深度学习入门-05
基于小土堆学习
优化器是用于优化损失函数的;
常见的Transforms:

需要注意不同的数据格式;
class Compose:
"""Composes several transforms together. This transform does not support torchscript.
Please, see the note below.
Args:
transforms (list of ``Transform`` objects): list of transforms to compose.
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.PILToTensor(),
>>> transforms.ConvertImageDtype(torch.float),
>>> ])
.. note::
In order to script the transformations, please use ``torch.nn.Sequential`` as below.
>>> transforms = torch.nn.Sequential(
>>> transforms.CenterCrop(10),
>>> transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
>>> )
>>> scripted_transforms = torch.jit.script(transforms)
Make sure to use only scriptable transformations, i.e. that work with ``torch.Tensor``, does not require
`lambda` functions or ``PIL.Image``.
"""
def __init__(self, transforms):
if not torch.jit.is_scripting() and not torch.jit.is_tracing():
_log_api_usage_once(self)
self.transforms = transforms
def __call__(self, img):
for t in self.transforms:
img = t(img)
return img
def __repr__(self) -> str:
format_string = self.__class__.__name__ + "("
for t in self.transforms:
format_string += "\n"
format_string += f" {t}"
format_string += "\n)"
return format_string
这段代码定义了一个名为Compose的类,它用于将多个图像变换(transforms)组合在一起。这个类不是为了支持torchscript而设计的。Compose类接收一个变换对象列表作为输入,并允许按顺序对这些变换进行组合和执行。
构造函数__init__接收一个变换列表transforms,并将这个列表存储在实例变量self.transforms中。如果当前不是在torchscript的脚本化或追踪模式下,构造函数还会调用_log_api_usage_once(self)函数来记录API的使用情况(尽管这个函数在代码段中没有给出定义)。
__call__方法允许Compose实例像函数一样被调用。它遍历self.transforms中的每个变换,依次将图像img传递给这些变换,并返回最终的变换结果。
__repr__方法定义了Compose实例的字符串表示形式。它返回一个格式化的字符串,其中包含了Compose类名和所有组合的变换的字符串表示。
示例用法展示了如何使用Compose来组合多个图像变换,比如中心裁剪、将PIL图像转换为张量、以及转换图像数据类型。同时,注释也指出了如何使用torch.nn.Sequential来替代Compose进行脚本化变换,以及在使用torch.jit.script时需要注意的事项。
Compose 类在图像处理库中(如 torchvision.transforms)非常常见,它用于将多个图像变换步骤组合成一个单一的可调用对象。以下是一个使用 Compose 类的示例,假设我们已经在使用 PyTorch 和 torchvision:
import torchvision.transforms as transforms
from PIL import Image
# 定义一系列图像变换操作
transform_list = [
transforms.Resize((256, 256)), # 将图像大小调整为 256x256
transforms.CenterCrop(224), # 从图像中心裁剪出 224x224 的区域
transforms.ToTensor(), # 将 PIL 图像转换为 PyTorch 张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], # 标准化图像
std=[0.229, 0.224, 0.225])
]
# 使用 Compose 类将这些变换组合起来
transform = transforms.Compose(transform_list)
# 加载一张 PIL 图像
img = Image.open('path_to_your_image.jpg')
# 应用组合好的变换
transformed_img = transform(img)
# 此时 transformed_img 是一个 PyTorch 张量,可以用于模型推理等后续步骤
在这个示例中,我们首先导入 torchvision.transforms 模块,并定义了一个包含多个图像变换操作的列表 transform_list。然后,我们使用 transforms.Compose 将这些操作组合成一个单一的变换对象 transform。最后,我们加载一张 PIL 图像,并应用这个组合好的变换,得到可以用于后续步骤的 PyTorch 张量 transformed_img。
class Person:
def __call__(self, name):
print("__call__"+"Hello"+" "+name)
def hello(self,name):
print("hello"+" "+name)
person = Person()
person("ZHANGSAN")
person.hello("lisis")
对比person调用函数的情况
结果如下
C:\Anaconda3\envs\pytorch_test\python.exe H:\Python\Test\01test\CallTest.py
__call__Hello ZHANGSAN
hello lisis
输入函数名称后,在pycharm中单击ctrl+P,就可以提示出,当前需要输入什么参数;
1、 ToTensor使用
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
write = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)
#ToTensor()使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
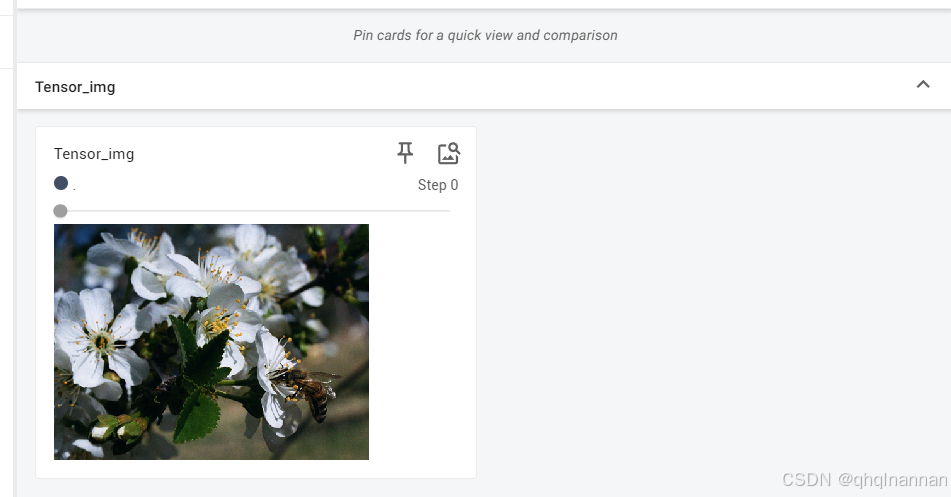
write.add_image("Tensor_img",img_tensor)
write.close()
在local中输入:
tensorboard --logdir logs --port=6007
结果为:
(pytorch_test) PS H:\Python\Test> tensorboard --logdir logs --port=6007
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.17.1 at http://localhost:6007/ (Press CTRL+C to quit)
单击6007网址,弹出:
class Normalize(torch.nn.Module):归一化使用
描述的是一个用于对张量图像进行标准化处理的变换操作。具体来说,它会根据给定的每个通道的均值(mean)和标准差(std),对输入张量图像的每个通道进行标准化处理。标准化处理的公式是:
output[channel] = (input[channel] - mean[channel]) / std[channel]
其中,output[channel] 表示输出张量在某个通道上的值,input[channel] 表示输入张量在该通道上的值,mean[channel] 和 std[channel] 分别表示该通道的均值和标准差。
这个变换操作不支持 PIL 图像,只能用于 PyTorch 的张量(torch.*Tensor)。
参数说明:
mean:一个序列,包含每个通道的均值。
std:一个序列,包含每个通道的标准差。
inplace:一个可选的布尔值,用于指定是否在原地(in-place)进行这个操作。如果设置为 True,则会直接在输入张量上进行修改,不会创建新的输出张量;如果设置为 False(默认值),则会创建一个新的输出张量,不会修改输入张量。
class Normalize(torch.nn.Module):
"""Normalize a tensor image with mean and standard deviation.
