某个函数f ,使得存储位置=f(关键字),那么我们可以通过查找关键字不需要比较就可以获得需要记录的存储位置。
哈希函数具有以下特点:
- 输入数据相同,输出的哈希值必定相同。
- 不同的输入数据,哈希值是独立的,即不会有冲突。
- 哈希值的长度是固定的,不会随输入数据的长度变化而变化。
- 哈希值是不可逆的,即无法从哈希值还原出原始的输入数据。
哈希既是一种存储方法,也是一种查找方法。
二、哈希冲突定义
两个或多个关键码key1!=key2,但是通过哈希函数的计算,得出的结果却相等,这种现象就是发生了哈希冲突。
例如:f(x)=x %10
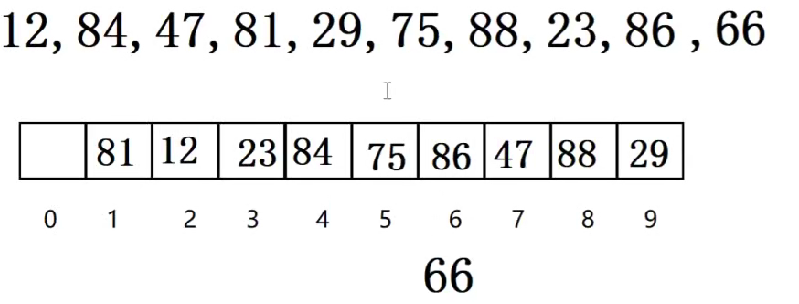
例如上述的86和66,计算得出都应该存放在6号下标,冲突了。
三、构造哈希函数的方法
构造哈希函数的方法有很多种。其中一种常见的方法是利用数学运算来将输入数据映射到固定大小的哈希值。
以下是一些构造哈希函数的方法:
-
直接寻址法:将输入数据直接作为索引值,获取对应的哈希值。
-
除留余数法:将输入数据除以一个数,取余数作为哈希值。
-
平方取中法:对输入数据进行平方运算,然后取中间几位作为哈希值。
-
折叠法:将输入数据分割成固定长度的片段,对每个片段进行加法或异或运算,最终得到哈希值。
-
随机哈希函数:使用随机数生成器生成哈希函数,将输入数据与随机数进行运算来得到哈希值。
-
加法哈希函数:将输入数据中的每个字符转换成ASCII码,然后求和得到哈希值。
-
乘法哈希函数:将输入数据乘以一个常数,取乘积的某几位作为哈希值。
四、四种解决哈希冲突的方法
4.1 开放地址法
线性探测法:

但是这种方法会存在一种情况:两个值本来都不是同义词却需要争夺一个地址,这种现象叫做堆积 。
二次探测法:
所以我们想着再探测的时候,尽可能的即向左探测,也向右探测,并且探测的幅度还在呈指数爆炸的趋势增加。这种方法叫做二次探测法。

随机探测法:

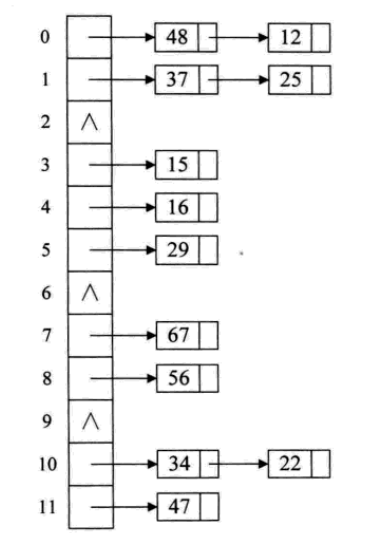
4.2 链地址法
当哈希表用链地址法处理冲突时,每个槽位都存储一个链表或其他数据结构,该链表用于存储哈希值相同的键值对。当需要查找、插入或删除一个键值对时,首先计算对应的哈希值,然后根据哈希值找到对应的槽位,最后在该槽位上的链表中进行操作。
优点:链地址法的优点是容易实现和理解,可以有效地处理哈希冲突,适用于存储大量数据的情况。
缺点:链地址法可能会浪费一定的空间用于存储链表的指针,同时在遍历链表时可能会引起缓存未命中。
4.3 再散列函数法
当发生哈希冲突时,再散列函数法会根据一个特定的规则选择另一个哈希函数,将原始的关键字重新哈希,生成一个新的哈希值。然后,再检查新的哈希值对应的槽位是否为空,如果为空则将数据插入该位置,如果不为空则继续使用再散列函数生成新的哈希值,直到找到一个合适的位置为止。
4.4 公共区溢出法
公共区溢出法与链地址法不同的是,公共区溢出法在哈希表的每个槽位中直接存储键值对,当发生哈希冲突时,会在其他空槽位中寻找可用的位置来存储冲突的键值对。
具体来说,当插入一个键值对时,如果计算得出的哈希值对应的槽位已经被占用,那么就会根据某种探测序列在哈希表中查找下一个可用的空槽位,并将键值对存储在该位置上。具体的探测序列可以是线性探测、二次探测、双重散列等。

优点:
- 公共区溢出法不需要额外的数据结构来存储冲突的键值对,节省了额外的空间开销。
- 可以提高数据的局部性,减少缓存未命中的可能性。
- 插入、查找和删除操作时,不需要额外的指针操作,节省了内存。
缺点:
- 当哈希表变满时,可能会增加插入操作的复杂度,可能导致性能下降。
- 如果探测序列选择不当,可能会导致产生大量的聚集现象,影响查找效率。
- 删除操作可能较为繁琐,需要标记删除的键值对。
