第九章:前沿 RAG 技术探索
9.0 引言:RAG 技术的未来趋势与挑战
检索增强生成(Retrieval-Augmented Generation, RAG)技术已成为提升大规模语言模型(LLMs)知识水平和生成质量的关键范式。然而,为了应对日益复杂的应用需求,研究社区正积极探索 RAG 的前沿技术,旨在克服现有挑战并拓展其能力边界。本章将深入探讨这些令人兴奋的进展,从自适应优化到多模态融合,再到与智能 Agent 的协同,以及更前沿的探索方向。
9.1 检索增强生成 (Retrieval Augmented Generation, RAG)
检索增强生成 (Retrieval Augmented Generation, RAG) 是一种强大的技术,旨在通过利用外部知识源来弥补大型语言模型 (LLM) 仅依赖其内部参数化知识的局限性。RAG 的核心思想是在生成文本的过程中,模型能够检索相关文档,并将这些信息融入到最终的输出中,从而提高生成内容的准确性、信息量和时效性。
在这里插入图片描述
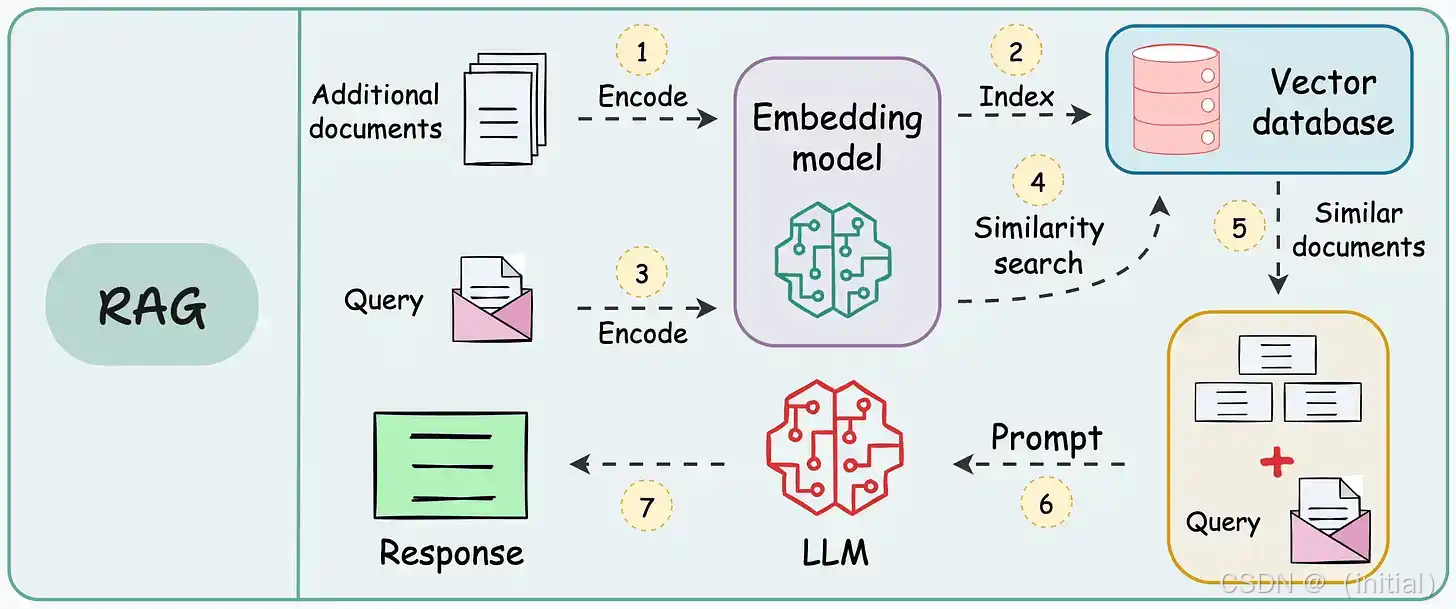
9.1.1 传统 RAG 的局限性
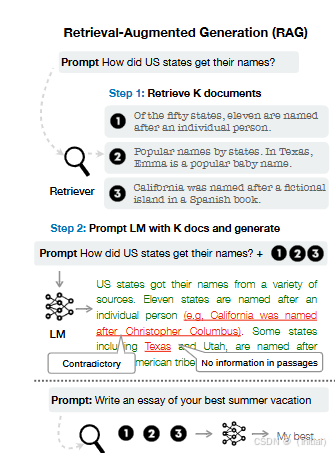
早期的 RAG 方法通常采用相对固定的流程:给定一个输入查询,模型会检索出Top-K个相关的文档,然后将这些文档与原始查询拼接起来作为上下文,输入到语言模型中进行生成。然而,这种传统方法存在一些固有的局限性:
- 无差别的检索: 无论检索到的文档是否真正相关或对生成有帮助,模型都会尝试利用它们。这可能导致模型被不相关的信息干扰,或者遗漏真正关键的信息。
- 生成与检索的脱节: 模型在生成过程中可能无法有效地利用检索到的信息,导致生成的内容与检索到的证据不一致,甚至产生矛盾。
9.1.2 Corrective Retrieval Augmented Generation (CRAG)
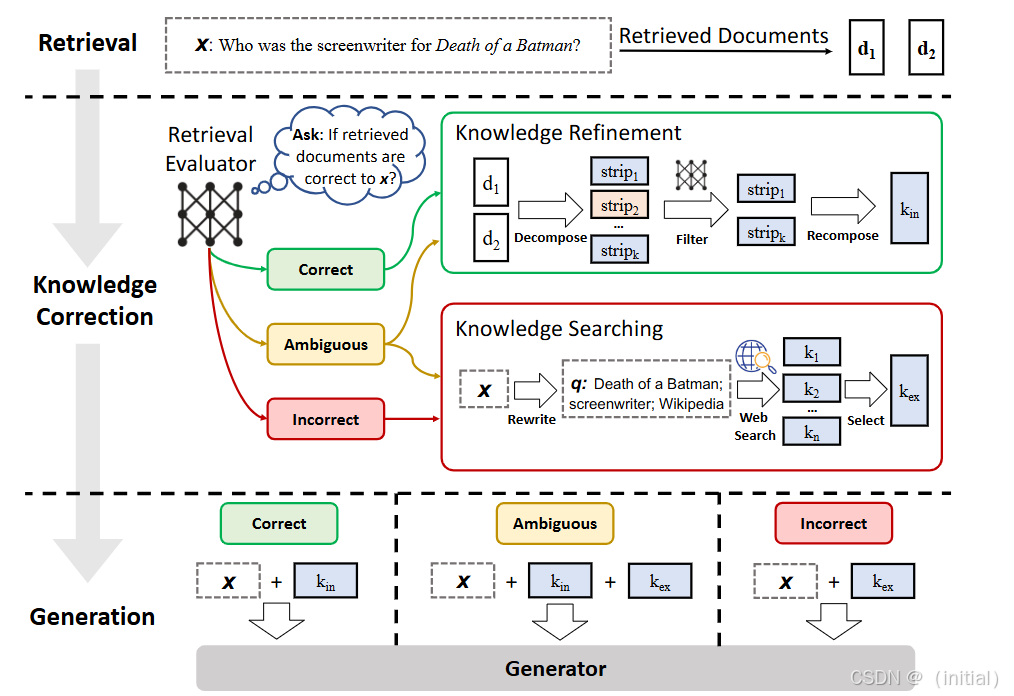