This transform does not support PIL Image.
Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n``
channels, this transform will normalize each channel of the input
``torch.*Tensor`` i.e.,
``output[channel] = (input[channel] - mean[channel]) / std[channel]``
.. note::
This transform acts out of place, i.e., it does not mutate the input tensor.
Args:
mean (sequence): Sequence of means for each channel.
std (sequence): Sequence of standard deviations for each channel.
inplace(bool,optional): Bool to make this operation in-place.
"""
def __init__(self, mean, std, inplace=False):
super().__init__()
_log_api_usage_once(self)
self.mean = mean
self.std = std
self.inplace = inplace
def forward(self, tensor: Tensor) -> Tensor:
"""
Args:
tensor (Tensor): Tensor image to be normalized.
Returns:
Tensor: Normalized Tensor image.
"""
return F.normalize(tensor, self.mean, self.std, self.inplace)
def __repr__(self) -> str:
return f"{self.__class__.__name__}(mean={self.mean}, std={self.std})"
这段代码定义了一个名为 Normalize 的类,它是 torch.nn.Module 的子类,用于对张量图像进行标准化处理。这个类不接受 PIL 图像作为输入,只处理 PyTorch 的张量(torch.*Tensor)。
在初始化函数 init 中,它接收三个参数:mean、std 和 inplace。mean 和 std 分别是每个通道的均值和标准差,它们都是序列类型。inplace 是一个可选的布尔值,用于指定是否在原地(in-place)进行标准化操作。
forward 函数是类的核心,它接收一个张量作为输入,并返回标准化后的张量。在这个函数中,它调用了 F.normalize 方法来执行标准化操作。F.normalize 方法是 PyTorch 提供的一个函数,用于对张量进行标准化。它接收输入张量、均值、标准差和 inplace 参数,并返回标准化后的张量。
repr 函数返回了类的字符串表示,包括类名和初始化时设置的均值和标准差。
需要注意的是,代码中的 _log_api_usage_once(self) 调用似乎是一个自定义的函数,用于记录 API 的使用情况,但在代码片段中没有给出这个函数的定义。在实际使用中,你可能需要替换或删除这个调用,或者提供 _log_api_usage_once 函数的定义。
另外,F.normalize 函数在 PyTorch 中实际上并不直接提供按照均值和标准差进行标准化的功能。通常,标准化是通过计算 (input - mean) / std 来实现的,而不是使用 F.normalize。因此,这里的 F.normalize 调用可能是一个错误或者是一个自定义的函数。在实际应用中,你应该使用正确的标准化方法来实现这个功能。
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
write = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)
#ToTensor()使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
print("img_tensor[0][0][0]:",img_tensor[0][0][0])
#class Normalize(torch.nn.Module):使用
trans_norm = transforms.Normalize([0.5,2,6],[0.5,3,0.5])
#此处的均值和方差为随机输入的,实际下可以计算影像的每个波段的均值和方差
