全局端对端问题及应对方案
一)全局端对端问题
1)大算力消耗及存储资源,通讯带宽,都无法满足落地需求
2)无辅助模块,比如缺少了应对交通规则的地图模块
3)3D空间感知能力不足,又比如遮挡,横穿,长距离远望,切出,后向来车
4)长序列记忆,能长期跟踪目标(行人运动)或复杂交互场景(比如多车博弈),路口变道交通标识
5)轨迹实时性和轨迹长度,8S,max100ms-cycle(其实可能实际要更快点),即如何解决车端实时推理(是整个链路的CycleTime评估),无法做到高频响应
6)像素低,细小物体颗粒度,比如筒锥,繁杂路口,小目标检测能力,会有信息损失,高分辨率图像的话,token数量又会太多,聚焦损失度分不清重点
7)决策震荡频繁,尤其是跟车变向,复杂action的衔接
8)数据多样性不足,极端场景不足,保留高质量且具有数据平衡度衡量,预测轨迹基于模仿学习,即依赖于真值轨迹平衡度和丰富度
9)LLM经过RFL后本身具备垂直领域驾驶知识和推理能力大概估计状态
10)下限兜底,RL怎么做?
以上基于VLM或者VLA的架构都没办法做到下限提高或者上限拔尖,反而技术路线会有局限性。
换而言之,模块化的端对端依旧是主流,从某种意义上依旧是快慢系统,快系统是diffusion planner或者policy,慢系统是LLM或VLM
二)RoadMap演进
1)模块化分段式端到端
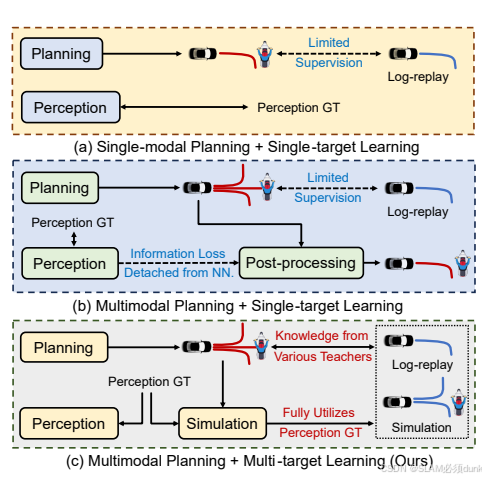
| 范式名 | 代表 | 优劣势 |
| 单模态规划+单目标学习 | UniAD,vad系列 | cmd的生成仍然需要人为输入,在推理时cmd的生成依靠大量rule base逻辑,非预期端到端模型 |