为了应对传统 RAG 的这些挑战,Corrective Retrieval Augmented Generation (CRAG) 被提出。CRAG 的核心在于引入了对检索过程的评估与修正机制,其侧重点在于提高检索质量。
- 检索评估: CRAG 模型能够评估检索到的文档的相关性和质量。
- 检索修正: 基于评估结果,如果模型认为检索到的信息不理想(例如,相关性低、信息不足),它可以触发重新检索或调整检索策略,以获取更合适的知识。
概念上,CRAG 就像一个严谨的学者,在写作时会仔细筛选参考资料,确保所引用的信息是准确且相关的。通过这种方式,CRAG 旨在为生成模型提供更可靠的知识基础。
9.1.3 Self-RAG: 通过自我反思学习检索、生成和评价
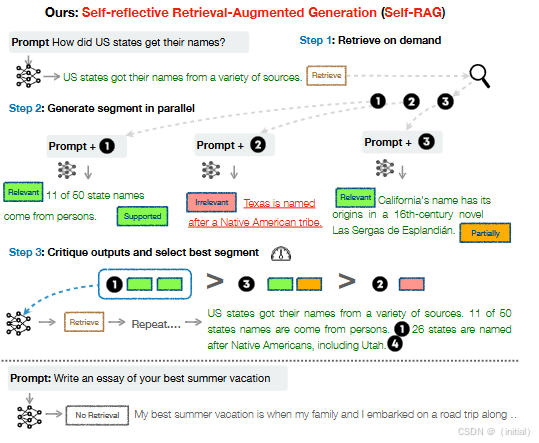
Self-RAG 是一个更先进的框架,它不仅关注检索,更强调模型在生成全流程中的自主性和质量控制。其核心侧重点在于提升生成质量和事实准确性,并使模型具备更强的自我评估和改进能力。
- 自我反思: Self-RAG 训练模型生成特殊的“反思令牌”,这些令牌用于指示模型进行自我评估,包括判断是否需要检索、检索到的文档是否相关、生成的内容是否与检索到的证据一致,以及最终生成的回应是否有用。
- 按需检索: 模型能够根据输入和生成过程中的需求,动态地决定是否需要进行检索,甚至可以多次检索。
- 细粒度评价与选择: 模型在生成每个片段时,会对检索到的多个文档进行评估,并基于评估结果和生成概率选择最佳的片段。
- 整体效用评价: 在生成完整的回应后,模型还会评估整个回应的质量。
概念上,Self-RAG 就像一个经验丰富的作家,不仅会查找资料,还会不断地审视自己的写作过程,判断哪些信息需要进一步补充,哪些内容需要修改,以确保最终作品的质量。
9.2 多模态 RAG:结合图像、音频等多模态信息检索