img_norm = trans_norm(img_tensor)
#因为是RGB三通道,因此需要输入三个均值和三个标准差
print("img_norm[0][0][0]:",img_norm[0][0][0])
write.add_image("Tensor_img",img_tensor)
write.add_image("Norm",img_norm)
write.close()
代码运行结果:
C:\Anaconda3\envs\pytorch_test\python.exe H:\Python\Test\P10_Usefultransforms.py
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x374 at 0x20E95332EC0>
img_tensor[0][0][0]: tensor(0.1451)
img_norm[0][0][0]: tensor(-0.7098)
进程已结束,退出代码0
TensorBoard结果:
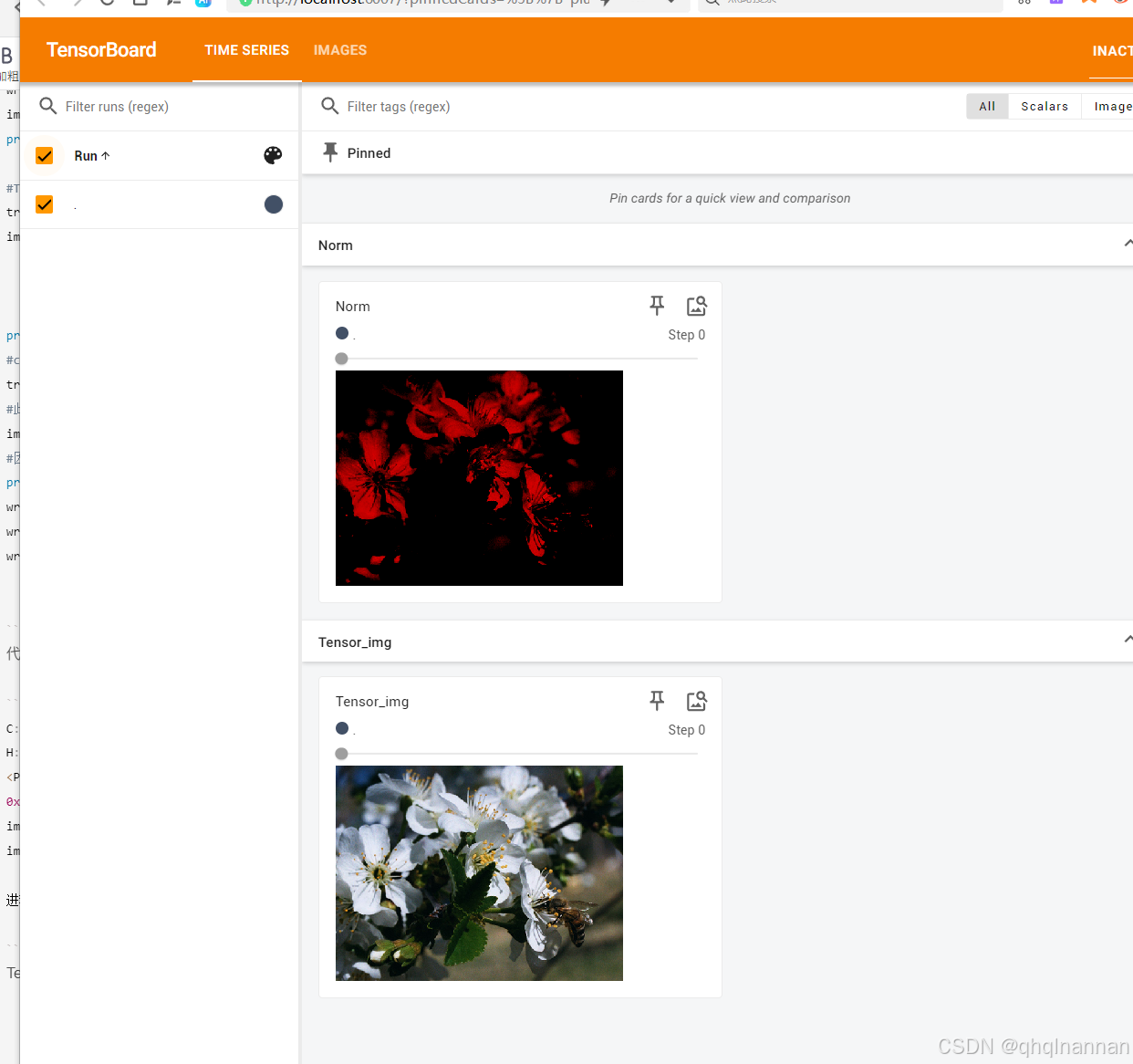
Resize使用
函数介绍见前篇博文
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
write = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)
#ToTensor()使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
print("img_tensor[0][0][0]:",img_tensor[0][0][0])
#class Normalize(torch.nn.Module):使用
trans_norm = transforms.Normalize([0.5,2,6],[0.5,3,0.5])
#此处的均值和方差为随机输入的,实际下可以计算影像的每个波段的均值和方差
img_norm = trans_norm(img_tensor)
#因为是RGB三通道,因此需要输入三个均值和三个标准差
print("img_norm[0][0][0]:",img_norm[0][0][0])
#Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img_tensor)
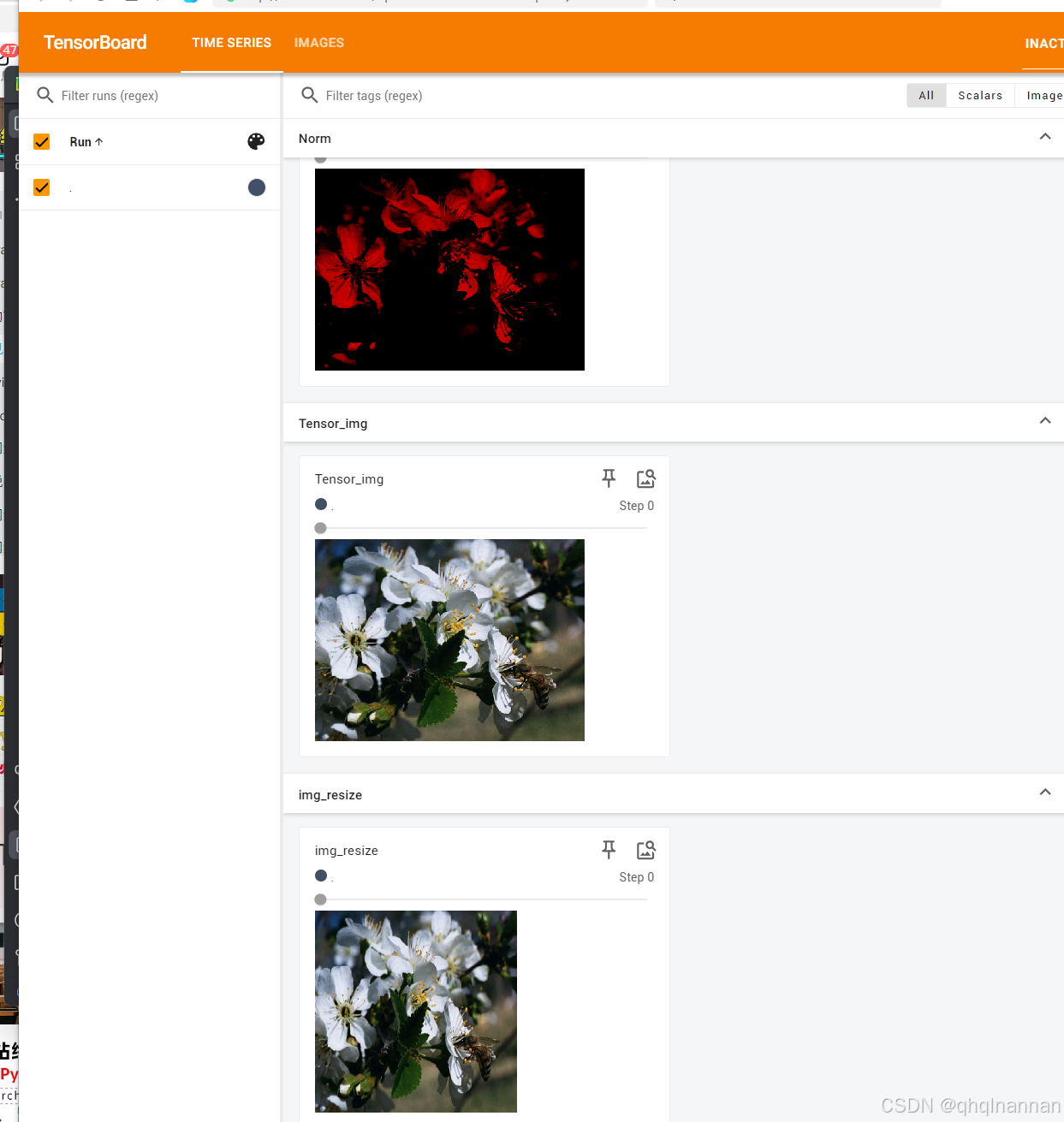
write.add_image("Tensor_img",img_tensor)
write.add_image("Norm",img_norm)
write.add_image("img_resize ",img_resize )
write.close()
输出结果为
C:\Anaconda3\envs\pytorch_test\python.exe H:\Python\Test\P10_Usefultransforms.py
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x374 at 0x1EC84B9B1C0>
img_tensor[0][0][0]: tensor(0.1451)
img_norm[0][0][0]: tensor(-0.7098)
(500, 374)
进程已结束,退出代码0
通过该处理,将(500, 374)的图像变换为了(512,512)
Compose使用
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
write = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)
#ToTensor()使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
print("img_tensor[0][0][0]:",img_tensor[0][0][0])
#class Normalize(torch.nn.Module):使用
trans_norm = transforms.Normalize([0.5,2,6],[0.5,3,0.5])
#此处的均值和方差为随机输入的,实际下可以计算影像的每个波段的均值和方差
img_norm = trans_norm(img_tensor)
#因为是RGB三通道,因此需要输入三个均值和三个标准差
print("img_norm[0][0][0]:",img_norm[0][0][0])
#Resize
print("img.size:",img.size)
trans_resize = transforms.Resize((1024,512))
