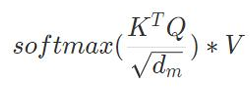LLM面试题七
NLP算法工程师面试题8道|含解析
- 分类场景下bert和gpt+prompt的方式哪种会有更好效果,为什么?
在分类场景下,BERT比GPT更适合用于建模,因为BERT的结构中包含了双向的Transformer编码器,而GPT的结构中只包含单向的Transformer解码器。这使得BERT能够更好地捕捉文本中的双向上下文信息,从而在文本分类任务中表现更好。而GPT+prompt的方式则可以通过在输入文本前加入一些提示语来指导模型学习特定任务的表示,从而提高模型的泛化性能。
- 如何解决prompt泛化性使用多个不同的prompt,从而增加模型学习的样本多样性。
通过在prompt中添加随机噪声或变换,来增加数据集的丰富性,从而提高模型的泛化性能。采用迁移学习或元学习等方法,从先前学习的任务中提取知识,并将其应用于新的任务中。
- 对COT(Chain-of-Thought Prompt)和Instruction Tuning的理解
- COT Prompt是一种用于自然语言生成的提示机制,它可以通过将一个文本片段(例如一段文章或一个问题)分解为一系列相关的语义单元,从而帮助自然语言生成模型更准确地理解文本的意义。这些语义单元可以按照它们的层次结构(例如句子、段落或章节)进行组织,并且可以用于为模型提供关于生成文本的结构和内容的提示。
- Instruction Tuning是一种用于调整自然语言生成模型的参数的技术,它可以通过向模型提供来自人类编辑或专家的指令来指导模型的生成过程。这些指令可以涵盖各种不同的方面,例如语法、风格,结构和内容等。通过使用Instruction Tuning,可以在不改变模型架构的情况下对其进行微调,从而使其更好地满足特定的生成需求。
- 关于bet的后续改进工作,分别改进了哪些地方?
BERT的后续改进工作主要包括以下方面:基于BERT的预训练模型的改进,例如RoBERTa、ALBERT等。通过调整BERT的架构和超参数来进一步优化模型性能,例如Electra、DeBERTa等。改进BERT在特定任务上的应用方法,例如ERNIE、MT-DNN等。
- 对知识蒸馏知道多少,有哪些改进用到了?
知识蒸馏是一种通过将一个复杂模型的知识转移到一个简单模型来提高简单模型性能的方法。这种方法已经被广泛应用于各种深度学习任务中。其中一些改进包括:使用不同类型的损失函数和温度参数来获得更好的知识蒸馏效果。引入额外的信息来提高蒸馏的效果,例如将相似性约束添加到模型训练中。将蒸馏方法与其他技术结合使用,例如使用多任务学习和迁移学习来进一步改进知识蒸馏的效果。
- attention计算复杂度以及如何改进。
在标准的Transformer中,attention计算的时间复杂度为O(N^2),其中N是输入序列的长度。为了降低计算复杂度,可以采用以下几种方法:使用自注意力机制,减少计算复杂度。自注意力机制不需要计算输入序列之间的交叉关系,而是计算每个输入向量与自身之间的关系,从而减少计算量。使用局部注意力机制,只计算输入序列中与当前位置相关的子序列的交互,从而降低计算复杂度。采用基于近似的方法,例如使用随机化和采样等方法来近似计算,从而降低计算复杂度。使用压缩注意力机制,通过将输入向量映射到低维空间来减少计算量,例如使用哈希注意力机制和低秩注意力机制等。
- 谈一下对模型量化的了解。
模型量化是一种将浮点型参数转换为定点型参数的技术,以减少模型的存储和计算复杂度。常见的模型量化方法包括:量化权重和激活值,将它们转换为整数或小数。使用更小的数据类型,例如8位整数、16位浮点数等。使用压缩算法,例如Huffman编码、可逆压缩算法等。模型量化可以减少模型的存储空间和内存占用,同时也可以加速模型的推理速度。但是,模型量化可能会对模型的精度造成一定的影响,因此需要仔细权衡精度和计算效率之间的平衡。
- topk数组取值,尽可能多的方法。
