【NLP 55、投机采样加速推理】
目录
一、投机采样
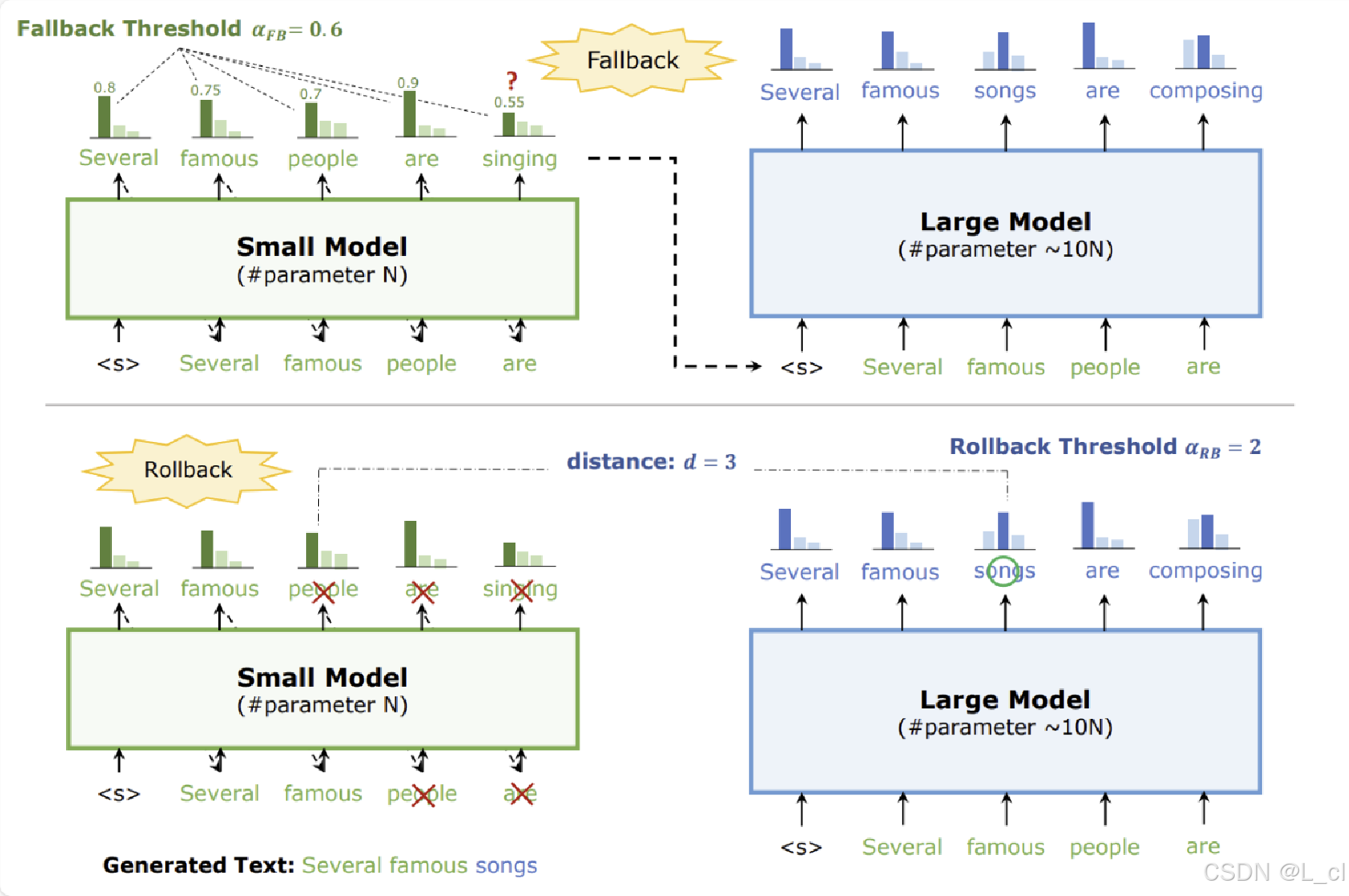
二、投机采样改进:美杜莎模型
流程
改进
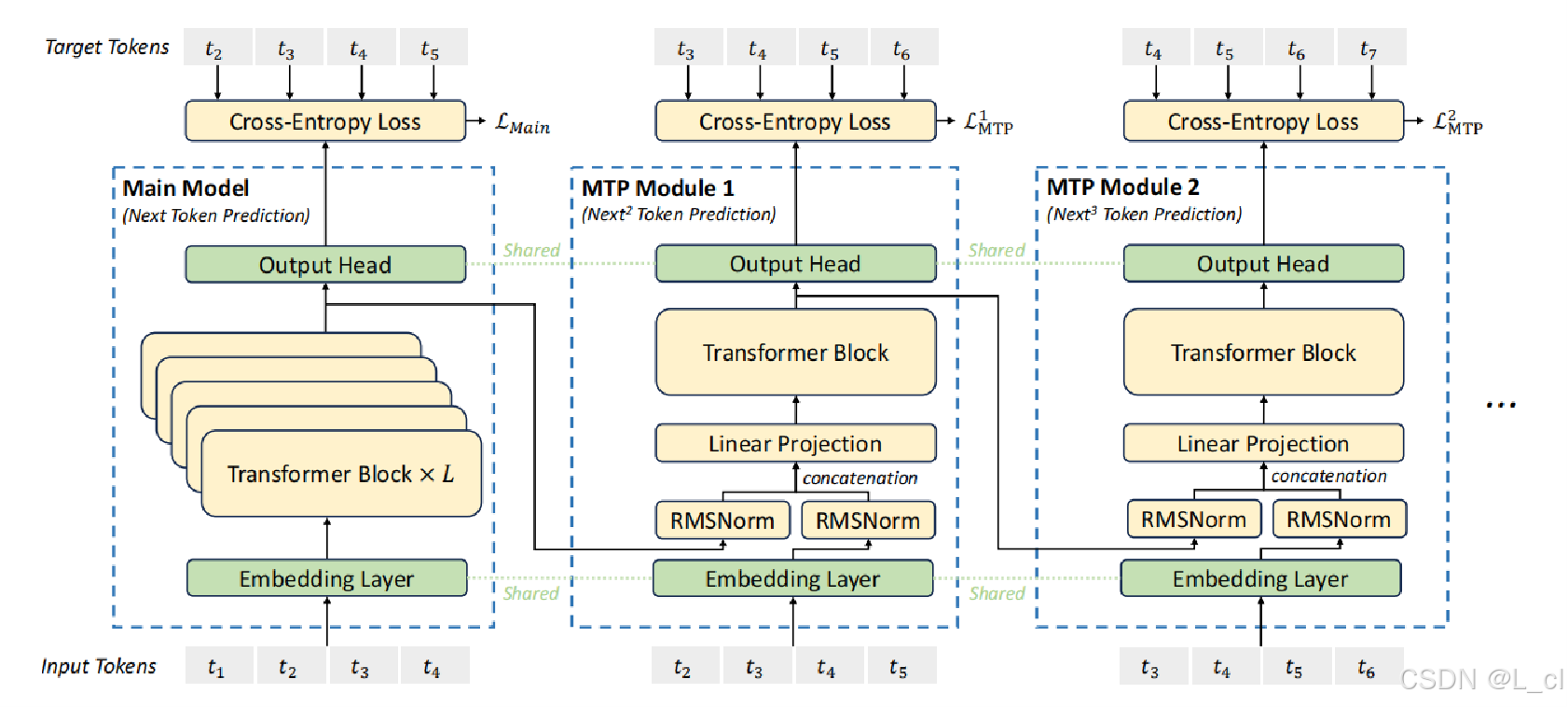
三、Deepseek的投机采样
流程
Ⅰ、输入文本预处理
Ⅱ、引导模型预测
Ⅲ、候选集筛选(可选)
Ⅳ、主模型验证
Ⅴ、生成输出与循环
骗你的,其实我在意透了
—— 25.4.4
一、投机采样
找到一种方式加速我们的推理过程 —— 投机采样
投机采样(Speculative Sampling)是一种用于加速大语言模型推理的技术,它通过预测模型可能生成的下一个 token 来减少计算量,同时尽量保持生成文本的质量 。
分层预测:投机采样基于这样一个假设,即可以使用一个较小、更快的 “引导模型”(也称为 “投机模型”)来对大语言模型(“主模型”)的生成进行预测。引导模型结构简单、计算成本低,能快速生成可能的下一个 token 及其概率分布。
验证与修正:引导模型提出若干可能的下一个 token 及其概率。这些预测结果被视为 “投机”。主模型随后仅对这些投机结果中的部分或全部进行验证,而不是对所有可能的 token 进行完整计算。如果引导模型的预测与主模型的验证结果相符,那么就采用引导模型的预测作为生成的下一个 token ,从而跳过主模型对其他大量 token 的计算。如果预测不符,主模型则会按照常规方式计算出正确的下一个 token ,同时这一信息也可用于微调引导模型,使其后续预测更准确。