img_resize = trans_resize(img_tensor)
print("img_resize:",img_resize)
#Compose
trans_resize_2 = transforms.Resize((1024,600))
trans_compose = transforms.Compose([trans_resize_2 ,trans_totensor,trans_norm])#后一个的输入必须要和前一个的输出匹配
img_compose = trans_compose(img)
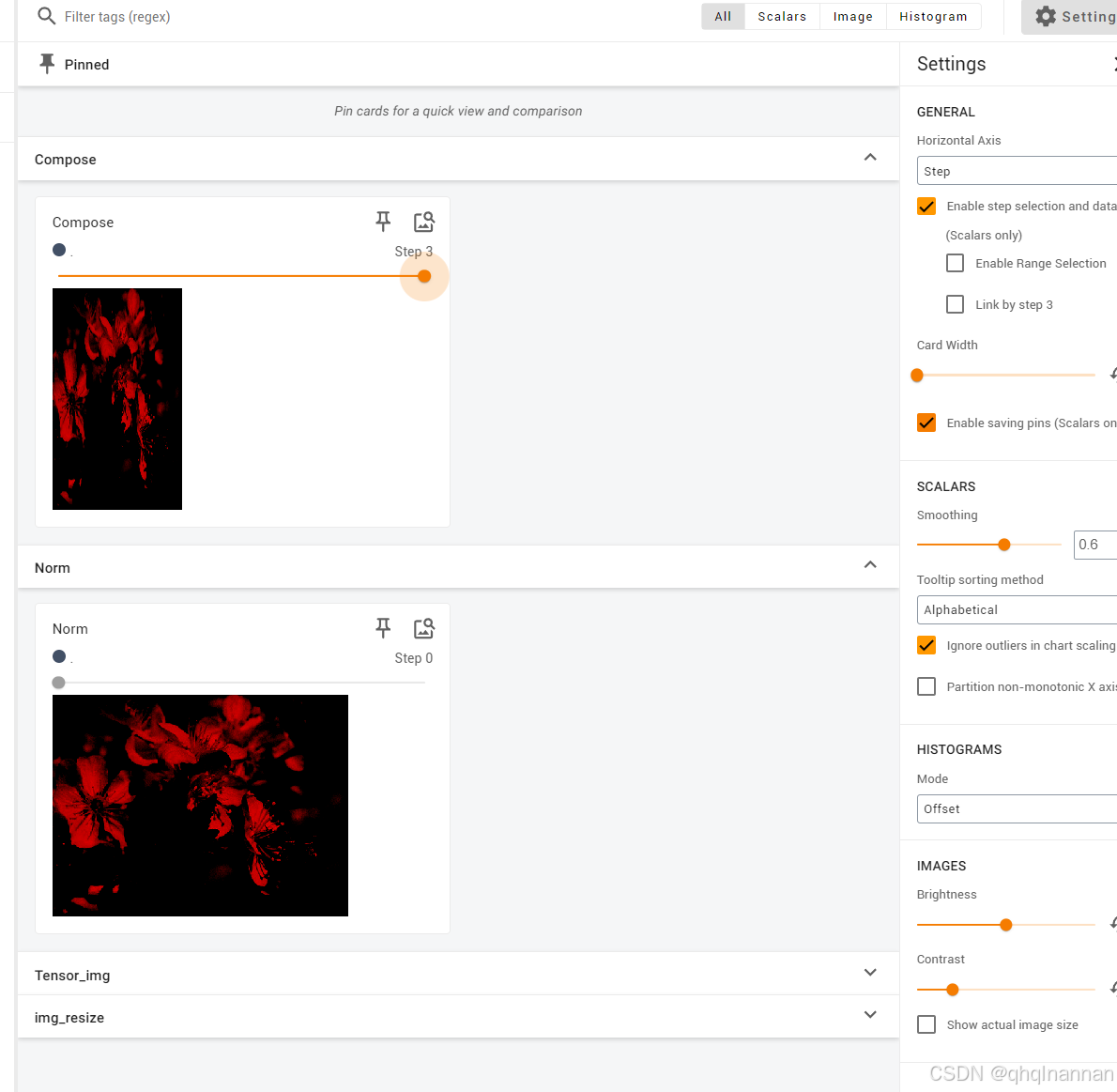
write.add_image("Compose",img_compose,3)
write.add_image("Tensor_img",img_tensor)
write.add_image("Norm",img_norm)
write.add_image("img_resize ",img_resize ,1)
write.close()
输出结果为:
C:\Anaconda3\envs\pytorch_test\python.exe H:\Python\Test\P10_Usefultransforms.py
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x374 at 0x2419D6B35E0>
img_tensor[0][0][0]: tensor(0.1451)
img_norm[0][0][0]: tensor(-0.7098)
img.size: (500, 374)
img_resize: tensor([[[0.1451, 0.1716, 0.1799, ..., 0.1317, 0.1692, 0.1843],
[0.1466, 0.1711, 0.1785, ..., 0.1310, 0.1692, 0.1851],
[0.1581, 0.1674, 0.1674, ..., 0.1256, 0.1694, 0.1908],
...,
[0.3036, 0.2894, 0.2652, ..., 0.3344, 0.3145, 0.3170],
[0.3021, 0.2838, 0.2608, ..., 0.3359, 0.3172, 0.3141],
[0.3020, 0.2830, 0.2602, ..., 0.3361, 0.3175, 0.3137]],
[[0.2431, 0.2431, 0.2394, ..., 0.2143, 0.2548, 0.2510],
[0.2443, 0.2441, 0.2395, ..., 0.2132, 0.2543, 0.2523],
[0.2529, 0.2513, 0.2399, ..., 0.2049, 0.2505, 0.2623],
...,
[0.3275, 0.3044, 0.2740, ..., 0.3261, 0.2996, 0.2967],
[0.3361, 0.3033, 0.2726, ..., 0.3274, 0.2980, 0.2909],
[0.3373, 0.3032, 0.2724, ..., 0.3276, 0.2978, 0.2902]],
[[0.4000, 0.3849, 0.3548, ..., 0.0872, 0.1664, 0.2118],
[0.4013, 0.3856, 0.3554, ..., 0.0863, 0.1664, 0.2133],
[0.4113, 0.3915, 0.3597, ..., 0.0796, 0.1668, 0.2247],
...,
[0.2265, 0.2236, 0.2051, ..., 0.2404, 0.2115, 0.2055],
[0.2308, 0.2238, 0.2051, ..., 0.2445, 0.2115, 0.2041],
[0.2314, 0.2238, 0.2051, ..., 0.2450, 0.2115, 0.2039]]])
进程已结束,退出代码0
随机裁剪RandomCrop
这段代码描述的是一个图像处理操作,即在给定的图像上随机位置进行裁剪。这个操作适用于torch张量图像,并且支持不同的裁剪参数和填充模式。下面是详细的解释:
- size:指定裁剪后图像的大小。如果size是一个整数,那么裁剪的图像将是正方形(size x
size)。如果size是一个长度为1的序列,那么它将被解释为(size[0], size[0]),即正方形裁剪。 - padding:可选参数,用于在图像边界上添加填充。如果提供了一个整数,所有边界都将使用相同的填充。如果提供了长度为2的序列,分别表示左右和上下边界的填充。如果提供了长度为4的序列,分别表示左、上、右、下边界的填充。在torchscript模式下,不支持单个整数的填充,应使用长度为1的序列。
