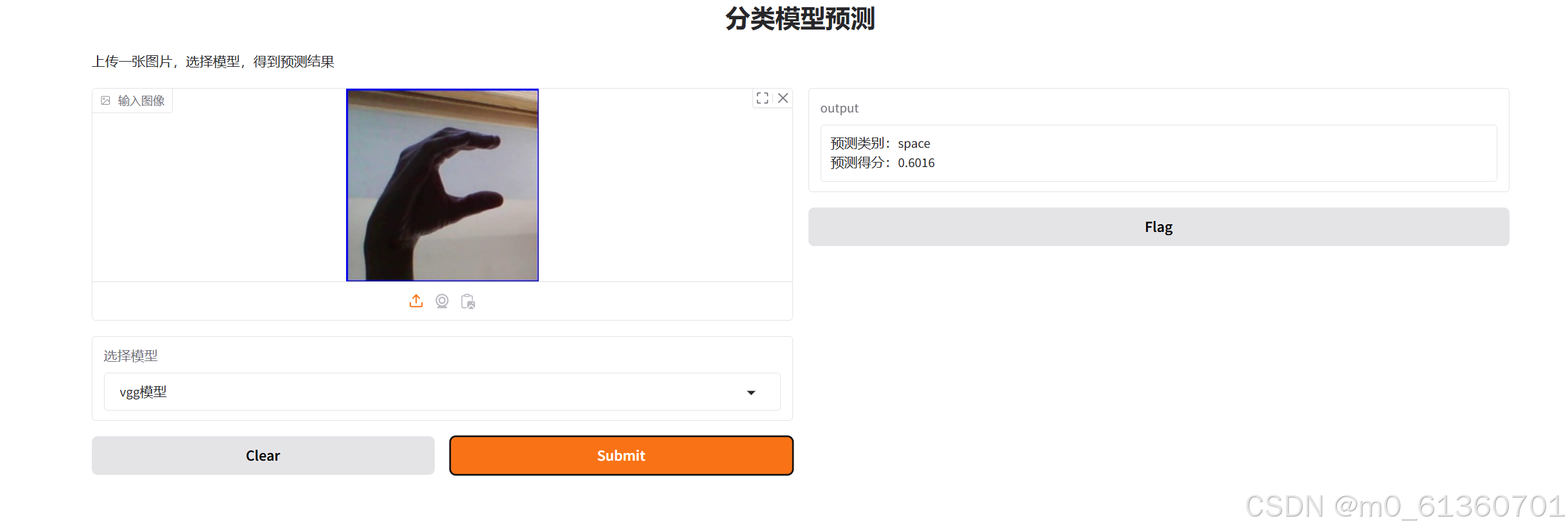
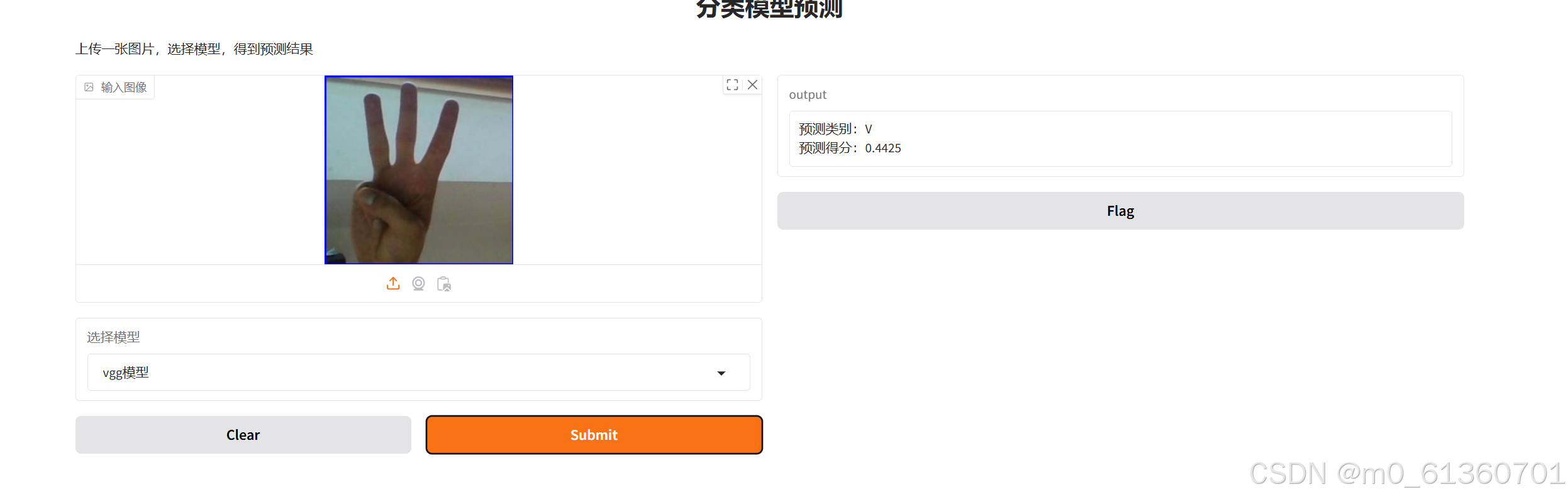
5.模型训练-毕设篇3
vgg:
base_model_vgg13 = models.vgg13(pretrained=True)
base_model_vgg13.classifier[-1] = nn.Linear(4096, num_classes)
base_model_vgg13.to(device)(b_img_rgb.to(device)).shape

base_model_vgg13 = models.vgg13(pretrained=True)
作用:加载预训练的 VGG13 模型
-
models.vgg13:PyTorch 提供的经典卷积神经网络模型 VGG13。 -
pretrained=True:表示加载别人已经在 ImageNet 上训练好的参数,这样可以让模型学习得更快。 -
把它保存到变量
base_model_vgg13中,后面就可以对它修改、训练、使用。
base_model_vgg13.classifier[-1] = nn.Linear(4096, num_classes)
作用:修改最后一层为适合你自己任务的输出层。
VGG 的最后一部分是一个 classifier(全连接层序列),修改了其中最后一层([-1] 表示最后一层):
nn.Linear(4096, num_classes)
这表示:
-
输入是
4096个神经元的特征; -
输出是你任务中的类别数(比如 ASL 就是 29 类)
关于4096是怎么来的
这是 VGG13 的模型结构中固定的输出维度。
vgg:
classifier = nn.Sequential(
nn.Linear(25088, 4096), # 第一层全连接
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096), # 第二层全连接
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 1000), # 第三层(原始输出层)——这里要把它改成 num_classes
)
nn.Linear(4096, 1000) # 输出 ImageNet 的 1000 类 这是原来的最后一行
修改为:
nn.Linear(4096, num_classes) # 输出你自己的类别,比如 29 类
4096 是上一个全连接层输出的神经元个数,它已经被前面两层全连接层固定了,不需要你管。
base_model_vgg13.to(device)(b_img_rgb.to(device)).shape
这是你执行了 模型的前向传播(推理):
-
b_img_rgb.to(device):把一批图像数据放到 GPU 或 CPU 上。 -
base_model_vgg13.to(device):把模型放到 GPU 或 CPU 上。 -
然后你直接在模型后加
(b_img_rgb.to(device)):就是在跑 forward(前向预测)。
vgg13的网络结构

表示卷积核大小是 3×3(也可能写作 3x3 Conv) |
64 | 表示该层输出了 64 个“通道(feature maps)”,即这层的输出深度是 64 |
VGG13 的名字中 “13” 是什么意思?