二、投机采样改进:美杜莎模型
模型自带多个头,代替draft model (投机小模型) 起到打草稿的目的
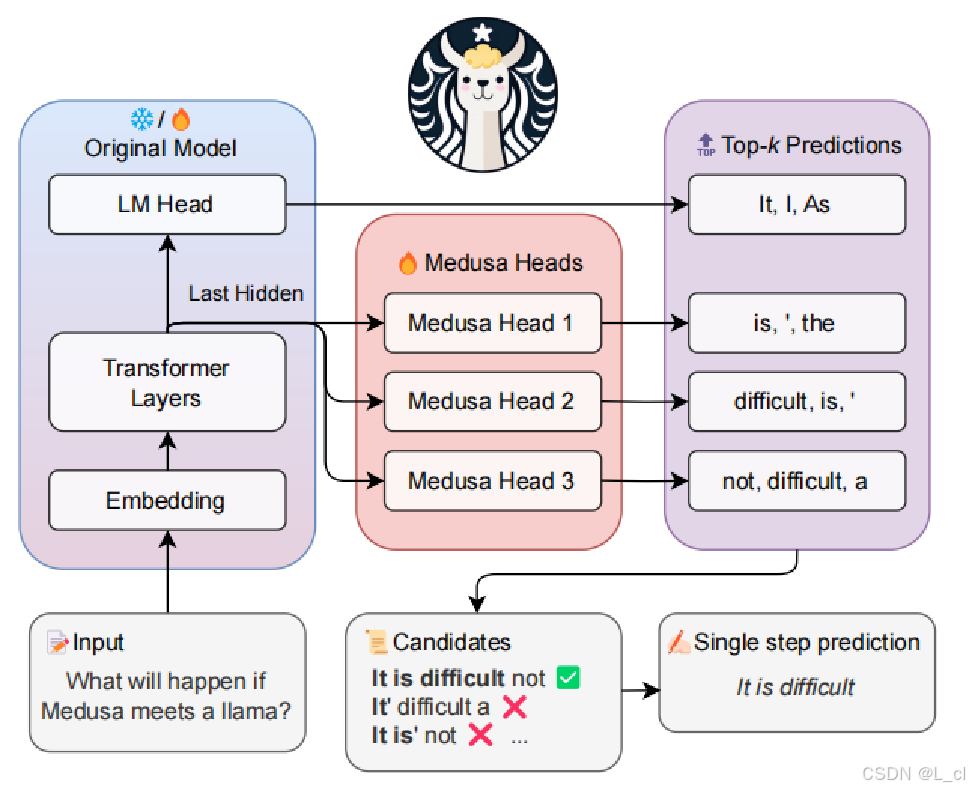
流程
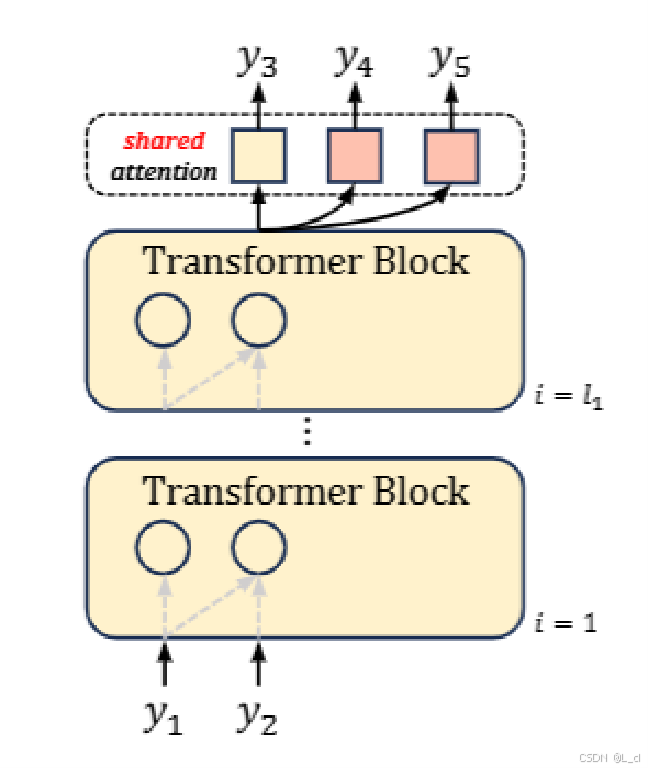
改进
把前一个头的输出,作为后一个头的输入的一部分;
把前一个头的输出当作下一个头的输入进行传递

三、Deepseek的投机采样
双模型架构:与常见的投机采样方法类似,Deepseek 采用主模型和引导模型的架构。主模型是具有强大语言处理能力的大型预训练模型,负责生成高质量的文本。引导模型则相对轻量级,设计目的是快速预测主模型可能生成的下一个词元(token)。引导模型经过优化,能够以较低的计算成本对主模型的输出进行近似预测。
分层预测与验证:在推理过程中,引导模型首先基于输入文本生成一系列可能的下一个 token 及其概率分布。这些预测并非随意生成,而是通过引导模型对语言模式的学习以及对主模型行为的近似模拟得出。然后,主模型对引导模型提供的预测 token 进行验证。主模型并非对词汇表中的所有 token 进行全面计算,而是集中精力评估引导模型给出的候选集。若引导模型的预测与主模型的验证结果匹配,就直接采用引导模型的预测作为生成结果,从而跳过主模型对其他大量 token 的计算,实现加速推理。若预测不匹配,主模型则以常规方式计算正确的下一个 token 。