| 多模态规划+单目标学习 | VADv2系列 | 预测多个轨迹,计算与专家轨迹的相似度,感知输出P通过成本函数明确后处理合适的轨迹,选择成本最低的轨迹 |
| 动态cmd(vlm)+单路径规划 | drivevlm,lmdrive等 | 可以认为该系列模型cmd是由模型动态生成,是预期端到端模型,但vlm模型受限于3d空间和时间理解能力以及单目标的偏好,无法完成任务快速切换和任务精细控制,即非快模型 |
| cmd+多路径规划 | sparsedrive | 和cmd+单路径规划一样的问题 |
| 多路径+多目标 | hydra-mdp | 预期端到端模型,但是其中traj的评估和任务切换状态机设计比较复杂。作为teacher的评估器无法进行快速升级迭代,无法适应多样复杂的现实环境。所以在评估器上会设计以下系统进行 |
VAD约束:
1)矢量地图过于单调,主要考虑到车道分割线,道路分界,人行横道 实际中需要丰富信息
2)command 来自导航,左转右转和直行,这个后面可以优化来自VLM等
3)规则约束模块过于简单,以前写rulebase,现在改成约束模块或者约束Loss
4)自车与边界约束,实际量产道路边界的表示只用车道线是不行的,Occ改善
5)自车与车道线约束,实际没有车道线就会有问题
6)没有VRU的约束,仅仅是浅显的前车和旁车的直线约束
7)单模态输出会有问题,需要更改为多模态输出
2)经典的VLA流程

输入前视视频序列,VLM大模型对视频理解、分析、提出驾驶建议,生成waypoint轨迹规划,基本上一个VLM完成了所有任务。
