ui-tars和omni-parser使用
ui-tars部署和训练
- 说明
- 快速开始
- 环境准备
- ui-tars web推理和训练
- ui-tars api部署
- omni-parser使用
说明
镜像中包含ui-tars、llama-factory和omni-parser。该镜像还在审批中,估计明天可以上线,到时候可以在auto-dl中的社区镜像搜索。
快速开始
使用auto-dl镜像:
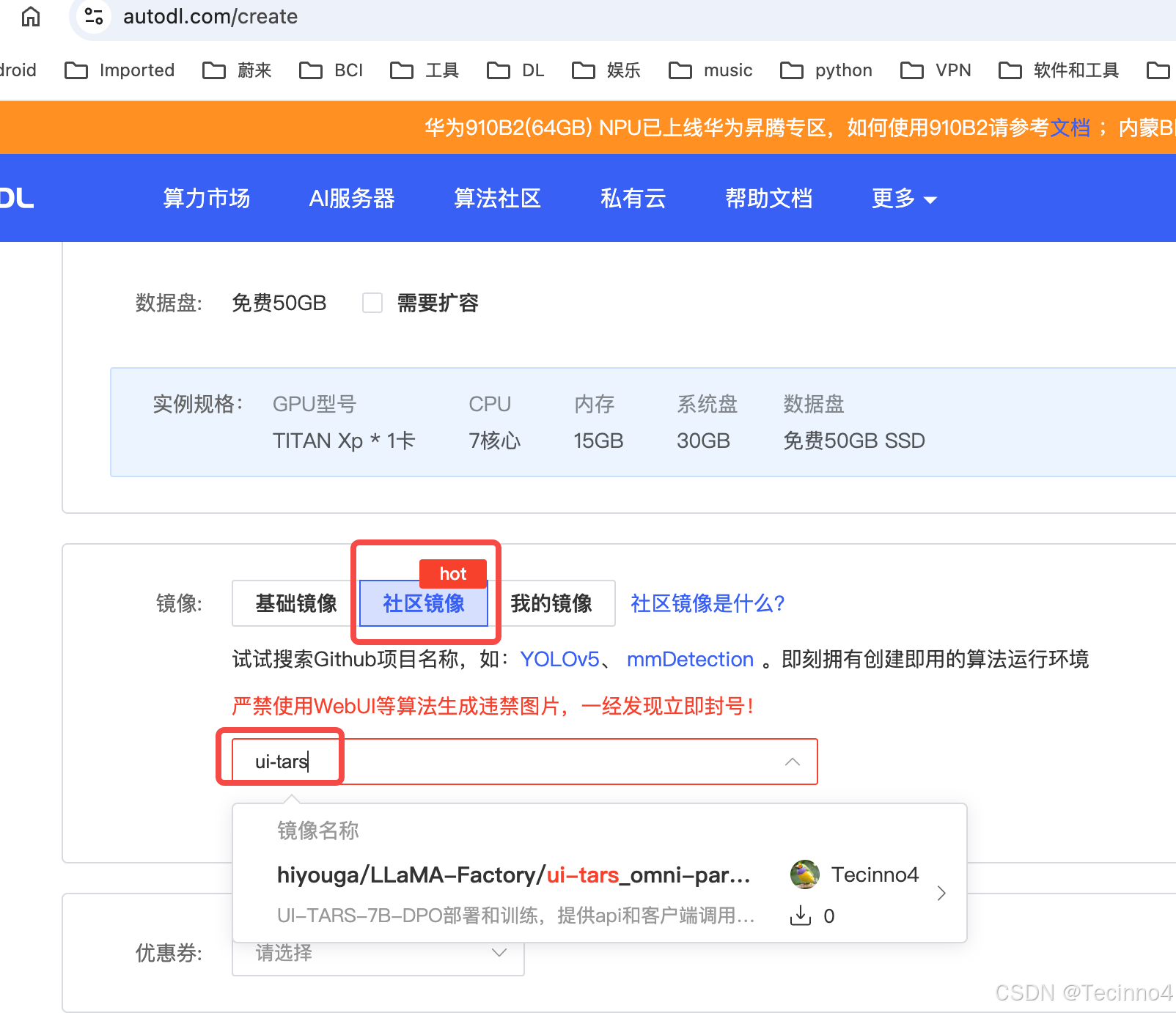
https://www.codewithgpu.com/i/hiyouga/LLaMA-Factory/ui-tars_omni-parser_llama-factory
环境准备
将模型从系统盘移动到数据盘,移动成功后可以选择删除原文件
cp -r /root/model/UI-TARS-7B-DPO /root/autodl-tmp/
cp -r /root/omni /root/autodl-tmp/
ui-tars web推理和训练
bash /root/LLaMA-Factory/chuli/one.sh
高级设置的提示模板要改成qwen2_vl,否则无法上传图片

具体的使用方法可以查看llama-factory官方
https://github.com/hiyouga/LLaMA-Factory
ui-tars api部署
进入conda环境
conda activate llama
-tp 是指需要的gpu数量,改成1
python -m vllm.entrypoints.openai.api_server --served-model-name ui-tars \
--model /root/autodl-tmp/UI-TARS-7B-DPO --limit-mm-per-prompt image=5 --dtype=half -tp 1
使用自定义服务进行映射,方便本地电脑调用:
ssh -CNg -L 8000:127.0.0.1:8000 root@region-9.autodl.pro -p 46525
本地电脑调用示例:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ui-tars",
"messages": [
{"role": "user", "content": "我想问你,5的阶乘是多少?<think>\n"}
]
}'
{"id":"chat-7c8149f008a24adfa451a989ba6256d5","object":"chat.completion","created":1741314705,"model":"ui-tars","choices":[{"index":0,"message":{"role":"assistant",
"content":"5的阶乘是120。阶乘运算的数学符号是“!”。在计算机编程语言中,它通常用“ fact”来表示。阶乘的定义为:n! = n * (n - 1) * (n - 2) * ... * 2 * 1,其中n是一个正整数。","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":22,"total_tokens":97,"completion_tokens":75},"prompt_logprobs":null}%
test.py
from model import OpenAIModel, print_with_color
configs = {
"DEEPSEEK_API_BASE": "http://localhost:8000/v1/chat/completions",
"DEEPSEEK_API_MODEL": "ui-tars",
"MAX_TOKENS": 1024,
"TEMPERATURE": 0,
"OPENAI_API_KEY": ''
}
def ask(question: str):
print_with_color("####################deepseek####################", "magenta")
print_with_color(f"question: {question}", 'yellow')
mllm = OpenAIModel(base_url=configs["DEEPSEEK_API_BASE"],
api_key=configs["OPENAI_API_KEY"],
model=configs["DEEPSEEK_API_MODEL"],
temperature=configs["TEMPERATURE"],
max_tokens=configs["MAX_TOKENS"],
disable_proxies=True)
prompt = question
images = ['image1.jpg']
status, rsp = mllm.get_model_response(prompt, images=images)
if not status:
print_with_color(f"失败,{rsp}", 'red')
return
print_with_color(f"*********************** rsp:\n{rsp}", "yellow")
ask("解释下图片的内容")
model.py
from abc import abstractmethod
from typing import List
import base64
import requests
import sys
from typing import Tuple
from colorama import Fore, Style
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def print_with_color(text: str, color=""):
if color == "red":
print(Fore.RED + text)
elif color == "green":
print(Fore.GREEN + text)
elif color == "yellow":
print(Fore.YELLOW + text)
elif color == "blue":
