嵌入式c学习第十一天
c语言结构体:struct(structure的缩写)
定义格式:
struct 结构体名称
{
数据类型 成员名称;
数据类型 成员名称;
数据类型 成员名称;
}; //复合语句后面的分号,不可以省略 结构体不应该包含不完整的类型或者函数类型,结构体中不应该包含结构体本身,但是结构体可以包含指向该结构体类型的指针。
构造的结构体类型不占内存,只有使用该类型创建变量实才会得到内存空间
成员赋值:连续赋值,和单独赋值
成员访问:
①通过.访问:后缀运算符 . 的第一个操作对象应该是一个结构体或者联合体类型,第二个操作对象是成员名称
②通过->访问:后缀运算符-> 的第一个操作对象是指向结构体类型的指针,第二个操作对象是成员名称
#include <stdio.h>
// 定义一个结构体数据类型,此时不占内存
struct Person
{
char name[20];
int age;
char sex[10];
};
int main()
{
//定于一一个结构体变量,此时变量p1会得到内存空间
struct Person p1;
//通过后缀运算符点访问成员
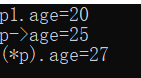
p1.age = 20;
printf("p1.age=%d\n", p1.age);
//定义一个指针变量指向该结构体类型的空间(堆内存或者变量地址)
struct Person *p = &p1;
p->age = 25; //通过->访问
printf("p->age=%d\n", p1.age);
(*p).age = 27; //通过间接得到地址下的变量,使用点访问成员
printf("(*p).age=%d\n", p1.age);
return 0;
}
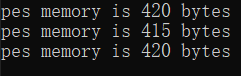
结构体的空间大小:32位系统中未考虑CPU运行效率,寻址主要是以4字节为主,即当数据不够4字节宽度时,系统默认提供4字节内存,方便CPU寻址,这种方式也叫字节对齐(空间换时间)
使用 #pragma pack(1),可以取消字节对齐
#include <stdio.h>
// 32位系统默一次性寻址4字节
struct Person1
{
int i; //4 4
char j; //1 4
char *p; //4 4
long a[100]; //400 400
char b[2]; //2 4
char *q; //4——415 4——420
};
#pragma pack(1) //取消字节对齐
struct Person2
{
int i; //4 4
char j; //1 4
char *p; //4 4
long a[100]; //400 400
char b[2]; //2 4
char *q; //4——415 4——420
};
#pragma pack() //恢复字节对齐
struct Person3
{
int i; //4 4
char j; //1 4
char *p; //4 4
long a[100]; //400 400
char b[2]; //2 4
char *q; //4——415 4——420
};
int main()
{
struct Person1 pes1;
printf("pes memory is %d bytes\n", sizeof(pes1)); //420
struct Person2 pes2;
printf("pes memory is %d bytes\n", sizeof(pes2)); //415
struct Person3 pes3;
printf("pes memory is %d bytes\n", sizeof(pes3)); //415
return 0;
}
变量定义
#include <stdio.h>
//此方式,data1,data2都是结构体变量,且后续不能在定义此结构体变量
struct
{
int i;
char j;
char *p;
long a[100];
char b[2];
char *q;
}data1, *data2; //data1 普通变量,data2 指针变量
int main()
{
(&data1)->i = 20;
printf("(&data1)->i is %d\n", data1.i); //420
return 0;
}![]()
别名定义:typedef(type define缩写)
使用格式:typedef 数据类型 别名;如:typedef unsigned char uint8_t(别名末尾加_t)
#include <stdio.h>
typedef struct student
{
int i;
char j;
char *p;
long a[100];
char b[2];
char *q;
}pes_t;
int main()
{
//定于一个结构体变量
struct student data1;
pes_t data2;
//定义结构体数组,并访问访问内部成员
struct student arr[10];
arr[0].i = 20;
//定义结构体指针数组,并访问访问内部成员
struct student *str[10];
str[0]->i = 30;
return 0;
}c语言联合体:union,用同一块内存存储不同类型数据,这些数据是互斥的,不能同时存在,联合体内存空间就是成员中数据宽度最大的那个
定义类型
union 联合体名称
{
数据类型 成员名称;
数据类型 成员名称;
数据类型 成员名称;
};
成员访问
①通过.访问 类型.成员名称
②通过->访问 指向结构体类型的指针->成员名称
联合体也遵循字节对齐原则
通过联合体判断大端还是小端存储
#include <stdio.h>
union //创建联合体类型
{
int a;
char b;
}outmod; //定义联合体变量
int main()
{
outmod.a = 0x12345678;
printf("%#x\n", outmod.b);
if(0x12 == outmod.b)
{
printf("采用大端存储模式");
}
else
{
printf("采用小端存储模式");
}
return 0;
}
枚举:enum,每个成员都必须是整形,吧一些没有意义的整数起一个有意义的名称,利用该名称就相当于使用该常量,提高程序的可读性
#include <stdio.h>
enum
{
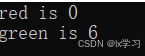
red, //第一个元素未被初始化默认为0
blue,
yellow=5, //对当前元素进行初始化
green //当前元素的值是上一个元素的值+1 = 6
};
int main()
{
printf("red is %d\n", red);
printf("green is %d\n", green);
return 0;
}