VLA即Vision Language Action,可以看做是多模态大模型即VLM的延伸,VLM主要做VQA任务,基本就是看图分析回答问题,加入针对自动驾驶监督微调后增加一个输出waypoint的任务,即Action,也就成了VLA,是一个整体。
这是目前选择的路线,但是开头遇到的问题,依旧是可以否定的,至少低算力平台上车很难。
3)双系统快慢模型
理想Drive VLM

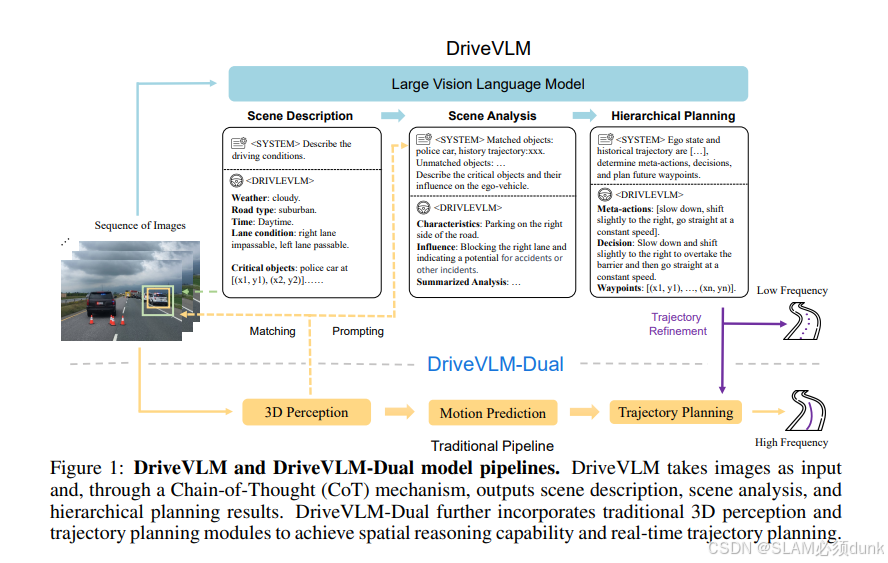
这块重点是VLM承担role具体是什么(CoT),首先低频,其次场景和认知能力泛化,最后充当决策使用,并不是用来解决NormalCase
地平线SENNA
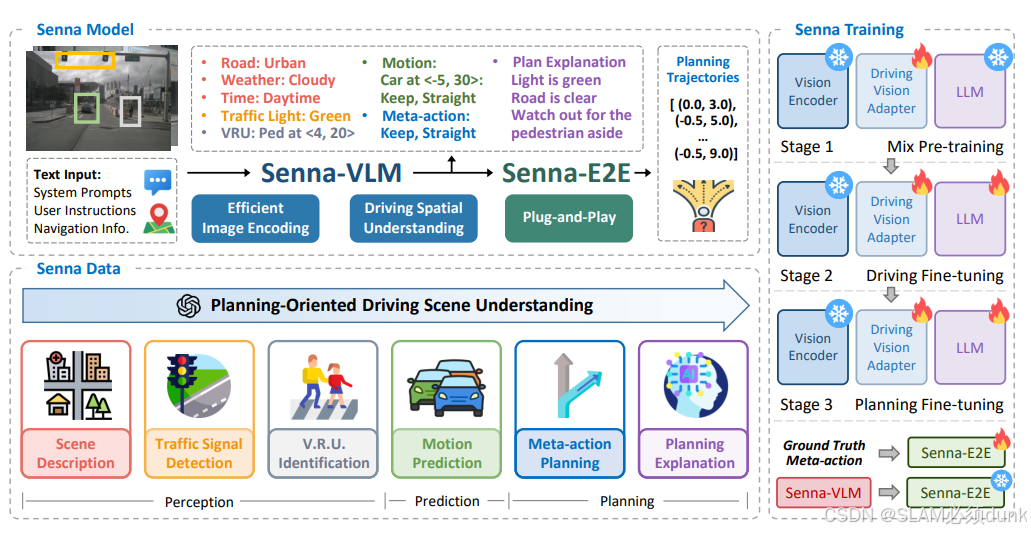
地平线24年开环测试打榜第一,即VLM在大规模驾驶数据上微调,提升了垂直领域的理解能力,并采用了自然语言输出高维度决策指令(是决策指令,不是规划指令),显示地传递,然后端对端模型基于大模型的决策指令,进行了具体规划轨迹生成,类似于HyMDP的TeacherModel,这样做一是解决了cornercase和非通常训练的障碍物,利用语言任务预先泛化训练知识和认知能力,形成合理的决策,并且取长补短,保留了模块化端对端甚至传统算法感知更擅长的数字敏感度,将高维决策任务解耦,即有下限兜底提升,又能利用高维决策提高上限,模型学习难度降低,轨迹规划精度提高。
但是同样面临的问题是,高低频怎么配合?某方案可能只是针对类似潮汐车道,公交车道,施工区域等5%case进行解决,且都是依赖于场景识别,未能做实时性的响应。
Figure 双系统