- pad_if_needed:布尔值参数,如果图像小于所需的大小,将自动添加填充以避免引发异常。由于裁剪是在填充之后进行的,所以填充看起来是在随机偏移处进行的。
- fill:用于常数填充的像素填充值。默认是0。如果是一个长度为3的元组,它将分别用于填充R、G、B通道。这个值仅当padding_mode是constant时使用。对于torch张量,仅支持数字填充值;对于PIL图像,支持整数或元组值。
- padding_mode:填充类型,应该是constant、edge、reflect或symmetric之一。默认是constant。
- constant:使用fill指定的常数值进行填充。
- edge:使用边缘的最后一个值进行填充。如果输入是5D torch张量,则最后3个维度将被填充,而不是最后2个。
- reflect:使用图像的反射进行填充,但不重复边缘的最后一个值。
- symmetric:使用图像的反射进行填充,重复边缘的最后一个值。
这个操作允许对图像进行灵活的裁剪和填充处理,适用于不同的图像处理需求。
class RandomCrop(torch.nn.Module):
"""Crop the given image at a random location.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions,
but if non-constant padding is used, the input is expected to have at most 2 leading dimensions
Args:
size (sequence or int): Desired output size of the crop. If size is an
int instead of sequence like (h, w), a square crop (size, size) is
made. If provided a sequence of length 1, it will be interpreted as (size[0], size[0]).
padding (int or sequence, optional): Optional padding on each border
of the image. Default is None. If a single int is provided this
is used to pad all borders. If sequence of length 2 is provided this is the padding
on left/right and top/bottom respectively. If a sequence of length 4 is provided
this is the padding for the left, top, right and bottom borders respectively.
.. note::
In torchscript mode padding as single int is not supported, use a sequence of
length 1: ``[padding, ]``.
pad_if_needed (boolean): It will pad the image if smaller than the
desired size to avoid raising an exception. Since cropping is done
after padding, the padding seems to be done at a random offset.
fill (number or tuple): Pixel fill value for constant fill. Default is 0. If a tuple of
length 3, it is used to fill R, G, B channels respectively.
This value is only used when the padding_mode is constant.
Only number is supported for torch Tensor.
Only int or tuple value is supported for PIL Image.
padding_mode (str): Type of padding. Should be: constant, edge, reflect or symmetric.
Default is constant.