现实世界的信息往往以多种模态呈现。多模态 RAG 旨在将图像、音频等非文本信息融入 RAG 流程。关键在于构建能够理解和匹配不同模态信息的 Embedding 模型,例如 Visual-Language Transformers (Li et al., 2019) 和 CLIP (Radford et al., 2021),它们利用对比学习等方法将图像和文本映射到同一语义空间。通过这些模型,用户可以基于图像或音频进行检索,系统可以检索到相关的多模态信息,并用于增强文本生成的效果,例如在图像问答或音视频内容理解任务中。Google Research 开发的 AudioCLIP 则展示了将 CLIP 的思想扩展到音频领域的潜力。
9.3 Agentic RAG:Agent 主动决策何时以及如何进行 RAG
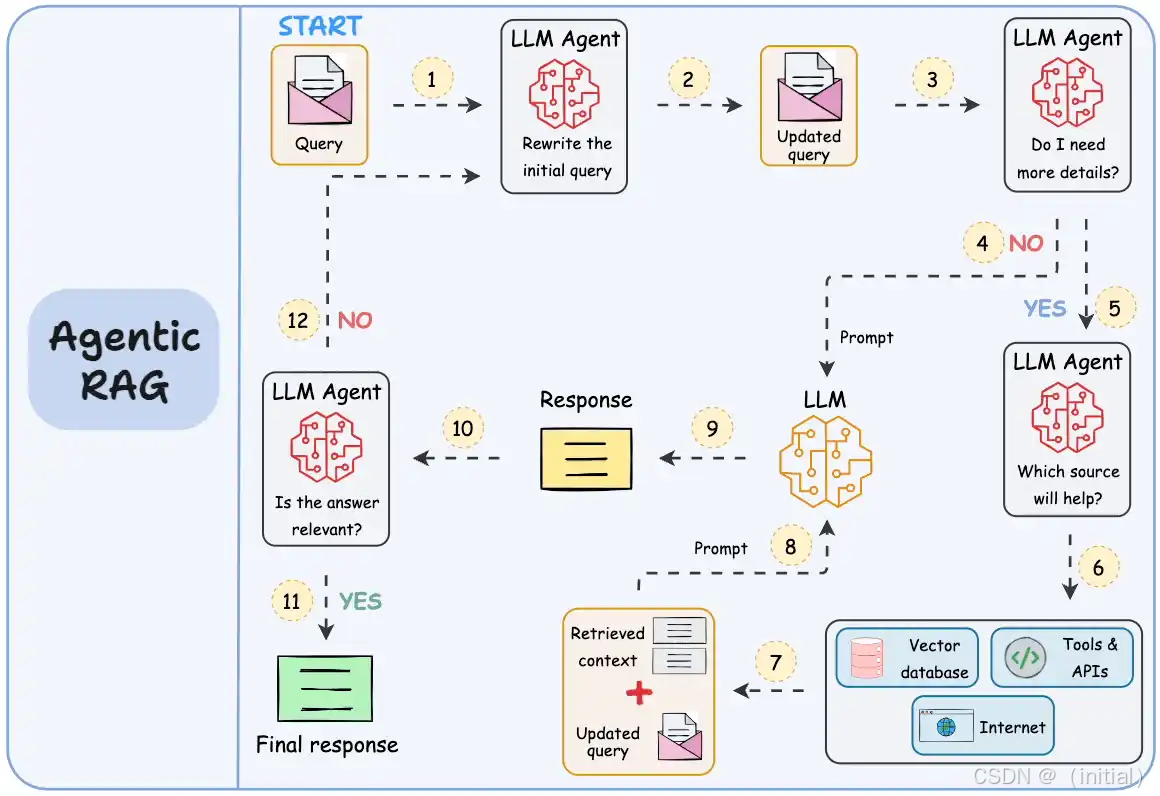
Agentic RAG 将 RAG 与自主 Agent 的概念相结合,赋予模型更强的行动能力和决策智能。在这种框架下,LLM 扮演着 Agent 的角色,能够根据任务需求自主决定何时需要检索外部信息,并选择合适的检索工具和策略。例如,Toolformer (Schick et al., 2023) 展示了语言模型如何学习使用各种外部工具,包括信息检索工具。ReAct (Zhou et al., 2023) 则强调了推理和行动的协同作用,Agent 可以通过交替进行推理和检索来完成复杂任务。例如,在回答一个复杂问题时,Agent 可以先进行初步推理,然后判断需要检索哪些信息来支持推理过程,最终生成答案。ChatGPT 也被探索作为信息检索的强大工具 (Schick et al., 2023)。
9.4 更复杂的图谱应用:多跳推理增强、子图推理 RAG
传统的检索增强生成 (RAG) 方法在处理需要简单的事实查询时表现良好,但在面对需要复杂推理或利用结构化知识(如图谱)的场景时往往力不从心。为了克服这些局限性,研究人员提出了多种增强 RAG 能力的方法,其中多跳推理增强和子图推理 RAG 是两个重要的方向。
9.4.1 多跳推理增强 RAG
许多现实世界的问题需要连接多个不同的知识点才能找到答案,这类问题被称为多跳问题。传统 RAG 通常只能检索到与问题直接相关的文档,而无法进行跨多个文档或知识单元的推理。多跳推理增强 RAG 的目标就是让模型具备这种能力。
