RNN模型与NLP应用——(7/9)机器翻译与Seq2Seq模型
声明:
本文基于哔站博主【Shusenwang】的视频课程【RNN模型及NLP应用】,结合自身的理解所作,旨在帮助大家了解学习NLP自然语言处理基础知识。配合着视频课程学习效果更佳。
材料来源:【Shusenwang】的视频课程【RNN模型及NLP应用】
视频链接:RNN模型与NLP应用(7/9):机器翻译与Seq2Seq模型_哔哩哔哩_bilibili
一、学习目标
1.了解什么是Seq2Seq模型
2.掌握Sequence to Sequence模型实现的底层逻辑
3.学会提升Sequence to Sequence模型的几种方法
二、Sequence to Sequence模型
这是一个多对多的模型

【样例介绍】我们要搭建一个将英语文本翻译为德语的模型
(1)处理数据
大家可以在这个网站上找数据来训练
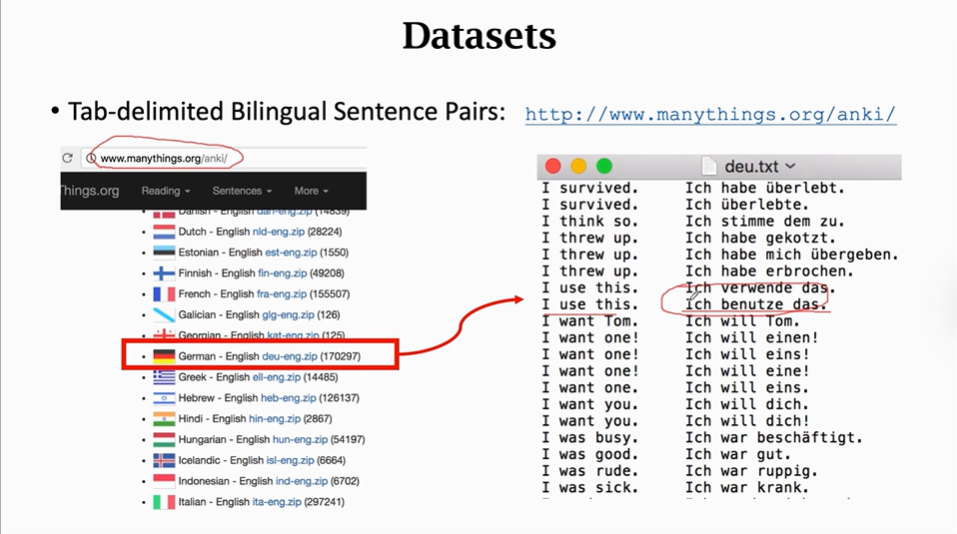
预处理:
将文本中的标点符号删掉,将大写转换为小写等操作
tokenazation:

要用两个不同的tokenizer,因为不同的语言有着不同的字母表,两种语言的字母表通常是不同的,此外不同的语言分词方法不同,所以我们应该构建两种不同的字母表。
char-level可以将文本分割成以一个一个的字符
word-level可以将文本分割成一个一个单词
实际上我们通常会用word-level【这里我们选用char-level】因为实际的数据集通常比较大,但我们这里数据集没有那么大,因此使用char-level

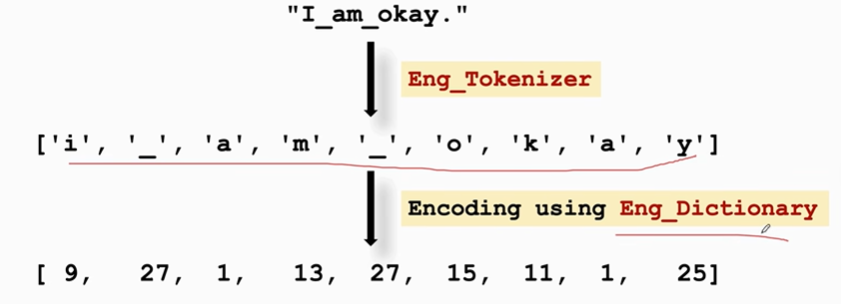
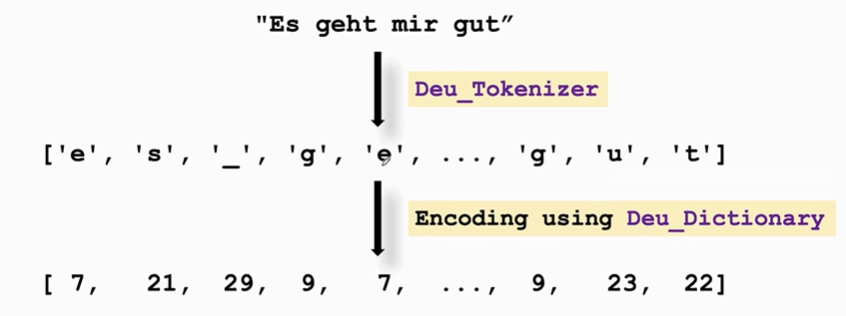
左边的字典是英语字典,右边是德语字典