流程
Ⅰ、输入文本预处理
文本分词:将输入文本送入分词器,把文本分割成一个个词元(token)。这是语言模型处理文本的基础步骤,不同的语言模型可能使用不同的分词方法,如字节对编码(Byte - Pair Encoding,BPE)等。通过分词,将连续的文本转化为模型能够理解和处理的离散单元序列。
构建输入表示:对分词后的结果进行处理,添加必要的位置编码、段编码等信息(如果模型需要),将其转换为适合模型输入的张量形式。这个张量包含了文本的词元信息以及位置等上下文信息,为模型后续的处理提供基础。
Ⅱ、引导模型预测
快速前向传播:轻量级的引导模型接收预处理后的输入张量,通过其神经网络结构进行快速的前向传播计算。引导模型经过专门设计和训练,旨在以较低的计算成本快速生成预测结果。
生成候选 token 及概率:引导模型输出一组可能的下一个 token 及其对应的概率分布。这些候选 token 是引导模型基于对输入文本的理解和对主模型生成模式的学习而预测出来的。引导模型通过其内部的参数和训练学到的语言知识,评估每个可能 token 成为下一个生成词元的可能性,并输出概率值。例如,引导模型可能预测下一个 token 有 80% 的概率是 “苹果”,10% 的概率是 “香蕉” 等。
Ⅲ、候选集筛选(可选)