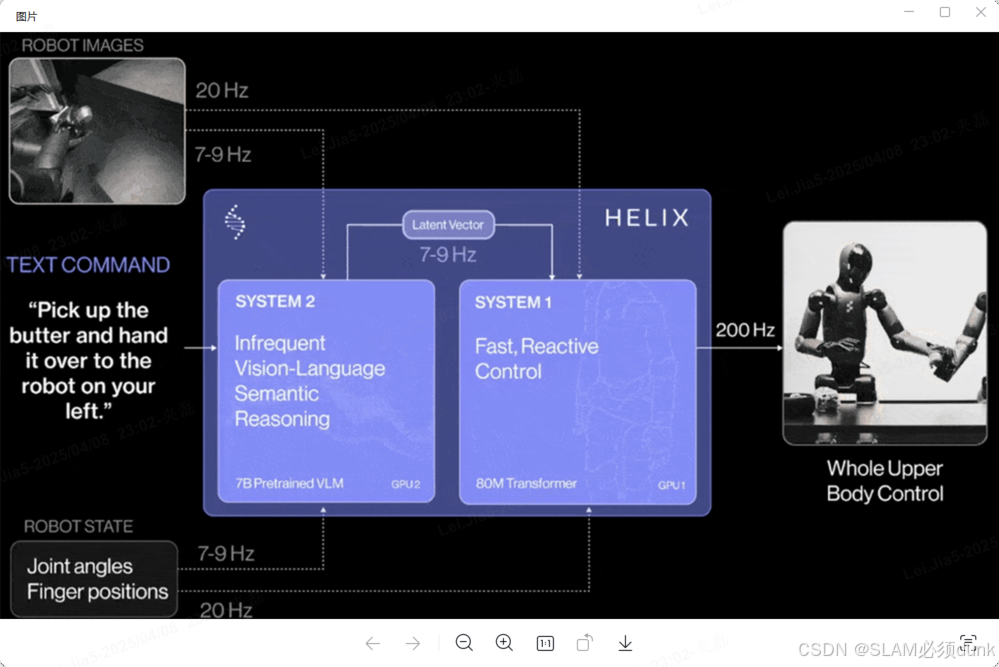
但注意不是显示传递,做了token进入端对端(像素级别端对端,与前面双系统)至于depth怎么传递的,我个人猜测仅是个人,是多个camera弥补了很多depth不足,传感器可能会有RGBD,点云预训练可以增加泛化性
理想后续VLM-E2E 有点开始VLA的苗头(只是论文)
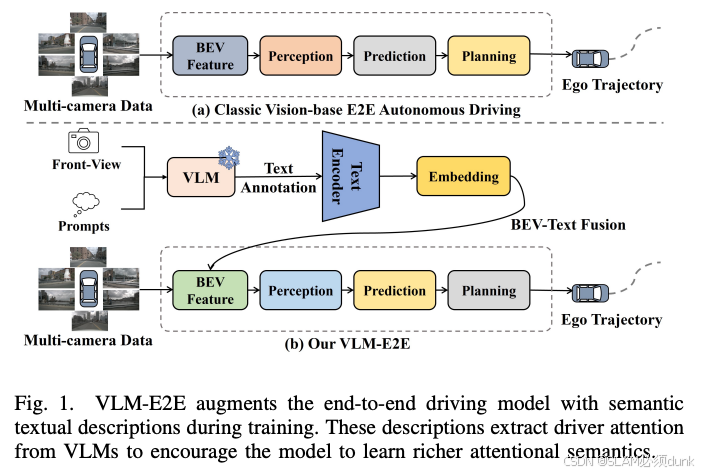
主要思路是VLM输出注入到BEV里,别的都是传统智驾e2e方案
一般VLA直接将前视图像token化之后输入VLA模型,如果是高分辨率图像的话,token数量太多,即使用英伟达H100也难以做到最低10Hz的下限。如果将图像提取特征,token数量会大幅度减少,但这样会增加一个特征提取模块,通常就是BEVFormer,这样就又回到了模块化分段端到端。
4)VLA兴起
日本图灵公司
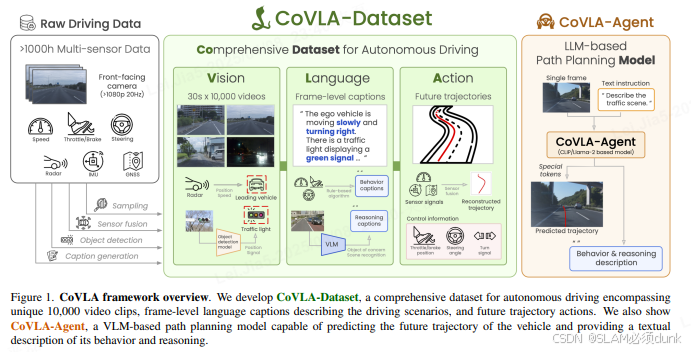
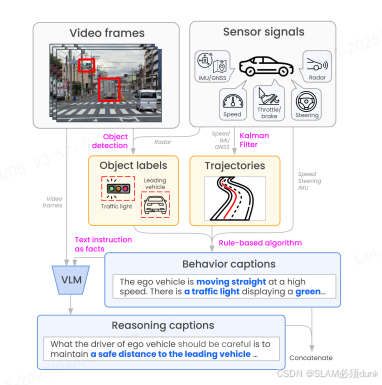
注意:对于object也做了交通信号灯检测和前车跟踪(交通流量理解)基于卷积神经网络(CNN),通过大量标注数据进行训练,以实现高精度的检测。
元戎启行
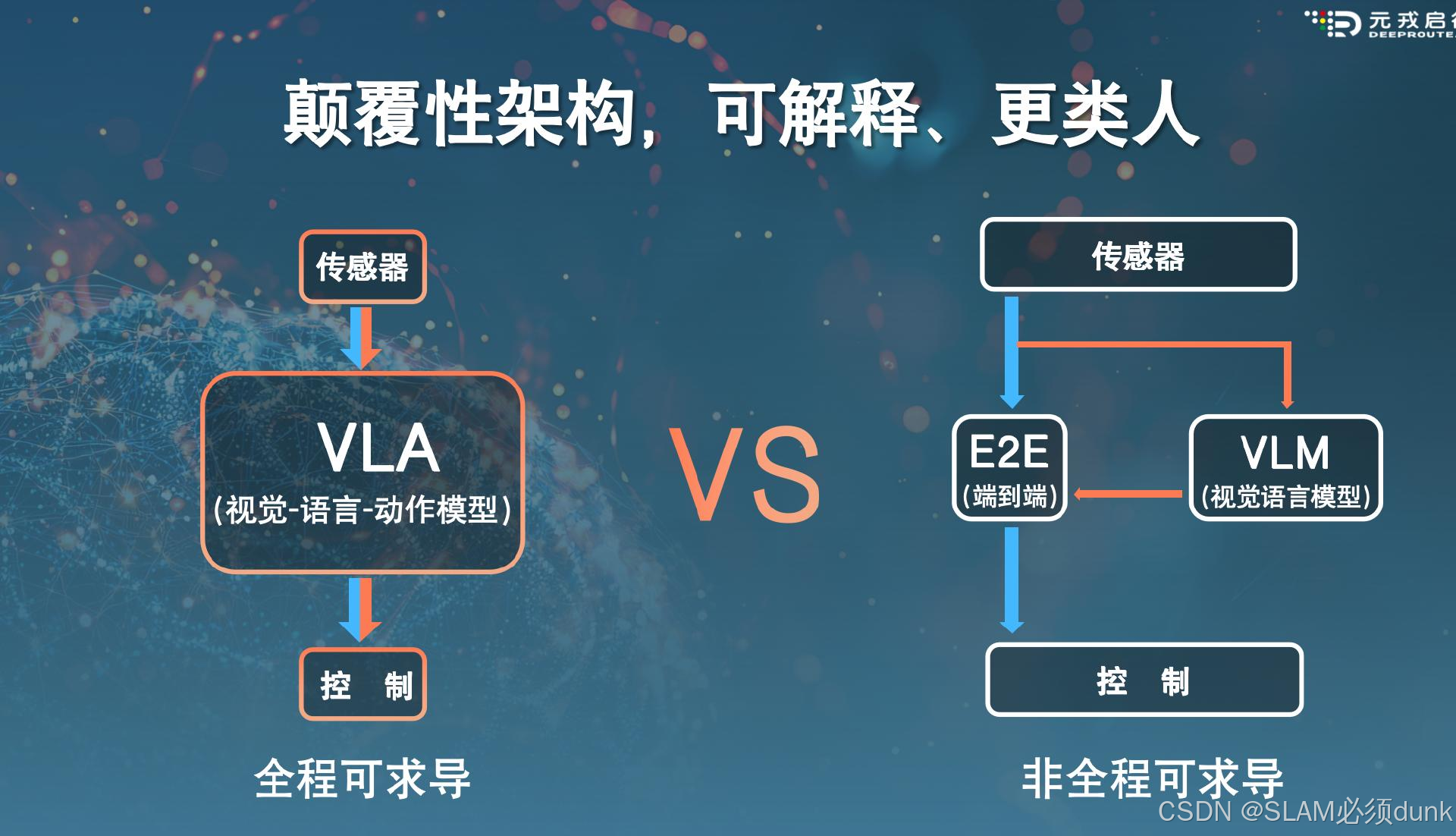
以下VLA从某种意义上讲还是快慢双系统,快系统是diffusion planner或policy,慢系统是LLM或VLM。
理想MindVLA
英伟达
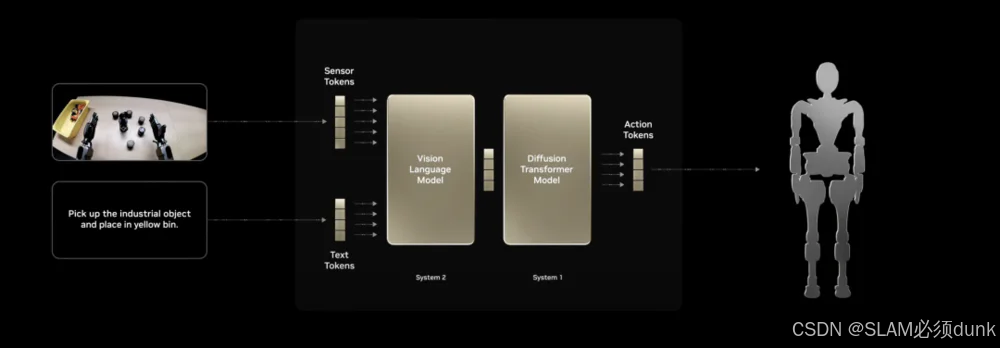