用字母表示出英语文本序列和德语文本序列
英语:
德语:
(2)搭建模型
接下来,我们搭建一个Sequence to Sequence模型。
Sequence to Sequence模型由编码器和解码器两个部分构成
编码器:
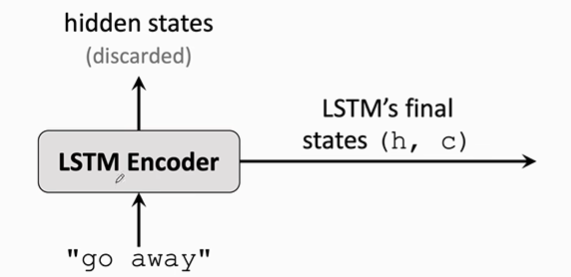
Encoder是一个LSTM或者其他RNN模型,用来从输入的英语语句中提取特征,Encoder最后一个状态就是从输入的句子中提取的特征,包含这句话的信息。其余的状态信息没有用都被丢掉了。Encoder的输出就是最后一个状态向量h 和传输带c
解码器:

Decoder的初始状态是Ecoder的最后一个状态,通过Encoder最后一个状态,Decoder得知输入信息是“go away”。
现在Decoder开始输出德语句子,Decoder的第一个输入必须是起始符(如“\t”)

【详细过程】 第一个字母是m,则Decoder会将m做noe hot encoding然后作为标签y,Decoder会输出一个概率分布记作p,用标签y和p的交叉熵作为损失函数,所以损失函数越小越好。有了损失函数,就可以反向传播计算梯度,梯度传到Decoder,再由Decoder传到Encoder,然后用梯度下降来调整Encoder和Decoder的参数,从而使得损失函数减小。
然后输入变为两个字符“\tm”,根据上述过程以此类推,在推出下一个字母
然后输入变为三个字符“...”
.......
不断重复这个过程,直到这句德语的最后一个字符,当输出维停止字符"\n"的话,则停止。
以下为具体步骤:
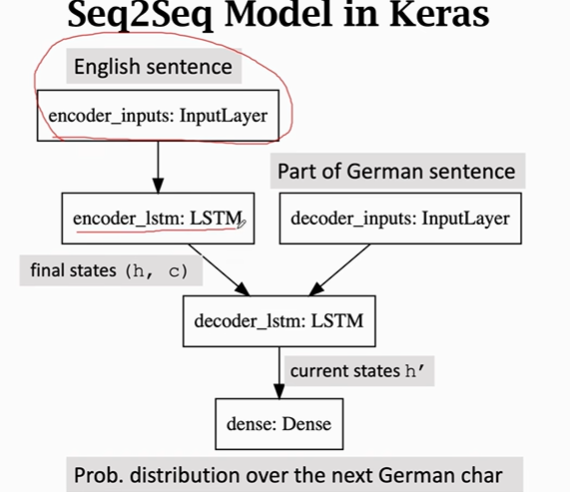
(3)推导
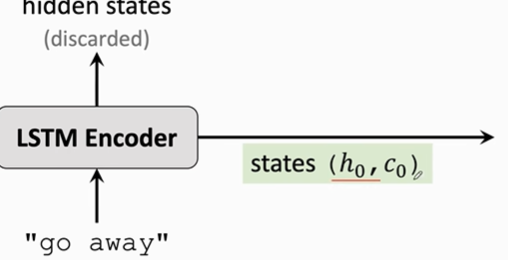
Encoder将英文信息通过RNN模型,最终输出为状态向量h0和传输带c0,h0和c0中存储着听英文文本的特征,被作为Decoder的初始状态向量,这样以来Decoder就知道了输入文本是“go away”。
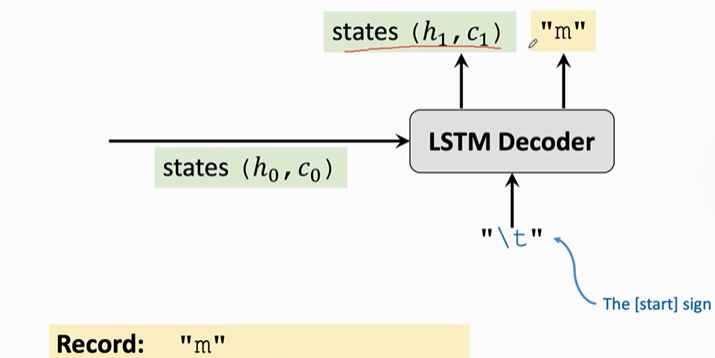
当第一个输入“\t”输入到Decoder中时,Decoder就会更新状态和传输带,得到新的状态向量h1和新的传输带C1,并预测下一个字母“m”。并将其记录下来。
不断重复这个过程,就可以完整的输出翻译结果。
三、总结
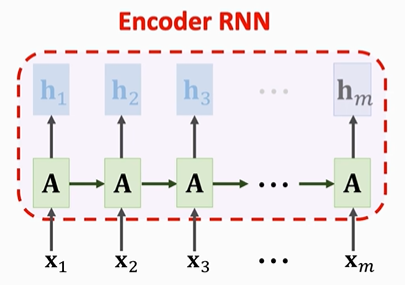
在本例中,一段英文文本会输入进Encoder,每输入一个字母,RNN就会记录当前字符的信息,直到输完最后一个字符,Encoder就会记录下整个文本的信息存储在状态向量hm中。
最后一个hm会作为Decoder的初始化状态进入Decoder,这样Decoder就会记住输入的英文句子了
接下来的步骤如下图:

四、思考:我们该如何改进Sequence to Sequence模型
(1)将Encoder由单向LSTM改进为双向LSTM
由于Encoder从头开始读取英语句子,那么Encoder有可能会遗忘并遗漏一开始输入的信息,
那么我们可以将Encoder改进为双向RNN,这样就可以使Encoder更好的记住整个英语文本。
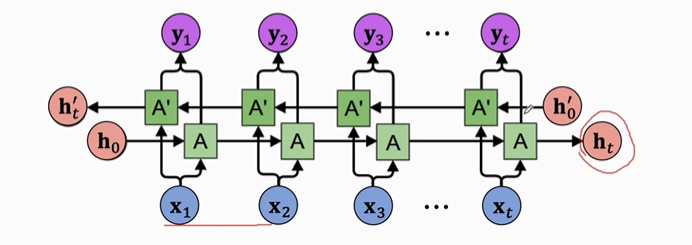
【注意】Decoder必须是单向LSTM,因为decoder相当于一个文本生成器,只能从头按顺序输出
(2)可以用word-level替代char-level
因为word-level处理后的序列更短,可以是LSTM更容易记住英语句子。但是由于单词维度为10000很高,所以需要embedding层将其映射为低维词向量才可以。并且要求拥有足够大的数据集才可以。
(3)采取多任务训练
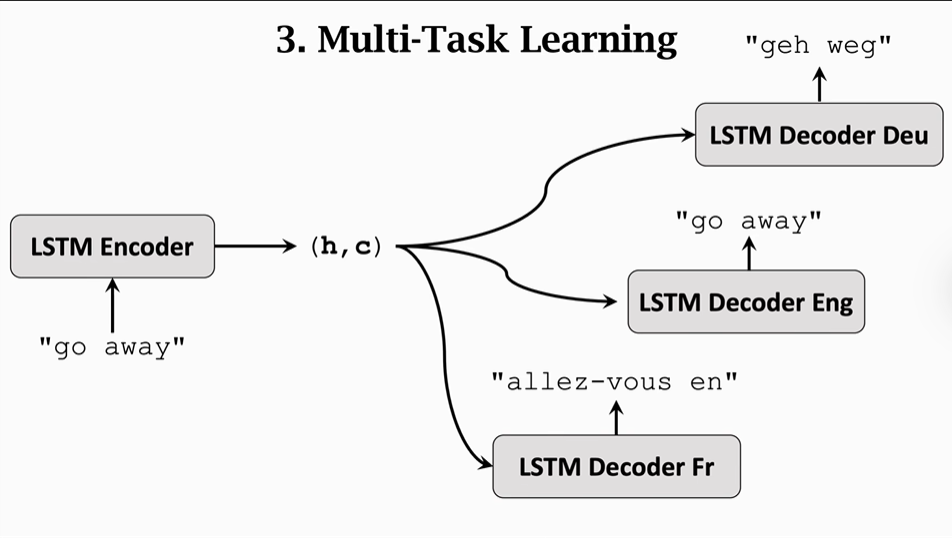
我们可以同时采取英语翻译英语本身,英语翻译汉语,英语翻译其他语言这样的多任务训练方法,来提升英语翻译德语的效果。一是因为数据集变大了,导致训练效果变的更好了;而是因为即使训练的是其他语言,但仍会对英语翻译德语的效果有所提升。