根据概率排序与筛选:如果引导模型生成的候选 token 数量较多,可能会根据预测概率对候选集进行排序,然后筛选出概率较高的一部分 token 作为最终的候选集。例如,只选择概率最高的前 5 个 token,这样可以进一步减少主模型需要验证的 token 数量,提高整体效率。这一步骤并非绝对必要,具体是否执行以及筛选的标准可能根据模型的设计和应用场景而定。
Ⅳ、主模型验证
针对候选集计算:主模型接收输入文本以及引导模型生成的候选 token 集,对这些候选 token 进行验证。主模型会根据自身强大的语言理解和生成能力,对每个候选 token 在当前上下文下的合理性进行评估。与传统生成方式不同,此时主模型无需对整个词汇表中的所有 token 进行计算,大大减少了计算量。
确定最终 token:主模型通过计算,确定在候选集中哪个 token 是最符合当前文本上下文的下一个生成词元。如果引导模型的预测准确,主模型验证后选择的 token 与引导模型预测概率最高的 token 一致,就直接采用该 token 作为生成结果;若主模型验证后认为引导模型的预测均不准确,则按照常规方式,对整个词汇表进行计算,确定正确的下一个 token。
Ⅴ、生成输出与循环
输出当前 token:将确定的下一个 token 输出,作为文本生成的一部分。这个 token 可能会被添加到已生成的文本序列中,形成新的上下文。
循环进行下一轮预测:以新的文本序列作为输入,重复上述步骤,继续生成下一个 token,直到满足预设的生成结束条件,如达到指定的文本长度、生成特定的结束标志 token 等。通过这样的循环过程,逐步生成完整的文本。