print(Fore.BLUE + text)
elif color == "magenta":
print(Fore.MAGENTA + text)
elif color == "cyan":
print(Fore.CYAN + text)
elif color == "white":
print(Fore.WHITE + text)
elif color == "black":
print(Fore.BLACK + text)
else:
print(text)
print(Style.RESET_ALL)
class BaseModel:
def __init__(self):
pass
@abstractmethod
def get_model_response(self, prompt: str, images: List[str]) -> Tuple[bool, str]:
pass
class OpenAIModel(BaseModel):
def __init__(self, base_url: str, api_key: str, model: str, temperature: float, max_tokens: int, disable_proxies=False):
super().__init__()
self.base_url = base_url
self.api_key = api_key
self.model = model
self.temperature = temperature
self.max_tokens = max_tokens
self.disable_proxies = disable_proxies
def get_model_response(self, prompt: str, images: List[str]=[], tools: list[dict]=None,
history: list[dict]=None, role: str="user") -> Tuple[bool, str]:
content = [
{
"type": "text",
"text": prompt
}
]
for img in images:
base64_img = encode_image(img)
content.append({
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_img}"
}
})
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
payload = {
"model": self.model,
"messages": [
{
"role": role,
"content": content
}
],
"temperature": self.temperature,
"max_tokens": self.max_tokens
}
if tools:
payload["tools"] = tools
if history:
history.append(payload['messages'][-1])
payload['messages'] = history
if self.disable_proxies:
response = requests.post(self.base_url, headers=headers, json=payload, proxies={}).json()
else:
response = requests.post(self.base_url, headers=headers, json=payload).json()
if "error" not in str(response):
if not 'usage' in response:
print_with_color(f"not usage:{response}", 'res')
else:
usage = response["usage"]
prompt_tokens = usage["prompt_tokens"]
total_tokens = usage["total_tokens"]
completion_tokens = usage["completion_tokens"]
print_with_color(f"total_tokens: {total_tokens}, prompt_tokens: {prompt_tokens}, completion_tokens: {completion_tokens}")
completion_tokens = usage["completion_tokens"]
if self.model == "gpt-4o":
print_with_color(f"Request gpt-4o cost is "
f"${'{0:.2f}'.format(prompt_tokens / 1000 * 0.005 + completion_tokens / 1000 * 0.015)}",
"yellow")
else:
print_with_color(f"Request cost is "
f"${'{0:.2f}'.format(prompt_tokens / 1000 * 0.01 + completion_tokens / 1000 * 0.03)}",
"yellow")
else:
print_with_color(f"执行失败,response: {response}", "red")
return False, response
if tools:
return True, response["choices"][0]["message"]["tool_calls"]
else:
return True, response["choices"][0]["message"]["content"]
omni-parser使用
方法1,通过服务器部署
进入omni目录
进入conda环境
conda activate llama
启动服务,最好有gpu的
python server.py
本地
通过client.py中的parser方法调用
方法2,本地部署调用
如果本地电脑有比较好的GPU,可以直接调用omni_parser.py里的parser方法。