- constant: pads with a constant value, this value is specified with fill
- edge: pads with the last value at the edge of the image.
If input a 5D torch Tensor, the last 3 dimensions will be padded instead of the last 2
- reflect: pads with reflection of image without repeating the last value on the edge.
For example, padding [1, 2, 3, 4] with 2 elements on both sides in reflect mode
will result in [3, 2, 1, 2, 3, 4, 3, 2]
- symmetric: pads with reflection of image repeating the last value on the edge.
For example, padding [1, 2, 3, 4] with 2 elements on both sides in symmetric mode
will result in [2, 1, 1, 2, 3, 4, 4, 3]
"""
@staticmethod
def get_params(img: Tensor, output_size: Tuple[int, int]) -> Tuple[int, int, int, int]:
"""Get parameters for ``crop`` for a random crop.
Args:
img (PIL Image or Tensor): Image to be cropped.
output_size (tuple): Expected output size of the crop.
Returns:
tuple: params (i, j, h, w) to be passed to ``crop`` for random crop.
"""
_, h, w = F.get_dimensions(img)
th, tw = output_size
if h < th or w < tw:
raise ValueError(f"Required crop size {(th, tw)} is larger than input image size {(h, w)}")
if w == tw and h == th:
return 0, 0, h, w
i = torch.randint(0, h - th + 1, size=(1,)).item()
j = torch.randint(0, w - tw + 1, size=(1,)).item()
return i, j, th, tw
def __init__(self, size, padding=None, pad_if_needed=False, fill=0, padding_mode="constant"):
super().__init__()
_log_api_usage_once(self)
self.size = tuple(_setup_size(size, error_msg="Please provide only two dimensions (h, w) for size."))
self.padding = padding
self.pad_if_needed = pad_if_needed
self.fill = fill
self.padding_mode = padding_mode
def forward(self, img):
"""
Args:
img (PIL Image or Tensor): Image to be cropped.
Returns:
PIL Image or Tensor: Cropped image.
"""
if self.padding is not None:
img = F.pad(img, self.padding, self.fill, self.padding_mode)
_, height, width = F.get_dimensions(img)
# pad the width if needed
if self.pad_if_needed and width < self.size[1]:
padding = [self.size[1] - width, 0]
img = F.pad(img, padding, self.fill, self.padding_mode)
# pad the height if needed
if self.pad_if_needed and height < self.size[0]:
padding = [0, self.size[0] - height]
img = F.pad(img, padding, self.fill, self.padding_mode)
i, j, h, w = self.get_params(img, self.size)
return F.crop(img, i, j, h, w)
def __repr__(self) -> str:
return f"{self.__class__.__name__}(size={self.size}, padding={self.padding})"
这段代码定义了一个名为 RandomCrop 的 PyTorch 模块,用于在给定图像上执行随机裁剪操作。这个模块是继承自 torch.nn.Module,使得它可以作为神经网络的一部分。以下是详细的解释和示例:
解释
初始化 (init 方法):
-
size: 期望的输出裁剪大小。可以是一个整数(表示正方形裁剪),或者是一个包含两个整数的元组(表示高度和宽度)。
-
padding: 可选的填充参数,用于在图像边界上添加填充。可以是一个整数、一个长度为2的序列(表示左右和上下边界的填充),或者是一个长度为4的序列(表示左、上、右、下边界的填充)。
-
pad_if_needed: 布尔值,如果图像小于所需的大小,则自动添加填充以避免引发异常。
-
fill: 用于常数填充的像素填充值。默认是0。
-
padding_mode: 填充类型,可以是 constant、edge、reflect 或 symmetric。
-
get_params 方法:
计算随机裁剪的参数,包括裁剪的起始坐标和裁剪的高度和宽度。 -
forward 方法:
执行裁剪操作。首先,如果设置了填充,则对图像进行填充。然后,如果 pad_if_needed 为真且图像尺寸小于所需裁剪尺寸,则进一步填充图像。最后,使用 get_params 方法计算的裁剪参数对图像进行裁剪。
示例
假设我们有一个大小为 (3, 256, 256) 的图像(即3个通道,高度和宽度都是256),我们想随机裁剪出一个大小为 (128, 128) 的图像。
import torch
from torchvision.transforms import RandomCrop
# 创建一个随机裁剪模块,裁剪大小为128x128
crop_transform = RandomCrop(size=(128, 128))
# 假设我们有一个大小为 (3, 256, 256) 的图像
image = torch.randn(3, 256, 256)
# 应用裁剪
cropped_image = crop_transform(image)
# 输出裁剪后的图像大小
print(cropped_image.shape) # 应该输出 torch.Size([3, 128, 128])
示例代码:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
write = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)
#ToTensor()使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
print("img_tensor[0][0][0]:",img_tensor[0][0][0])
#class Normalize(torch.nn.Module):使用
trans_norm = transforms.Normalize([0.5,2,6],[0.5,3,0.5])
#此处的均值和方差为随机输入的,实际下可以计算影像的每个波段的均值和方差
img_norm = trans_norm(img_tensor)
#因为是RGB三通道,因此需要输入三个均值和三个标准差
print("img_norm[0][0][0]:",img_norm[0][0][0])
#Resize
print("img.size:",img.size)
trans_resize = transforms.Resize((1024,512))
img_resize = trans_resize(img_tensor)
print("img_resize:",img_resize)
#Compose
trans_resize_2 = transforms.Resize((1024,600))
trans_compose = transforms.Compose([trans_resize_2 ,trans_totensor,trans_norm])
img_compose = trans_compose(img)
#RandomCrop
trans_randomcrop = transforms.RandomCrop(size=(100,50))
img_randomcrop = trans_randomcrop(img_tensor)
shape = img_tensor.shape
print("img_resize shape:",shape)
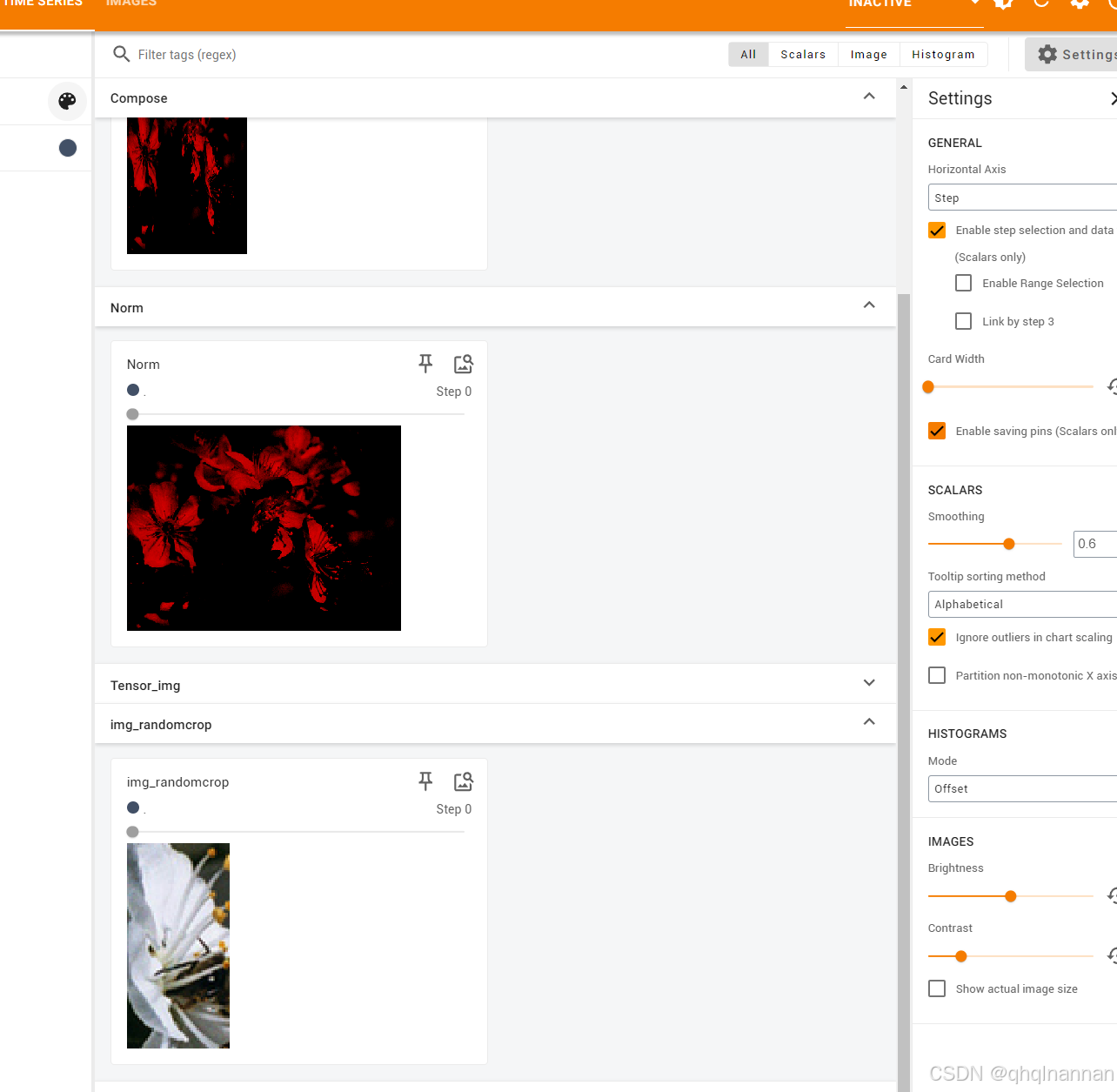
write.add_image("img_randomcrop",img_randomcrop,0)
write.add_image("Compose",img_compose,3)
write.add_image("Tensor_img",img_tensor)
write.add_image("Norm",img_norm)
write.add_image("img_resize ",img_resize ,1)
write.close()
结果为:
C:\Anaconda3\envs\pytorch_test\python.exe H:\Python\Test\P10_Usefultransforms.py
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x374 at 0x16586E878B0>
img_tensor[0][0][0]: tensor(0.1451)
img_norm[0][0][0]: tensor(-0.7098)
img.size: (500, 374)
img_resize: tensor([[[0.1451, 0.1716, 0.1799, ..., 0.1317, 0.1692, 0.1843],
[0.1466, 0.1711, 0.1785, ..., 0.1310, 0.1692, 0.1851],
[0.1581, 0.1674, 0.1674, ..., 0.1256, 0.1694, 0.1908],
...,
[0.3036, 0.2894, 0.2652, ..., 0.3344, 0.3145, 0.3170],
[0.3021, 0.2838, 0.2608, ..., 0.3359, 0.3172, 0.3141],
[0.3020, 0.2830, 0.2602, ..., 0.3361, 0.3175, 0.3137]],
[[0.2431, 0.2431, 0.2394, ..., 0.2143, 0.2548, 0.2510],
[0.2443, 0.2441, 0.2395, ..., 0.2132, 0.2543, 0.2523],
[0.2529, 0.2513, 0.2399, ..., 0.2049, 0.2505, 0.2623],
...,
[0.3275, 0.3044, 0.2740, ..., 0.3261, 0.2996, 0.2967],
[0.3361, 0.3033, 0.2726, ..., 0.3274, 0.2980, 0.2909],
[0.3373, 0.3032, 0.2724, ..., 0.3276, 0.2978, 0.2902]],
[[0.4000, 0.3849, 0.3548, ..., 0.0872, 0.1664, 0.2118],
[0.4013, 0.3856, 0.3554, ..., 0.0863, 0.1664, 0.2133],
[0.4113, 0.3915, 0.3597, ..., 0.0796, 0.1668, 0.2247],
...,
[0.2265, 0.2236, 0.2051, ..., 0.2404, 0.2115, 0.2055],