对于一个长度为N的数组,获取其中前K个最大或最小值的方法有很多种,其中些常见的方法包括:
- 直接排序,将整个数组排序,然后取前K个或后K个元素。使用堆,维护一个大小为K的最大或最小堆,然后遍历数组并将元素插入到堆中,最后取出堆中的元素。
- 分治算法,将数组分成多个小的部分,然后对每个部分分别计算前K个或后K个元素,最后将结果合并。
- 快速选择算法,类似于快速排序,通过每次选择一个基准值来将数组分成两部分,然后根据基准值所在的位置递归地对其中一部分进行处理。使用快排变种算法,例如三向切分快排,通过将数组分成小于、等于和大于基准值的三部分来减少递归次数。
- 桶排序,对于已知取值范围的数组,可以使用桶排序来计算前K个或后K个元素。
- 部分排序算法,例如选择排序和插入排序,可以只对数组的一部分进行排序,从而减少计算量。
- 分层采样算法,将数组分成多个层次,每个层次采样一定比例的元素,然后通过分层采样的结果来估计整个数组的前K个或后K个元素。
对于长度较大的数组,使用基于排序的方法可能会非常慢,而使用堆和快速选择算法则可以在较短的时间内获得结果。
NLP算法工程师面试题
- 可以解释一下熵吗,它的公式怎么算的?
熵可以用来描述信息的不确定性或信息的随机程度。嫡的公式为:H=-Σ(p*log§其中,H表示熵,P表示每种可能事件发生的概率,IOg表示以2为底的对数。
- BERT的base版本的原始模型,训练的时候,第一个epoch模型的判定结果很可能是错的,这个时候熵还可信吗?
在训练BERT模型时,通常需要多个epoch来达到最佳性能。在初始训练过程中,模型的判定结果可能不是非常准确,因此第一个epoch的结果可能会存在误差。但即使在初始阶段,BERT模型的熵仍然是可信的。熵是衡量信息的不确定性的量,可以用来衡量模型的预测结果的置信度。在第一个epoch,BERT模型的熵也可以帮助我们评估模型的性能和预测结果的置信度。当熵较低时,表示模型对于给定的输入文本的预测结果比较确定:当熵较高时,则表示模型对于该输入文本的预测结果不确定。因此,即使在第一个epoch,熵仍然是一种可信的评估模型性能的指标。
- 交叉熵和KL散度有什么关系?
交叉熵和KL(Kullback-Leibler)散度都是用于度量两个概率分布之间的差异性的指标,它们有一些相似之处,但也有不同之处。
- 相同处:都不具备对称性;都是非负的
- 区别:KL散度是交叉熵与熵的差。
- BERT的缺点?可以从预训练方法角度解答。
- 训练时间长:BERT模型需要巨大的计算资源和时间来进行预训练,尤其是在较大的语料库上进行训练时。这使得BET对于小规模数据集的任务可能不是很适合。
- 处理长文本困难:BERT对于长文本的处理存在困难,因为输入文本长度有限制,而且BERT的self-attention机制需要计算所有输入词的相互交互,这样的计算开销也很大。
- RoBERTa相比BERT有哪些改进?
- 预训练数据更多:RoBERTa使用了更多的训练数据,并且在预训练中采用了更多的数据增强技术,这使得RoBERTa在多个自然语言处理任务上的表现优于BERT。
- 去掉了NSP任务:RoBERTa将原本下一句预测任务去掉了,只保留遮蔽语言模型任务,这使得RoBERTa能够更好地处理单个句子的表示。
- 动态掩码:RoBERTa使用了一种动态遮蔽策略,通过在每次训练迭代中随机选择遮蔽哪些词语来增加模型的鲁棒性。
- BERT的输入有哪几种Embedding?
- Token Embedding:将每个输入词转化为其对应的NordPiece嵌入向量。
- Segment Embedding:对于一组输入文本,将其分为两个部分,并为每个部分分别分配一个segment ID,以区分不同的输入文本。
- Position Embedding:为了捕捉输入词的相对位置,BERT使用了位置嵌入向量,对于不同的位置位置,使用不同的嵌入向量表示。
- 你有了解其他模型去尝试解决长度限制的方案吗?