-
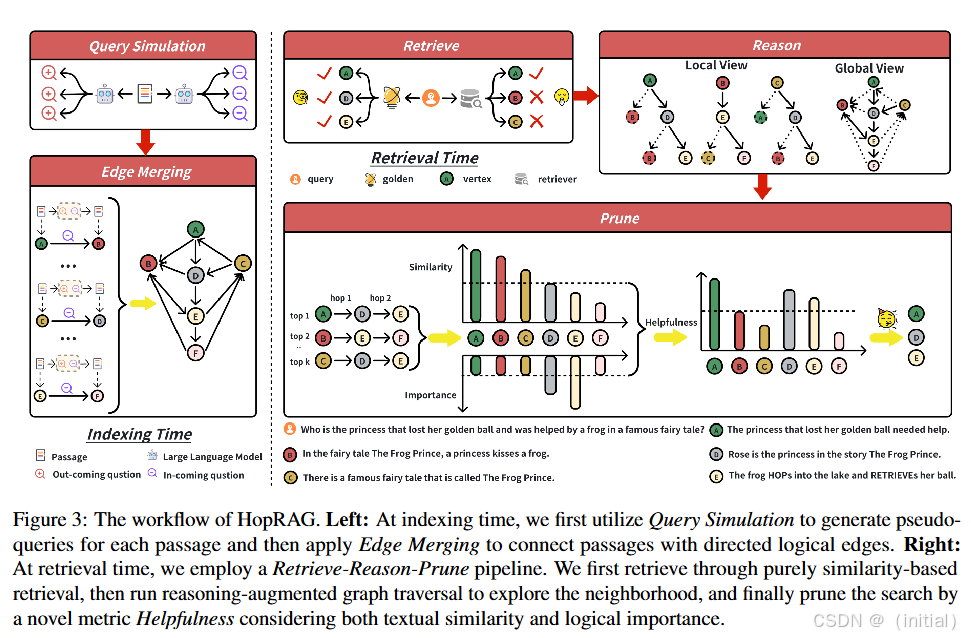
HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation 提出了一种新颖的框架,通过构建一个图结构的段落索引,并利用大型语言模型 (LLM) 生成伪查询来发现段落之间的逻辑连接。在检索时,HopRAG 使用广度优先搜索算法在图上进行多跳探索,并结合 LLM 的推理能力选择最相关的段落。实验证明,HopRAG 在多跳问答任务中显著提升了答案的准确性和检索的 F1 值。这表明通过显式地建模段落之间的逻辑关系,可以有效地增强 RAG 的多跳推理能力。
-
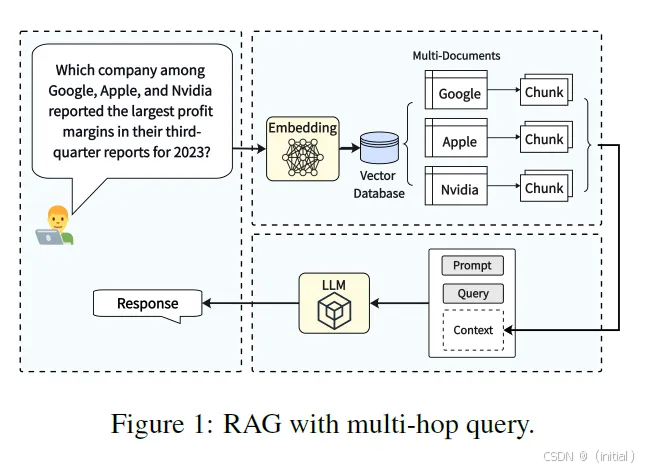
MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries 这项工作着重于评估现有 RAG 系统在处理多跳查询时的性能瓶颈。研究人员构建了一个专门针对多跳查询的数据集,并通过实验发现,即使是最先进的 RAG 方法在处理这类复杂问题时仍然表现不佳。这突显了开发更强大的多跳推理增强 RAG 系统的必要性,并为未来的研究提供了重要的基准。
-
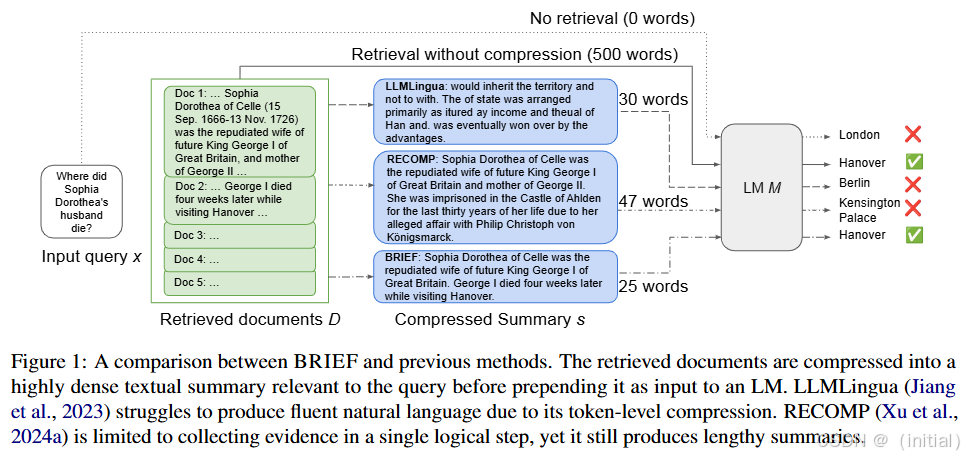
BRIEF: Bridging Retrieval and Inference for Multi-hop Reasoning via Compression 提出了通过压缩检索到的文档来增强多跳推理的方法。针对多跳问题通常需要检索多个文档,导致输入 LLM 的文本长度过长的问题,BRIEF 通过将检索到的证据压缩成高密度的摘要,从而在不损失关键信息的情况下,提高了推理效率和性能。
9.4.2 子图推理 RAG
对于那些以知识图谱作为外部知识源的应用场景,如何有效地利用图谱的结构信息进行推理至关重要。子图推理 RAG 旨在通过检索知识图谱中与查询相关的子图,并利用图的结构进行更深入的推理。
-