表示它有 13 个“有学习参数的层”,即:
-
11 个卷积层(Conv)
-
2 个全连接层(FC)
Block 层级结构 输出通道数 输出尺寸(假设输入是 224×224) 输入 Input 3通道 (RGB) 224×224 Conv1 Conv(3→64), Conv(64→64), MaxPool 64通道 112×112 Conv2 Conv(64→128), Conv(128→128), MaxPool 128通道 56×56 Conv3 Conv(128→256), Conv(256→256), MaxPool 256通道 28×28 Conv4 Conv(256→512), Conv(512→512), MaxPool 512通道 14×14 Conv5 Conv(512→512), Conv(512→512), MaxPool 512通道 7×7 Flatten 展平为向量 - 25088 (即 512 × 7 × 7) FC1 Linear(25088 → 4096) - - FC2 Linear(4096 → 4096) - - FC3 Linear(4096 → 1000)(或自定义的 num_classes) - - Softmax(可选) 转成概率分布 - -
base_model_vgg13 是加载了预训练权重的 VGG13 卷积神经网络模型,就是训练、预测图像分类任务的“核心大脑”。
① 模型类型:VGG13 是一个中大型 CNN 网络
-
参数很多(大约 133M),比 ResNet18 大不少;
-
容易在小数据集上过拟合,所以不能设置太多 epoch;
-
需要一定轮数才能学好,但不能太多。
② 数据量:你训练的数据是 29,000 张图片
-
数据不算特别大;
-
如果没有做 数据增强(比如旋转、裁剪等),模型可能在 20 轮后就过拟合;
-
如果有增强,可以训练 30~50 轮,但要配合 EarlyStopping 提前停止。
③ 训练表现:是否收敛的关键指标是 验证集准确率和 loss 曲线
-
如果验证集准确率上升 → 可以继续训练;
-
如果验证准确率不升了、loss 不降了 → 提前停止;
-
用
early stopping自动帮你判断。
loss_fn = nn.CrossEntropyLoss()#创建一个交叉熵损失函数(CrossEntropyLoss)
# 专门用来处理“多分类问题”(比如要分 29 个手语类别)
optimizer = torch.optim.SGD(base_model_vgg13.parameters(), lr=1e-3)
# 创建一个优化器,用来更新模型参数,让 loss 更小
# 使用的是“随机梯度下降”(SGD)方法,适合基础训练
# 参数说明:
# base_model_vgg13.parameters():告诉优化器你要优化哪些参数(即整个模型的参数)
# lr=1e-3:学习率(learning rate),意思是每次学习走多大的一步,这里是 0.001# 自定义 EarlyStopping 类
class EarlyStopping:
def __init__(self, patience=5, delta=0):
"""
patience: 可以容忍多少个 epoch 验证集 loss 没有改善
delta: 认为“改善”的最小变化值(例如改善了0.0001也算)
"""
self.patience = patience