Bert模型的长度限制问题主要是由于Transformer结构中的自注意力机制(self.attention mechanism)和位置嵌入(position embeddings)所导致的。这些机制使得Bert对于较长的序列处理非常耗时,并且占用大量的内存,从而限制了Bt在处理长序列任务上的性能。为了解决这个问题,一些研究人员提出了一些改进型的模型,包括:
- Longformer:Longformer是一个基于Transformer结构的模型,它使用了一种新的自注意力机制,称为"Sliding Window Attention’",该机制可以在处理长序列时缓解Bert模型的计算和存储成本。
- Reformer:Reformer是一个基于哈希注意力(Hashing Attention)的Transformer模型,该模型可以有效地处理长序列,并且在一些NLP任务上表现良好。
- Performer:Performer是一种基于FFT(Fast Fourier Transform)Transformer模型,该模型可以处理长序列,并且在一些NLP任务表现良好。
- Sparse Transformer:Sparse Transformer是一种使用稀疏注意力机制的Transformer模型,它可以减少Bert模型在处理长序列时的计算和存储成本。
- BERT是怎么缓解梯度消失的?
- Layer Normalization(LN):在每个Transformer模块中,BERT使用LN来规范化每个词嵌入的向量值,使其具有相同的均值和方差。这有助于提高梯度的流动性,减少梯度消失的可能性。
- Residual Connections:BERT使用残差连接将每个Transformer模块的输入和输出相加,以便梯度能够更容易地传播到较早的层。这也有助于缓解梯度消失问题。
- LN和BN的区别?
Layer Normalization(LN):在神经网络中,LN是一种用于规范化输入向量的技术。LN基于每个输入的样本进行标准化,而不是使用整个批次的统计信息,这使得LN对于小批量输入数据也能提供相对稳定的标准化。另外,LN通常应用在RNN或Transformer等网络结构中的每个层上,而不是在整个网络中的一Batch Normalization(BN):BN是一种在神经网络中用于标准化输入向量的技术。与LN不同,BN使用整个批次的统计信息来标准化输入向量。BN通常应用在卷积层或全连接层上,以减少梯度消失问题并提高模型的鲁棒性。在训练过程中,BN会维护每个批次的均值和方差,用于标准化输入数据。在推理时,BN使用训练期间学习的统计信息进行标准化。
NLP算法工程师面试题
- 生成式模型与判别式模型的区别?
- 生成式模型先对数据的联合分布进行建模,然后再通过贝叶斯公式计算样本属于各类别的后验概率。
- 判别式模型直接进行条件概率建模,由数据直接学习决策函数或条件概率分布作为预测的模型。判别方法不关心背后的数据分布,关心的是对于给定的输入,应该预测什么样的输出。、
- 用一句话总结就是生成模型估计的是联合概率分布,判别式模型估计的是条件概率分布。
- 模型的方差和偏差是指什么?
- 偏差(Bias):表示模型的预测值和真实值之间的差异程度。用所有可能的训练数据集训练出的所有模型的输出的平均值与真实模型的输出值之间的差异。如果模型的偏差很高,说明模型无法捕捉到数据中的所有信息,因此模型的预测值和真实值之间的差异会很大。例如,在房屋预测的例子中,如果模型只考虑了房屋的面积这一个特征,那么模型的偏差就会很高,因为模型无法考虑到其他特征(比如卧室数量、浴室数量等)对房价的影响。
- 方差(Variance):表示模型对于不同的训练集的预测结果分散程度。如果模型的方差很高,说明模型对于不同的训练集的预测结果差异很大,也就是说,模型无法捕捉到数据中的一般规律,而过度拟合了训练数据。例如,在房屋预测的例子中,如果我们使用非常复杂的模型(比如高阶多项式回归),那么模型的方差就会很高,因为模型过度拟合了训练数据,而无法捕捉到一般规律。
- 二分类模型的评估指标有哪些?