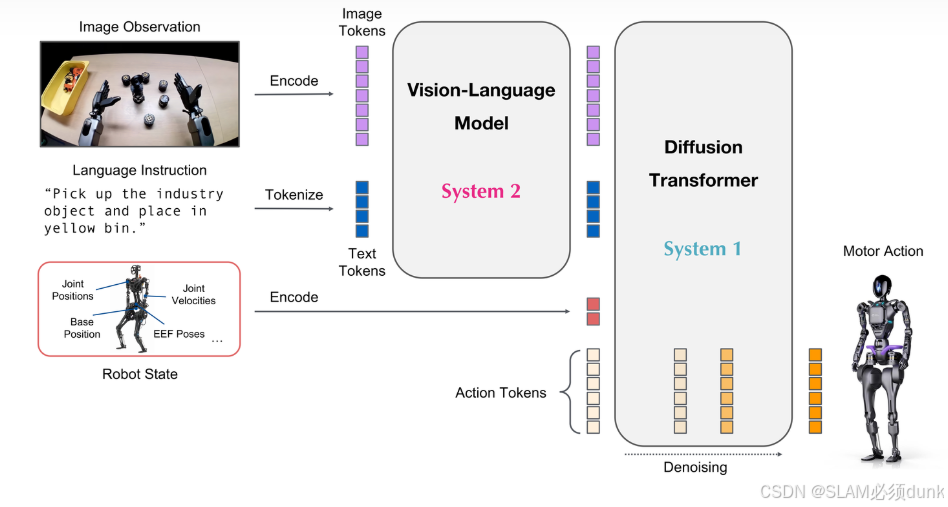
注意:
- 视觉-语言模型(System 2):基于 NVIDIA-Eagle 和 SmolLM-1.7B 构建,负责用视觉和语言指令理解环境,进行推理和规划,输出动作计划。
- 扩散变换器(System 1):该模块基于Diffusion Transformer(DiT),负责生成机器人的运动动作。DiT通过迭代去噪的方式生成动作块,输入包括噪声动作、机器人本体感知状态、图像标记和文本标记。DiT的输出经过特定机器人平台的动作解码器,生成最终的运动动作。GROOT N1采用了4步推理去噪,能够在保持高效的同时生成高质量的动作。
理想的DiT与diffusionPlanner的框架十分一致,diffusionPlanner的输入是“自车+他车的历史轨迹信息、车道线信息等”,输出是“自车+他车的轨迹概率评分”;理想的DiT输入也包括自车和他车相关的信息。根据diffusionPlanner的DiT结构,完成了一版VLM Token与DiT结合的模型。
公交车道、限时车道、交警指示、路边一些特殊文字指标、商店标牌的理解,以及理解之后的推理能力,如地库里根据各种标识来推测用户目的地在哪儿,该往哪里走。
- VL单独的能训Action Token我觉得很必要,这样不必各种标注文本啥的,在出问题时,也容易的区分到底是VL部分的问题还是Action部分的问题。(也不一定是Action Token,直接先用latent state MLP出轨迹也可以,主要就是仅VL部分也能独自监督)