self.delta = delta
self.counter = 0
self.best_loss = None
self.early_stop = False
def __call__(self, val_loss):
if self.best_loss is None:
self.best_loss = val_loss
elif val_loss > self.best_loss - self.delta:
self.counter += 1
print(f"验证集 loss 没有改善 ({self.counter}/{self.patience})")
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_loss = val_loss
self.counter = 0
return self.early_stop
# 设置总共训练轮数为 25 轮(epoch)
epochs = 25
# 创建 EarlyStopping 实例:
# 如果验证集 loss 连续 5 轮(patience=5)没有改善超过 delta=0.001,就提前停止训练
early_stopping = EarlyStopping(patience=5, delta=0.001)
# 初始化列表,用来保存每一轮训练和测试的 loss 与 准确率,方便后续画图或分析
train_loss_list = [] # 存每一轮训练集的损失值
train_acc_list = [] # 存每一轮训练集的准确率
test_loss_list = [] # 存每一轮测试集(验证集)的损失值
test_acc_list = [] # 存每一轮测试集的准确率
# Step 2:开始训练循环,总共训练 epochs 轮
for t in range(epochs):
# 打印当前是第几轮(t 从 0 开始,所以要 +1)
print(f"Epoch {t+1}\n-------------------------------")
# 调用 train() 函数,在当前 epoch 对模型进行训练
train(train_dataloader, base_model_vgg13, loss_fn, optimizer)
# 用 test() 函数在训练集上评估效果(得到 loss 和 accuracy)
train_loss, train_correct = test(train_dataloader, base_model_vgg13, loss_fn)
# 用 test() 函数在测试集(验证集)上评估效果
test_loss, test_correct = test(test_dataloader, base_model_vgg13, loss_fn)
# 把每一轮的结果存进列表中,方便后续画图
train_loss_list.append(train_loss)
train_acc_list.append(train_correct)
test_loss_list.append(test_loss)
test_acc_list.append(test_correct)
# Step 3:判断是否触发 EarlyStopping(如果 test_loss 没有继续下降,就触发)
if early_stopping(test_loss):
print("早停触发,提前结束训练!")