[0.2308, 0.2238, 0.2051, ..., 0.2445, 0.2115, 0.2041],
[0.2314, 0.2238, 0.2051, ..., 0.2450, 0.2115, 0.2039]]])
img_resize shape: torch.Size([3, 374, 500])
进程已结束,退出代码0
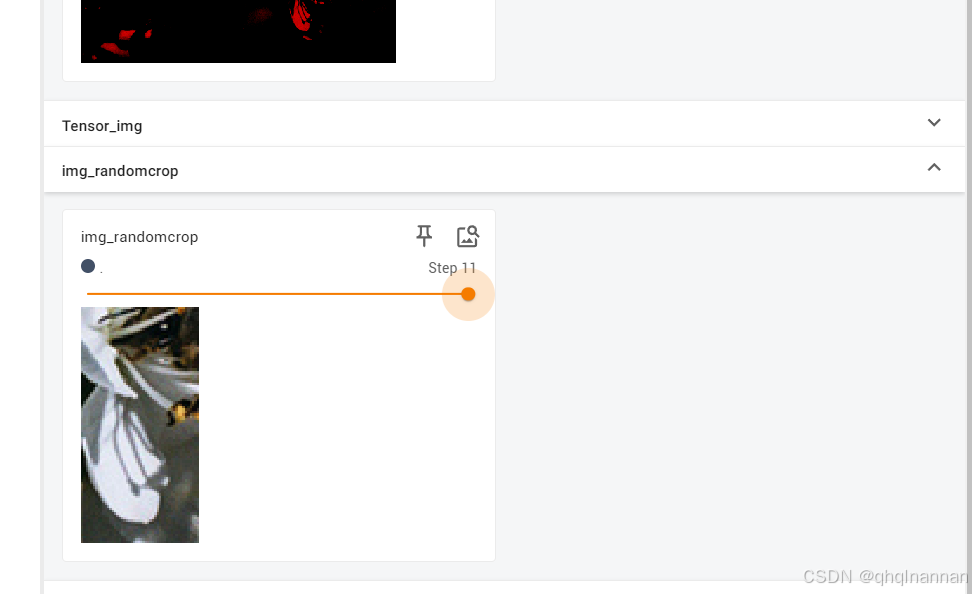
可以用for循环进行随机裁剪:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
write = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)
#ToTensor()使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
print("img_tensor[0][0][0]:",img_tensor[0][0][0])
#class Normalize(torch.nn.Module):使用
trans_norm = transforms.Normalize([0.5,2,6],[0.5,3,0.5])
#此处的均值和方差为随机输入的,实际下可以计算影像的每个波段的均值和方差
img_norm = trans_norm(img_tensor)
#因为是RGB三通道,因此需要输入三个均值和三个标准差
print("img_norm[0][0][0]:",img_norm[0][0][0])
#Resize
print("img.size:",img.size)
trans_resize = transforms.Resize((1024,512))
img_resize = trans_resize(img_tensor)
print("img_resize:",img_resize)
#Compose
trans_resize_2 = transforms.Resize((1024,600))
trans_compose = transforms.Compose([trans_resize_2 ,trans_totensor,trans_norm])
img_compose = trans_compose(img)
#RandomCrop
trans_randomcrop = transforms.RandomCrop(size=(100,50))
for i in range(12):
img_randomcrop = trans_randomcrop(img_tensor)
shape = img_tensor.shape
print("img_resize shape:", shape)
write.add_image("img_randomcrop", img_randomcrop, i)
write.add_image("Compose",img_compose,3)
write.add_image("Tensor_img",img_tensor)
write.add_image("Norm",img_norm)
write.add_image("img_resize ",img_resize ,1)
write.close()
结果为:
C:\Anaconda3\envs\pytorch_test\python.exe H:\Python\Test\P10_Usefultransforms.py
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x374 at 0x1F771D07970>
img_tensor[0][0][0]: tensor(0.1451)
img_norm[0][0][0]: tensor(-0.7098)
img.size: (500, 374)
img_resize: tensor([[[0.1451, 0.1716, 0.1799, ..., 0.1317, 0.1692, 0.1843],
[0.1466, 0.1711, 0.1785, ..., 0.1310, 0.1692, 0.1851],
[0.1581, 0.1674, 0.1674, ..., 0.1256, 0.1694, 0.1908],
...,
[0.3036, 0.2894, 0.2652, ..., 0.3344, 0.3145, 0.3170],
[0.3021, 0.2838, 0.2608, ..., 0.3359, 0.3172, 0.3141],
[0.3020, 0.2830, 0.2602, ..., 0.3361, 0.3175, 0.3137]],
[[0.2431, 0.2431, 0.2394, ..., 0.2143, 0.2548, 0.2510],
[0.2443, 0.2441, 0.2395, ..., 0.2132, 0.2543, 0.2523],
[0.2529, 0.2513, 0.2399, ..., 0.2049, 0.2505, 0.2623],
...,
[0.3275, 0.3044, 0.2740, ..., 0.3261, 0.2996, 0.2967],
[0.3361, 0.3033, 0.2726, ..., 0.3274, 0.2980, 0.2909],
[0.3373, 0.3032, 0.2724, ..., 0.3276, 0.2978, 0.2902]],
[[0.4000, 0.3849, 0.3548, ..., 0.0872, 0.1664, 0.2118],
[0.4013, 0.3856, 0.3554, ..., 0.0863, 0.1664, 0.2133],
[0.4113, 0.3915, 0.3597, ..., 0.0796, 0.1668, 0.2247],
...,
[0.2265, 0.2236, 0.2051, ..., 0.2404, 0.2115, 0.2055],
[0.2308, 0.2238, 0.2051, ..., 0.2445, 0.2115, 0.2041],
[0.2314, 0.2238, 0.2051, ..., 0.2450, 0.2115, 0.2039]]])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
img_resize shape: torch.Size([3, 374, 500])
进程已结束,退出代码0
总结
多关注官方文档
- 关注每个类的输入和输出
- 确定出数据类型,不确定输出类型的可以用print(img),或者在控制台查看数据的类型
- 关注方法需要什么参数,按照说明文档穿参数
- 不知道返回值的时候,可以使用print