Simple Is Effective: The Roles of Graphs and Large Language Models in Knowledge-Graph-Based Retrieval-Augmented Generation (SubgraphRAG) 这篇论文提出了 SubgraphRAG 框架,它通过检索知识图谱中的相关子图,并结合 LLM 的推理能力来生成答案。该方法强调了简单而有效的设计,可以灵活地调整检索到的子图大小,并在多个知识图谱问答基准测试中取得了优异的性能,证明了基于子图检索的 RAG 在处理结构化知识方面的有效性。
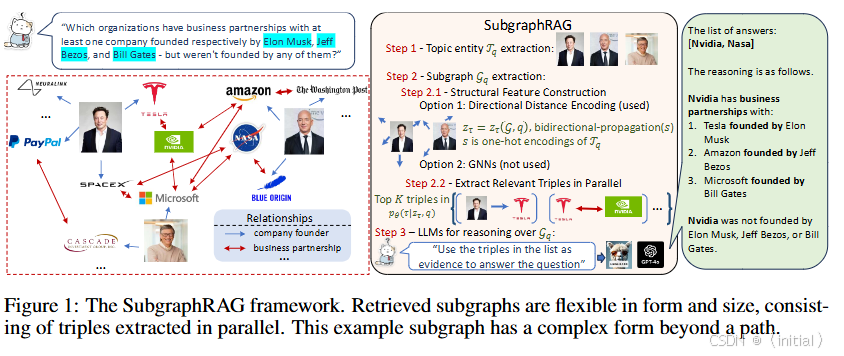
-
CRP-RAG: A Retrieval-Augmented Generation Framework for Supporting Complex Logical Reasoning and Knowledge Planning 提出了一个基于推理图的 RAG 框架。该框架构建推理图来表示复杂的查询推理路径,并指导知识的检索、利用和答案生成。CRP-RAG 能够根据评估结果动态调整推理路径,选择最合适的知识来支持推理过程,从而在多跳推理等复杂任务中表现出色。
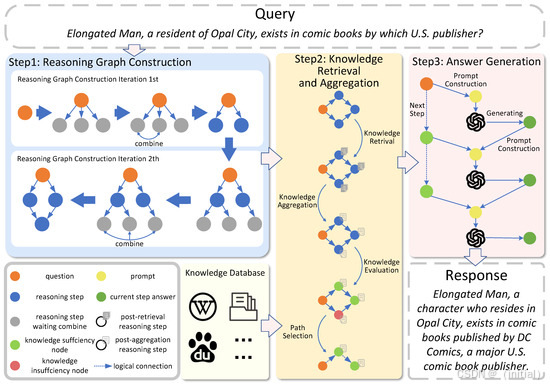
-
Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering (G-Retriever) 专注于处理带有文本属性的图谱。该论文提出了 G-Retriever 方法,它是一种用于通用文本图的 RAG 方法,能够检索与用户查询相关的子图,并生成相应的文本回复,同时高亮显示图谱中的相关部分。这为用户提供了一种更直观的方式来理解和查询图谱数据。
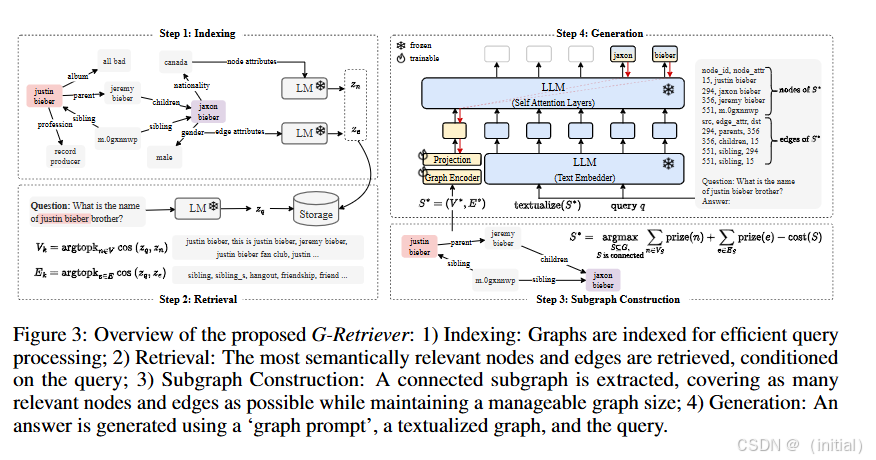
9.5 RAG 与 Fine-tuning 的协同:各自优势与结合方法