break # 终止训练循环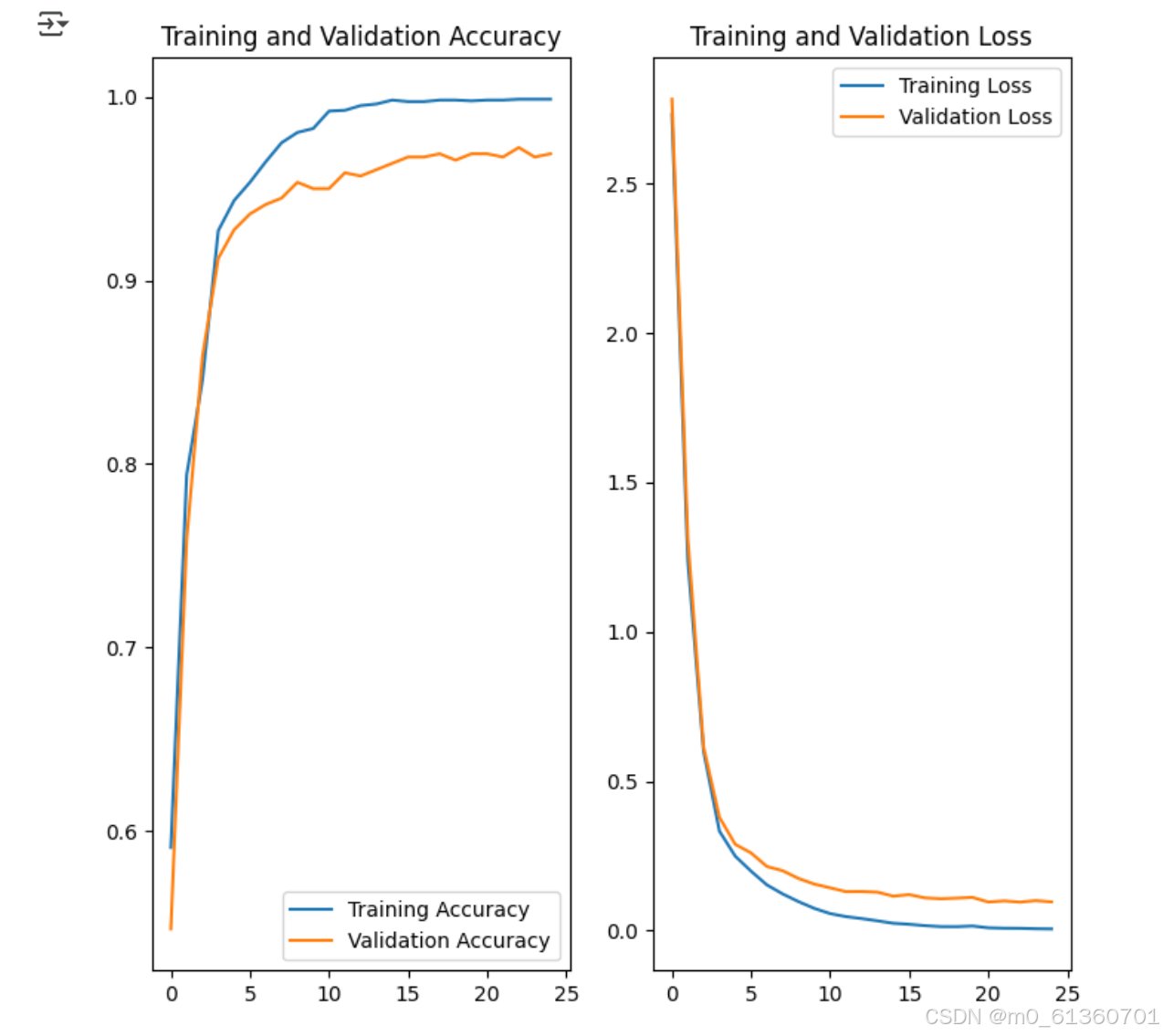

下次改为训练20轮,这个训练时间尤其得长
| 模块 | 解释 | 用处 |
|---|---|---|
| 可视化训练过程 | 用图表展示 loss / accuracy 的变化 | 看模型是否收敛、是否过拟合 |
| 模型验证集预测 | 用模型对测试集/验证集做预测 | 得到预测结果和概率 |
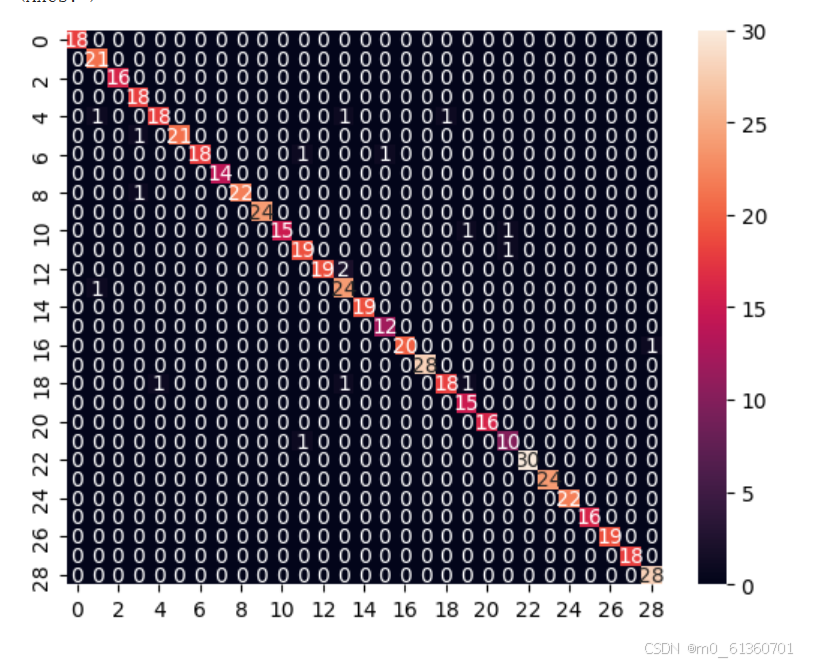