在二分类模型中,我们通常将样本分为两类:正例和反例。在评估模型性能时,我们需要考虑以下四个指标:
- 准确率(Accuracy):预测正确的样本占总样本数的比例。
- 精确率(Precision):预测为正例的样本中,真正为正例的比例。
- 召回率(Reca):真正为正例的样本中,被预测为正例的比例。
- F1值:精确率和召回率的调和平均数,常用于综合评估模型性能。
此外,我们还可以使用ROC曲线和AUC来评估模型的性能。ROC曲线是以假正率(False Positive Rate,FPR)为横坐标,真正率(True Positive Rate,TPR)为纵坐标绘制的曲线,用于衡量模型在不同阈值下的性能。AUC则是ROC曲线下的面积,用于综合评估模型的性能。AUC的取值范围为0.5到1,值越大,模型性能越好。
- AUC刻画的什么?说明了什么意思?
AUC(Area Under the ROC Curve)是机器学习领域中常用的一个性能度量指标,用于衡量分类器对样本的分类能力。ROC(Receiver Operating Characteristic)曲线是以假正率(False Positive Rate,FPR)为横坐标,真正率(True Positive Rate,TPR)为纵坐标绘制的曲线,用于衡量模型在不同阈值下的性能。AUC则是ROC曲线下的面积,用于综合评估模型的性能。AUC的取值范围在0.5到1之间,值越大,分类器性能越好。具体来讲,AUC刻画了分类器对正负样本的分类能力,即对于一个随机的正负样本对,分类器给出正样本的预测值高于负样本的概率。AUC越高,说明分类器在区分正负样本时具有更好的能力。在实际场景中,例如医学诊断、金融风控等领域,AUC是评估分类器性能的重要指标之一。需要注意的是,AUC并不是一个完美的指标,因为它并不能告诉我们分类器在不同的阈值下的表现,而且对于类别不平衡的数据集,AUC可能会给出误导性的结果。因此,在实际应用中,我们需要综合考虑多个性能度量指标来评估分类器的性能。
- 交叉熵函数刻画的什么?
交叉熵函数是机器学习中常用的一种损失函数。它常用于评估两个概率分布之间的差异,尤其是在神经网络中用于度量模型输出与真实标签之间的差距。交叉熵函数的基本思想是将模型的输出概率与真实标签的概率进行比较,通过计算两个概率分布之间的交叉熵(cross–entropy)来衡量它们的相似程度。在分类任务中,我们通常将标签表示为一个one-hot向量,即只有一个元素为1,其余元素都为0.
- 对于非常大的分类类别,对于softmax有哪些优化方法?
当分类类别非常大时,计算softmax的复杂度会变得非常高,因为softmax的计算复杂度是与类别数成正比的。因此,需要采用一些优化方法来加速softmax的计算。
一种常见的优化方法是基于交叉熵的方法,这包括hierarchical softmax和noise-contrastive estimation(NCE)。hierarchical softmax通过将所有的类别组织成一棵二叉树,并对每个节点定义一个概率值,从而将原问题转化为对一系列二分类问题的求解。这样就可以减少softmax计算的次数,从而提高运行速度。NCE是一种用于训练softmax模型的替代方法,它通过最大化正确标签和噪声标签之间的差异来训练模型。与传统的softmax方法不同,NCE不需要计算所有类别的概率,因此在类别数非常大时可以大大提高运行速度。
另一种优化softmax的方法是采用近似softmax方法,例如采用采样的方法进行训练。这包括采样自适应重要性抽样(sampled softmax)、target sampling和sparsemax等。sampled softmax通过随机采样一小部分类别来近似计算softmax概率,从而减少计算量。target sampling是一种基于重要性采样的方法,它根据类别的频率对类别进行采样,从而减少少数类别的影响。sparsemax是一种类似于softmax的激活函数,但是它产生的分布更加稀疏,因此可以减少计算量。
总之,当我们需要处理非常大的分类问题时,需要采用一些优化方法来加速softmax的计算,从而提高运行速度和效率。不同的优化方法有不同的适用场景,需要根据具体情况进行选择。
- softmax除了作为激活函数,在深度学习中还有哪些用途?
除了作为激活函数,还可以使用softmax进行软归一化,而且在transformer中,softmax在注意力机制中计算注意力,主要是软最大化。