进程地址空间:操作系统中的虚拟世界与心灵映射,深入解析进程地址空间
文章目录
- 引言
- 📘正文
- 📖问题引入
- 📖虚拟空间划分
- 📖真实空间分布
- 🖋️代码实现
- 🖋️问题反思
- 📖进程地址空间
- 🖋️虚拟地址
- 🖋️页表+MMU
- 🖋️写时拷贝
- 📕各部分结构的详细说明
- 🖊地址空间布局图
- 🖊代码段
- 🖊数据段
- 🖊 BSS段
- 🖊堆(Heap)
- 🖊 栈(Stack)
- 🖊C代码示例:进程地址空间
- 结语:进程地址空间的哲学意义

引言
在操作系统的浩瀚宇宙中,进程地址空间犹如一片神秘的荒原,深藏着无数的秘密与可能性。它是每一个程序运行的根基,是虚拟与现实交汇的地方,是计算机内存的魔法世界。它存在于操作系统的心脏之中,伴随着进程的诞生与死灭,演绎着一场关于资源管理与控制的永恒故事。
今天,我们将一起穿越这片无形的疆域,去探讨进程地址空间的奥秘,去感受它在操作系统中的重要地位与深刻影响。
对于 C/C++ 来说,程序中的内存包括这几部分:栈区、堆区、静态区 等,其中各个部分功能都不相同,比如函数的栈帧位于 栈区,动态申请的空间位于 堆区,全局变量和常量位于 静态区 ,区域划分的意义是为了更好的使用和管理空间。
他们的结构排布如图所示。那么真实物理空间也是如此划分吗?多进程运行 时,又是如何区分空间的呢?写时拷贝 机制原理是什么?本文将对这些问题进行解答.
内存条:真实的物理空间,用来存储各种数据

📘正文
📖问题引入
地址是唯一的,对地址进程编号的目的是为了不冲突
这是个耳熟能详的概念,在 C语言 学习阶段,我们可以通过对变量 & 取地址的方式,查看当前变量存储空间的首地址信息
#include <stdio.h>
int main()
{
const char* ps = "这是一个常量字符串";
printf("字符串地址:%p\n", ps); //%p 专门用来打印地址信息
return 0;
}
linux下的执行结果

利用前面学习的 fork 函数创建子进程,使得子进程和父进程共同使用一个变量
代码示例如下:
1#include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 #include<sys/wait.h>
5 #include<stdlib.h>
6 int main()
7 {
8 int val=10;
9 pid_t id=fork();
10 if(id==0)//子进程
11 {
12 val*=2;
13 printf("我是一个子进程,pid: %d ppid : %d 共享值: %d 共享值地址: %p\n",getpid(),getppid(),val,&val);
14 exit(0);
15 }
16 waitpid(id,0,0);
17 printf("我是父进程,pid: %d ppid: %d 共享值: %d 共享值地址: %p\n",getpid(),getppid(),val,&val);
18 return 0;
19 }

可以看到,针对同一个地址相同的值val,二者打印出来的共享值却不同,难度一个数可以同时拥有两个不同的值吗,这显然是不可能的。
这与之前提到的fork有两个返回值原理类型,都利用了写时拷贝
因为真实地址都是 唯一 的,分析:
- 不同的空间出现同名的情况
- 父子进程使用的真实物理空间并非同一块空间!