RAG 和 Fine-tuning 是提升 LLM 性能的互补方法。RAG 能够动态地引入外部知识,而 Fine-tuning 则可以使模型更好地适应特定任务或领域的数据分布。研究表明,将两者结合可以取得更好的效果。例如,可以使用 LoRA (Hu et al., 2022) 等高效 Fine-tuning 方法微调 LLM,使其更擅长利用检索到的上下文信息。同时,也可以 Fine-tuning Embedding 模型,使其生成的向量更能捕捉特定领域知识的语义关系。此外,利用 RAG 生成的高质量数据来进一步 Fine-tuning LLM 也是一种有效的策略。例如,先使用 RAG 系统针对某个领域的问题生成大量高质量的问答对,然后利用这些数据对 LLM 进行 Fine-tuning,可以使其在该领域表现更佳。综述性工作如 “Pre-train, Prompt, and Predict” (Zhang et al., 2023) 也讨论了 Prompting、RAG 和 Fine-tuning 之间的关系和协同作用。
9.6 Long-Context RAG:有效处理长文档与多文档检索
LLM 的上下文窗口限制了其处理长文档和多文档的能力。Long-Context RAG 旨在解决这个问题。一些方法包括使用更长的上下文窗口模型(如 Longformer (Beltagy et al., 2020) 和 Big Bird (Zaheer et al., 2020)),以及采用文档分割、摘要和信息压缩等技术来将长文档或多文档的信息浓缩到有限的上下文窗口内。此外,一些研究也探索了稀疏注意力机制,以更高效地处理长序列。REALM (Guu et al., 2020) 等早期工作也探索了如何从大量文档中检索相关片段用于生成。
9.7 RAG 在特定领域的应用进展与挑战
RAG 技术在各个领域都展现出巨大的潜力,例如:
- 代码 RAG: 用于代码检索、生成和解释,通常需要考虑代码的语法结构和语义含义。例如,可以检索相似的代码片段来辅助代码生成,但挑战在于如何理解代码的逻辑和上下文。
- 医疗 RAG: 在医疗领域,RAG 可以用于检索医学知识、辅助诊断和提供治疗建议,但对准确性和可靠性要求极高。例如,检索到的医疗信息必须来自权威可靠的来源,并且需要仔细验证。
