ASRank: Zero-Shot Re-Ranking with Answer Scent for DocumentRetrieval
一、动机
传统的检索方法不能将最相关的文档放在前面
二、解决方法
参考信息线索:一条相关信息的轨迹,引导用户找到正确的答案。
第一步:利用LLM生成答案线索,在整个过程中只执行一次。
第二步:使用较小的模型根据生成的答案线索对文档进行重新排序
三、方法详细
首先使用已有的检索方法检索到一些相关的文档,检索到了K个文档,记为下面:
![]()
第一步:利用LLM进行答案的线索生成
LLM是基于自回归模型来生成,序列中的每个单词的概率,即条件概率,通常使用Transformer模型实现,所以,我们还要使用一个掩码来遮盖未来的单词序列。表达式如下:
![]()
通过零样本的方法,让LLM生成 一个答案线索,来引导LLM生成与查询语境相符的答案
第二步:重排序
贝叶斯定理:获得新的信息后,如何更新我们对事件发生的概率
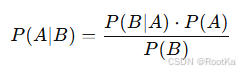

概率的知识:
相乘(联合概率):当你需要计算 两个事件同时发生的概率 时,使用相乘。这是 条件概率 或 联合概率 的基本概念。它可以表示为 P(A∩B)=P(A∣B)⋅P(B),即两个事件 依赖 或 独立 发生的概率。
相加(加法规则):当你需要计算 至少一个事件发生的概率 时,使用相加。如果事件是 互斥 的,可以直接相加;如果事件是 非互斥 的,需要减去它们同时发生的部分,以避免重复计算。
ASRANK是一个无监督的重排序方法,它的核心就是,通过LLM来评估文档的相关性,利用低一步产生的答案线索,作为上下文来判断相关性。
文档的相关性的得分计算如下:
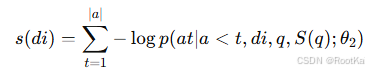
 文档的评估得分就是在给定的文档、查询、和答案线索的条件下,计算答案的每个token的logit然后对所有的logit求和就是这个文档整体的相关性
文档的评估得分就是在给定的文档、查询、和答案线索的条件下,计算答案的每个token的logit然后对所有的logit求和就是这个文档整体的相关性
根据贝叶斯定理,来重构这个相关性分数:
用下面的这个公式计算查询和文档和答案线索条件下生成的答案概率:
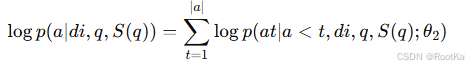
最后使用下面的公式来计算文档的相关性分数:
![]()
注:注解,在基础相关的情况下,前面相关的概率
最后,我们选择分数最高的为最相关的文档:
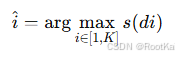
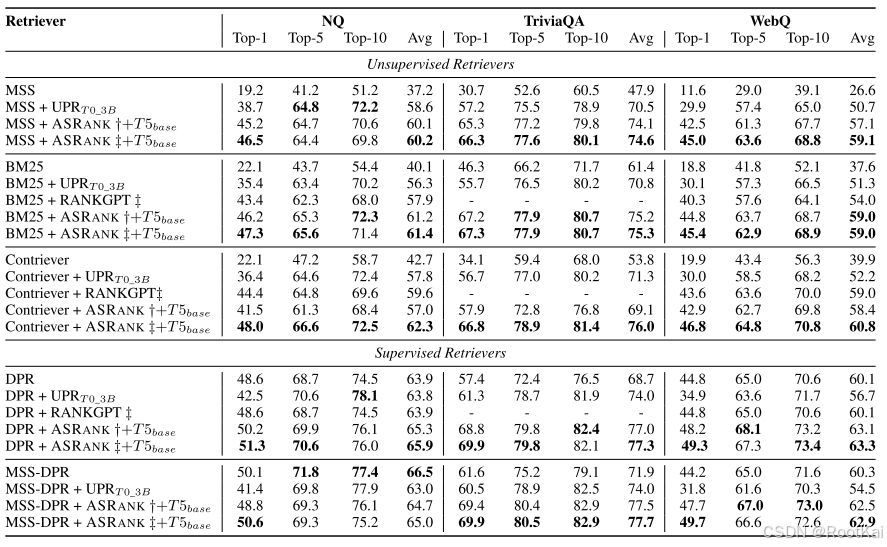
四、结果
1.数据集:
TriviaQA、Natural Questions (NQ)、WebQuestions、EntityQuestions、ArchivalQA、HotpotQA、NFCorpus、DBPedia、Touche 和 News、TREC-DL19
2.评估指标
exact match, recall, F1 scores
3.实验结果