- 同样的,DexVLA这种Action Model单独能训也很有意义。肌肉记忆也很有用。而智驾领域现在已经有成熟的e2e model了,基本上就是一个pretrained Action Model。
- 按RoboDual的结论,别的传感器、额外的感知识别网络也是能提升网络效果的。因此,现在的智驾里的感知等网络信息也很有用。
不过也存在可能是因为它没有让VL和A联合训练,所以导致仅使用VL的vision backbone提供的信息不够Action Model使用,这才显得额外的感知网络很有用。
但整体来说,我觉得不太应该放弃掉智驾领域成熟的感知网络。 - 智驾领域对于动态障碍物的响应需求是远高于机器人的,或者说当前相关方面的进展是领先于机器人界的。觉得可以参考MotionLM里的Token编码方式,不仅仅输出主车的Action Token,也要有障碍车的Action Token,联合预测建模。
- 长期确实应该还是用通用视频生成训个通用理解世界知识的模型,然后再加上自动驾驶的传感器和专用感知网络做微调DiT出Action。这个上限是最高的,但也明显,这类模型训的时候需要资源量也大。
但单纯的视频生成可能也不一定能够容易理解世界常识,还是要把语言中的知识注入进去的。类比于人类,如果没有语言传承,人类对世界许多知识的理解也会停留在很初期的阶段,每个个体都很难从零完整的学习并推理出很深层的现在我们认为是常识的东西——可能能做到的就跟猴子一样——让这样的智力的智能体来开车可能是比较难比现在的端到端带来什么增量价值的。
综上所述,选择基本的范式为多路径+多目标有更低的下限,vlm上限会很高但是并未探索出理想中的模型。