原因:
- 当子进程尝试修改共享值时,发生
写时拷贝机制 - 语言层面的程序空间地址不是真实物理地址
- 一般将此地址称为
虚拟地址或线性地址
结论: 语言层面的地址都是虚拟地址,用户无法看到真实的物理地址,由 OS 统一管理
📖虚拟空间划分
一般用户的认知中,C/C++ 程序内存分布如下图所示,直接表示内存中的各个部分
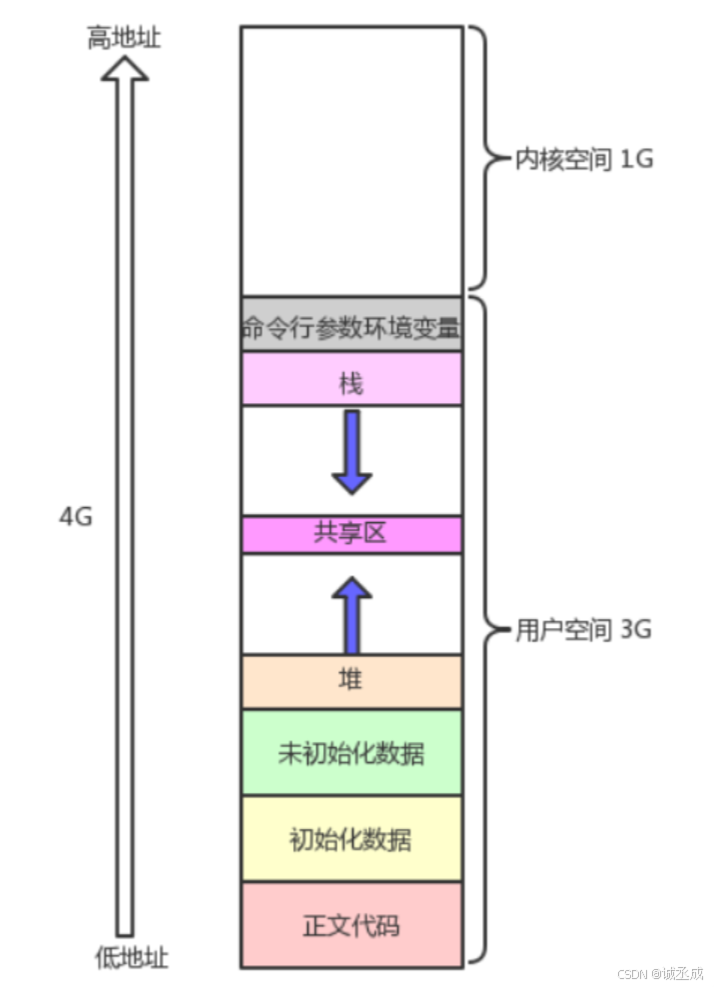
📖真实空间分布
但实际上的空间分布是这样的:
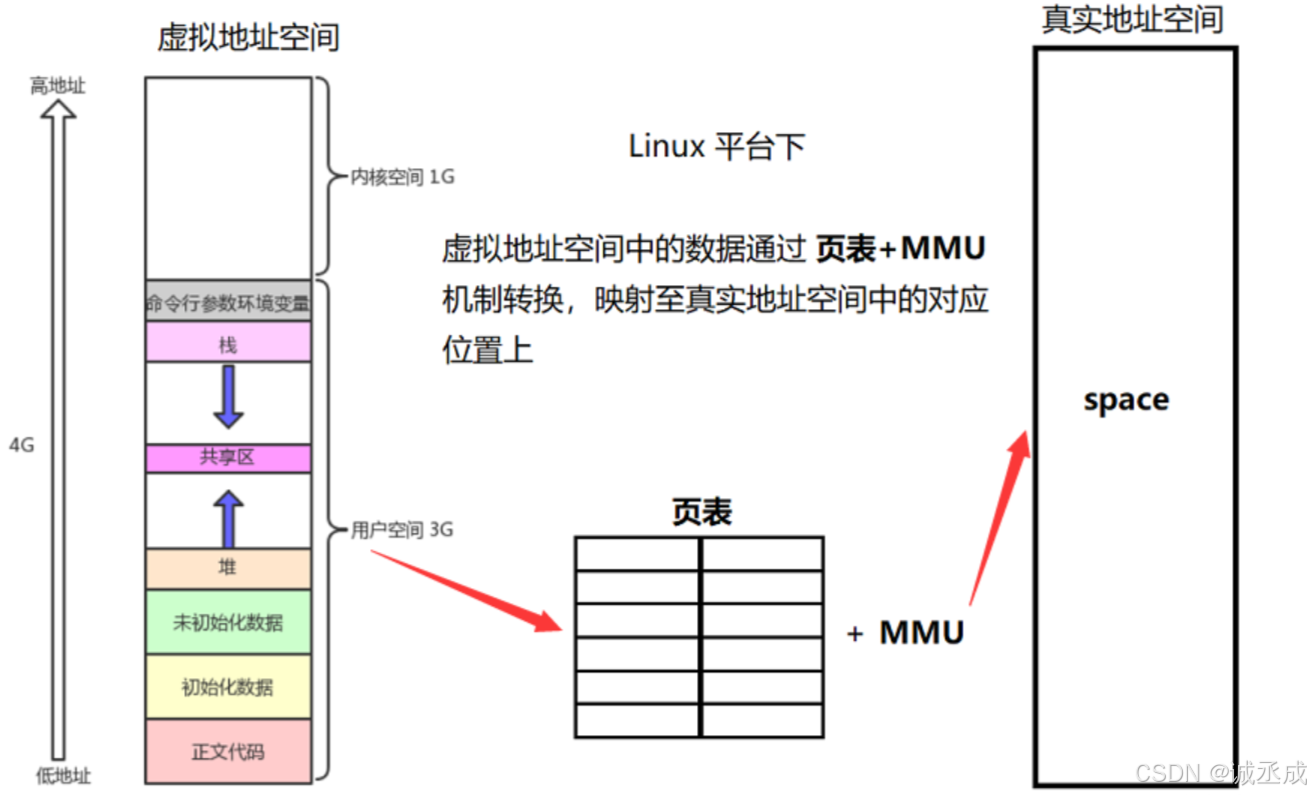
如果有多个进程(真实地址空间只有一份),此时情况是这样的:
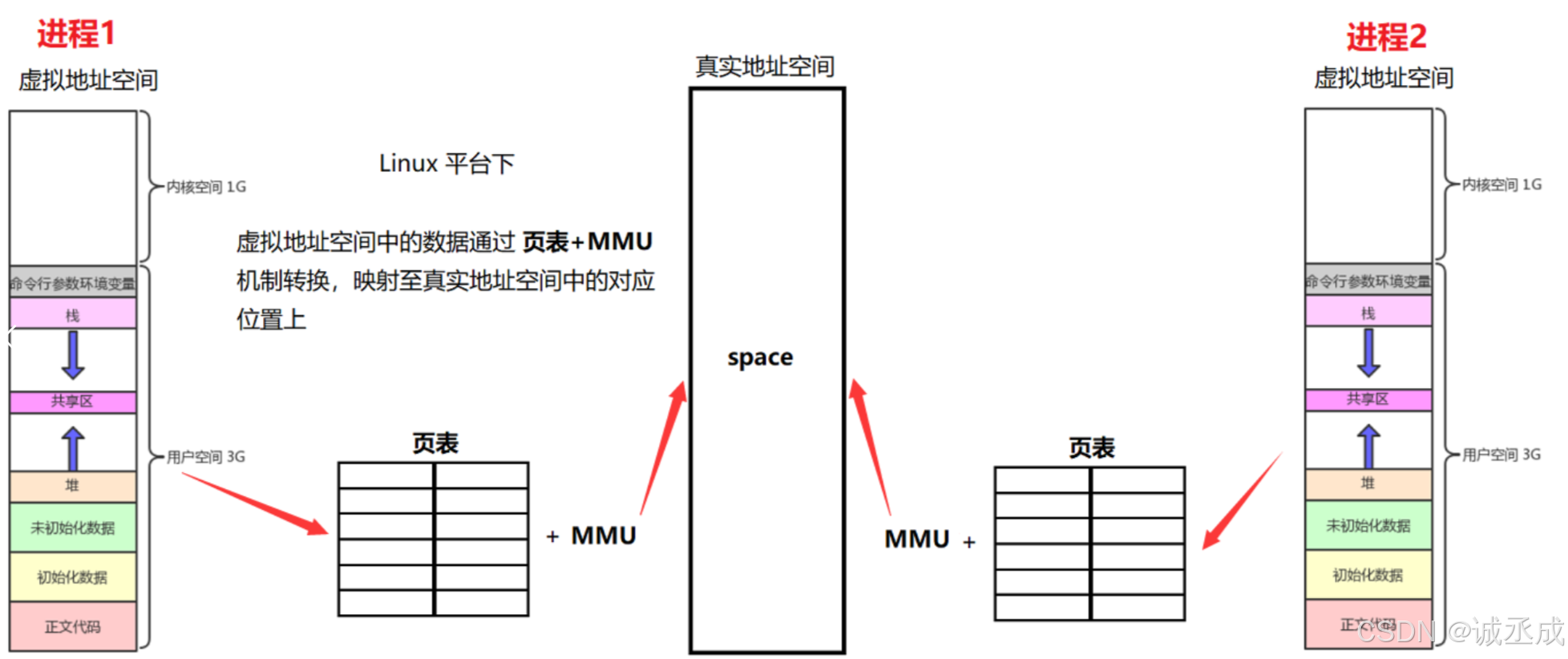
🖋️代码实现
在实现虚拟地址空间时,是用结构体mm_struct实现的
同task_struct一样,mm_struct 中也包含了很多成员,比如不同区域的边界值
//简单展示其中的成员信息
mm_struct
{
//代码区域划分
unsigned long code_start;
unsigned long code_end;
//堆区域划分
unsigned long heap_start;
unsigned long heap_end;
//栈区域划分
unsigned long stack_start;
unsigned long stack_end;
//还有很多其他信息
……
}
因此其程序地址空间的管理,也就是区域划分,只需要修改不同区域的start和end即可.
每个进程都会有这样一个 mm_struct,其中的区域划分就是虚拟地址空间
-
通过对边界值的调整,可以做到不同区域的增长,如堆区、栈区扩大
-
mm_struct 中的信息配合 页表+MMU 在对应的真实空间中使内存(程序寻址)
🖋️问题反思
此时可以理解为什么会发生同一块空间能读取到不同值的现象了
父子进程有着各自的 mm_struct,其成员起始值一致
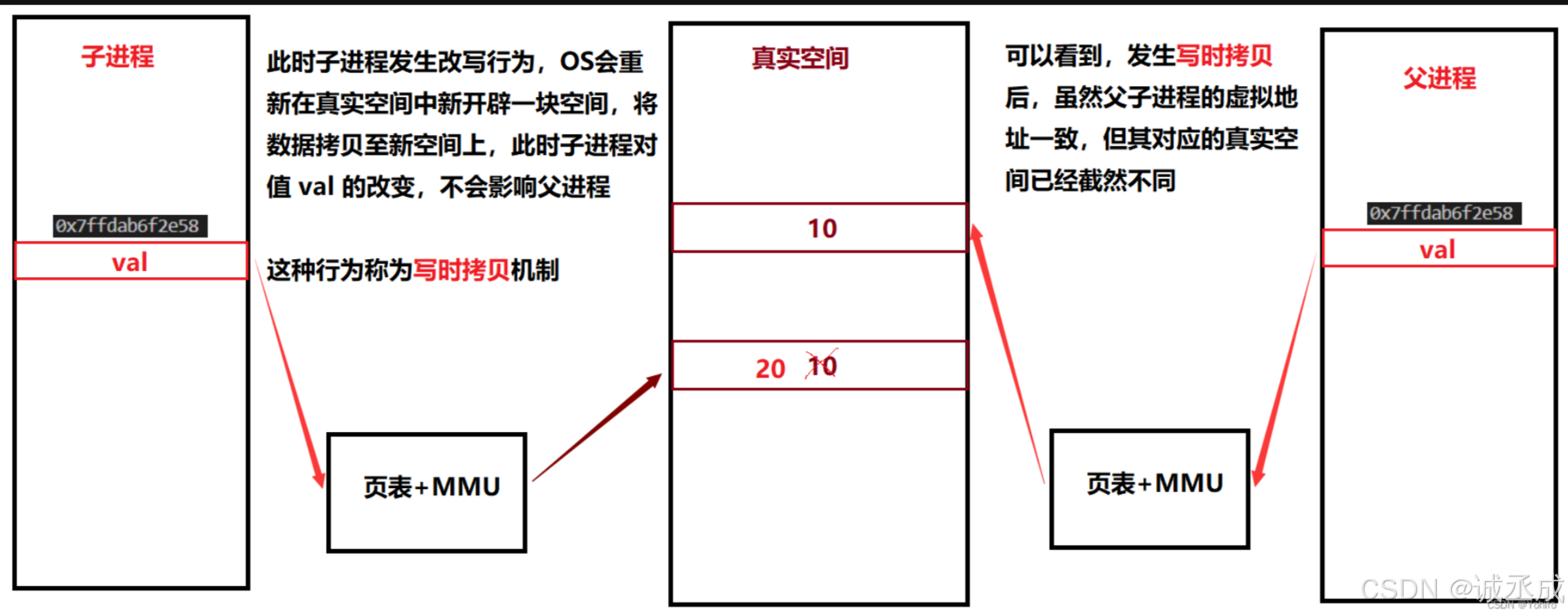
- 对于同一个变量,如果未改写,则两者的虚拟地址通过 页表 + MMU 转换后指向同一块空间
- 发生改写行为,此时会在真实空间中再开辟一块空间,拷贝变量值,让其中一个进程的虚拟地址空间映射改变,这种行为称为
写时拷贝
刚开始,父子进程共同使用同一块空间
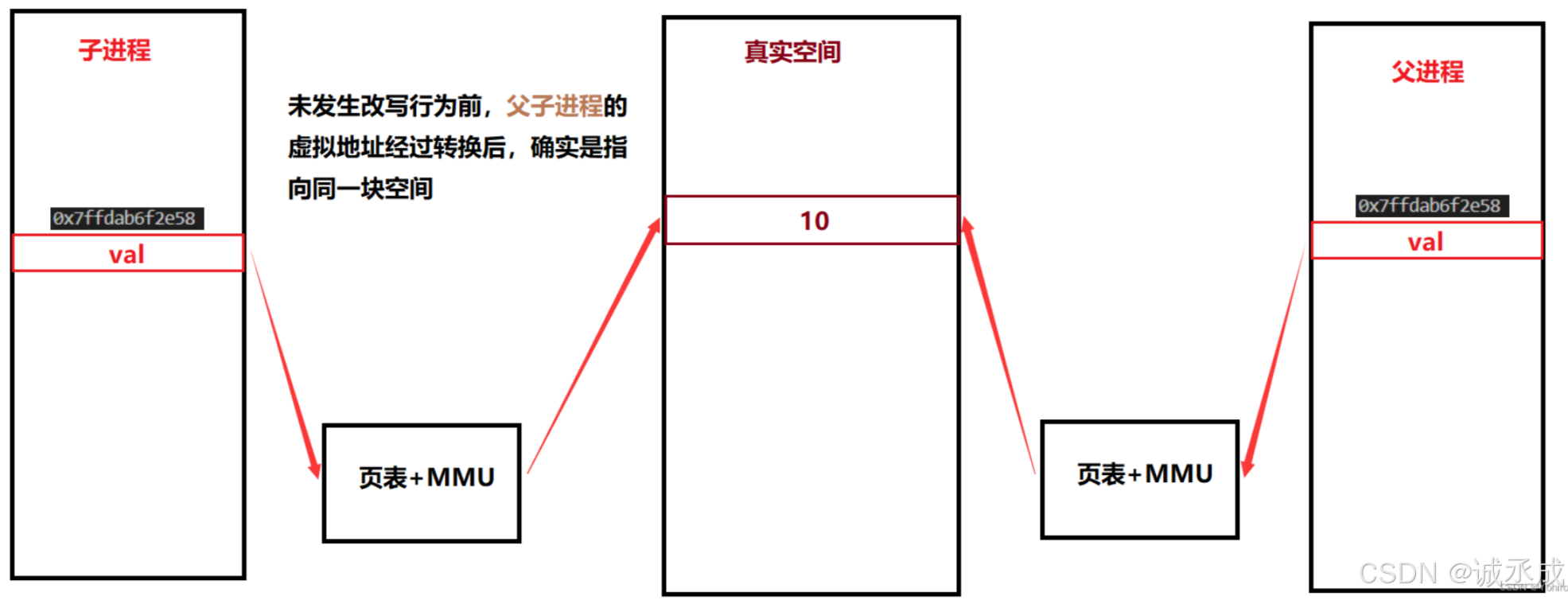
在发生改写行为后,子进程在真实空间内重新开辟一块空间,拷贝变量值改下,虽然此时的虚拟地址仍为初始值,蛋映射关系已经发生变化。
📖进程地址空间
下面来好好谈谈 进程地址空间 (虚拟地址)
🖋️虚拟地址
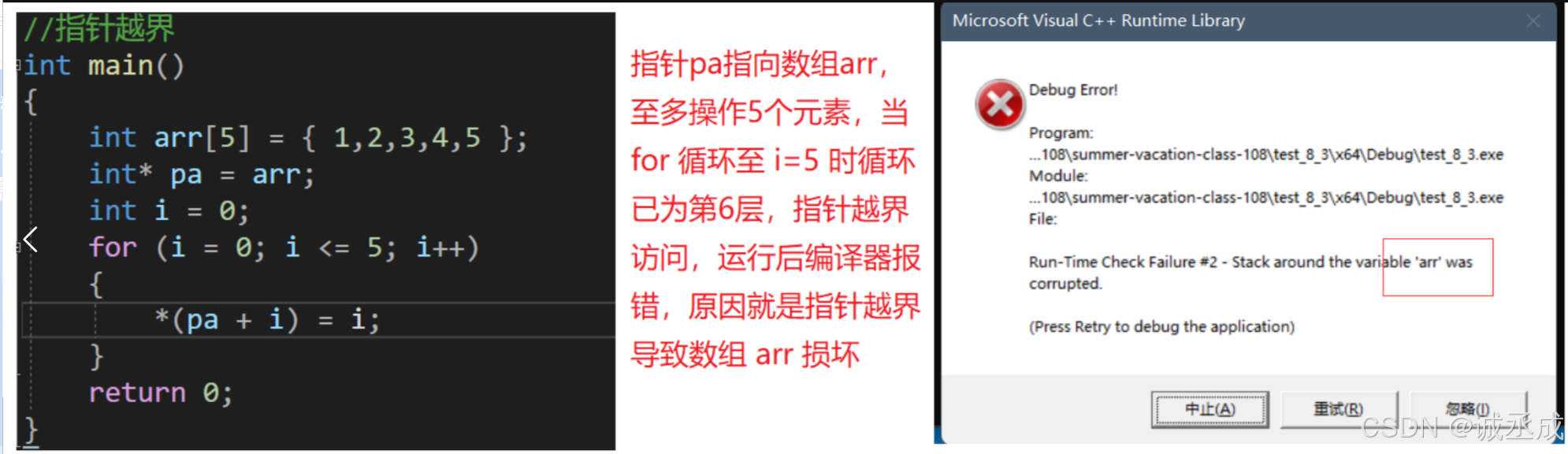
在早期程序中,是没有虚拟地址空间的,对于数据的写入和读取,是直接在物理地址上进行的,程序与物理空间直接打交道,存在以下问题:
- 假设存在野指针问题,此时可能直接对物理内存造成越界读写
- 程序运行时,每次都需要大小为 4GB 的内存使用,当进程过多时,资源分配就会很紧张,引起进程阻塞,导致执行效率下降
- 动态申请内存后,需要依次释放,影响整体效率
为了解决各种问题,大佬们提出了 虚拟地址空间 这个概念,有了 虚拟空间 后,当进程创建时,系统会为其分配属于自己的 虚拟空间,需要使用内存时,通过 寻址 的方式,使用物理地址上的空间即可
- 多个进程互不影响,动态使用,做到
效率、资源双赢 - 发生越界行为时,
寻址机制会检测出是否发生越界行为,如果发生了,能在其对物理地址造成影响前进行拦截 - 因为每个进程都有属于自己的空间,
OS在管理进程时,能够以统一的视角进行管理,效率很高
光有 虚拟地址空间 是不够的,还需要一套完整的 ‘‘翻译’’ 机制进行程序寻址,如 Linux 中的 页表 + MMU
🖋️页表+MMU
页表本质上是一张表,一侧存储虚拟地址,另一侧存储所映射的真实物理地址。
操作系统 会为每个 进程 分配一个 页表,该 页表 使用 物理地址 存储。当 进程 使用类似 malloc 等需要 映射代码或数据 的操作时,操作系统 会在随后马上 修改页表 以加入新的 物理内存。当 进程 完成退出时,内核会将相关的页表项删除掉,以便分配给新的 进程
系统底层机制的研究是非常生涩的,这里简言之就是 页表 记录信息,通过 MMU 机制进行寻址使用内存.
假设目标空间为只读区域(比如数据段、代码段),在进行空间开辟时,会打上只读权限标签。后续对这块进行写入操作时,会直接拒绝
🖋️写时拷贝
思考:为什么要采取写时拷贝映射开辟的方式进行存储呢?每一个数据直接存储不可行吗?
写时拷贝是一种为了优化空间和时间应运而生的操作,带有一定赌博成分。
- 操作系统认为你对于数据的修改与存储操作相比,是较为低频的,因此采取
偷懒的方式进行映射存储,多个进程中的共享数据均指向同一块存储空间,用来优化存储冗余和多次构造的情况 - 这一点在自定义类型时较为明显,内置类型的优化效率并不算高。
可以通过一个简单的例子来证明此现象
//计算 string 类的大小
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s;
cout << sizeof(s) << endl;
return 0;
}
VS2022中
linux环境中

分析:
在代码中,string
s;定义了一个C++的字符串对象。虽然你没有给字符串分配任何内容,但是字节大小却不为0。这是因为不同的编译器和标准库实现可能会有不同的内存布局,通常会包括指向动态内存的指针、当前大小、容量和一些额外的管理信息。
📕各部分结构的详细说明
操作系统将进程地址空间划分为多个区域,每个区域用于存储特定类型的数据。以下是典型的地址空间布局:
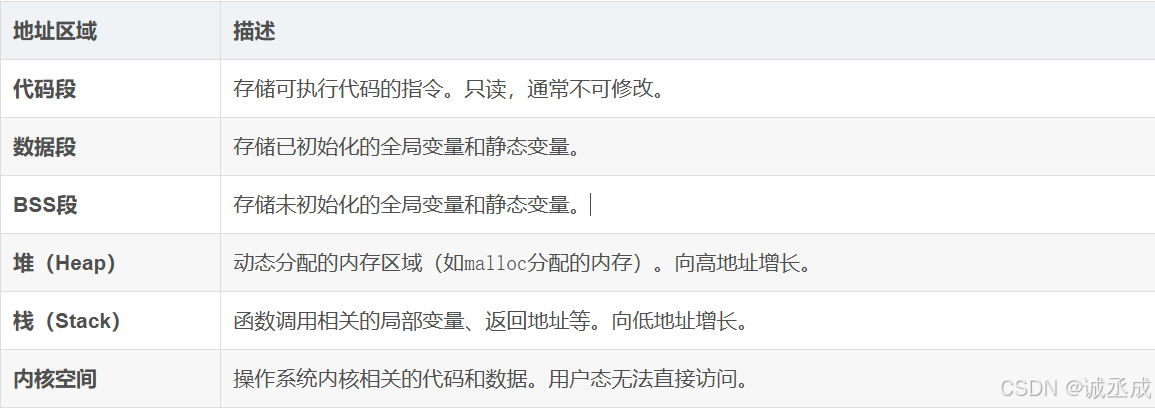
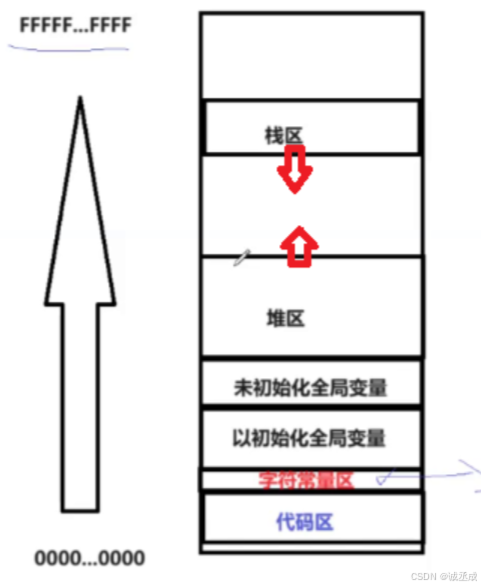
🖊地址空间布局图
以32位操作系统为例,地址空间布局如下:
+---------------------------+ 0xFFFFFFFF
| 内核空间 |
+---------------------------+ 0xC0000000
| 用户栈 |
+---------------------------+
| 动态分配的堆(Heap) |
+---------------------------+
| BSS段 |
+---------------------------+
| 数据段 |
+---------------------------+
| 代码段 |
+---------------------------+ 0x00000000
🖊代码段
- 存储内容:存放程序的可执行代码。
- 访问权限:只读,防止程序意外修改指令。
- 特点:多个进程可以共享同一段代码段(如共享库)
🖊数据段
- 存储内容:存储
已初始化的全局变量和静态变量。 - 访问权限:读写权限。
- 特点:程序运行时大小固定。
🖊 BSS段
- 存储内容:存储
未初始化的全局变量和静态变量。 - 特点:初始值默认为0,占用物理内存时才分配。
🖊堆(Heap)
- 存储内容:
动态分配的内存(如malloc、new分配的内存)。 - 特点:向高地址增长;由程序员手动分配和释放。
🖊 栈(Stack)
- 存储内容:
局部变量、函数调用参数、返回地址等。 - 特点:向低地址增长;由操作系统自动管理,超出范围会触发栈溢出。
上面的几种是主要的几种,还有几个小的内存区,比如字符段常量区,字符常量区的内容不能修改,只有读权限
🖊C代码示例:进程地址空间
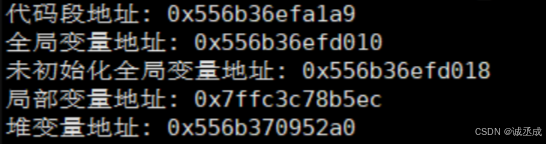
以下代码展示了不同段的地址空间位置。
#include <stdio.h>
#include <stdlib.h>
int global_var = 10; // 全局变量(数据段)
int uninit_var; // 未初始化变量(BSS段)
void print_addresses() {
int local_var = 20; // 局部变量(栈)
void *heap_var = malloc(10); // 动态内存(堆)
printf("代码段地址: %p\n", (void*)print_addresses);
printf("全局变量地址: %p\n", (void*)&global_var);
printf("未初始化全局变量地址: %p\n", (void*)&uninit_var);
printf("局部变量地址: %p\n", (void*)&local_var);
printf("堆变量地址: %p\n", heap_var);
free(heap_var);
}
int main() {
print_addresses();
return 0;
}
输出示例:
代码段地址: 0x401000
全局变量地址: 0x601020
未初始化全局变量地址: 0x601030
局部变量地址: 0x7ffd25d3f8bc
堆变量地址: 0x55d3ecf1b260
结语:进程地址空间的哲学意义
进程地址空间的概念,超越了技术的范畴,它涉及到操作系统如何管理和控制内存,如何为每个进程提供一个独立而安全的运行环境。在这个过程中,虚拟内存技术则如同魔法师一样,巧妙地将虚拟世界与现实世界结合在一起,为开发者创造出一个更加自由和高效的编程环境。
在这个隐形的、却至关重要的空间中,进程的每一次启动、每一次执行、每一次销毁,都在演绎着一场关于资源管理、内存控制与程序执行的深刻哲学思考。正如人生的每一个阶段,进程地址空间也在默默地展示着操作系统的智慧与魅力,成为计算机科学中不可或缺的一部分。
本篇关于进程地址空间的介绍就暂告段落啦,希望能对大家的学习产生帮助,欢迎各位佬前来支持斧正!!!