五、链地址法结构体设计
链地址法中有效节点的结构体设计:1.数据域 2.指针域
//链地址法有效节点的结构体设计
typedef int ElemType;
typedef struct List_Node
{
ElemType data; //数据域
struct List_Node* next; //指针域
}List_Node, *PList_Node;
链地址法中辅助节点的结构体设计: 1. 数组,有INIT_SIZE个格子,每一个格子存放的是单链表的辅助节点。
//链地址法辅助节点的结构体设计
#define INITSIZE 12
typedef struct List_address
{
struct List_Node arr[INITSIZE];
}List_address;六、基本操作的实现
6.1 哈希函数
哈希函数实现,就是计算给定元素的哈希值。其中,ElemType代表元素的类型,INITSIZE代表哈希表的初始大小。
哈希函数采用了取余运算符%来计算元素的哈希值,具体操作是将给定元素val除以INITSIZE后取余数。取余运算可以将元素的值映射到一个较小的范围内,使得得到的哈希值在哈希表的合法索引范围内。
代码实现如下:
//哈希函数
int Hash(ElemType val)
{
return val % INITSIZE;
}
6.2 初始化
通过for循环,调用单链表中的初始化函数即可完成初始化。
//初始化
void Init_List_Address(List_address* pla)
{
for (int i = 0; i < INITSIZE; i++)
{
InitList(&pla->arr[i]);
}
}
6.3 插入值
-
首先,函数接受一个指向哈希表的指针
pla和待插入的元素值val作为参数。 -
通过调用之前提到的哈希函数
Hash(val)来计算元素val的哈希值,并将其赋值给index变量。 -
接着,通过调用
malloc()函数动态分配内存,创建一个新的节点pnewnode,用于存储待插入的元素。 -
如果内存分配成功(即
pnewnode不为NULL),则将元素值val赋给新节点的数据域data。 -
将新节点的
next指针指向哈希表中对应索引位置的链表头节点,以实现在链表头插法的方式将新节点插入到哈希表中。 -
最后,返回
true表示插入成功。
代码实现如下:
//插入值
bool Insert(List_address* pla, ElemType val)
{
assert(pla != NULL);
int index = Hash(val);
Node* pnewnode = (Node*)malloc(sizeof(Node));
if (NULL == pnewnode)
return false;
pnewnode->data = val;
pnewnode->next = pla->arr[index].next;
pla->arr[index].next = pnewnode;
return true;
}
6.4 删除值
-
首先,函数接受一个指向哈希表的指针
pla和待删除的元素值val作为参数。 -
通过调用哈希函数
Hash(val)计算元素val的哈希值,并将其赋值给index变量。 -
调用
Hash_List_Address_Search()函数来查找哈希表中是否存在值为val的节点,将返回的节点赋给指针 q。 -
如果节点
q为NULL,即未找到待删除的元素,则返回false表示删除失败。 -
如果找到了值为
val的节点q,则进入循环,遍历哈希表中索引为index的链表,找到节点q的前驱节点,即节点p。 -
在找到节点
q的前驱节点p后,将前驱节点的next指针指向节点q的后继节点,实现删除节点q的操作。 -