| 分类报告(classification report) | 输出每一类的 precision、recall、f1-score | 了解每类预测效果 |
| 混淆矩阵(confusion matrix) | 显示每类预测对/错的次数 | 可视化分类错误在哪些kesuu |
可视化
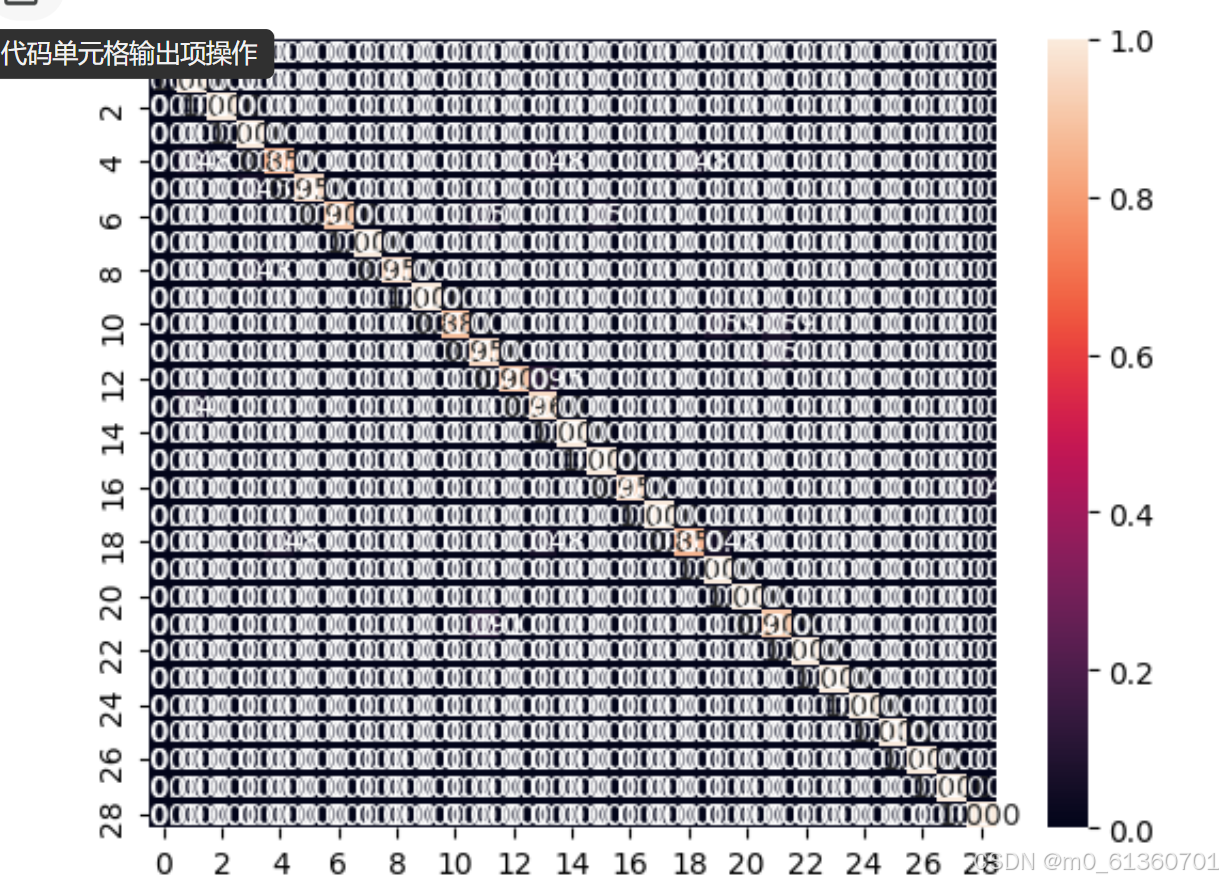
如果在训练中途突然换了 GPU(或 Colab 自动断线 / 切换 GPU):
-
训练是不会自动从中断的地方继续的。
-
所有内存内容(模型、optimizer、训练状态)会丢失。
-
即使保存了代码,也要从头开始,除非自己手动保存了模型状态。