- 金融 RAG: 金融领域需要处理大量的报告、新闻和市场数据,RAG 可以帮助分析师快速获取和整合信息。挑战在于如何处理金融数据的时效性和复杂性。
- 教育 RAG: 可以为学生提供个性化的学习资源和答案,提高学习效率。例如,可以根据学生的学习进度和知识掌握情况检索相关的学习材料。
每个领域都有其特定的知识特点和应用挑战,需要针对性地优化 RAG 系统。
9.8 RAG 的可解释性与可追溯性
为了提高用户对 RAG 系统的信任,可解释性和可追溯性至关重要。这涉及到让用户了解系统检索了哪些信息以及如何利用这些信息生成答案。研究方向包括可视化检索结果、展示推理路径以及提供指向原始知识来源的链接。例如,系统可以高亮显示生成答案所依赖的检索到的文档片段。Li 等人 (2017) 在推荐系统领域的研究以及 Baumgartner 等人 (2016) 在问答系统中的工作都探讨了如何提供忠实的解释。
9.9 RAG 评估与基准的最新进展
随着 RAG 技术的进步,对其进行有效评估至关重要。Ragas 是一个专门用于评估 RAG 管道的框架。除了传统的检索指标(如 Hit Rate、NDCG),还需要评估生成答案的忠实度(Faithfulness)、相关性(Answer Relevancy)和上下文相关性(Context Recall)等。研究社区正在不断开发新的评估指标和基准数据集,以更全面地衡量 RAG 系统的性能。
9.10 更前沿的 RAG 技术展望
- 生成式检索 (Generative Retrieval): 模型直接生成相关文档的标识符或内容片段,而不是依赖于传统的索引检索。
- 超越文本的知识增强生成: 更深入地融合表格、代码、科学数据等多种非文本知识形式。
- 记忆增强的 RAG: 为 RAG 系统引入记忆模块,以提升对话连贯性和个性化能力。
- 个性化 RAG: 根据用户画像、历史交互等信息定制检索和生成过程。
- RAG 的持续学习与知识更新: 使 RAG 系统能够动态地更新知识,适应信息变化。
- 可解释且值得信赖的 RAG: 提供更清晰的答案来源和推理过程解释,增强用户信任。