通过调用
free(q)释放节点q占用的内存空间,并将指针q设为NULL,避免悬空指针。 -
最后,返回
true表示删除成功。
代码实现如下:
bool Delete(List_address* pla, ElemType val)
{
assert(pla != NULL);
int index = Hash(val);
Node* q = Hash_List_Address_Search(pla, val);
if (q == NULL)
return false;
//此时代码执行到这,证明val值节点存在在index下标里面的单链表上
Node* p = &pla->arr[index];
for (; p->next != q; p = p->next);
//此时代码执行到这里,证明p和q都就位
p->next = q->next;
free(q);
q = NULL;
return true;
}
6.5 查找值
-
首先,函数接受一个指向哈希表的指针
pla和待查找的元素值val作为参数。 -
通过调用哈希函数
Hash(val)计算元素val的哈希值,并将其赋值给index变量。 -
查找哈希表中索引为
index的单链表的起始节点,并将其赋给指针p。 -
进入循环,遍历哈希表中索引为
index的链表,逐个比较节点中存储的数据值是否等于待查找的元素值val。 -
如果找到与待查找的元素值相等的节点,则返回该节点的指针p,表示找到了目标节点。
-
如果在整个链表中都没有找到与待查找的元素值相等的节点,则循环结束后,返回NULL,表示未找到目标节点。
代码实现如下:
struct Node* Hash_List_Address_Search(List_address* pla, ElemType val)
{
assert(pla != NULL);
int index = Hash(val);
Node* p = pla->arr[index].next;
for (; p != NULL; p = p->next)
{
if (p->data == val)
{
return p;
}
}
return NULL;
}
6.6 打印
void Show(List_address* pla)
{
for (int i = 0; i < INITSIZE; i++)
{
printf("第%d行:", i);
Node* p = pla->arr[i].next;
for (; p != NULL;p = p->next)
{
printf("%d->", p->data);
}
printf("\n");
}
}6.7 测试用例
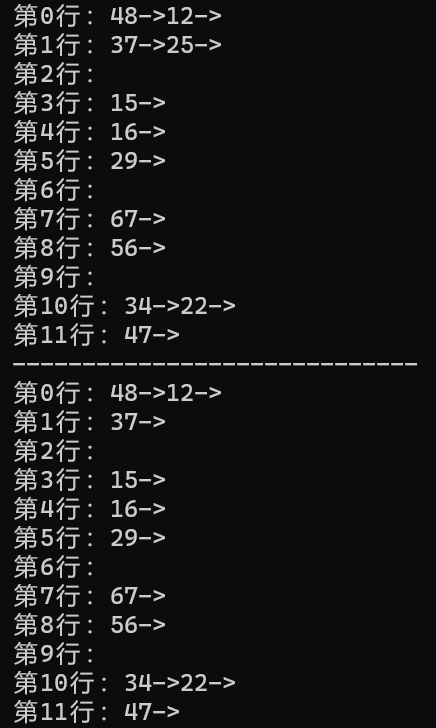
int main()
{
List_address head;
Init_List_Address(&head);
Insert(&head, 12);
Insert(&head, 67);
Insert(&head, 56);
Insert(&head, 16);
Insert(&head, 25);
Insert(&head, 37);
Insert(&head, 22);
Insert(&head, 29);
Insert(&head, 15);
Insert(&head, 47);
Insert(&head, 48);
Insert(&head, 34);
Show(&head);
printf("-----------------------------\n");
Delete(&head, 25);
Delete(&head, 12345);
Show(&head);
return 0;
}运行结果如下: