EdgeInfinite: 用3B模型处理无限长的上下文
论文标题
EdgeInfinite: A Memory-Efficient Infinite-Context Transformer for Edge Devices
论文地址
https://arxiv.org/pdf/2503.22196
作者背景
vivo,浙江大学
代码
The code will be released after the official audit.
动机
self-attention的二次时间复杂度带来了老生常谈的效率问题,这在资源受限的边缘设备(例如手机、小型机器人)上的情况尤为严峻,许多主流提效方案都无法满足端侧场景的严苛需求

对此,作者希望在保持现有Transformer架构优势的同时,实现对长序列的高效支持。
本文方法
作者提出EdgeInfinite,面向边缘计算这样资源极度受限的场景,并且能够处理“无限长”的上下文(这样说是因为本方法处理长文本时并没有主动舍弃任何信息,但在迭代的过程中肯定还是会有信息精度的损失),具体结构如下:
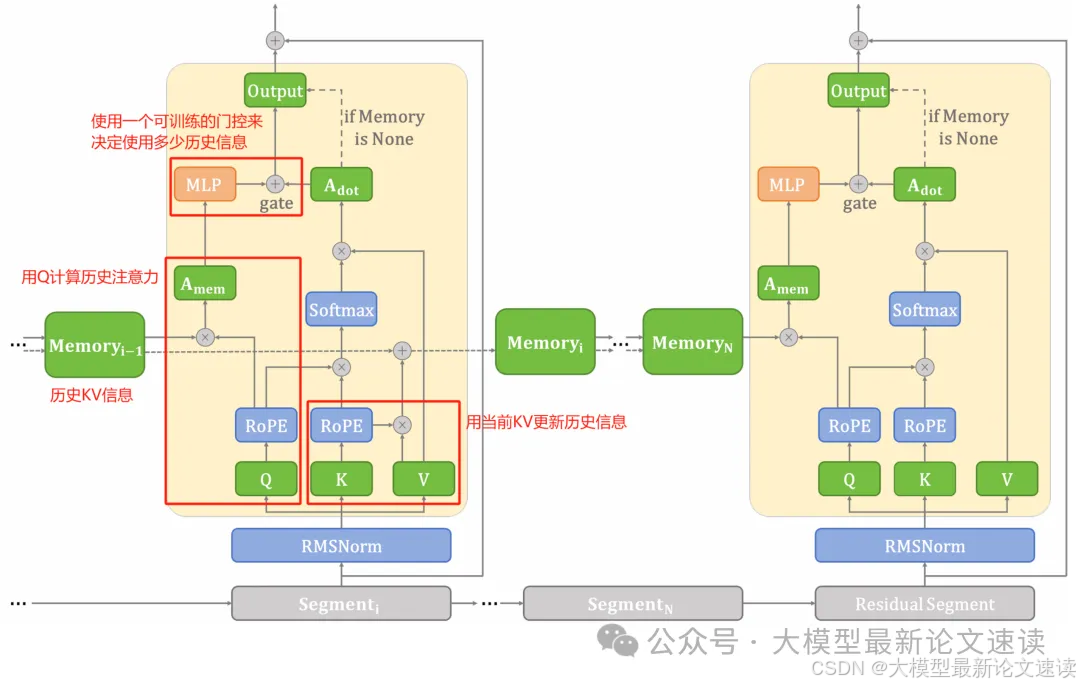
一、分段注意力
EdgeInfinite把输入上下文分割成长度为L的段,每个段中的token只在内部执行注意力分数计算,从而把复杂度控制在段长范围内,极大地降低了单次计算长上下文注意力的成本;同时也加入全局的位置编码信息(ROPE),避免切分后丢失跨段位置信息;
二、记忆压缩-解压模块
新增一个历史信息记忆模块,每段长度为L的文本处理完毕后都会被压缩存储到这个模块中(不包括划分后剩下的残段),以供下一段文本的注意力计算。存储的对象是K和V,记忆更新方式为:
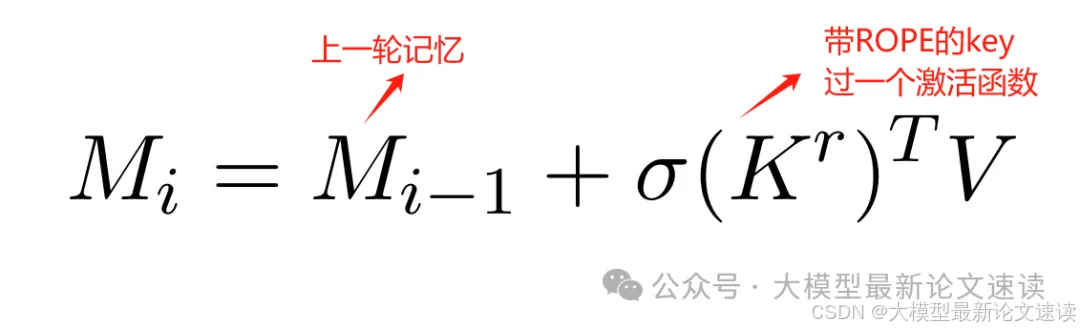
读取记忆时,拿当前段的每个query与记忆模块相乘,得到类似于自注意力的计算结果:

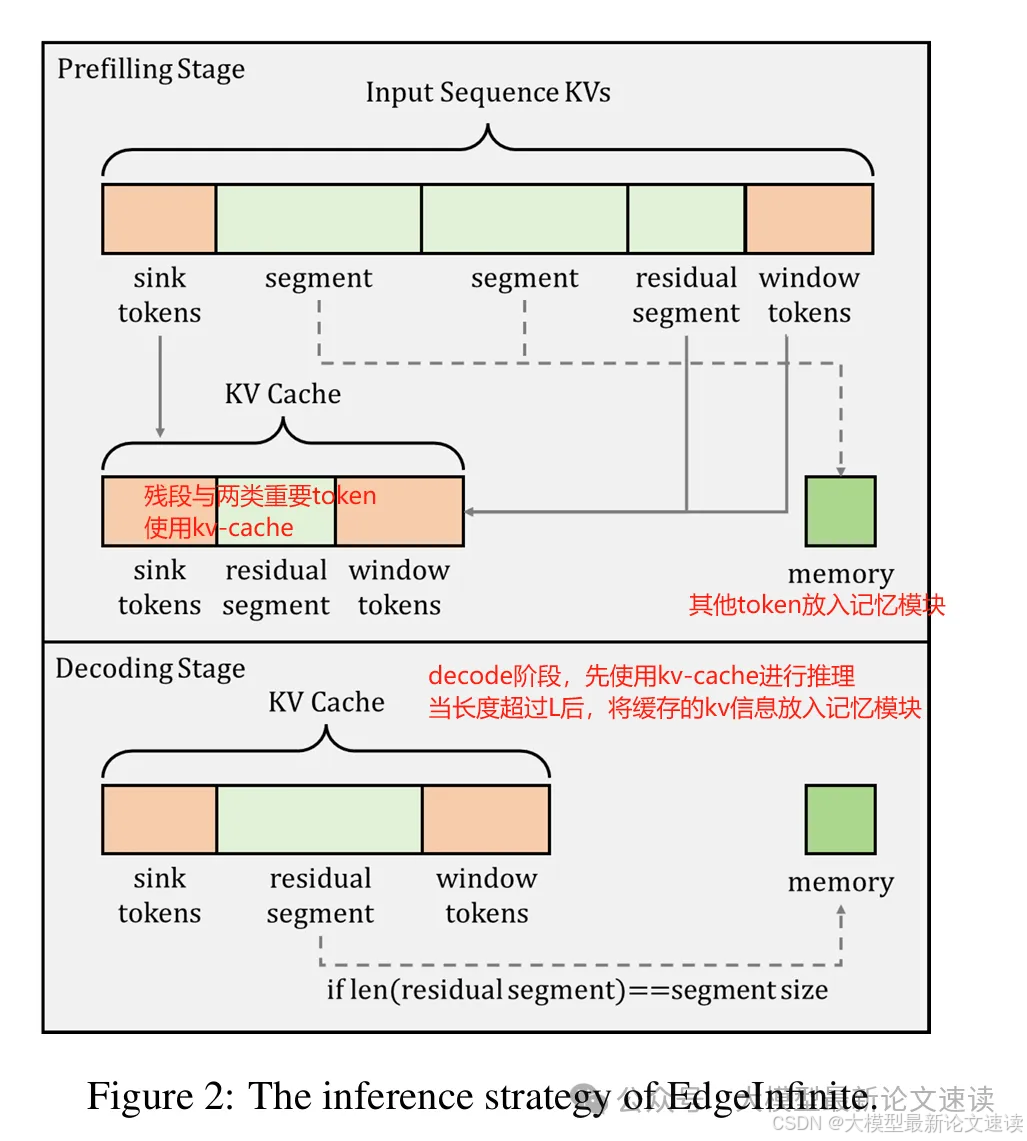
上述M可看作是所有历史信息的压缩(全都塞到一组参数里面)。此外还可以让一些重要的token不进行这样的压缩,对此本文做了一些简单的探索:对于上下文的开头部分(sink token)和最邻近的上文(window token),像kv-cache一样保留它们的原始信息
三、自适应记忆门控
与Infini-Transformer需要训练整个模型不同,EdgeInfinite仅需微调记忆门控模块。该模块通过一个多层感知机(MLP)和一个门控向量,将基于记忆的注意力与基于局部段的注意力结合起来,动态平衡当前上下文和历史上下文的重要性,甚至支持在在短文本任务上退化回原始模型进行推理。
实验结果
一、性能测试
作者在LongBench上进行了全面的评估,测试对象是一个适用于边缘设备的3B模型(BlueLM-3B),EdgeInfinite的段长L设为2048,实验结果如下表所示:
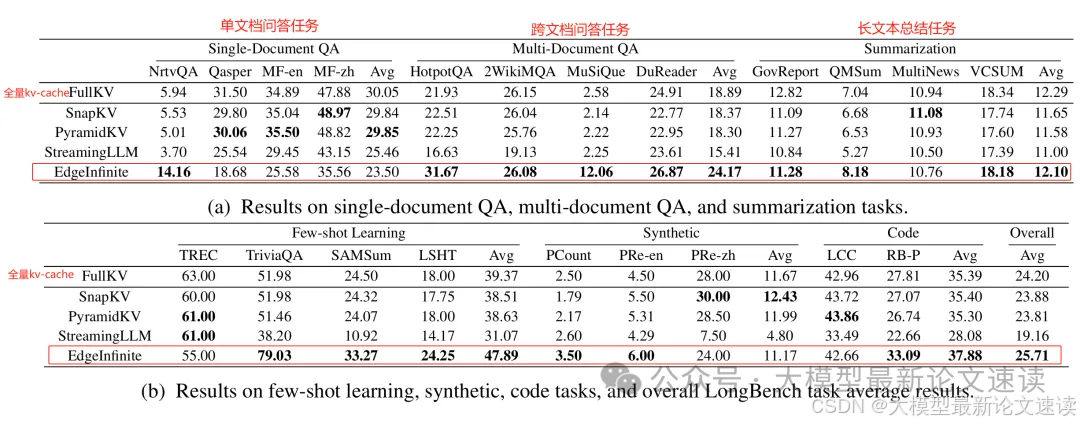
可见除了单文档问答任务,EdgeInfinite具有良好的性能优势,在许多任务上好于全量的KV-Cache(全量缓存超长上下文时信息过载造成能力下降,而EdgeInfinite能够通过压缩只保留重点)
单文档问答任务的效果略差,是因为此类任务大多需要对上下文细节进行分析,而EdgeInfinite压缩了上下文导致其更擅于长篇总结,细节问答是弱点
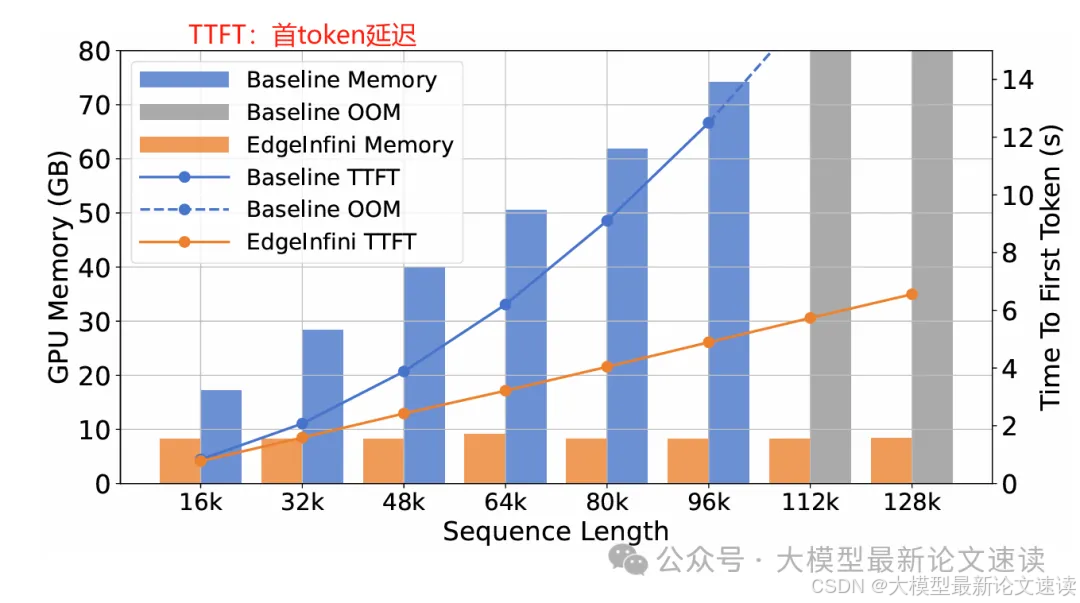
二、效率测试
EdgeInfinite非常高效,只使用了常数级别的存储开销,这也是作者称其为“Infinite”的原因
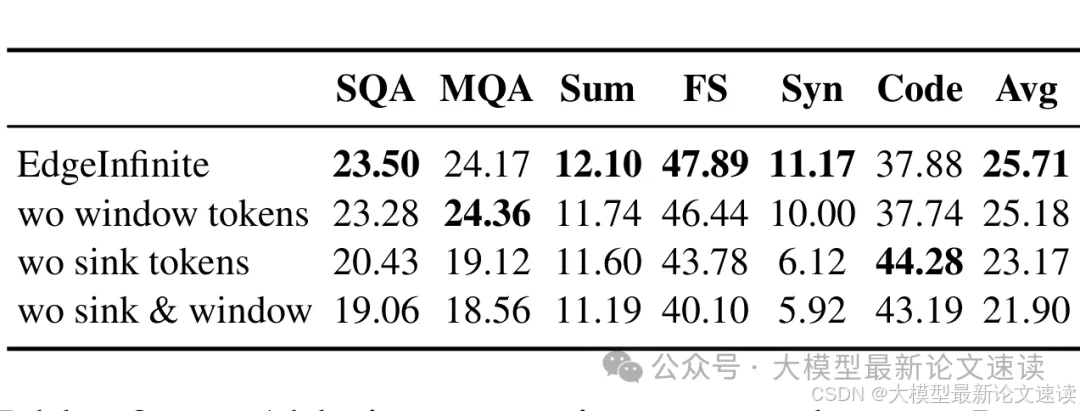
三、消融实验
对于保留两种特殊token的原始kv这一行为,消融结果表明其正向作用
总结
本文提出了一种常数级存储开销的长上下文处理方法,对于像边缘计算这种资源限制严苛的场景很有帮助,并且只在模型层面上增加了少量模块,改动很小,兼容性强;此外自适应门控的存在也极为重要:确保在兼顾长上下文的同时不损害短文本效果;
但EdgeInfinite更擅长总结,而不擅长细节处理的特点是当前的硬伤,原因可能在于重要token的挑选逻辑过于简单