- 面向复杂推理任务的 RAG: 将 RAG 应用于需要多步推理、规划和工具调用的复杂场景。
- 联邦学习与去中心化 RAG: 在保护数据隐私的前提下,利用分布式数据构建 RAG 系统。
9.11 结论与未来展望:RAG 技术的发展方向
本章深入探讨了 RAG 技术领域的前沿进展,涵盖了自适应优化、多模态融合、Agent 协同、复杂的图谱应用、与 Fine-tuning 的结合、长上下文处理、领域特定应用、可解释性以及最新的评估方法。此外,我们还展望了生成式检索、记忆增强、个性化等更具潜力的未来方向。值得注意的是,RAG 技术正处于一个快速发展和不断演进的阶段,新的研究成果和技术突破不断涌现,未来的研究将继续探索如何构建更智能、更可靠、更通用的知识增强型语言模型。
参考文献
- Corrective Retrieval Augmented Generation
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation
- MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for
Multi-Hop Queries - BRIEF: Bridging Retrieval and Inference for Multi-hop Reasoning via
Compression - Simple Is Effective: The Roles of Graphs and Large Language Models in Knowledge-Graph-Based Retrieval-Augmented Generation
- CRP-RAG: A Retrieval-Augmented Generation Framework for Supporting Complex Logical Reasoning and Knowledge Planning
- Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering