自然语言处理(26:(终章Attention 2.)带Attention的seq2seq的实现)
系列文章目录
终章 1:Attention的结构
终章 2:带Attention的seq2seq的实现
终章 3:Attention的评价
终章 4:关于Attention的其他话题
终章 5:Attention的应用
目录
系列文章目录
前言
一、编码器的实现
二、解码器的实现
三、seq2seq的实现
前言
上一节实现了Attention层(以及Time Attention层),现在我们使用 这个层来实现“带Attention的seq2seq”。和上一章实现了3个类(Encoder、 Decoder 和 seq2seq)一样,这里我们也分别实现3个类(AttentionEncoder、 AttentionDecoder 和 AttentionSeq2seq)
一、编码器的实现
首先实现AttentionEncoder 类。这个类和上一章实现的Encoder类几乎一样,唯一的区别是,Encoder类的forward()方法仅返回LSTM层的最后的隐藏状态向量,而AttentionEncoder类则返回所有的隐藏状态向量。因此, 这里我们继承上一章的Encoder类进行实现。AttentionEncoder类的实现如下所示
class AttentionEncoder(Encoder):
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
return hs
def backward(self, dhs):
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
二、解码器的实现
接着实现使用了Attention层的解码器。使用了Attention的解码器的层结构如下图所示
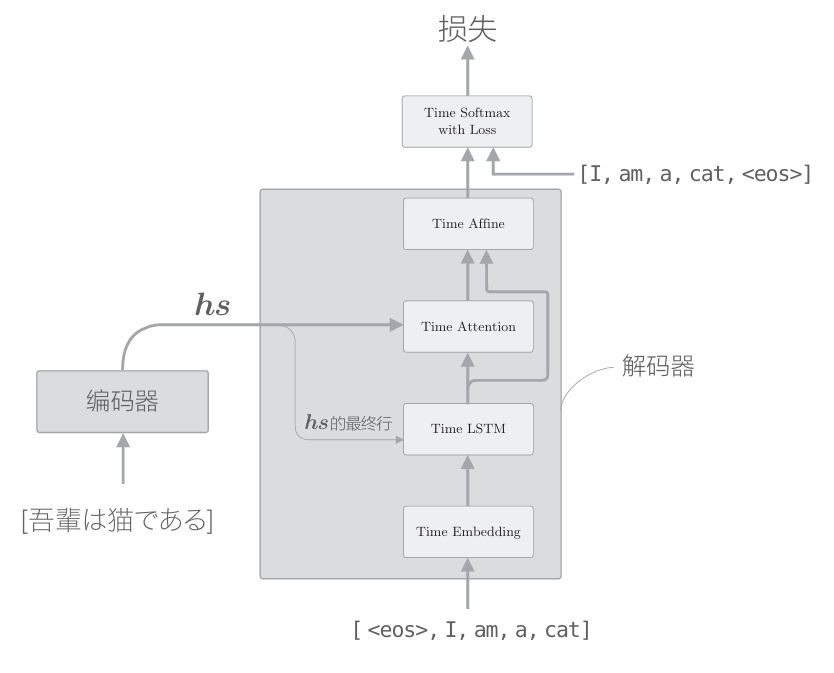
从上图中可以看出,和上一章的实现一样,Softmax层(更确切地说,是Time Softmax with Loss层)之前的层都作为解码器。另外,和上一章一样,除了正向传播forward()方法和反向出传播backward()方法之外,还实现了生成新单词序列(字符序列)的generate()方法。这里给出Attention Decoder层的初始化方法和forward()方法等的实现,如下所示
class AttentionDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(2*H, V) / np.sqrt(2*H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.attention = TimeAttention()
self.affine = TimeAffine(affine_W, affine_b)
layers = [self.embed, self.lstm, self.attention, self.affine]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, enc_hs):
h = enc_hs[:,-1]
self.lstm.set_state(h)
out = self.embed.forward(xs)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
N, T, H2 = dout.shape
H = H2 // 2
dc, ddec_hs0 = dout[:,:,:H], dout[:,:,H:]
denc_hs, ddec_hs1 = self.attention.backward(dc)
ddec_hs = ddec_hs0 + ddec_hs1
dout = self.lstm.backward(ddec_hs)
dh = self.lstm.dh
denc_hs[:, -1] += dh
self.embed.backward(dout)
return denc_hs
def generate(self, enc_hs, start_id, sample_size):
sampled = []
sample_id = start_id
h = enc_hs[:, -1]
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array([sample_id]).reshape((1, 1))
out = self.embed.forward(x)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(sample_id)
return sampled这里的实现除使用了新的Time Attention层之外,和上一章的Decoder类 没有什么太大的不同。需要注意的是,forward()方法中拼接了Time Attention 层的输出和LSTM层的输出。在上面的代码中,使用np.concatenate()方法进行拼接。 这里省略对AttentionDecoder 类的backward() 和 generate() 方法的说明。最后,我们使用AttentionEncoder类和AttentionDecoder 类来实现 AttentionSeq2seq类
三、seq2seq的实现
AttentionSeq2seq 类的实现也和上一章实现的seq2seq几乎一样。区别仅在于,编码器使用AttentionEncoder类,解码器使用AttentionDecoder类。 因此,只要继承上一章的Seq2seq类,并改一下初始化方法,就可以实现 AttentionSeq2seq 类
class AttentionSeq2seq(Seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
args = vocab_size, wordvec_size, hidden_size
self.encoder = AttentionEncoder(*args)
self.decoder = AttentionDecoder(*args)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
以上就是带Attention的seq2seq的实现。